

schema设计:Nebula Graph 本身的存储结构和索引
存储技术
描述
图数据库的性能和 schema 的设计息息相关,但是 Nebula Graph 官方本身对图 schema 的设计其实没有一个定论,唯一的共识就是面向性能去做 schema 设计。
背景知识
先来讲解下存储背景,再讲 schema 设计中会遇到的问题,最后讲下实践过程中我们能达成一致的最佳实践。
在使用图数据库之前,先了解下图数据库这个 NoSQL 数据库同关系型数据库不一样的地方。
关系型数据库存储结构
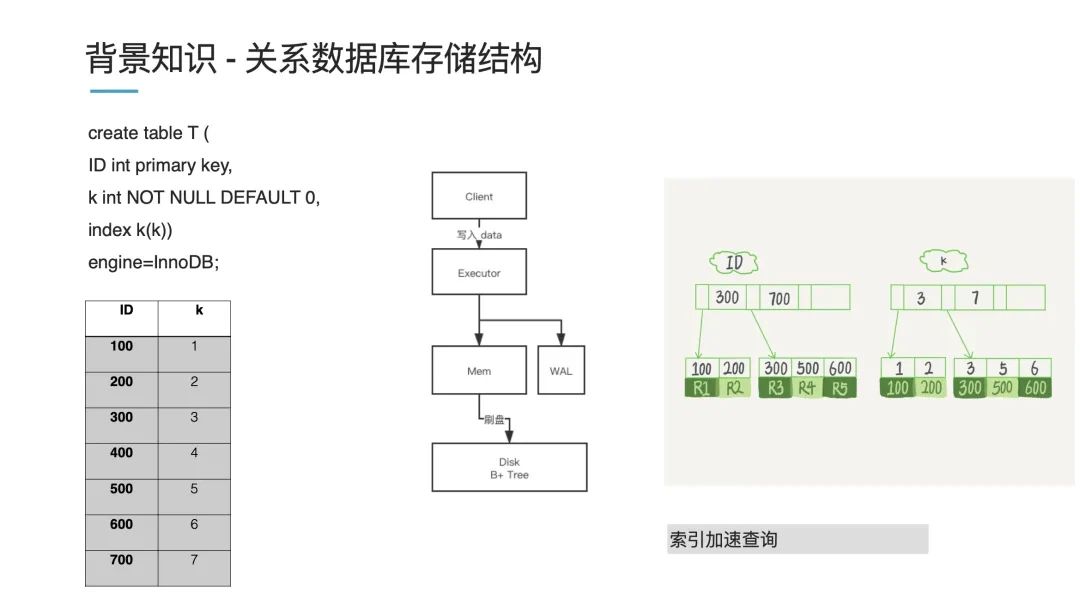
以上图为例,存一个 ID 作为一个主键,然后它有个特征 k,我们对 k 创建索引进行查询,对于左下角这份列表数据,内存中存储的话,会以一个 B+ 树进行存储(上图右侧):一个主索引 ID 和一个从索引 k。举个例子,现在我们要查询 k=3 的数据,它就先查询 ID=100 然后经过回表后回到具体的值。
这体现了关系型数据库的一个特点,如果你要查询速度快,那就需要创建一个索引。假如你不创建索引,那数据库就会扫全表。
我们再来看下写过程。数据一般先写到内存 Mem(这是一个常规的优化减小磁盘压力),写到一定程度再同步到磁盘中,这个过程我们叫原位刷盘,刷盘就是说找到这个地方的数据,然后修改掉数据,即原位修改。
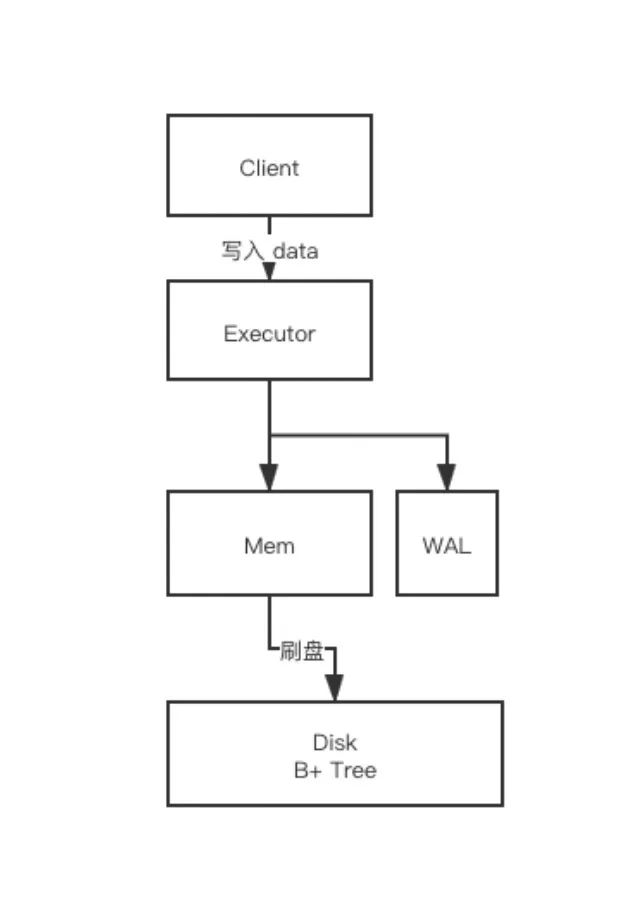
如果你之前熟悉 MySQL 或者是其他关系型数据库,这套原理应该是比较熟悉的。
而相对应的,用传统的数据库来实现图功能的话,代价比较大,下图便展示了它的实现弊端:
