

香山处理器“南湖”DFT设计范例
描述
香山处理器的第二代微架构,南湖微架构,引入了L3 Cache,可配置多核形态,我们完成流片的是双核版本的南湖。较第一代雁栖湖,设计规模在大幅膨胀,主频也从1.3GHz提升到2GHz。规模化之后对DFT设计及物理实现都造成新的挑战,我们的设计方法学也需要与时俱进。
同时南湖微架构的产品化改造(南湖V2),我们以工业级产品的要求对南湖微架构进行更加细致的验证与优化。产品化改造中核心是PPA(Performance『性能』、Power『功耗』、Area『面积』),我们在实现更高性能、更低功耗、更小面积上不断地寻求最佳路径。而在定位量产的产品化改造中,DFT(Design For Test)更是一个绕不开的规格,在雁栖湖微架构上,我们已经落实了一版基本的DFT方案;在南湖V2架构上,我们基于PPA对DFT方案进行了更加细致的优化。
本文整理出“南湖”的DFT设计范例,同样包括了生产测试规格、DFT设计规格、DFT设计数据对比及测试数据预期,给各大开发者作一个参考。
1. 生产测试规格
“南湖”是纯数字电路,由时序逻辑、组合逻辑、Memory组成;设计范例考虑常规soc芯片所需要的生产测试规格,若芯片有更高的测试要求(如车规芯片),可自行增加测试规格及对应的电路开发。
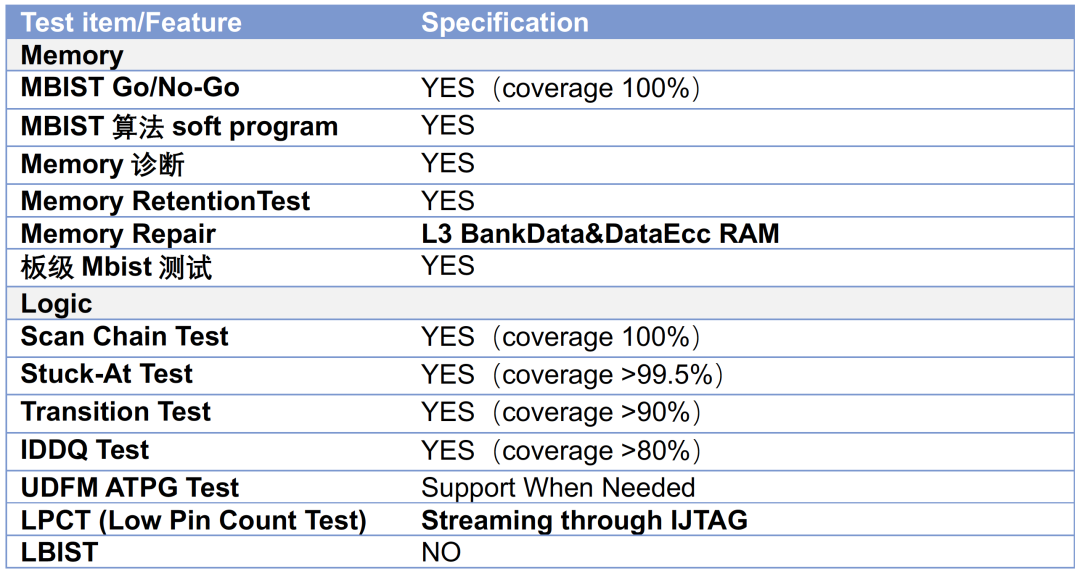
2. DFT 设计规格
“南湖”仍是采用结构化的DFT,可以通过EDA工具快速对design插入DFT电路以实现敏捷开发;“南湖”较“雁栖湖”DFT相关电路进行了精细化的调整,“南湖”包含的结构化DFT电路如表所示:

2.1 雁栖湖和南湖的DFT电路对比
南湖相比于雁栖湖,最大的改动是MBIST调整为基于Sharedbus以减少Mbist Controller的数量,edt channel不再以pin-muxed的方式集成,而是通过SSH(Streaming Scan Hosts)对edt进行内部集成,整芯片形成一张Streaming Scan Network,以下两图展示两代DFT电路架构的差异:
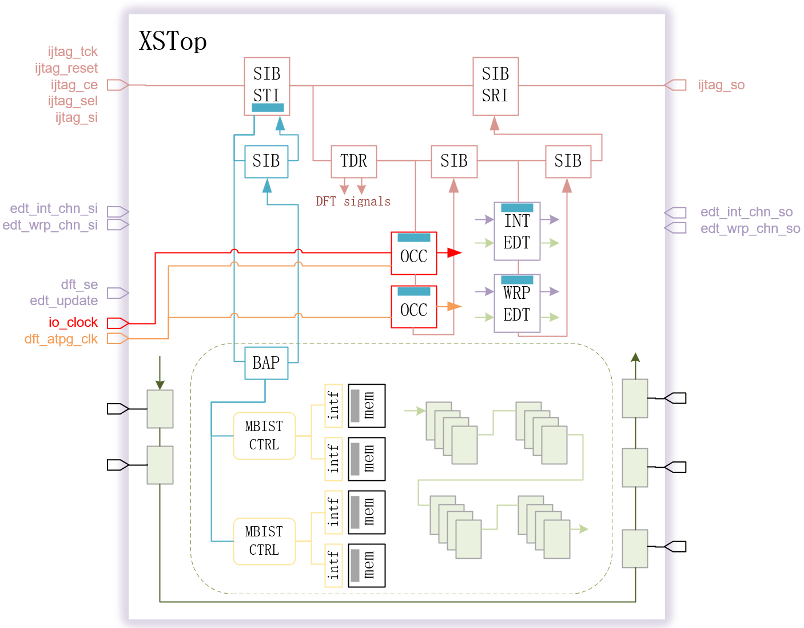
图1 雁栖湖的DFT电路架构
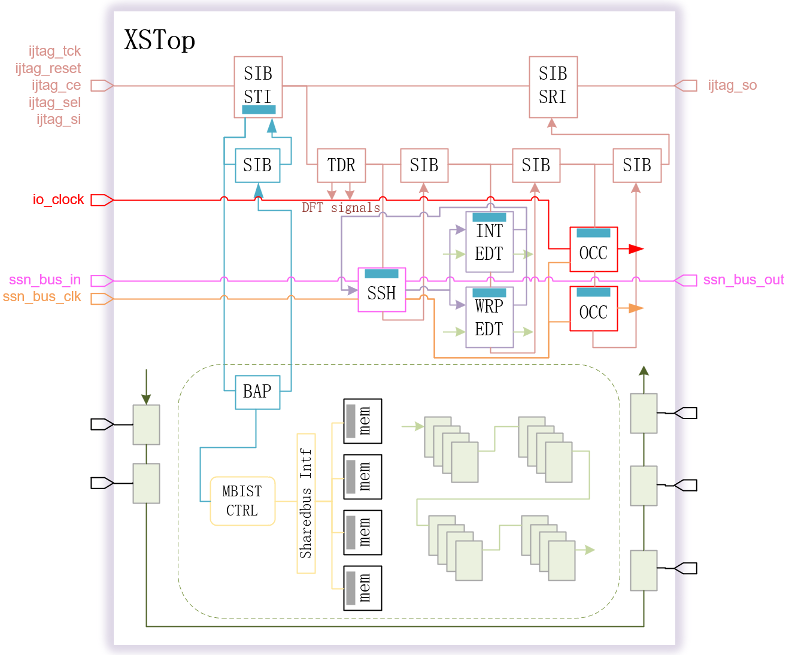
图2 南湖的DFT电路架构
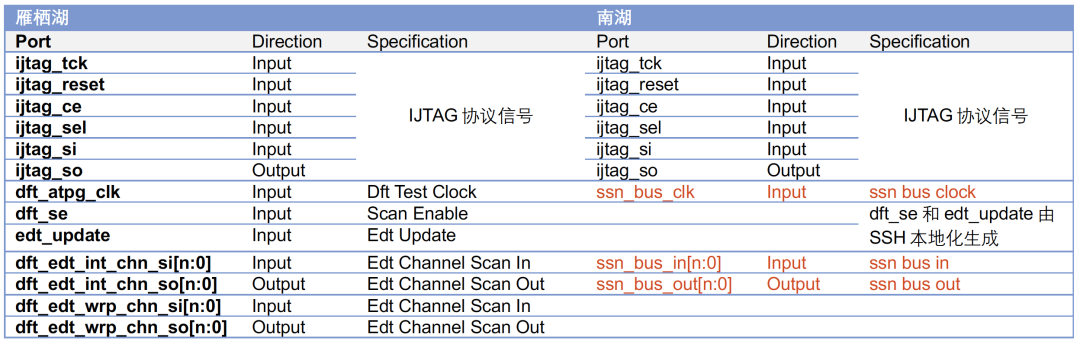
南湖因SSN规格的引入,DFT端口较雁栖湖相比也进行了优化。不变的是南湖还是会通过基于IEEE1687协议的IJTAG配置网络对MBIST、EDT、OCC以及其他DFT的静态信号进行控制。dft_se/edt_update由SSH(Streaming Scan Hosts)本地化生成,edt channel成为了内部连接信号,因此调整edt压缩比导致的edt channel数发生变化以及增加减少edt数量均不再影响模块端口,我们称其为Real Hierarchical Design。
雁栖湖和南湖的DFT新增端口差异如下表所示:
2.2 DFT设计流程
“南湖”微结构设计是基于chisel语言开发,Chisel作为一种全新的高级硬件描述语言,相关的工具链生态还比较薄弱;因此Chisel支持编译成RTL以兼容传统的芯片开发流程包括综合、DFT设计以及基于UVM框架的验证等等。
Chisel由编译器编译出来的RTL,自然也非常利于工具解析,规避掉很多语法识别问题,这个可以更好地支持DFT RTL Flow;MBIST等逻辑在rtl flow进行,大部分情况下可获得更好的PPA指标。设计范例中选取了与综合工具配套的SCAN工具,可以在综合环境当中完成Scan Insert,以应对带物理信息的综合流程。而业界当中也有很多设计采用DFT Gate Flow,这也是完全没有问题,下图为大致的DFT设计流程示意图:
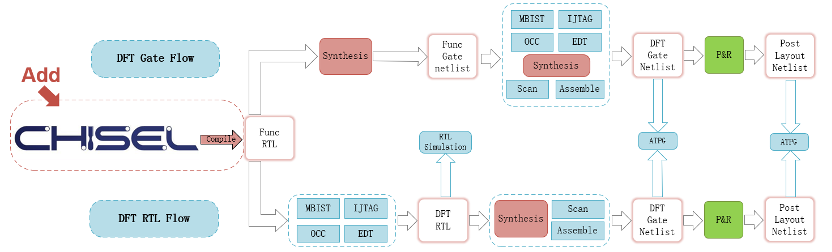
图3 DFT设计流程
3. DFT 的集成与设计
从“南湖”开始,我们在代码设计中加入了一些DFT相关接口,便于开发者实现更加具有竞争力的DFT方案。其中DFT相关接口包括ATPG测试相关接口以及MBIST测试相关接口。
