

数学模型如何捕获真实世界的信号失真
描述
本文介绍数字预失真(DPD)的数学基础,以及如何在收发器的微处理器和硬件中实现它。它解决了现代通信系统需要DPD的原因,并探讨了数学模型如何捕获真实世界的信号失真。
介绍
DPD 是许多 RF(射频)工程师、信号处理爱好者和嵌入式软件开发人员熟悉的首字母缩略词。DPD在我们的蜂窝通信系统中无处不在,使功率放大器(PA)能够有效地为天线提供最大功率。随着5G推动基站的天线数量增加,我们的频谱变得越来越拥挤,DPD已成为一项关键技术,允许开发高效,具有成本效益和规范兼容的蜂窝系统。
我们中的许多人根据自己的观点对DPD有独特的理解,无论是从纯数学角度还是从微处理器上更受约束的实现。也许您是一名评估RF基站产品中DPD性能的工程师,或者对数学建模技术如何在现实世界系统中实现感到好奇的算法开发人员。本文旨在拓宽您的知识面,使您能够从各个角度充分掌握该主题。
什么是DPD,为什么使用它?
当RF信号从基站无线电输出时(见图1),在通过天线传输之前需要放大。射频PA用于执行此操作。在理想情况下,PA接受输入信号并输出与其输入成比例的更高功率信号。它还以最节能的方式做到这一点,以便将提供给放大器的大部分直流电源转换为信号输出功率。

图1.带和不带DPD的简化无线电结构框图。
然而,这不是一个理想的世界。PA由晶体管制成,晶体管是有源器件,本质上是非线性的。现在,如果我们在PA的“线性”区域使用PA(此处为线性是一个相对术语;因此为引号),如图2所示,则输出功率与输入功率相对成正比。这种方法的缺点是PA通常在非常低效的状态下使用,提供的大部分功率都以热量的形式损失。我们经常希望在PA开始压缩时使用它们。这意味着,如果输入信号增加设定量(例如3 dB),PA输出不会增加相同的量(可能仅增加1 dB)。显然,此时信号被放大器严重失真。

图2.PA输入功率与输出功率的关系图(显示采样输入/输出信号的投影)。
这种失真发生在频域中的已知位置,具体取决于输入信号。图3显示了这些位置以及基频与这些失真产物之间的关系。在RF系统中,我们唯一需要补偿的失真是那些接近基波信号的失真,即奇阶互调产物。系统中的滤波负责带外产物(谐波甚至阶次交调产物)。图4显示了RF PA在其压缩点附近运行的输出。互调产物(尤其是三阶)清晰可见。它们看起来像所需信号周围的“裙子”。

