

基于动态层级通信的多无人机协同策略方案
军用/航空电子
描述
作者:程进1,2,胡寒栋1,2,3,江业帆1,2,张一博1,2,3,丁季时雨1,2,3
(1.航天科工集团智能科技研究院有限公司,北京 100144;2.航天防务智能系统与技术科研重点实验室,北京 100144;3.中国航天科工集团第二研究院,北京 100854)
摘要: 随着人工智能技术的发展,空域无人作战正由“单平台遥控”向“多平台协同”转变。多无人机协同作战任务具有非完全信息、通信受限、高实时、强动态等特点,给协同决策生成带来巨大挑战。针对通信受限环境中的多无人机协同决策问题,提出一种基于动态层级网络通信架构的通信强化学习协同策略,该策略能够显著减少无人机集群间的通信次数,同时准确传递其决策需要的信息,从而得到较优协同策略。针对多无人机协同围捕的典型任务场景,基于OpenAI平台对所提出的算法进行了仿真验证。结果表明,与传统强化学习算法相比,提出的通信强化学习策略可以显著减少无人机间的通信次数,同时在一定程度上避免潜在的信息欺骗问题。完成任务需要的平均通信次数相比于传统两两通信结构减少约 77%,为实现通信受限环境中的多无人机协同任务提供技术支撑。
1 引 言
随着人工智能技术的发展,空域无人作战正由“单平台遥控”向“多平台协同”转变[1]。由于单个无人机的载荷能力与探测能力有限,因而难以完成复杂的作战任务,无法满足日益增长的智能化作战需求。多无人机集群协同能够突破单个无人机的能力限制,通过信息共享与统一决策有效提升无人机的总体作战能力[2],从而实现多无人机集群自主协同搜索、协同围捕、协同打击等作战任务。在多无人机协同作战过程中,每架无人机作为一个智能体,共同构成多智能体系统。多智能体系统的目标是让若干个单智能体通过相互协作实现复杂智能,使得在降低系统建模复杂性的同时,提高系统的鲁棒性、可靠性、灵活性。
当前,多无人机在复杂环境下的不完全信息博弈决策问题已成为多无人机协同作战场景下亟待解决的前沿热点问题之一[3]。多无人机协同决策具有多智能体并存、多复杂任务、对抗实时性、动作持续性、信息不完全、搜索空间庞大等特点。近年来,以深度学习和强化学习为代表的人工智能技术取得了较大的突破,多智能体协同决策问题的解决方法逐渐从传统的基于预编程规则的方法转向以智能体自主强化学习为主的方法[4-5]。通过强化学习方法研究多无人机间的协同决策,能够为解决未来军事协同对抗问题提供新的有效途径。