开发者在基于南湖微架构实现DFT方案的时候,需要清晰地知道相关接口的集成方式,以便保证具体DFT设计的正确性且能达到预期覆盖。
3.1 时钟树设计及测试时钟
随着处理器主频不断提高,逻辑规模不断地增大,时钟网络的分布也越来越大、规模不断增加,由此带来芯片时序收敛及功耗优化的压力凸显。“南湖”的时钟树设计上,采取了H-Tree的时钟树设计,来降低芯片时钟网络功耗并克服巨大时钟网络分布受片上工艺偏差(OCV,On Chip Variation)影响而带来的时钟偏斜(clock skew),从而加速设计时序收敛。
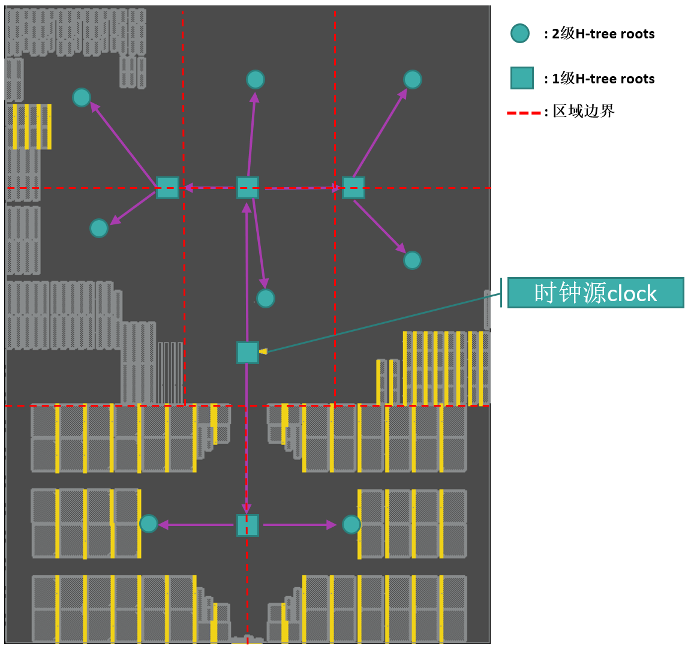
图4 南湖的时钟树设计
DFT的时钟网络设计上也进行了修改,一方面来应对H-Tree的时钟树网络,另一方面是适配新引入的SSN规格:
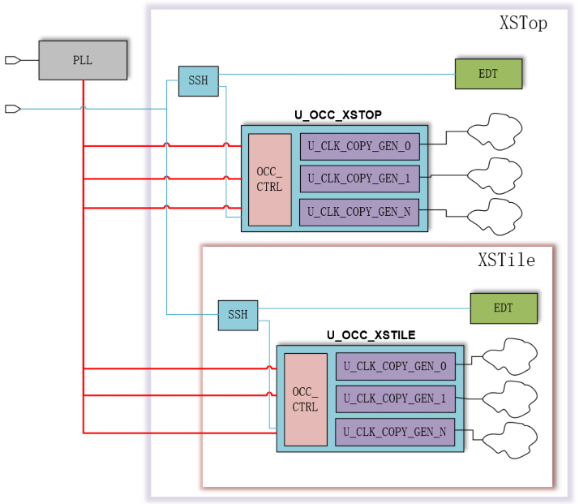
图5 南湖的DFT时钟网络设计
其中CLK_COPY_GEN与H-Tree末端TAP点、与OCC的连接关系如下图所示:
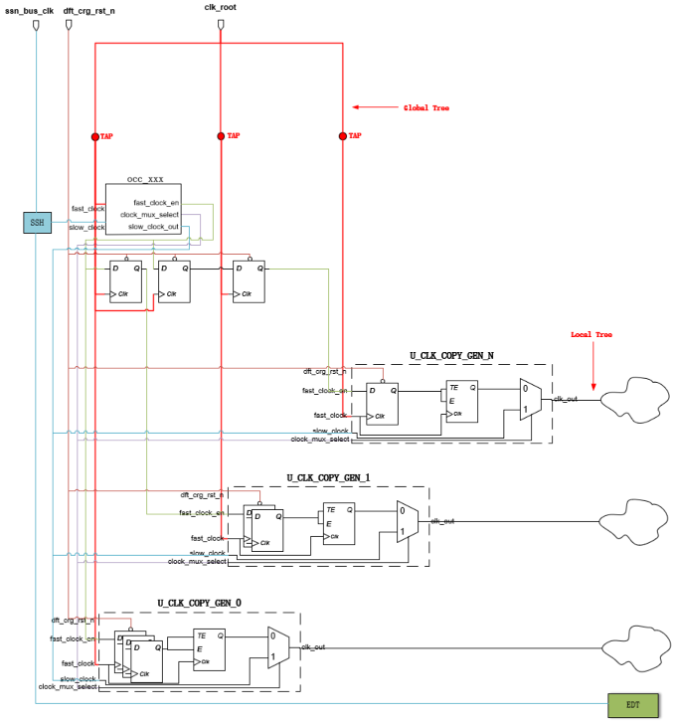
图6 CLK_COPY_GEN的电路连接关系
“南湖”主时钟频率为2GHz,ssn_bus_clk频率设定为200MHz,EDT及模块寄存器shift频率设定为100MHz。
3.2 复位的DFT可控处理
南湖采用异步复位、同步撤离的复位电路结构,功能模式仅在低频时钟下进行复位撤离。复位模块在代码设计中加入以下DFT可控电路,以便于复位操作及满足SCAN DRC。后续功能模式将支持高频复位及撤离,复位dft可控电路结构也会持续演进。
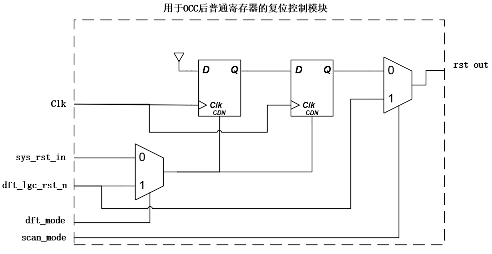
图7 复位的DFT可控处理
其中dft_mode、scan_mode由IJTAG集成,dft_lgc_rst_n复位信号加入了测试点处理,以满足pattern retarget的规格实现。
3.3 ATPG接口信号处理
考虑到ATPG测试的一些需求,南湖微架构设计中加入与ATPG测试相关的DFT接口。
以下为ATPG DFT信号列表:

dft_mode/scan_mode/dft_lgc_rst_n
参考南湖复位的DFT可控处理
dftcgen/dft_mcp_hold/dft_l3dataram_clk/dft_l3dataramclk_bypass
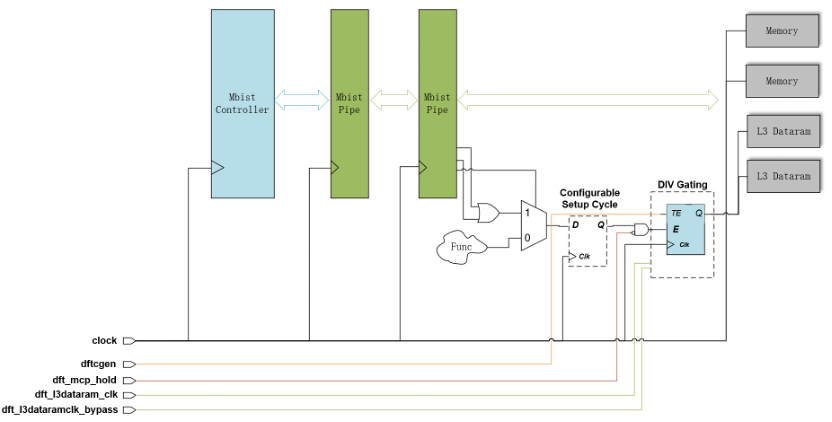
图8 L3 Dataram的时钟门控处理
南湖微架构在L3 dataram时钟上进行了分频门控处理,代码设计上对该结构也进行了DFT可控处理。
dftcgen连接的是集成门控的TE端,该信号在scan shift阶段保证有效,scan capture阶段由测试点控制打开/关闭,可有效测试门控本身及支持stuck-at ATPG的ram sequential向量生成。
dft_mcp_hold可以强制关闭门控以在at-speed ATPG的时候阻止multicycle paths带来的X-pollution。
若STA约束对L3 Dataram的输入设置hold multicycle,设计范例将dft_l3dataram_clk挂载在低频的OCC上,利用两个OCC之间的hold multicycle来实现L3 Dataram的stuck-at ram sequential向量生成。
dft_ram_hold/dft_ram_bypass/dft_ram_bp_clken
南湖微架构采用基于sharedbus的MBIST设计方法,EDA生成的Mbist Controller和sharedbus接口对接,不再对Memory周边插入MBIST及支持ram sequential的电路处理。因此南湖微架构设计中进行了支持ram sequential的信号处理,有3个dft信号dft_ram_hold/dft_ram_bypass/dft_ram_bp_clken送到sram_array上。