图3.2 音输入的互调和谐波失真位置。
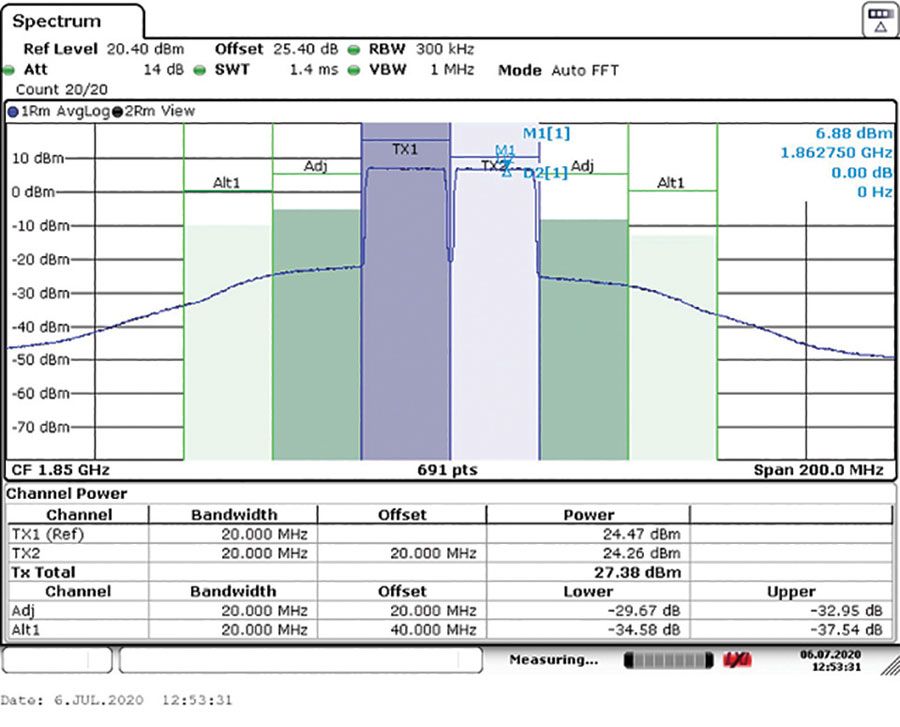
图4.2× 20 MHz载波通过SKY66391-12射频PA。中心频率 = 1850 MHz。
DPD旨在通过观察PA输出来表征这种失真,并在知道所需的输出信号后改变输入信号,使PA输出更接近理想值。这只有在相当具体的情况下才能有效地完成。我们需要配置放大器和输入信号,使放大器有所压缩,但不会完全饱和。
PA 失真建模背后的数学原理
看到希腊字母和其他数学符号是否往往会带来对过去大学考试的可怕闪回?你并不孤单!当人们得到的第一个参考文献是一篇数学繁重的学术论文时,人们可能会不必要地被基础知识所推迟。论文“RF功率放大器数字预失真的广义记忆多项式模型”1是一项开创性的工作,介绍了广泛采用的广义记忆多项式 (GMP) 方法 DPD。如果您只是涉足信号处理方面的事情,那么介绍该主题可能会有点沉重。因此,作为开始,让我们尝试分解GMP方法,并更直观地理解数学正在做什么。
Volterra系列是DPD的数学支柱。它用于用内存对非线性系统进行建模。内存只是意味着系统的当前输出可以依赖于当前和过去的输入。Volterra系列非常通用(因此功能强大),用于电气工程以外的许多领域。对于PA DPD,Volterra系列可以精简,使其在实时数字系统中更具可实施性和稳定性。GMP就是这样一种瘦身的方法。
图 5 描述了如何使用 GMP 对 PA 的输入 x 与其输出 y 之间的关系进行建模。您将看到等式的三个独立求和块彼此非常相似。让我们专注于下面以红色突出显示的第一个。|x(。..)|k项称为输入信号的包络,其中 k 是多项式阶。l 将内存整合到系统中。如果 L一个= {0,1,2},则模型允许输出 y药品监督管理总局(n) 取决于当前输入 x(n) 和过去的输入 x(n – 1) 和 x(n – 2)。图 6 检查了多项式阶数 k 对样本向量的影响。矢量x是单个20 MHz载波,绘制在复基带上。通过去除内存组件简化了GMP建模公式。x|x的图|k与图4中可见的真实失真有明显的相似之处。
每个多项式阶数 (k) 和内存滞后 (l) 都有一个相关的复权重 (a吉隆坡)。当选择了模型的复杂性(将包括k和l的值)时,有必要根据对已知输入信号的PA输出的实际观察来求解这些权重。图 7 将简化的方程转换为矩阵形式。使用的数学符号允许对模型进行简洁的表示。但是,对于DPD在数字数据缓冲区上的实际实现,以矩阵表示法查看事物是最简单且更具代表性的。
让我们简要看一下图 6 中公式的第二行和第三行,为简单起见,忽略了它们。请注意,如果 m 设置为零,则这些行将与第一行相同。这些线路允许在包络项和复基带信号之间添加延迟(正和负)。这些称为滞后和前导交叉项,可以显着提高DPD的建模精度。它们为我们尝试模拟放大器的行为提供了额外的自由度。请注意,Mb, Mc, Kb和 Kc不包含零;否则,我们将重复第一行中的术语。

图5.用于模拟PA失真的GMP。1

图6.阶数 (k) 对信号 x 频域中信号的影响图。

图7.将简化的公式转换为数据缓冲区上的矩阵运算(更接近数字实现方式)。
那么我们如何确定模型的顺序、记忆项的数量以及我们应该添加哪些交叉项呢?这就是一定数量的“黑魔法”进入事物的地方。在某种程度上,我们可以从我们对失真物理学的知识中获得指导。放大器的类型及其制造材料以及通过它播放的信号带宽都会影响建模术语,并允许在该领域有经验的工程师对应该使用哪种模型进行限制。但是,在此之上还涉及一定程度的试验和错误。
从数学角度要解决的问题的最后一个方面,既然有建模结构可用,是如何求解加权系数。在实际场景中,倾向于求解上述模型的逆函数。事实证明,这些模型系数有一个很好的互惠性,因为相同的权重可用于对捕获的PA输出矢量进行后失真,以消除非线性,并对通过PA发送的传输信号进行预失真,使PA输出看起来尽可能线性。图8显示了如何进行权重系数估计和预失真的框图。

图8.描述建模和预失真间接实现的框图。
对于逆模型,将图 7 中给出的矩阵方程交换,得到 X̂ = Yw。此处矩阵 Y 的形成方式与 X 在另一种情况下的形成方式相同,如图 9 所示。对于此示例,已包含内存项,并且已减少包含多项式阶数。为了求解w,我们需要得到Y的逆,Y不是正方形的(它是一个高而细的矩阵),所以这是使用矩阵“伪逆”来实现的(见公式1)。这在最小二乘意义上求解了 w,也就是说,它最小化了 X̂ 和 Yw 之间差的平方,这就是我们想要的!