多智能体强化学习场景根据任务目标可分为完全合作型、完全竞争型、混合型[6]。其中,在完全合作型中,智能体一般无法观测到环境中的所有状态信息,且所有智能体需要合作实现共同目标;在完全竞争型中,智能体一般分为两队,且两队智能体具有零和奖励函数,智能体一般考虑在最坏的情况下将对手尽力最小化,从而最大化自己的利益,经典算法有Minimax-Q等[7];在混合型中,智能体拥有各自独立的奖励函数且不受限制,常见方法主要有Nash Q-learning等[8]。近年来,多智能体强化学习主要聚焦于在部分可观环境下的完全合作型场景。在该设置下,多智能体强化学习算法的主要研究方向包括紧急行为分析[9]、值分解[10]、联合探索[11]等。
真实作战场景电磁环境复杂、通信容量有限,难以满足智能体海量节点实时全联通的需求。对于无人机集群而言,通信受限问题已成为限制其协同决策发展的关键瓶颈之一。传统强化学习算法无法有效处理通信受限环境中的协同决策需求。为此,一些学者提出了基于通信的多智能体强化学习算法。基于通信的多智能体强化学习算法主要解决多智能体系统中的部分可观测问题,试图使用显式的通信信道实现信息的共享。Foerster等[12]最先在深度多智能体强化学习中引入通信学习,提出了RIAL和DIAL两种使用深度网络学习离散通信信息的方法。Sukhbaatar等[13]提出了CommNet,在智能体之间构建了一个具备传输连续信息能力的通信通道,确保环境中任何一个智能体都可以实时传递信息。IC3NET[14]使用可学习的阀函数控制智能体是否参与本次通信,减少了智能体间不必要的通信频率。SchedNet[15]利用智能体根据自身观测生成的动态重要性权重进行排序,只选取最大的K个智能体进行通信,利用先验信息减少了通信次数。TarMAC[16]利用注意力机制计算智能体对其他智能体消息的权重,以此实现选择性的通信。GA-Comm使用游戏提取法,即基于软性注意力及硬性注意力提取智能体间的关系,结合双向LSTM网络实现更准确、高效的通信[17]。NDQ[17]通过限制信息熵、接收到的信息与动作信息,对信息质量进行优化,得到更加简短、高效的通信信息。IS[18]使用预测网络估计环境转移概率,并将智能体未来运动轨迹编码至通信信息中,实现智能体间的意图分享。然而,上述方法在多无人机协同决策中存在信息欺骗问题。
鉴于此,本文针对通信受限环境中的多无人机协同决策问题,提出了一种基于动态层级网络通信架构的通信强化学习协同策略。该策略能够显著减少无人机集群间的通信次数,同时准确传递其决策需要的信息,在一定程度上避免信息欺骗问题,从而得到较优协同策略。针对多无人机协同围捕的典型场景,基于 OpenAI平台对所提出的算法进行了仿真验证。
2 多无人机通信强化学习协同策略架构