我们约定在sram_array模块中让用户例化真实SRAM。在例化真实SRAM的时候可以参照以下电路自行加入相关DFT可控逻辑,其中mbist_selectOH(~dft_ram_hold)在sram_array中对sram的片选钳位处理是必须的,保证scan shift的时候RAM处于片选无效,而ram bypass logic则是可选。ram bypass logic的加入可以进一步提高memory shadow logic的覆盖率,但也对memory周边时序产生负影响,用户可以根据产品的测试需求来权衡。设计范例中对sram_array均加入ram bypass logic处理。
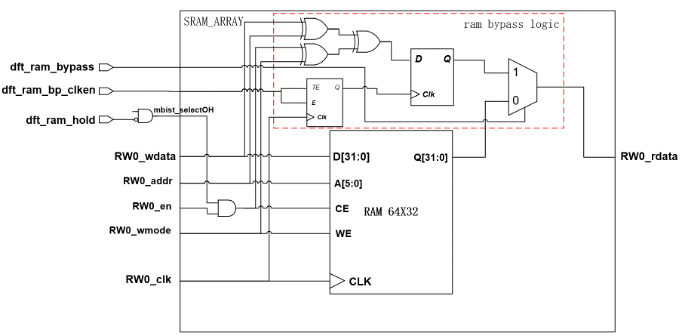
图9 sram_array的DFT处理
3.4 MBIST集成与设计
基于南湖微架构中的Cache结构,结合对Memory测试定位便利性及测试时间的均衡,sharedbus对CPU整系统的MBIST总线划分如下:
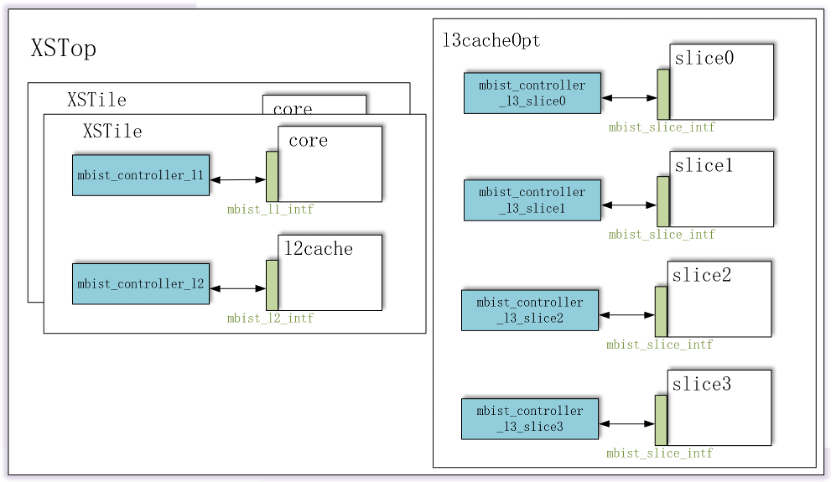
图10 南湖MBIST总线划分
Mbist总线接口具体层次如下列表所示:

MBIST总线(绿色部分)在南湖微架构代码中落实
MBIST Controller(蓝色部分)通过EDA工具插入与MBIST总线对接
DFT设计范例基于双核版本的南湖微架构,共设计了8组MBIST总线,对应8个MBIST Controller,相比于雁栖湖,MBIST Controller大幅减少。
3.4.1 Sharedbus相关文件配套
Sharedbus相关文件配套包含描述MBIST总线接口到Memory映射关系的csv格式文件;该文件可以直接文本打开或者通过excel打开:
MBIST_L1.csvMBIST_L2.csvMBIST_L3S0.csvMBIST_L3S1.csvMBIST_L3S2.csv
MBIST_L3S3.csv
Sharedbus相关文件配套也提供了转换脚本通过csv文件转换成主流EDA工具的MBIST输入件,以实现MBIST设计流程的高度自动化:
MbistIntfTcdGen.py –csv MBIST_L1.csvMbistIntfBuscfgGen.py –csv MBIST_L1.csv
3.4.2 L3 Dataram的读写Latency
南湖L3 cache 中的BankData RAM/DataEcc RAM工作在分频时钟下,Mbist测试模式通过mbist_readen/mbist_writeen进行门控控制,电路结构如下:
图11 L3 Dataram的时钟门控处理
MBIST Controller对mbist_readen/mbist_writeen进行隔拍发送。L3 Dataram的MBIST读写时序如下图波形所示:
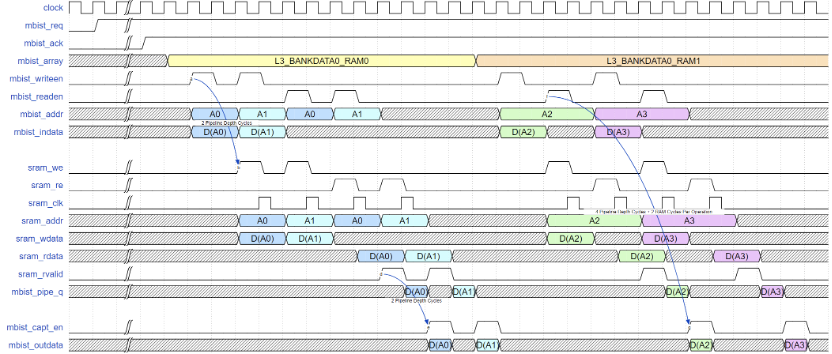
图12 二分频的sharedbus读写时序
从MBIST Controller发起读使能开始,控制器需要过多少拍之后才去采集有效的mbist_outdata,这里涉及到Read Total Cycles的计算。下图展示了Read Total Cycles的构成:
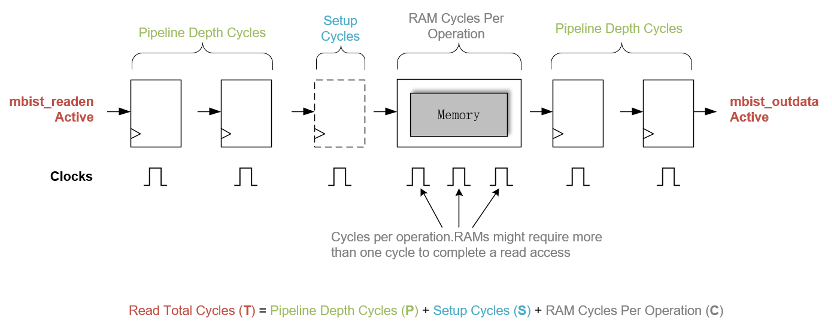
图13 Read Total Cycles计算
3.4.3 超大宽度Logical Memory的mbist_selectOH处理
sharedbus总线为了控制面积,mbist_data宽度最高限制在256,不过设计当中有一些Logical Memory的数据宽度超过了256(如PTW_L3_RAM宽度达到1380);在sharedbus设计对这类Logical Memory进行拆分,使用mbist_selectOH信号进行Mbistarray区分;sharedbus设计中有以下电路将mbist_selectOH信号送到sram_array上:
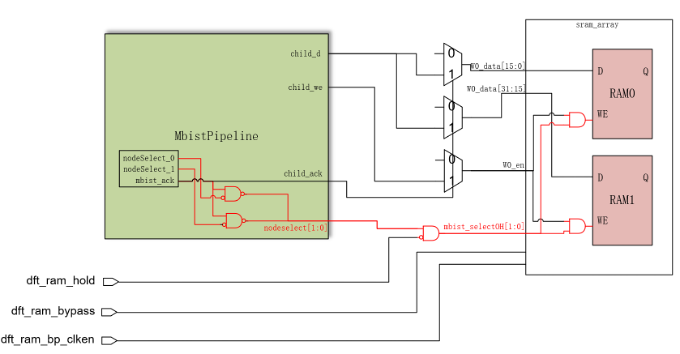
图14 超大宽度Logical Memory的mbist_selectOH处理
mbist_selectOH功能模式下默认值为全1。
在sram_array中是实例化SRAM同时,使用mbist_selectOH对Memory写使能/片选进行与门钳位。