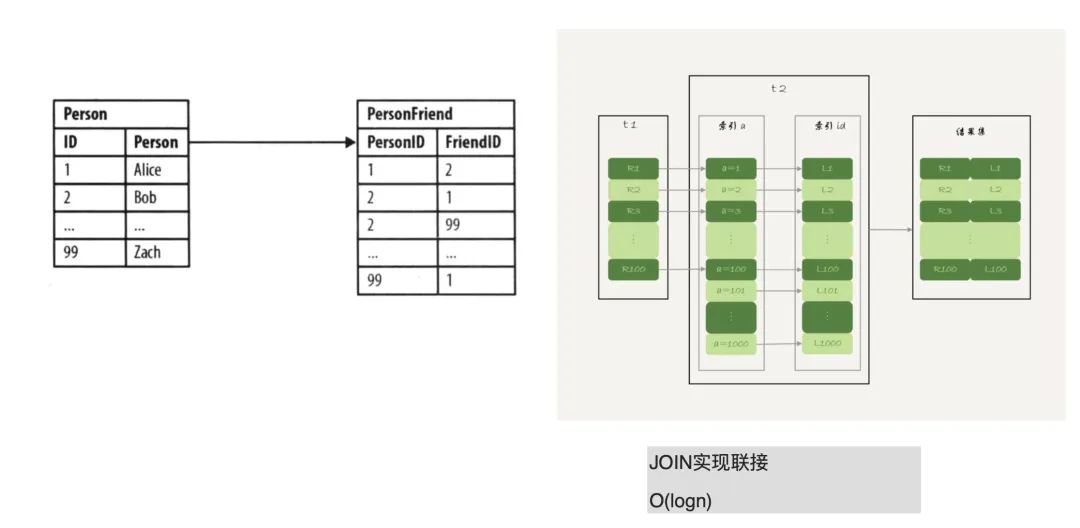
现在有个场景,现在我们有某个人(上图 Person 表),我们要找朋友的朋友(上图的 PersonFriend 表),在关系型数据库中便是两级索引,先查 Person 表索引找到 Person ID,再查 PersonFriend 表通过 ID 找到对应的人,就是一个 JOIN 查询过程。如果这里使用的是 B+ 树,那么程序复杂度便是 O(logn);如果是这里的多级大小表,在笛卡尔积上即 O(n*m),都加索引有一定程度优化,但查询这种多级关系的话,到了一定程度会遇到系统“爆炸”,无法进行相关查询。
LSM 存储模型
本文主题是图的高性能设计,主要基于 Nebula Graph 来讲解。这里部分存储细节同 Neo4j 会略有不同。
Nebula Graph 存储模型采用了 LSM 存储模型,同上面我们讲的原位修改不同,LSM 模型是先写内存,写到一定程度之后再写入到对应磁盘中,每次都是增量顺序写。LSM 模型是一个多级模型,第一层是 L0,第二层是 L1,一般默认是 7 层。
这里引用网图来讲解下 LSM 层级结构:
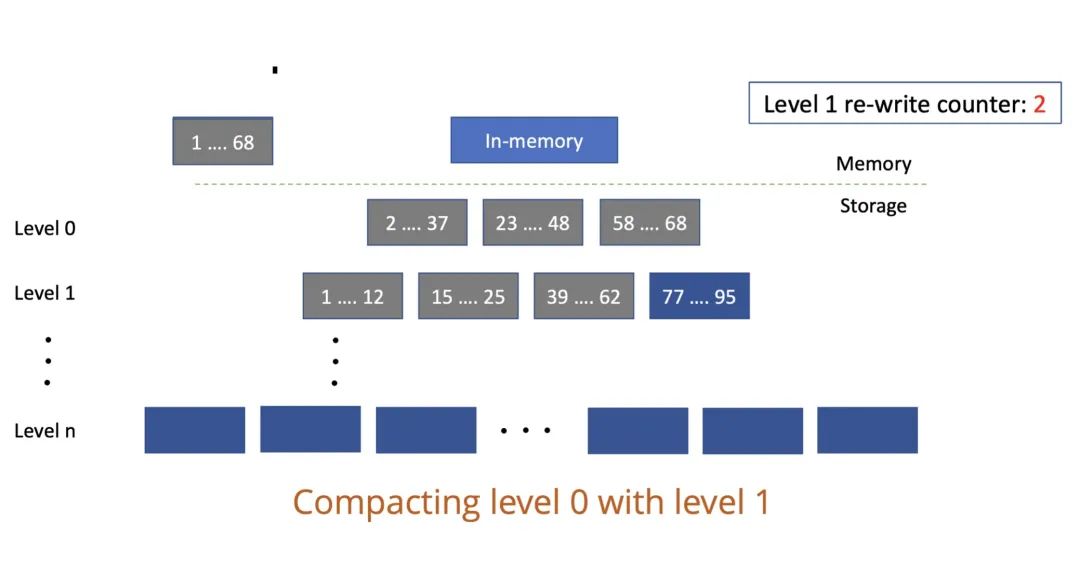
上图的 L0 层其实有重复数据,像上图的 1-68 的 key 在 L0 层的 2-37,以及 23-48,其实这两步数据是存在重叠的;但 L1 层的数据就不存在重叠情况了,1-12、15-25…要最大地发挥图性能的话,先得了解它的写入过程。LSM 模型的写是顺序写,即不会进行上文说到的原位修改。不管是写入新数据还是更新原来数据,永远是在后面插入新的数据(参考上图右侧深蓝色数据)。这样设计的好处在于,写入数据就不需要找之前的数据,一旦涉及查找数据就会慢,这样设计提升了写速度。