本文基于动态层级网络设计多无人机强化学习协同策略,通过将多无人机系统建模为层级通信网络,在消息中融合观测及意图信息,实现选择性的观测共享和单边的意图分享,提升无人机对全局状态的信念并且实现更好的协作。在此基础上,引入线性值分解网络,将团队奖励分解为条件状态-动作函数值,实现更为准确的效用分配。同时,结合内在奖励的方法,设计基于策略不确定度的通信奖励,实现对有向层级网络的训练。
多无人机通信强化学习协同策略的整体架构如图1所示。将多无人机系统建模为动态可学习的有向层级网络,该网络被定义为包含了多组领导者-追随者树的森林。每棵树可以表示为节点和有向边的集合,其中N代表节点集合,E代表有向边集合。每个节点代表了一个无人机,有向边则描述了无人机间的领导者-追随者关系。通过限制意图仅能沿着有向边单向流动,有向层级网络保证了单边的意图分享,从而在一定程度上减少了信息传递过程中潜在的信息欺骗,并缓解了通信过程中的环境非稳态问题。
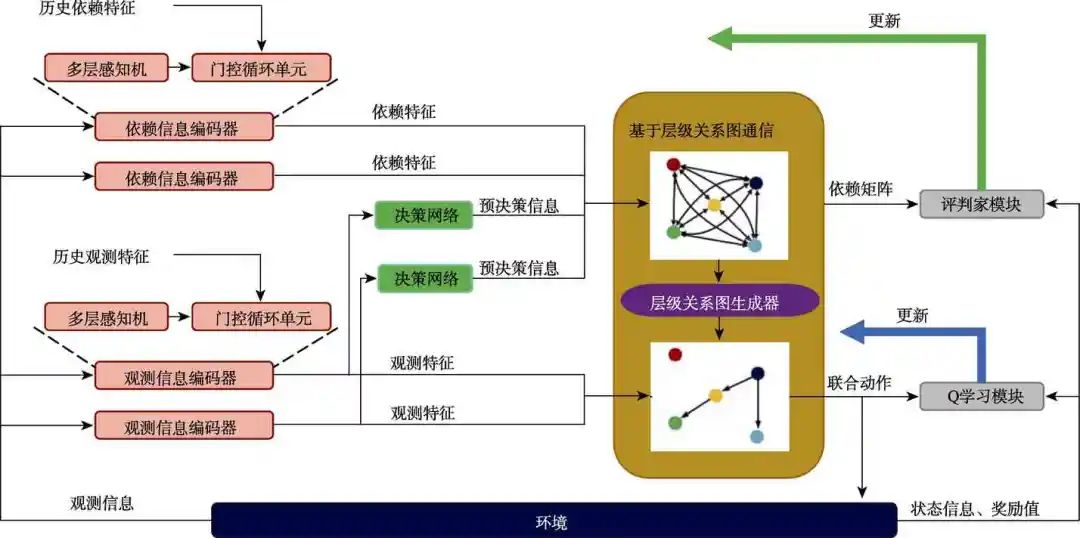
图1 基于层级通信网络的多无人机协同策略示意图
Fig.1 Schematic diagram of multi-UAV cooperation strategy based on hierarchical communication network
在每个决策时间步,每个无人机收到各自的局部观测信息后,经过观测信息编码器和依赖信息编码器,将其转化为观测特征和依赖特征。每个无人机根据其观测特征进行预决策,将预决策信息和依赖特征进行融合,利用融合特征计算无人机间的相关性,获得带权重的全连接图。之后,基于最小生成树算法的层级关系图生成器将带权重的全连接图转化为能够表示无人机间领导者-追随者的有向层级关系图。根据生成的有向层级关系图,无人机根据其领导的决策信息依次做出决策,并将其意图信息分享给追随无人机,直至所有的无人机均做出决策。多无人机执行联合动作并与环境交互,获得团队奖励,并将状态、动作、下时刻状态、奖励、预决策等信息存入经验回放池。
训练时,将多无人机系统视为一个整体,使用单无人机的训练方法优化联合动作价值函数及层级通信网络。联合动作价值函数是由各个无人机的观测动作值函数加和计算得到的,因此不仅可以适应动态变化的无人机数目及异构的多智能体类型,保证算法的可扩展性,同时由于所有无人机使用团队奖励,可以更好地实现多无人机的协作任务。具体的,根据每个无人机的状态-动作函数值及其执行动作,利用线性值分解网络计算团队状态-动作值,使用 Q学习模块完成智能体策略的更新。另一方面,根据无人机策略在通信前后的不确定性变化及环境奖励,设计内在通信奖励,基于深度确定性梯度下降方法,实现对动态有向层级关系图的训练。算法1展示了基于层级通信网络的多无人机强化学习算法的完整流程。该算法能够解决由于可能的信息欺骗所导致的错误合作,同时单边通信在一定程度上减少了通信次数,提升了基于通信的多无人机强化学习算法的性能。