这可以进一步完善,以考虑到它正在具有不同信号的实时环境中应用。在这里,系数通过从其先前的值更新来约束。μ 是一个介于 0 和 1 之间的常量值,用于控制每次迭代权重可以更改的程度。如果 μ = 1 且 w0= 0,则此方程立即恢复为基本最小二乘解。如果μ设置为小于 1 的值,则系数需要多次迭代才能收敛。

请注意,此处描述的建模和估计技术并不是执行DPD的唯一方法。也可以使用基于动态偏差减少 (DDR) 的建模等技术来代替或补充它。描述的用于求解系数的估计技术也可以通过多种方式完成。鉴于这是一篇短文而不是一本书,让我们把它留在那里。
我们如何在微处理器中实现这一点?
好的,数学已经完全涵盖了。下一个问题是它如何应用于现实世界的通信系统?它在数字基带中实现,通常在微处理器或FPGA中实现。ADI公司的RadioVerse收发器产品(如ADRV902x系列)内置微处理器内核,其结构经过专门设计,可轻松实现DPD。®

图9.矩阵形式的逆接近方程。此处包含了一些内存。

图 10.具有一个记忆抽头和一个三阶交叉项元件的三阶情况的预失真计算。
嵌入式软件中的DPD实现有两个不同的方面。第一个是DPD执行器,它是实时执行实时传输数据的预失真的地方,第二个是DPD自适应引擎,它是根据PA输出的观察结果更新DPD系数的地方。
如何在微处理器或类似处理器中实时实现DPD和许多其他信号处理概念的关键是通过使用查找表(LUT)。LUT 允许用更简单的数组索引操作代替昂贵的运行时计算。让我们考虑DPD执行器如何将预失真应用于传输的数据样本。符号如图 8 所示,其中 u(n) 是要传输的数据的原始样本,x(n) 是预失真版本。图 10 显示了在给定场景中获得一个预失真样本所需的计算。这是一个相对有限的示例,最高多项式阶数为三阶,只有一个记忆抽头和一个交叉项。即使对于这种情况,显然也需要大量的乘法、幂和加法计算来获得这一个数据样本。
这就是LUT可以减轻实时计算负担的地方。图10可以改写为图11,其中将在LUT中输入的数据变得更加明显。每个LUT都包含|u(n)|的大量可能值的公式中突出显示的元素的结果。分辨率取决于可在可用硬件中实现的LUT的大小。电流输入样本的幅度根据LUT的分辨率进行量化,并用作索引,以访问给定输入的正确LUT元件。

图 11.重新组合方程元素以显示LUT的结构。
图12显示了如何将LUT集成到我们示例案例的完整预分配执行器实现中。请注意,这只是众多可能实现中的一个。在保持相同输出的同时可以进行更改的一个例子是延迟元素 z–1,可以移动到 LUT2 的右侧。

图 12.使用 LUT 可能实现 DPD 的框图。
自适应引擎的任务是求解用于计算执行器中LUT值的系数。这涉及求解方程1和2中描述的w向量。伪逆矩阵运算,(YHY)-1YH,计算量很大。等式 1 可以改写为

如果 CYY= YHY 和 CYx= YHx,则等式 3 变为

CYY是一个方阵,可以分解为上三角矩阵L及其共轭转置(CYY=LHL)使用乔列斯基分解。这允许我们通过引入一个虚拟变量 z 并求解它来求解 w,如下所示:

然后将这个虚拟变量替换回去以求解

因为L和LH分别为上三角矩阵和下三角矩阵,公式5和公式6易于求解,计算费用最低,得到w。每次运行自适应引擎并找到 w 的新值时,都需要更新执行器 LUT 以反映它们。自适应引擎可以根据对PA输出的观察或操作员对要传输的信号变化的了解,以设定的定期间隔或更不规则的间隔执行。
在嵌入式系统中实现DPD需要大量的制衡,以确保系统的稳定性。传输的数据缓冲区和捕获缓冲区数据在时间上对齐至关重要,以确保它们之间建立的数学关系是正确的,并且在随着时间的推移应用时成立。如果失去这种对齐,则自适应引擎返回的系数将无法正确预扭曲系统,并可能导致系统不稳定。还应检查预失真的执行器输出,以确保信号不会使DAC饱和。
结论
希望本文通过检查底层数学及其在硬件中的实现,解开了DPD的一些谜团。这只是这个迷人主题的冰山一角,可能会促使读者进一步研究信号处理技术在通信系统中的应用。Pratt和Kearney的研究是关于DPD应用于有线通信系统中超宽带宽用例的良好来源。2ADI公司的RadioVerse收发器产品具有独特的优势,可集成DPD等算法,为客户提供高度集成的RF硬件和可配置的软件工具。
审核编辑:郭婷
-
永磁同步电机的数学模型2023-03-14 1110
-
永磁同步电机--数学模型2023-01-12 4713
-
交流电机数学模型与坐标变换2021-09-28 1008
-
电机的数学模型与仿真分析2021-05-19 1151
-
多电机数学模型推导2019-09-09 2187
-
自动控制原理matlab仿真实验之系统的数学模型2018-11-20 1260
-
系统辨识数学模型及常用输入信号2017-08-13 1588
-
第2章系统辨识数学模型及常用输入信号2017-06-12 1386
-
算法大全_模糊数学模型2016-01-14 693
-
运行特性和数学模型2013-04-10 2470
-
最佳捕鱼策略的数学模型2009-09-16 892
-
什么是数学建模,怎样建立数学模型2009-09-15 41999
-
控制系统的数学模型2009-01-08 811
全部0条评论

快来发表一下你的评论吧 !