mbist_selectOH信号也被复用为(~dft_ram_hold)
3.4.4 Memory Repair
设计范例中L3 Slice中的BankData RAM和DataEcc RAM均使能了Redundancy,DFT对存在Redundancy的SRAM进行MBISR(Memory Built-In Self-Repair)电路设计以谋求在量产测试中提高芯片良率。EDA工具可以在Sharedbus架构下自动完成MBISR相关的电路生成。MBISR在整芯片的集成架构如下图所示:
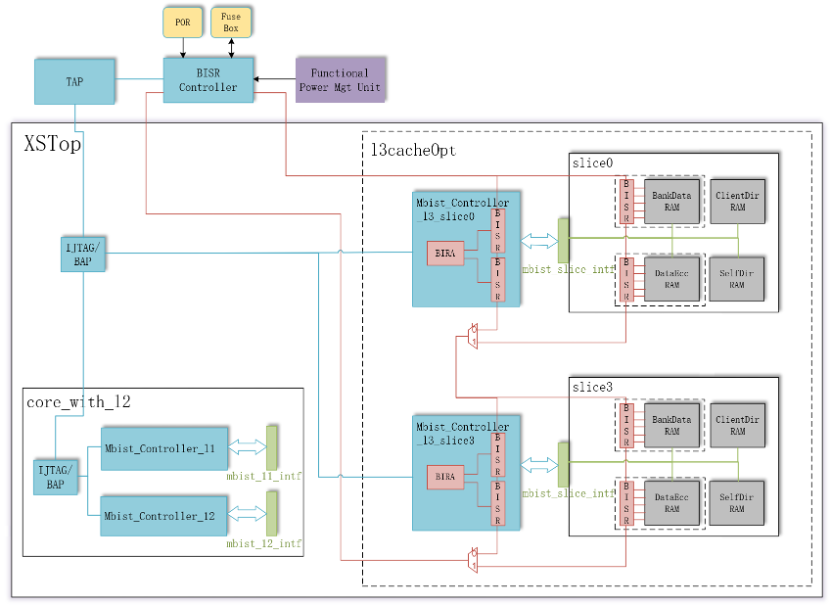
图15 整芯片MBISR集成架构
3.4.5 MBIST设计数据
Cache Size及MBIST规格数据对比:

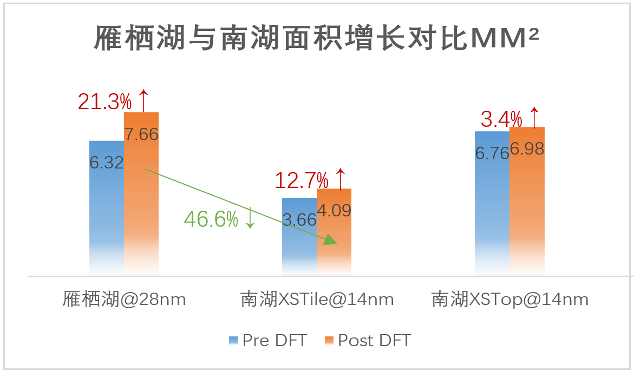
图16 雁栖湖与南湖面积增长对比
如上图雁栖湖与南湖面积增长对比,公平起见,南湖Pre DFT不包含sharedbus逻辑,Post DFT均为实现完全DFT规格后的综合面积(包括ijtag、mbist、occ、edt、scan replacement、scan stitching的面积增长),其中南湖Post DFT还包括SSN相关电路。
雁栖湖与南湖XSTile的Instances规模相当,两者面积进行对比
DFT面积增长从21.3%优化到12.7%受益于工艺制程,整体面积降46.6%
对比XSTile与XSTop,Cache Size越大,Sharedbus架构收益更明显
由于Sharedbus架构,组内memory串行测试带来测试时间增长,但MBIST测试时间并不是测试时间占比大头,这部分后续通过ATPG向量优化把整体测试时间降下来。
3.5 集成与设计
采用全扫描电路,南湖采取层次化的设计,XSTile与XSTop分别插入扫描链。
不同scan chain长度尽量保持平衡
为了方便timing收敛,一条scan chain上只对应同一个功能时钟域,链尾统一加上LOCKUP
Scan shift频率从雁栖湖的48MHz提升到100MHz
shift_capture_clock为ssn_bus_clk的generate clock,scan enable由SSH本地化生成
模块使能wrapper chain,加入wrapper cell原则为share first,reuse_threshold阈值设置为20
模块wrapper cell统计,物理实现需关注被加入Dedicate Wrapper Cell的功能接口时序:

时钟、dft相关端口不加入wrapper cell
3.6 集成与设计
南湖整体的EDT/SSH的集成框架如下图所示:
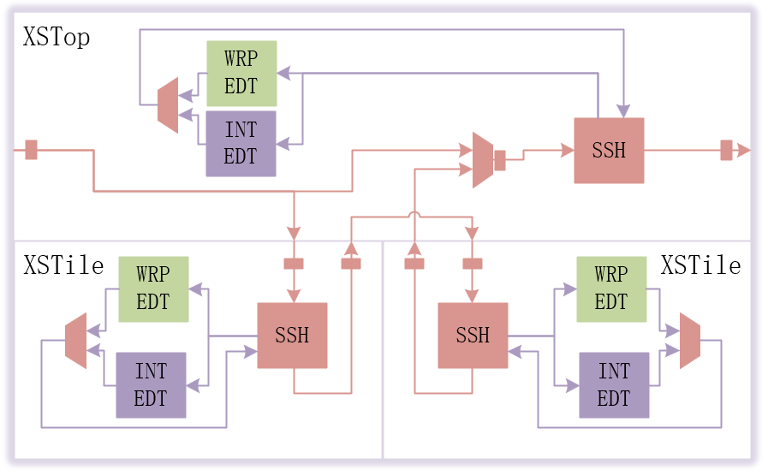
图17 南湖EDT/SSH集成框架
针对XSTile的输出SSN DataPath进行bypass处理应对XSTile掉电隔离
SSN DataPath在模块接口均加入Pipeline
使能On-chip Compare
XSTop/XSTile的SSH Nodes加入On-chip Compare电路便于Partical good die的测试分bin及indentical cores(XSTile)的测试向量优化;edt output channel影响Expect/Mask的数据量,edt output channel需尽量少。
SSH工作频率为200MHz,由外部时钟ssn_bus_clk输入,EDT工作频率为100MHz
edt_update由SSH本地化生成,edt_clk为ssn_bus_clk的generate clock,SSH中使用stdcell库提供的clock shaper cell便于简化时钟约束及CTS时钟处理。
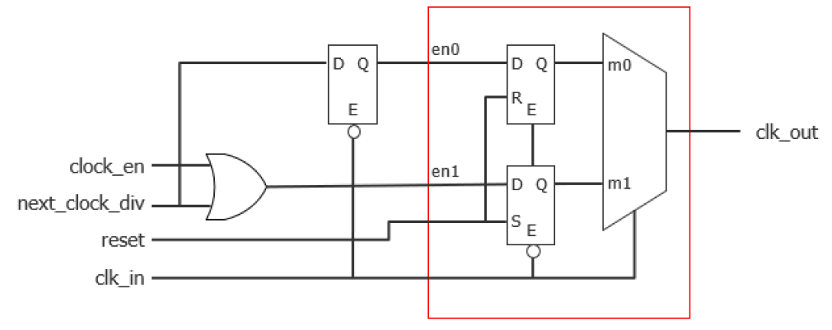
图18 clock shaper cell的电路结构
Clock shaper cell由两个latch以及一个mux组成,可以很好地实现分频时钟的生成以及保证时钟占空比:
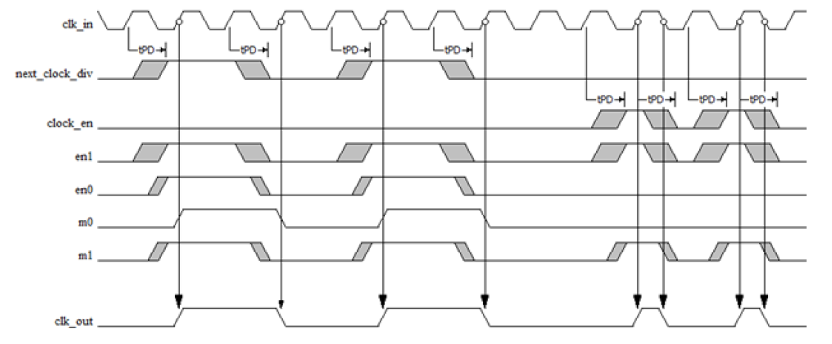