3 基于动态层级通信的多无人机协同策略
3.1 层级通信网络与单边意图分享
根据无人机智能体间的相互依赖关系,可以使用基于最小生成树的有向图生成算法,实现全连接图向层级通信网络的转变。首先,基于依赖矩阵 d
w计算每个节点的流入流出值,即无人机的相对依赖程度

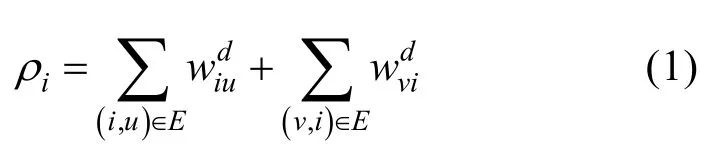
式中,u,v是除去 i以外的其他节点。由于我们采用了软性注意力机制计算依赖矩阵,因此实际上
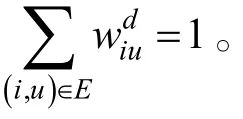
根据无人机相对依赖程度,我们可以选出更适合作为领导者的无人机:相对依赖程度越大,其越能影响其他无人机的决策,而越不受到其他无人机的影响。
基于最小生成树算法,本文提出了层级通信网络生成算法。首先,根据无人机的相对依赖程度ρi选出最大值对应的无人机作为根节点,将其建立在有向图中。之后,找到在 w d中拥有最大的边权重wij的无人机i,其中 i ∈ N r = ( N /Nnew),j∈N n ew。判断wij是否为从无人机i流出的最大边。如果是,则将其建立在有向图中,作为无人机 j的子节点;如果不是,则拒绝该节点的加入,再从未使用的无人机集合Nr中,根据无人机的相对依赖程度ρi选出最大的值对应的无人机作为根节点。重复上述操作,直至所有的无人机均被建立在有向图中,并生成最终的层级通信网络。同时,如果无人机的组数,即层级有向图的树木棵树是给定的,我们可以使用Top(k)方法直接选取n个根节点,且不使用拒绝机制,从而简化树的建立过程。级通信网络生成具体步骤如算法 2所示。在实际执行过程中,我们可以根据实际通信所需时间计算出层级网络中树的最大深度d,将超过此深度的节点进行剪枝,将其挂在前d层的父节点上,以此实现带有深度约束的层级通信网络,满足通信时间需求。

在通信过程中,无人机收到由其他无人机的观测信息h-i和意图信息u-i组成的通信信息mi。之后,无人机通过一个自注意力模型,将来自其他无人机的观测信息进行选择性接收,获得融合观测信息

式中, w isj表示自注意力模型中无人机i对无人机j发送的信息占融合观测信息的权重。同时,无人机根据其在层级关系图中的层数,获取其领导者的决策信息
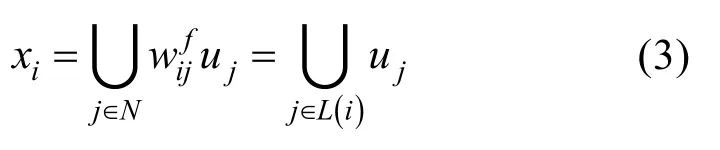
式中,L(i)表示无人机i的领导人,即其在层级通信网络中的所有祖先节点。最终,无人机根据自身观测信息及聚合信息 a ggri =[c i , xi ]做出最终决策
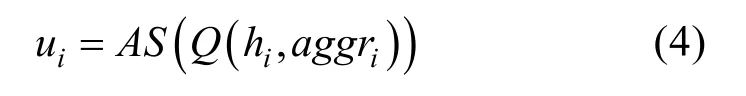
