

通过场景landmark做定位的新思路(CVPR 2022)
描述
主要内容:提出了一种基于学习的相机定位算法,其无需存储图像特征和场景三维点云,降低了存储限制,通过识别场景中稀疏但显著有代表性的landmark来找到2D-3D对应关系进行后续的鲁棒姿态估计,通过训练检测landmark的场景特定的CNN来实现所提出的想法,即回归输入图像中对应landmark的2D坐标。

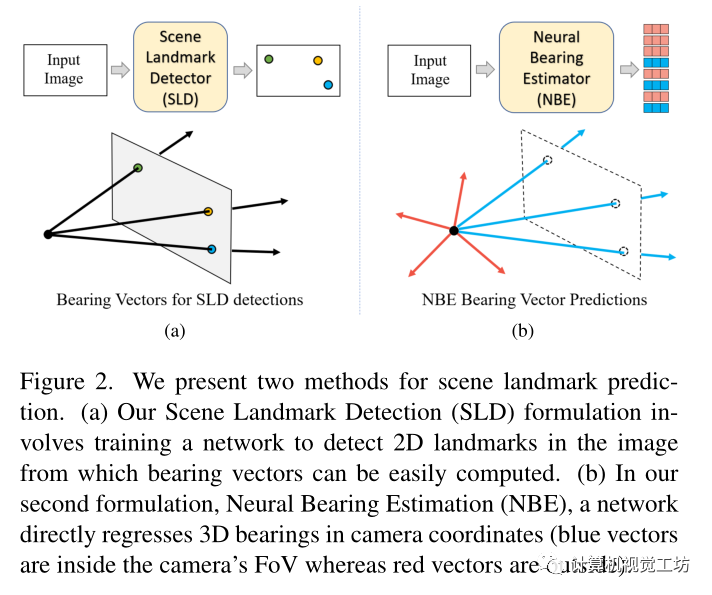
创新点与Contributions:1)与大多数landmark通常可见的人体姿态估计不同,由于相机视野有限并且无法同时观察场景的不同部分,相机姿态估计任务中大多数场景landmark不会同时可见,文章通过提出一种新的神经方位估计器(Neural Bearing Estimator,NBE)来解决这一问题,该估计器可以直接回归相机坐标系中场景landmark的3D方位向量,NBE学习全局场景表示的同时学习预测场景landmark的方向向量,即使它们不可见。 2)提出了一个新的室内定位数据集,INDOOR-6,相对于传统的7-Scenes室内数据集,包含更多变化的场景、昼夜图像和强烈的照明变化 3)与现有的无存储定位方法相比,具有低存储的优点且性能较好 文章提出了两种预测图像中场景landmark的方法,在第一种方法中训练了一个模型来识别图像中的2D场景地标,称之为场景地标检测器(SLD),由于假设已知的相机内参,这些2D检测可以转换为3D方位矢量或射线。在第二种方法中训练了一个不同的模型直接预测相机坐标系中landmark的3D方位向量,称之为神经方位估计器(NBE)。注:使用SLD,只能检测到相机视场(FoV)中可见的landmark,而NBE预测所有landmark的方位,包括相机视场外不可见的landmark。
首先会有一个SFM构建的点云模型,会在这些点云中挑选出有代表性的点云子集,用这些子集以及建图时SFM算法生成的数据库图像的伪真值来训练两个提出的网络模型。SLD:SLD被设计为将RGB图像I作为输入并输出一组像素似然图(热图)表示每个可见地标的位置,其模型架构如下:
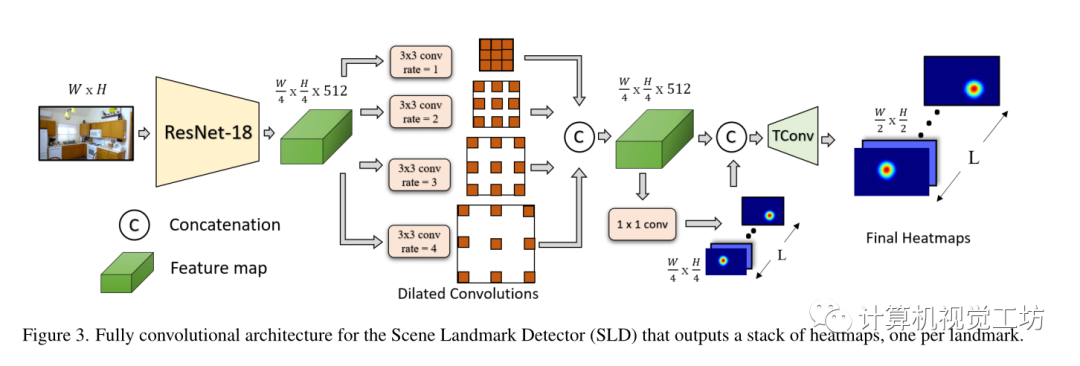
由四个主要组件组成:使用ResNet-18为backbone,删除最后三个最大池化层以保留高分辨率特征图(输出分辨率为输入图像分辨率的四分之一),其次在ResNet-18之后使用扩张卷积块,扩张率设置为1、2、3和4,接下来转置卷积层执行上采样,并负责生成分辨率为输入图像一半的热图,最后一层由1×1卷积组成,预测L个热图通道,每个地标一个。 训练损失:

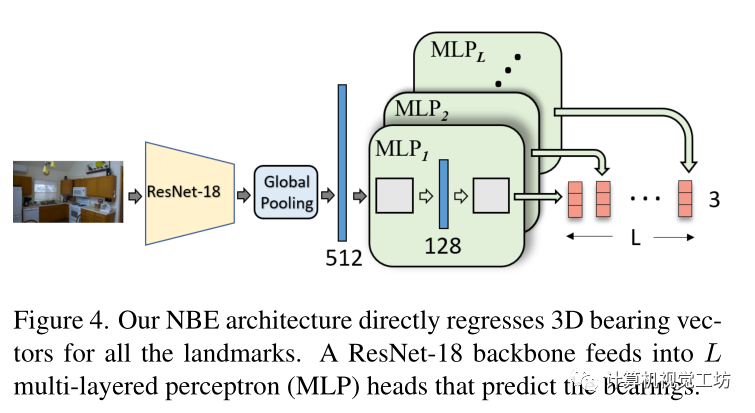
在推断过程中,假设当其最大热图值超过阈值τ=0.2时表明检测到地标,利用亚像素精度计算热图峰值位置处裁剪的17×17 patch的期望值。NBE:设计了一个模型在给定图像I的情况下回归全部场景landmark(即使它不可见)的方位向量。 CNN将图像I作为输入以生成深度特征图,然后是多个MLP(多层感知器)块,每个块输出指向landmark的方向向量,MLP包含两个全连接层,具有128个ReLU激活节点。

训练好两个模型后,将每个查询图像输入SLD网络以获得2D检测,然后根据内参将其转换为一组landmark方位向量B1,如果检测到超过八个场景landmark,使用鲁棒最小解算器(P3P+RANSAC)计算相机姿态,然后使用基于Levenberg-Marquardt的非线性细化。如果没有8个,将相同的图像输入NBE网络并获得预测方位B2,然后合并方位估计B1和B2的集合以形成新的集合B3,当集合B1和B2中的方位指向同一地标时,保留来自B1的估计,因为SLD通常比NBE更准确。最后使用上面描述的相同过程但使用B3计算相机姿态。如何从点云中选择有代表性的场景landmark提供给网络进行训练?从SfM点云P中找到L个场景landmark的最佳子集是一个组合问题,其中评估每个子集都是困难的。本文受之前以贪婪的方式寻找有区别的关键点或场景元素工作的启发,去选择鲁棒性(具有更长的轨迹)、可重复性(在多个场景中看到)和可概括性(从许多不同的观看方向和深度观察)的场景landmark,测量轨迹长度大于阈值t的3D点x的显著性得分A(x),如下所示:

除了最大化总体显著性得分之外还寻找在空间上覆盖3D场景的场景landmark以便从场景内的任何地方都可以看到一些地标,例如无论摄像机在场景中的哪个位置都希望一些地标可见。为此使用算法1中描述的约束贪婪方法