图19 clock shaper cell的电路时序
每一个block设计两个EDT,1个SSH
普通scan chain、reserved chain压缩到int edt当中occ chain、gt_se_chain、sti chain、wrp chain压缩到wrp edt当中,同时压缩到int edt当中模块edt chain/channel设置,SSH 的bus_width设置:

对EDT的Compactor进行打拍,避免组合逻辑深度过深
两个EDT的channel均集成到SSH当中
EDT使能lowpowershift,min_switching_threshold_percentage设置为15(翻转率)
3.7 Streaming Through IJTAG
LPCT(Low Pin Count Test)是增强板级定位的测试手段,同时也可以服务于芯片的装备测试。Low Pin Count Test顾名思义是用极少的管脚数量完成芯片的测试,常见于通过IEEE 1149.1协议的JTAG接口完成LPCT,因为功能模式和DFT模式都会使用JTAG接口,可以很好地复用。使用pin-muxed集成edt的方式,需要额外地加入LPCT Controller及相关连接才能实现LPCT,通过SSN的方式集成edt,其架构本身则利于LPCT的实现,在SSH内部IJTAG接口可轻松地对bus_clk/bus_data完成接管,我们称之为Streaming through IJTAG,结构如下图所示:
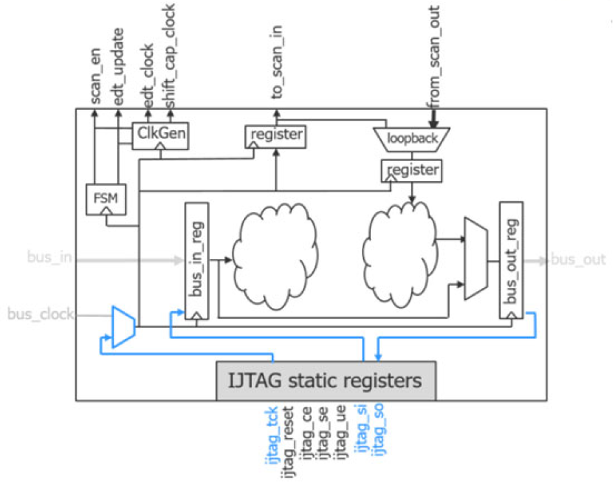
图20 Streaming Through IJTAG
Scan data通过TDI、TDO移进/移出,shift_capture clock通过TCK实现
借助于现有的IJTAG网络,完成TAP到ScanHost nodes的scan data传递
OCC需要支持inject tck
支持internal 及external capture
支持测试所有的ATPG fault models
模块正常生成的Retargetable Pattern可以重定向成LPCT的测试Pattern
支持同时测试所有的ScanHost nodes
3.8 设计数据
灵活的Pattern Retarget粒度
设计中通过合理分配OCC、SSH、EDT、Wrapper Chain所插入的位置,以实现XSTile、XSTop独立的Retargetable Pattern生成,或者以XSTop flatten为粒度进行Retargetable Pattern生成
ATPG Data Pin-muxed vs SSN
在进行基于SSN的ATPG设计数据收集同时,我们对pin-muxed集成方式进行对比。在pin-muxed集成方式下,edt的input channel与output channel保持和SSN一致,XSTile的edt input channel采用信号广播的方式进行集成。Pin-muxed/SSN的集成方式下,SCAN所占端口资源对比:

Pin-muxed/SSN的ATPG覆盖率及向量数对比:
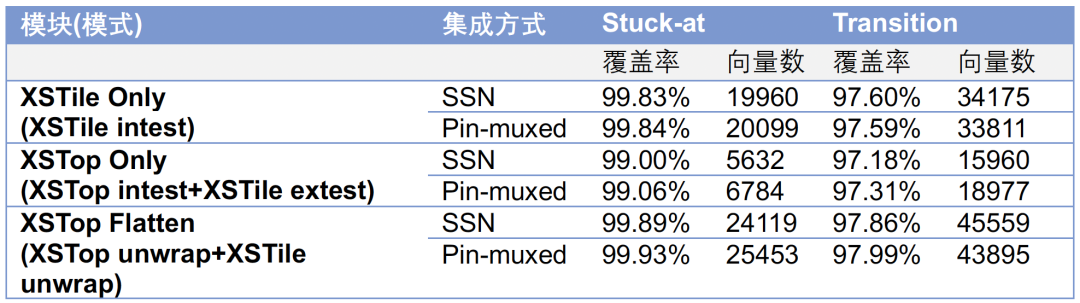
覆盖率具体情况:
unwrapped模式下的Stuck-at向量对比:

图21 unwrapped模式下的Stuck-at向量
unwrapped模式的Transition向量对比:
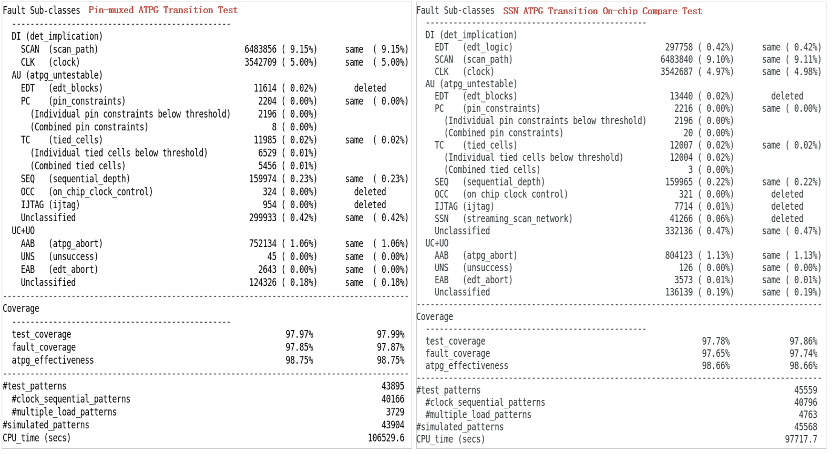
图22 unwrapped模式下的Transition向量
对于XSTop Only在edt channel明显少于SSN bus的宽度情况下,在向量数上有明显的优化;对于XSTop Only以及XSTop Flatten的SSN ATPG Generation,共启动了3个SSH Nodes,各SSH Nodes间的Capture会对齐,从ATPG数据上看UC+UO的比例稍微比Pin-muxed的ATPG多一点点,但整体差异并不大。
基于SSN的ATPG向量机制