最终,无人机i将其意图信息发送给其追随者,并在当前决策步中保持不变。循环此过程,直至所有的无人机都完成了通信任务。
3.2 条件状态-行为值分解及策略网络训练
在线性值分解网络 VDN和单调值分解网络QMIX等SOTA效用分配算法中,由于相对过度泛化问题,其在部分任务的性能极差。在博弈论中,相对过度泛化问题是指当联合行动空间中的次优纳什均衡优于最优纳什均衡。在该状态下,次优均衡中每个智能体的行动与合作智能体的任意行动组成的联合动作均为最优动作,从而导致无人机学习及协作的失败。
解决该问题的一个思路是引入无人机的策略信息,即使用无人机的动作信息减少环境的非稳态性,利用一种集中式的训练方式来寻找正确的全局最优点。在我们的方法中,由于使用了层级有向的意图分享,追随者能够获得其领导者的策略信息,进而生成条件状态-行为函数值。于是,基于条件状态-行为函数值的线性分解网络
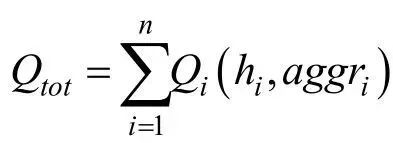
可以减少由于其他无人机变化策略带来的环境非稳态问题。
层级通信网络的结构在策略生成过程中也起到了至关重要的作用。层级通信网络控制了无人机的领导者,即影响了其接收到的其他无人机策略信息。同时,层级通信网络的生成过程中失去了训练所需要的梯度,但具有梯度的输入依赖矩阵 w d 和层级通信网络 w f之间是多对一的关系。因此,我们将层级通信网络 w f视为一个偏置项,同时利用集中式训练的优势,结合环境的真实状态信息,以此提高训练的稳定性。于是,策略的更新式可以写作
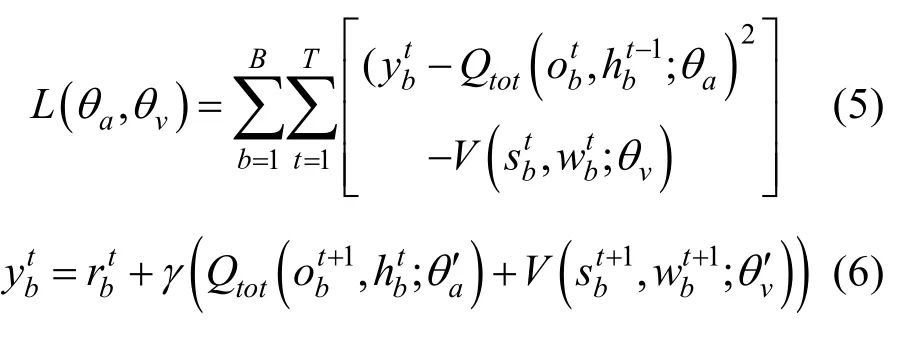
式中, 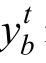 表示联合状态-动作目标值,V表示层级关系网络的值函数,B表示批采样得到的轨迹总数,b表示批采样中的轨迹标识,T表示当前轨迹的时间步总数,t表示强化学习时间步,γ表示奖励折扣因子,
表示联合状态-动作目标值,V表示层级关系网络的值函数,B表示批采样得到的轨迹总数,b表示批采样中的轨迹标识,T表示当前轨迹的时间步总数,t表示强化学习时间步,γ表示奖励折扣因子,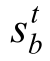 表示t时刻环境状态, w bt表示智能体间的有向图关系,θa表示智能体网络参数,θv表示层级关系网络的值函数网络参数,θa′表示智能体网络目标参数,θv′表示层级关系网络的值函数目标网络参数。
表示t时刻环境状态, w bt表示智能体间的有向图关系,θa表示智能体网络参数,θv表示层级关系网络的值函数网络参数,θa′表示智能体网络目标参数,θv′表示层级关系网络的值函数目标网络参数。