下图表述一些挑选到的landmark在二维图像中的投影的裁剪patch

实验:训练模型的细节可去论文中查看 实验数据集是在自己提出的INDOOR-6数据集和7Scenes数据集上

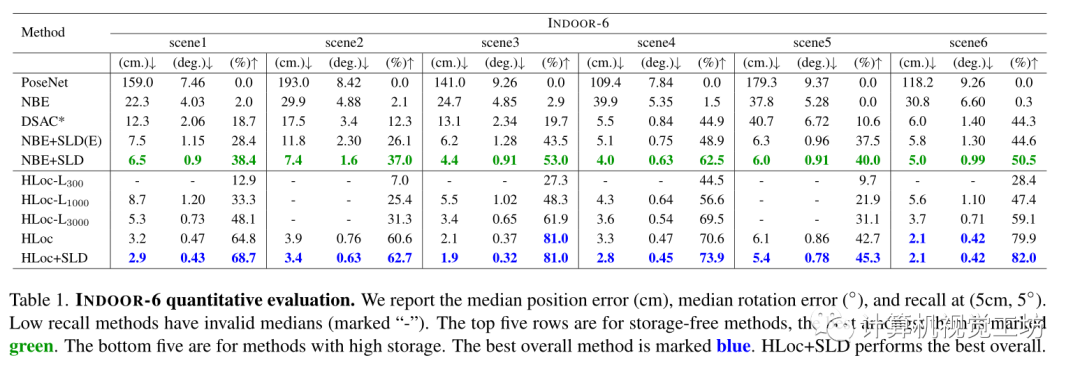
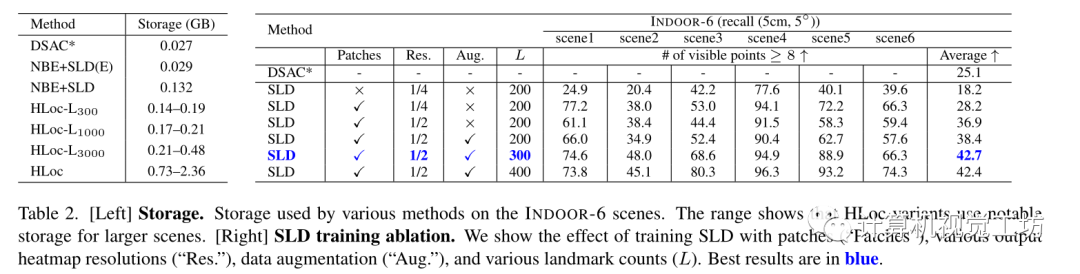
评估了单独使用NBE, SLD,联合使用NBE+SLD, NBE+SLD(E)(是更紧凑的网络),和SOTA的基于分层定位方法结合HLoc+SLD Baseline为Posenet、DSAC、HLoc 在INDOOR-6数据集上的结果:

存储比较和消融研究:
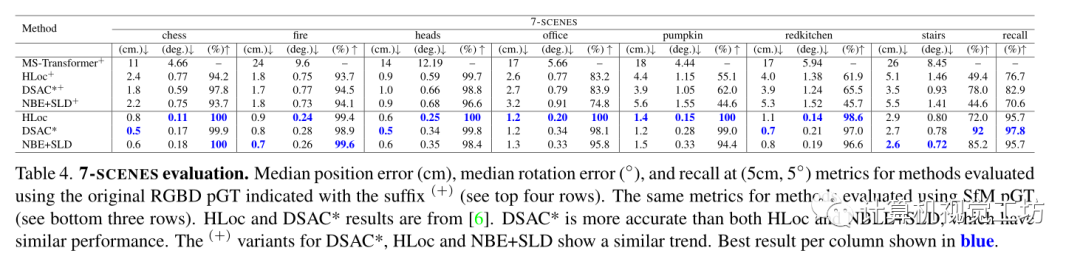
7Scenes数据集上的实验结果:
总结:算法是一种存储要求低但精度高的方法。主要见解是在人和物体姿态估计中广泛用于关键点检测的现代CNN架构也适用于检测显著的、场景特定的3D landmark。 实验结果表明,其方法优于以前的无存储方法,但不如HLoc(顶级检索和匹配方法之一)准确,但是HLoc需要高存储。而且基于landmark的2D–3D对应关系补充了HLoc的对应关系,并且在计算姿态之前结合这些对应关系进一步提高了HLoc精度。局限性:首先神经网络是特定于场景的,像其他学习方法一样每个场景需要许多训练图像,而且在使用之前需要仔细选择场景landmark集。
审核编辑 :李倩
-
云知声携手耘途教育成立云知学院福建分院,探索智慧教育新思路2024-05-11 1336
-
机器人设计:解决人类问题的新思路2023-08-07 1651
-
CVPR2022 人-物交互检测中结构感知转换相关资料推荐2022-11-09 3290
-
CVPR2020 | MAL:联合解决目标检测中的定位与分类问题,自动选择最佳anchor2022-01-26 475
-
西窗科技出席独立站卖家峰会,并分享出海新思路2021-11-18 3327
-
uwb定位技术原理及应用场景2021-06-30 3288
-
求大神分享设计虚拟仪器系统成为构建测试系统的新思路2021-04-14 1316
-
VR/AR+教育,颠覆传统教育模式,探索教育与文化传播的新思路2018-08-27 4298
-
程序控制器连接头封接技术与拓宽连接器研制的新思路2017-09-14 868
-
安卓平板未来的新思路2017-06-19 4404
-
聚焦电子创新设计,分享MCU技术新思路2009-11-10 849
-
喷漆室气流控制新思路2009-07-25 1120
-
汽轮机调节阀设计的新思路2008-12-22 843
全部0条评论

快来发表一下你的评论吧 !
