

在 NGC 上玩转新一代推理部署工具 FastDeploy,几行代码搞定 AI 部署
描述
号外:
全场景高性能 AI 部署工具
FastDeploy 发版 v1.0
几行代码搞定 AI 部署,快速使用 150+ 预置部署示例,支持 CV、NLP、Speech、Cross-model 模型,并提供开箱即用的云边端部署体验,实现 AI 模型端到端的推理性能优化。
欢迎广大开发者使用 NVIDIA 与飞桨联合深度适配的 NGC 飞桨容器,在 NVIDIA GPU 上进行体验 FastDeploy!
全场景高性能 AI 部署工具 FastDeploy
人工智能技术在各行各业正加速应用落地。为了向开发者提供产业实践推理部署最优解,百度飞桨发起了 FastDeploy 开源项目。FastDeploy 具备全场景、简单易用、极致高效三大特点。
(1)简单易用:几行代码完成 AI 模型的 GPU 部署,一行命令切换推理后端,快速体验 150+ 热门模型部署
FastDeploy 精心设计模型 API,不同语言统一 API 体验,只需要几行核心代码,就可以实现预知模型的高性能推理,极大降低了 AI 模型部署难度和工作量。一行命令切换 TensorRT、Paddle Inference、ONNX Runtime、Poros 等不同推理后端,充分利用推理引擎在 GPU 硬件上的优势。
import fastdeploy as fd
import cv2
option = fd.RuntimeOption()
option.use_gpu()
option.use_trt_backend() # 一行命令切换使用 TensorRT部署
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml",
runtime_option=option)
im = cv2.imread("test.jpg")
result = model.predict(im)
FastDeploy 几行命令完成 AI 模型部署
FastDeploy 支持 CV、NLP、Speech、Cross-modal(跨模态)四大 AI 领域,覆盖 20 多主流场景、150 多个 SOTA 产业模型的端到端示例,包括图像分类、图像分割、语义分割、物体检测、字符识别(OCR)、人脸检测、人脸关键点检测、人脸识别、人像扣图、视频扣图、姿态估计、文本分类、信息抽取、文图生成、行人跟踪、语音合成等。支持飞桨 PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR、PaddleNLP、PaddleSpeech 6 大热门 AI 套件的主流模型及生态(如 PyTorch、ONNX 等)热门模型的部署。
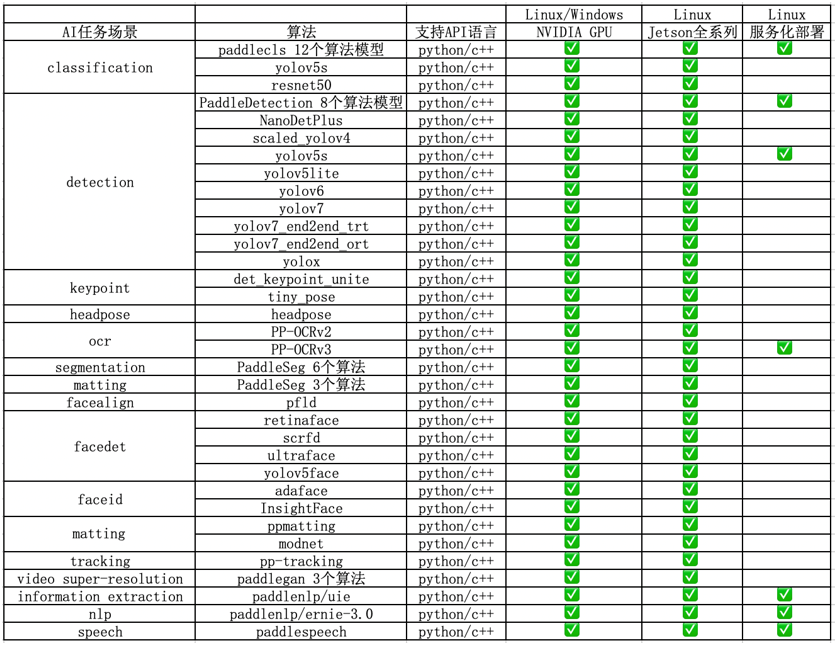
FastDeploy 在 NVIDIA GPU、Jetson上的 AI 模型部署库
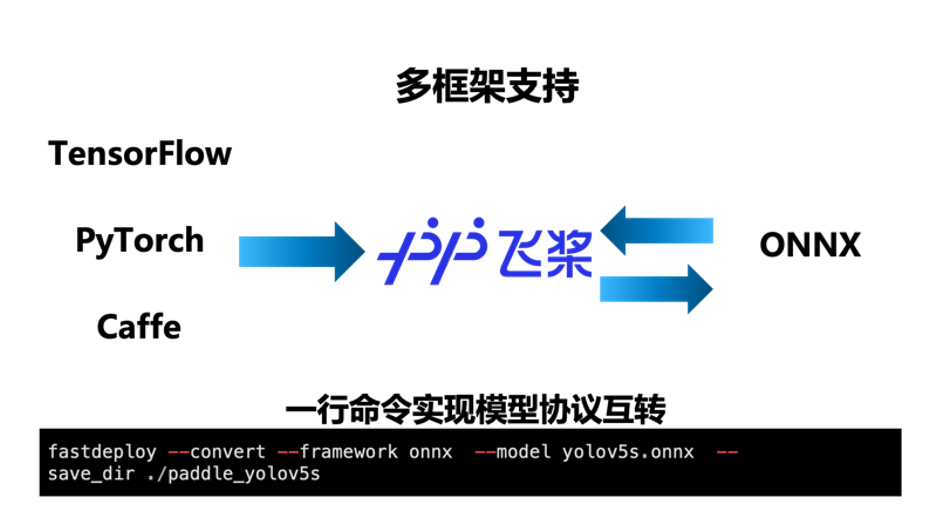
(2)全场景:支持多框架,轻松搞定 PaddlePaddle、PyTorch、ONNX 等模型部署
FastDeploy 支持 TensorRT、Paddle Inference、ONNX Runtime、Poros 推理引擎,统一部署 API,只需要一行代码,便可灵活切换多个 GPU 推理引擎后端。内置了 X2Paddle 和 Paddle2ONNX 模型转换工具,只需要一行命令便可完成其他深度学习框架到飞桨以及 ONNX 的相互转换,让其他框架的开发者也能通过 FastDeploy 体验到飞桨模型压缩与推理引擎的端到端优化效果。覆盖 GPU、Jetson Nano、Jetson TX2、Jetson AGX、Jetson Orin 等云边端场景全系列 NVIDIA 硬件部署。同时支持服务化部署、离线部署、端侧部署方式。
(3)极致高效:一键压缩提速,预处理加速,端到端性能优化,提升 AI 算法产业落地
FastDeploy 集成了自动压缩工具,在参数量大大减小的同时(精度几乎无损),推理速度大幅提升。使用 CUDA 加速优化预处理和后处理模块,将 YOLO 系列的模型推理加速整体从 41ms 优化到 25ms。端到端的优化策略,彻底解决 AI 部署落地中的性能难题。更多性能优化,欢迎关注 GitHub 了解详情。
https://github.com/PaddlePaddle/FastDeploy
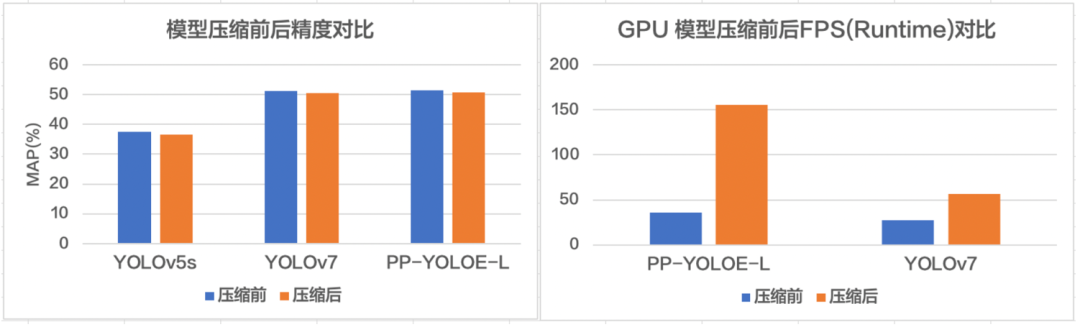
FastDeploy 一行命令实现自动压缩,充分利用硬件资源提升推理速度