3.3 内在奖励及层级通信网络训练
为生成动态变化的层级通信有向图,我们需要使得其成为可训练的网络。然而,在层级通信网络的生成过程中,我们使用的最小生成树方法无法实现梯度反传。但是,如果给定了一个依赖矩阵 w d ,层级通信网络 w f是确定的。因此,我们可以将 w f视为经过了动作选择器的动作信号,而其对应的策略网络输出为 w d = a =φ(o)。该策略网络将无人机观测信息映射到依赖特征上。于是,层级通信网络被建模为了一个强化学习过程,可以通过深度确定性梯度下降的方式进行更新。
在学习过程中,我们需要获得能够指导更新大小和幅度的奖励信号。基于内在奖励方法,我们为层级通信网络的训练设计了通信奖励。一方面,无人机在接收到其他无人机的意图信息后,其策略的不确定性应当减小。我们使用无人机状态-行为函数值最大的前两项的方差作为无人机对自身决策信心的评价标准。因此,内在奖励可以表示为通信前后所有无人机决策信心的变化
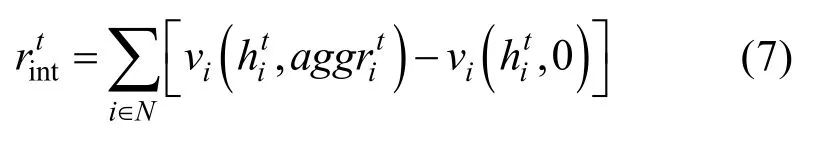
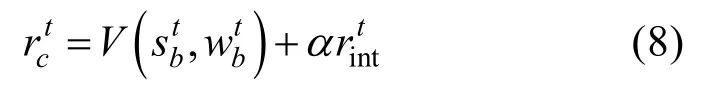
式中,α为调节内在奖励和外在建立的权重因子。依赖矩阵的更新式为
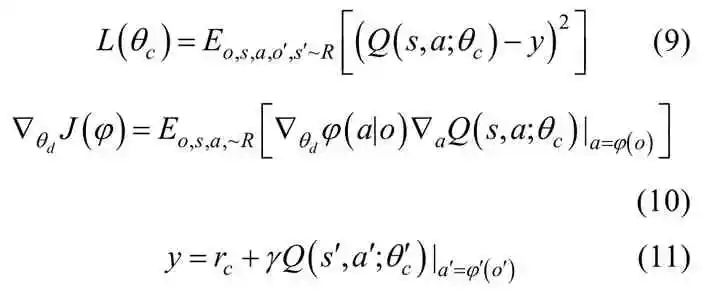
另一方面,层级通信网络的最终目标仍然是最大化无人机决策的累计回报。于是,我们可以最终获得通信奖励
式中,Q表示层级关系网络的状态-动作值,y表示层级关系网络的状态-动作目标值,cθ表示Critic网络的参数,cθ′表示Critic目标网络的参数,dθ表示Actor网络的参数。
4 多无人机协同场景设计及仿真验证
4.1 多无人机协同任务场景设计
本文针对多无人机协同围捕场景,采用捕食者-被捕食者强化学习训练平台对本文算法进行仿真验证。捕食者-被捕食者仿真环境为一个部分可观测多智能体协作任务环境,环境共初始化 8个捕食者(智能体)和8个被捕食者(猎物),分别模拟我方和敌方的无人机群。在该场景中,每个智能体的动作空间中有“上移”“下移”“左移”“右移”“静止”和“打击”6个动作,当选择移动的目标位置被其他智能体或猎物占领时所选的动作会被判定为无效动作,当相邻网格中没有猎物时不可以选择“打击”动作。环境中猎物随机选取一个方向移动,当4个相邻网格都被其他智能体占领时保持静止。每个智能体的观测信息为以其所在位置为中心的5×5网格。两个相邻的智能体同时进行“打击”动作,视为打击成功,并获得奖励值10,一个智能体单独执行“打击”动作则会受到惩罚p(p≤0)。实验目标为:通过8个捕食者无人机协同决策,完成对8个被捕食者无人机的全部打击。当所有被捕食者无人机都被成功“打击”或达到200个时间步,则判定任务结束。基于上述场景,分别对本文算法和当前主流通信强化学习算法进行仿真验证,对比不同算法间的决策效果以及完成任务所需要的平均通信次数。