SSN Bus如同一个管道,SSH如同开关阀门,Scan data如同管道中的水流向每一个模块当中。管道带宽Bandwidth=Bus Width*Bus Frequency,在IO资源(Bus Width)有限的情况下,通过提升Bus Frequency来增加管道带宽。因此南湖当中SSN bus设定为200MHz。SSN Bus的逻辑和时钟均与功能逻辑解耦,placement和cts均可DFT自己控制,200MHz的时序收敛相对来说风险可控。
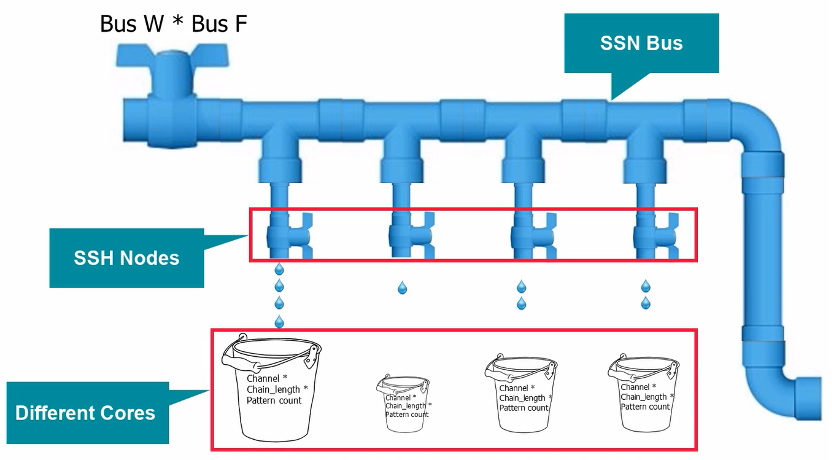
图23 SSN Bus Bandwidth
SSN bus当中的Scan data,有区别于传统ATPG的普通激励,其格式为Packet-based,普通的Packet Format中带有模块标记,以便于对应模块的SSH将Packet payload卸载到EDT当中,具体格式如下所示:
Packet Format:I,其中I表示ScanIn
普通的Packet Format常用于测试non-identical core,下图展示Packet-based数据如何通过SSN bus送到对应的EDT当中:
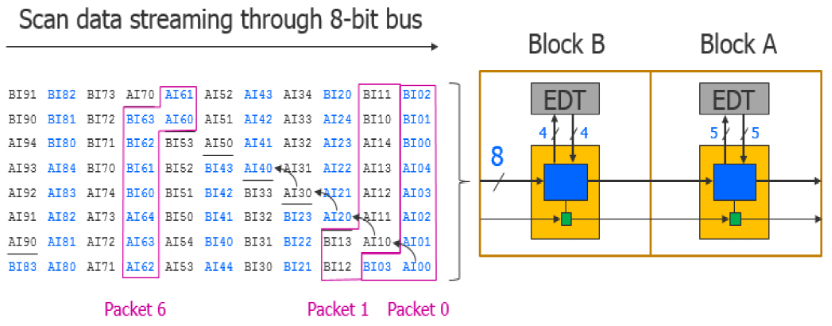
图24 Normal SSN Packet Formats
当我们使用On-chip Compare模式测试identical cores的时候,Packet Format会发生变化,如下图所示,例子中为6个identical cores,status groups分为a、b两个group,Packet data中除了ScanIn之外,还有Expect、Mask 、Status,因此Packet Format中input time slots有I、E、M这几个labels,output time slots有status groups的labels。
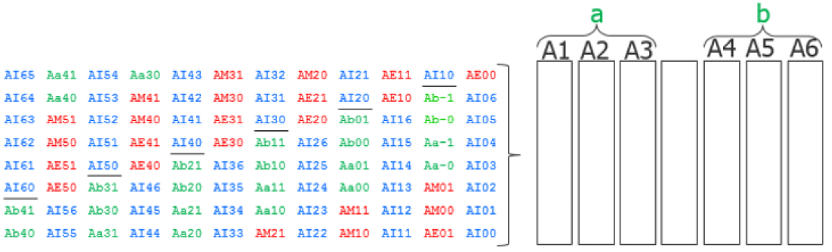
图25 SSN Packet Formats When Using On-chip Compare
基于SSN的ATPG向量收益
SSN较传统Pin-muxed的集成架构上发生了比较大的变化,且SSH增加了电路面积,这块的代价肯定希望可以换来收益的。传统的Pin-muxed集成方式下,scan enable为全局信号,因此在ATPG向量上各模块的capture必须对齐,shift cycle比较少的模块需要加入Padding cycle补齐。

图26 Pin-muxed Retargeting with aligned capture
在SSN集成方式下,scan enable为SSH本地生成,wrapper cores在retargeting的时候可以独立shift/capture。值得注意的是,在IDDQ向量以及多个SSH Nodes一起ATPG Generation的时候,多个SSH Nodes之间的Capture还是会对齐。

图27 SSN Retargeting with independent shift/capture
独立shift/capture带来几个好处:一个可以减少wrapper cores间因shift cycle不一致而导致产生的padding cycle,在SSN Retargeting的时候可以灵活地进行Bandwidth tuning;另外一个是错开capture时刻点可以降低capture的峰值功耗,从而减轻IR drop。传统Pin-muxed集成方式所完成的ATPG,测试时间容易因为某个模块的Test cycle特别多而成为瓶颈,实际上造成了带宽的浪费;下图展示通过SSN Retargeting的Bandwidth tuning,可有效降低整体测试时间。
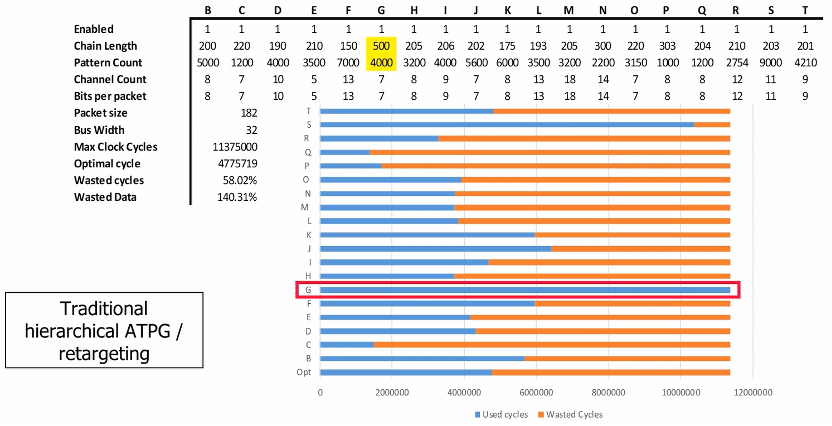
图28 Traditional hierarchical ATPG retargeting
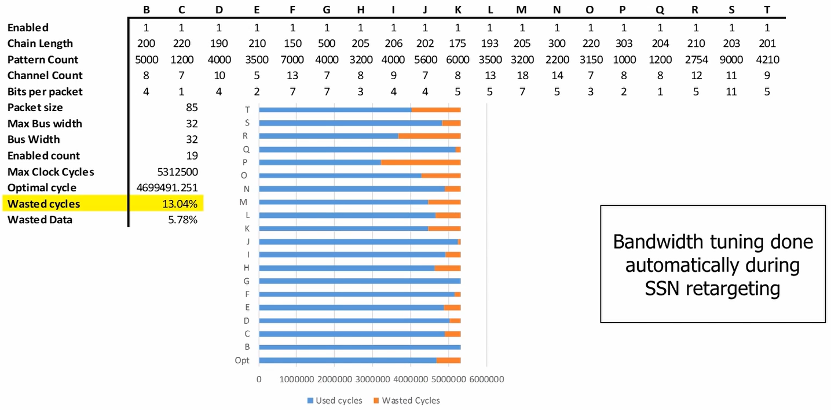
图29 Bandwidth tuning during SSN retargeting