FastDeploy 提升 AI 任务端到端推理速
直播预告:服务化部署高并发调优实战
12 月 12 日 - 12 月 30 日,《产业级 AI 模型部署全攻略》系列直播课程,FastDeploy 联合 10 家硬件公司与大家直播见面。
12 月 14 日 20:30 开始,NVIDIA 与百度资深专家将为大家带来以“一键搞定服务化部署,实现稳定高并发服务”为主题的精彩分享,详细解说 FastDeploy 服务化部署实战教学,以及如何提升 GPU 利用率和吞吐量!欢迎大家扫码报名获取直播链接,加入交流群与行业精英深度共同探讨 AI 部署落地话题。
一键搞定服务化部署
实现稳定高并发服务

12 月 14 日,星期三,20:30
精彩亮点
-
企业级 NGC 容器,快速获取强大的软硬件能力
-
三行代码搞定 AI 部署,一键体验 150+ 部署 demo
-
服务化部署实战教学,提升 GPU 利用率和吞吐量
会议嘉宾

Adam | NVIDIA 亚太区资深产品经理

Jason|百度资深研发工程师
参与方式

扫码报名获取直播链接
原文标题:在 NGC 上玩转新一代推理部署工具 FastDeploy,几行代码搞定 AI 部署
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 英伟达
-
添越智创基于 RK3588 开发板部署测试 DeepSeek 模型全攻略2025-02-14 2859
-
介绍一款基于昆仑芯AI加速卡的高效模型推理部署框架2023-10-17 3557
-
Ai 部署的临界考虑电子指南2023-08-04 888
-
基于凌蒙派开发板的FastDeploy适配2023-02-16 2844
-
【RK3588平台】使用飞桨FastDeploy进行AI部署2023-01-11 4165
-
昆仑芯科技产业级AI模型部署全攻略2022-12-28 3007
-
在 NVIDIA NGC 上搞定模型自动压缩,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.222022-11-15 2027
-
三行代码完成AI模型的部署!2022-11-10 2660
-
低门槛AI部署工具FastDeploy开源!2022-11-08 3840
-
嵌入式边缘AI应用开发指南2022-11-03 1479
-
NGC catalog新一键部署功开发人工智能解决方案2022-04-13 1876
-
YOLOv5s算法在RK3399ProD上的部署推理流程是怎样的2022-02-11 3626
-
介绍在STM32cubeIDE上部署AI模型的系列教程2021-12-14 3370
-
千芯科技推出了针对芯来RISC-V平台的AI部署工具包(tinyAI SDK)2020-11-21 2498
全部0条评论

快来发表一下你的评论吧 !