4.2 仿真结果
图2给出了本文算法与基于通信的SOTA多无人机强化学习算法在捕食者-被捕食者平台上的性能对比结果。在仿真测试中,分别取惩罚值p= -1、-1.25、-1.5和-2。可以看到,CommNet、TarMAC和GA-Comm随着惩罚值p的减小而逐渐变得不稳定,甚至在p= -2时完全无法完成任务。CommNet在 p≤-1.25后就开始无法完成任务,说明冗余的通信信息可能会损害多智能体协作的性能。由于 NDQ使用互信息减小了环境的非稳态问题,因此具有学习到正确策略的潜力。虽然IS也进行了意图共享,但是其中的软性注意力机制并无法让其获得准确的智能体间关系,从而间接证明了任务中可能存在信息欺骗,且该问题会导致算法的失效。作为对比,我们提出的算法在不同的环境设置下均能很快学习到正确的策略并保持稳定,证明了基于层级通信的网络结构的有效性。
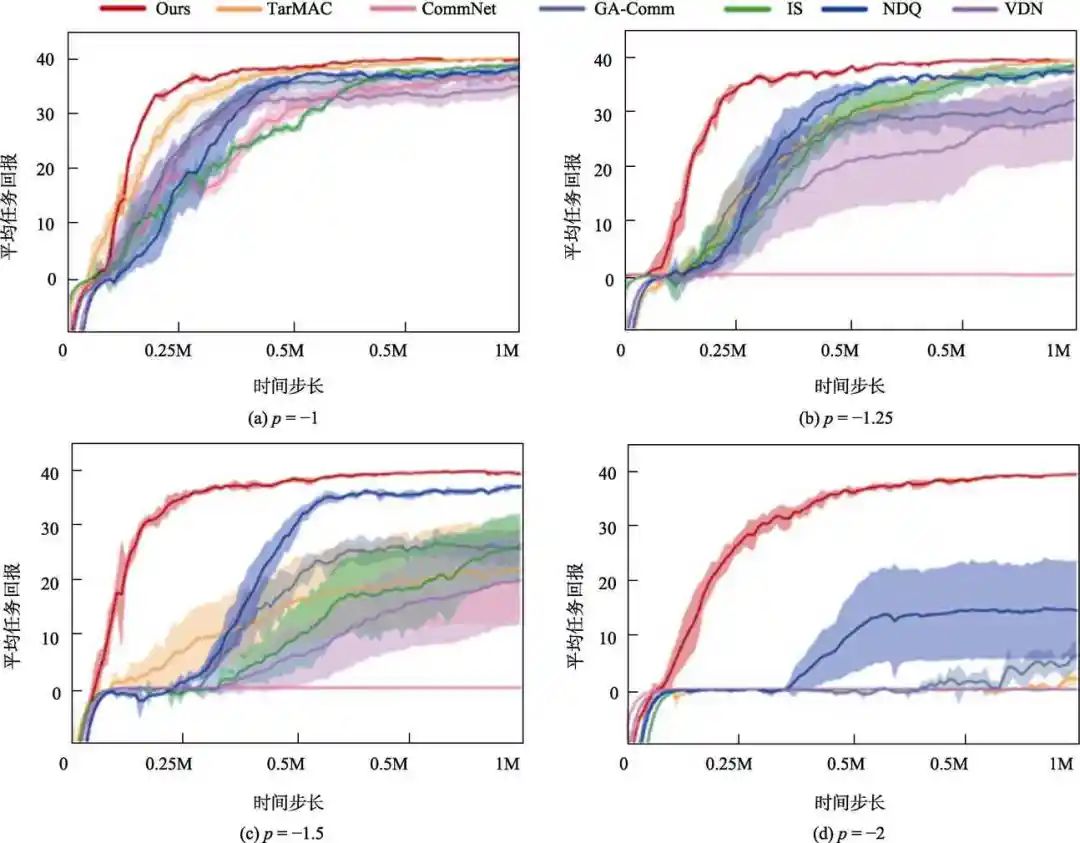
图2 不同基于通信的多智能体强化学习算法的性能对比
Fig.2 Performance comparison of different communication based multi-agent reinforcement learning algorithms
进一步地,将本文提出的算法与其他预先设定好的通信拓扑结构或关系生成算法进行对比。设置任务场景的惩罚值p= -2.25,结果如图3所示。可以看到,现有的关系生成算法均不能快速地学会最优策略,而预设的拓扑结构Line则能够快速地学习到正确的策略。与之相比,本文算法在算法前期上升较慢,这是由于算法需要学习合适的层级通信网络,这一过程较为复杂和耗时。但是,在算法后期的收敛状态,能够看到本文学习算法性能优于预设拓扑结构。同时,本文算法可以实现稀疏通信,比预设的Line型拓扑结构运行效率更高,能够高效、准确地完成任务。
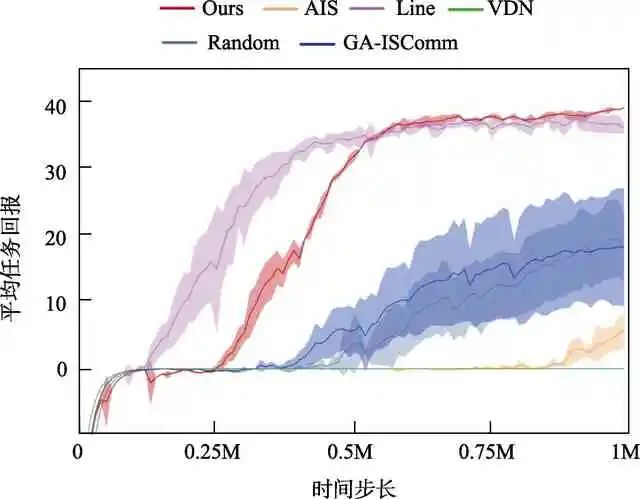
图3 不同通信拓扑结构对意图分享的影响Fig.3 Influence of different communication topologies on intention sharing
此外,在仿真环境下分别进行 20轮独立试验,得到完成任务过程中本文提出的层级通信结构和传统两两通信结构下的平均通信次数,如表1所示。结果表明,本文的动态层级通信结构的平均通信次数为 5.8次,传统两两通信结构的平均通信次数为25.9次,本文提出的基于动态层级通信结构的多无人机协同策略完成任务需要的平均通信次数减少约77%。