而对于设计中存在多个identical cores,SSN Bandwidth tuning的作用有限,此时我们可以通过on-chip Compare来减少测试时间。尽管indentical core(XSTile)的SSN DataPath是串接起来的,在On-chip Compare模式下也可以将同一份Scan data广播到每一个indentical core,数据比对通过identical cores中的sticky bit本地完成。
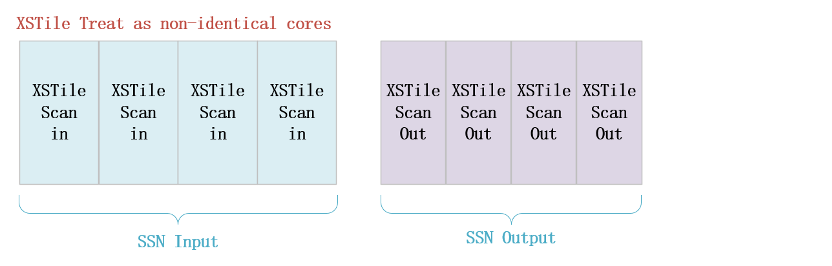
图30 non-identical cores SSN ATPG Test
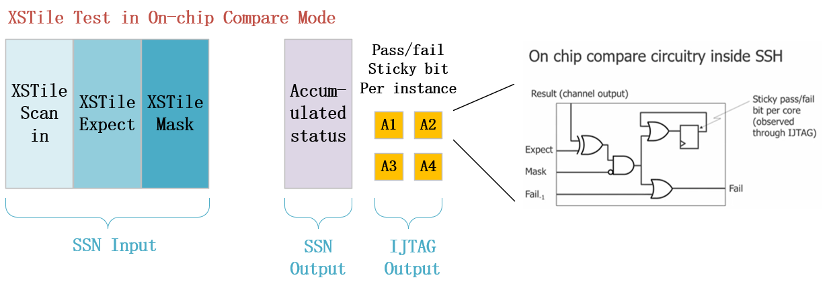
图31 identical cores Test in On-chip Compare Mode
但由于On-chip Compare的ATPG向量方式和普通ATPG向量不太一样,诊断流程也有所差别,是否可直接诊断受test_setup当中的on_chip_compare_contribution以及status group的分组影响,在向量开发的时候需要额外注意。
4. 众核香山处理器Pin_muxed vs SSN
从上一章节的SSN ATPG向量收益来看,SSN的优势更多地发挥在整芯片集成上;为了进一步地比对,本章节构造了一个众核版本的香山处理器,从整芯片集成的角度去分析两个技术上的差异。众核香山处理器基于双核南湖微架构作为CLUSTER,由8个CLUSTER组成tile-base design,65个可供SCAN复用的GPIO,IO最高测试速率100MHz,分别用Pin-muxed和SSN方式完成SCAN集成。
4.1 Pin-muxed集成
受限于IO资源,Pin-muxed的集成不能支持所有CLUSTER同时进行测试,IO复用我们设置3个reuse group,其中将8个CLUSTER的intest,分两次进行测试,reuse group如下表所示:
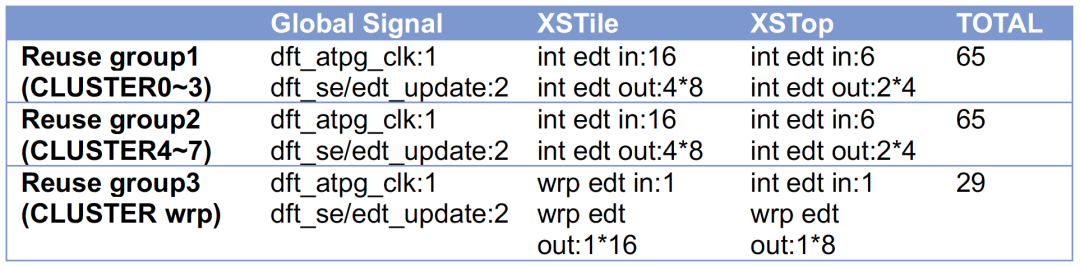
Pin-muxed的集成示意图如下图所示(受限于篇幅,图中没有画出XSTile):
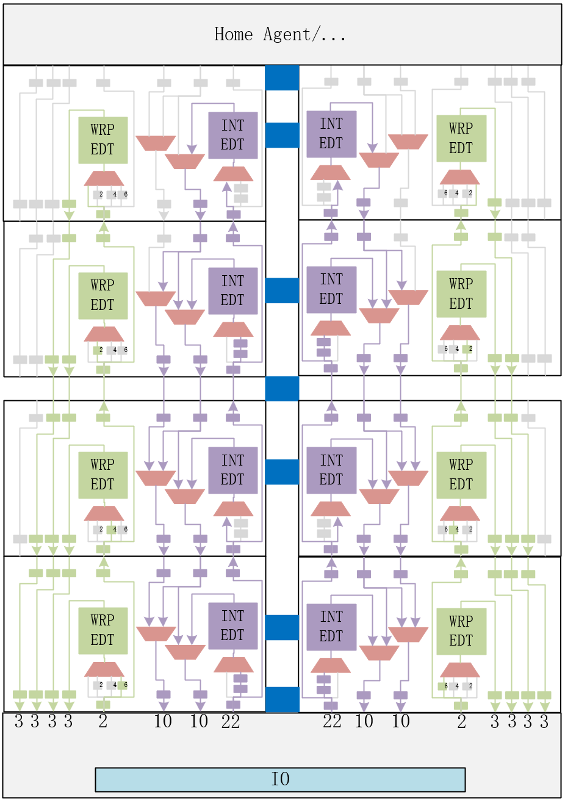
图32 众核香山处理器的Pin-muxed集成
4.2 SSN集成
南湖微架构当中的SSN bus为200MHz,而IO最高测试速率为100MHz。针对此,我们在同等带宽下,对Bus Width和Bus Frequency进行互换。在SSN Bus的输入,我们利用BusFrequencyMultiplier将32 Bus Width*100MHz转换成16 Bus Width*200MHz;又在SSN Bus的输出,利用BusFrequencyDivider将16 Bus Width*200MHz转换成32Bus Width*100MHz。加上ssn_bus_clk,SCAN的IO复用也是65个。基于SSN的集成方式,可以对所有的CLUSTER同时进行测试。ssn的集成方式如下图所示(受限于篇幅,图中没有画出XSTile):
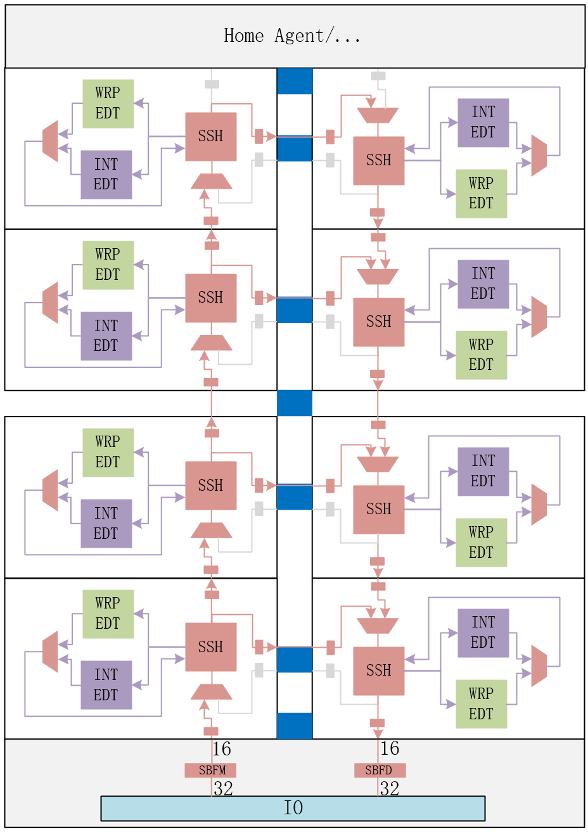
图33 众核香山处理器的SSN集成
从Pin-muxed及SSN的集成方式对比可以看出,Pin-muxed的测试并行度受限于IO资源,而SSN则不受影响,具有很好的扩展性;SSN可以实现模块间更少的信号交互,顶层集成更加地清晰。
4.3 Pin-muxed与SSN的测试时间
在测试时间上,SSN集成方式可以做得更优,这样可以有效地降低测试成本。在此,我们选取两种集成方式的两个Test Group进行比较,先列出两个Test Group的测试内容:
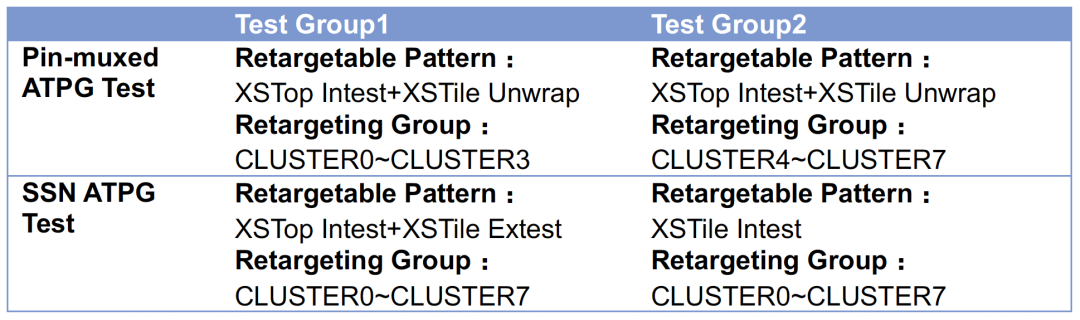
Test Group的Stuck-at/Transition测试时间统计如下:

首先SSN的Retargetable Pattern可以拆得更细,提高向量开发并行度,缩短向量开发周期;在最终整体测试时间上,SSN的测试时间也仅是Pin-muxed的55.7%。