表1 不同通信拓扑结构下的平均通信次数Table 1 Average communication times under different communication topologies

5 结束语
本文针对通信受限环境中的多无人机协同决策问题,提出一种基于动态层级网络通信架构的通信强化学习协同策略。通过将多无人机系统建模为层级通信网络,提升无人机对全局状态的信念;在此基础上引入线性值分解网络,实现更为准确的效用分配。针对多无人机协同围捕场景的仿真结果表明,与传统强化学习算法相比,本文提出的通信强化学习策略可以显著减少无人机间的通信次数,同时在一定程度上避免潜在的信息欺骗问题,完成任务需要的平均通信次数相比于传统两两通信结构减少约77%。本文所提出的基于动态层级网络通信架构的多无人机通信强化学习协同算法可为通信受限环境中的多无人机协同任务提供技术支撑,未来将考虑把该算法迁移到物理环境以验证其在真实场景中的有效性,并进一步探索其在体系化作战决策方面的应用可能。另一方面,本文尚未对通信拒止环境下的多无人机协同策略进行探讨,未来将考虑开展基于隐式信息共享的协同方法研究,进一步探索通信拒止环境下的多无人机协同策略与方法。
编辑:黄飞
- 相关推荐
- 热点推荐
- 无人机
-
[Optiwave] OptiSystem应用:无人机(UAV)中继通信系统仿真2026-06-01 65
-
无人机开发方案要领与电路图集锦2015-05-07 10522
-
【云智易申请】智能无人机通信2015-08-07 2958
-
【秀秀资源】无人机相关资料合集2017-02-15 5415
-
无人机类型之植保无人机,带你了解什么是植保无人机?2019-06-28 3833
-
航模/无人机遥控的解决方案2020-07-03 3481
-
无人机租赁服务成发展新方向2020-08-20 4043
-
多无人机环保监测任务调度2017-12-22 1620
-
中国无人机市场很好吗2019-06-24 1666
-
多无人机协同编队飞行控制的关键技术和发展展望2020-07-26 10837
-
多无人机局部地图数据共享融合的SLAM方法2021-06-02 1854
-
基于改进一致性的多无人机编队控制算法2021-06-22 1143
-
基于无线自组网的多无人机系统解决方案2022-03-02 2950
-
无人机宽带自组网技术分析2023-05-19 2980
-
无人机自组网关键技术有哪些2023-08-28 5008
全部0条评论

快来发表一下你的评论吧 !