再对比于3.86Million Instances的雁栖湖stuck-at+transition需要434.4ms完成测试,而8个CLUSTER共63.2Million Instances的南湖微架构众核香山处理器stuck-at+transition仅需要283.4ms完成测试,这是测试频率提升及集成架构优化带来的收益。
4.4 SSN的扩展性
常见的商业CPU,通常一个CLUSTER带4个Core,在SSN的集成上较于双核,只需要把增加两个Core的SSH Nodes串接起来即可,也不需要改变外部接口,凭借On-chip Compare测试,整体测试上从16 Core到32 Core,测试时间并不会发生明显的变化。
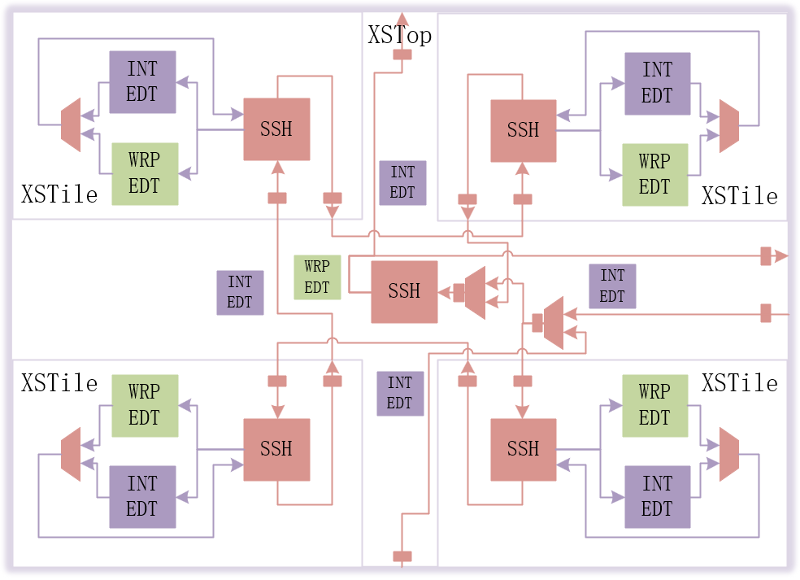
图34 四核南湖微架构的SSN集成
在chiplet的2.D封装集成上,Intel给出用了利用SSN完成die-to-die SCAN集成的示例:
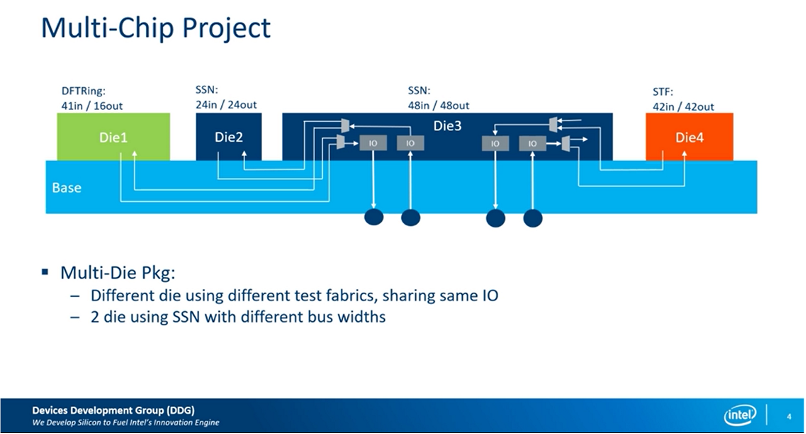
图35 2.5D die-to-die的SSN集成
对于3D IC的垂直堆叠,行业标准上IEEE 1838定义了新的3D-DFT标准用来测试堆叠芯片。IEEE 1838当中FPP(Flexible parallel port)提供了并行的测试访问接口,而利用SSN来完成FPP的集成,也是很好的解决方案。
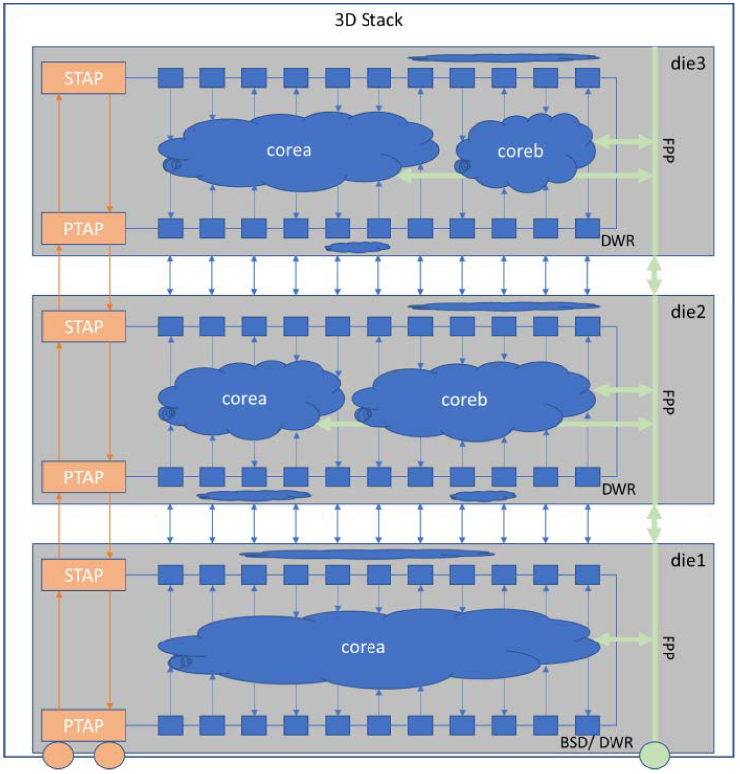
图36 IEEE 1838 schematic overview
另外,SSN结合Serdes高速接口(1149.10 HSIO )及高速数字机台,用更少的IO、更快的速率实现高带宽的SCAN测试。下图为爱德万展示1149.10+SSN结合的电路架构:
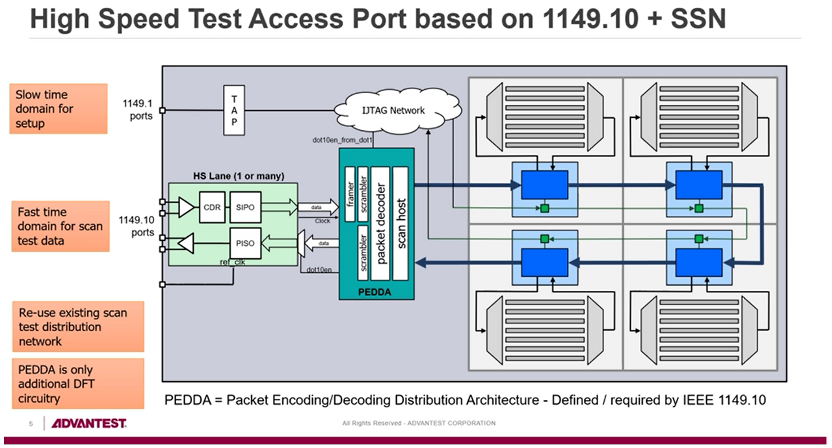
图37 1149.10+SSN
5. 测试数据预期
Broadcom在使用SSN集成上提供了一些实测数据,也希望香山处理器在实测当中也可以达到类似的效果。Broadcom在shmoo test中显示,在测试同等数量cores的情况下,SSN相比于Pin-muxed可以获得30mv的Vmin收益。上面的章节也提到,SSN可以让每个Core实现独立的capture来降低capture的峰值功耗,从而减轻IR drop。
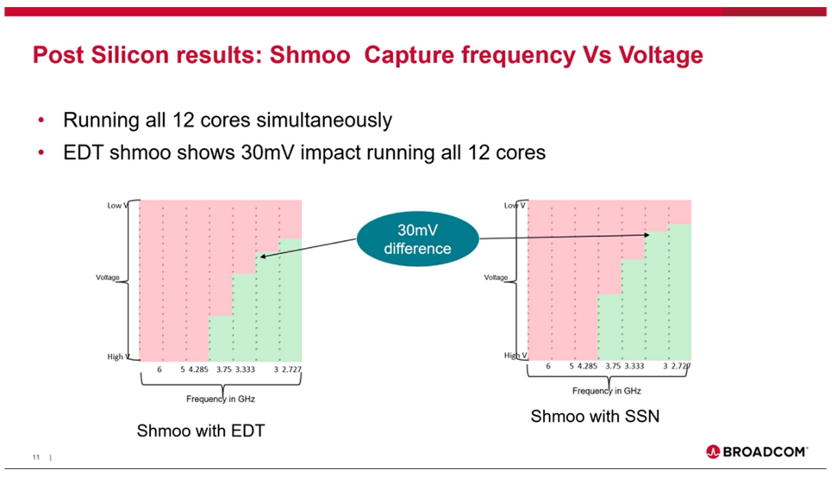
图38 SSN ATPG Test Shmoo
因为on chip compare测试不需要将数据cycle-to-cycle地移到SSN output上比较,不受IO速率和机台数据抓取速率瓶颈的影响,shift时序收敛与实测可以Match上。
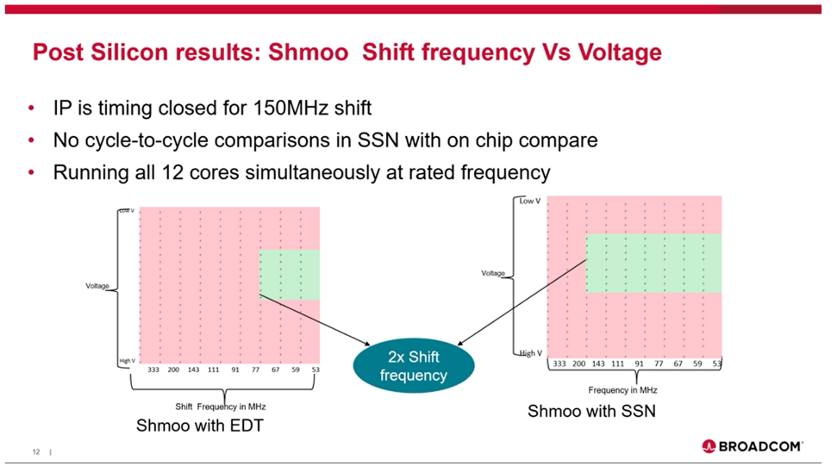
图39 SSN On chip compare Vmin
审核编辑:汤梓红
-
走进"香山":解密国产开源处理器的技术创新2025-01-06 3818
-
DFT在信号处理中的应用 DFT与FFT的区别2024-12-20 5003
-
如意香山笔记本软件适配工作稳步推进,成功运行多款Linux发行版及国产办公套件2024-09-02 1517
-
思尔芯原型验证助力香山RISC-V处理器迭代加速2023-10-25 1505
-
国产第二代“香山”RISC-V 开源处理器计划 6 月流片:基于中芯国际 14nm 工艺,性能超 Arm A762023-06-05 1344
-
透过第二代“香山”看RISC-V开源处理器的机遇和挑战2023-06-01 4319
-
性能超ARM A76!国产第二代“香山”RISC-V开源处理器最快6月流片2023-05-28 6005
-
香山处理器 RISC-V的典范2023-04-14 817
-
RISC-V发展以及中科院RISC-V开源处理器“香山”介绍2022-12-30 3225
-
香山是什么?“香山” 高性能开源 RISC-V 处理器项目介绍2022-04-07 6404
-
中科院发布国产开源高性能RISC-V处理器“香山”2021-07-01 2429
-
中科院重磅发布国产开源高性能RISC-V处理器“香山”2021-06-26 13202
全部0条评论

快来发表一下你的评论吧 !