但这也会带来一个问题:我们写入重复的数据,或是写入的数据越来越多,查询会不会受影响呢?我们来看看 LSM 是如何查数据的。LSM 进行数据查询时,先查内存,内存里没有数据再查不可变区域(Immutable Memtable),没有的话,再往下一级级地查(参考上图左侧部分)。所以,重复的数据越多,或者磁盘数据越多,便会越慢。
所以为了保证写入和查询性能,无论我们设计属性还是其他 schema,都要控制写入量,也就是 LSM 的写入不能是无限制追加,它有一个定时的合并操作,定期地将重复数据进行合并,叫做 Compaction。
Compaction 过程也需要控制。合并数据能减小数据量,但同时 Compaction 会带来磁盘压力,磁盘压力过大,读操作速度也会变慢。综合来看,Compaction 是一个写入平衡的过程。
Nebula Graph 存储结构和索引
下面再来了解下 Nebula Graph 本身的存储结构和索引。
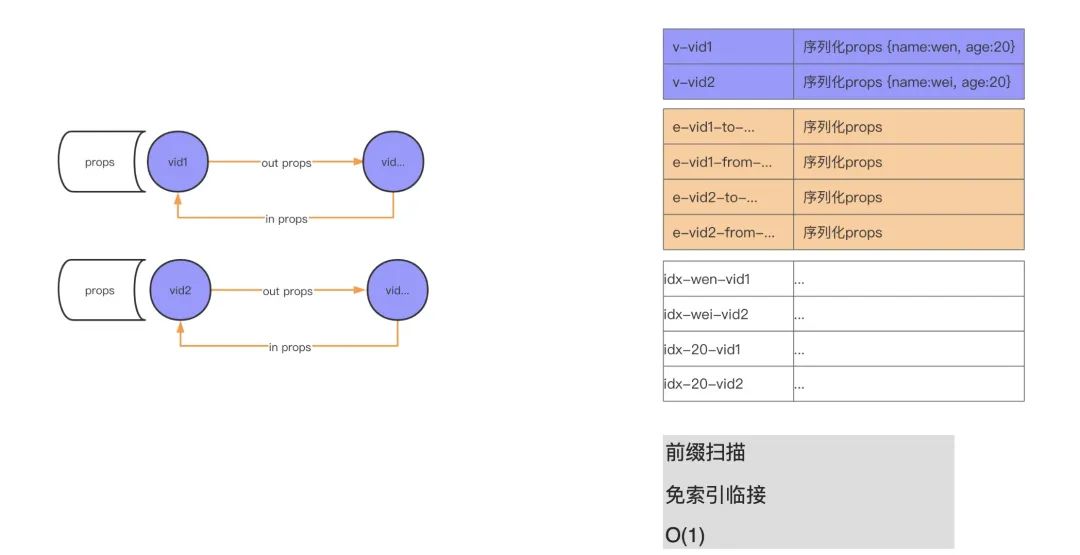
Nebula Graph 本身是分布式数据库,因为便于理解这里剔除了相关的分布式结构。简单来了解下 Nebula Graph 的结构,上面提到过的 LSM 其实是 KV(key value)存储,所以我们图里存储点、边、索引在磁盘上都是 KV 结构。我们可以看到上图左侧(紫色部分)有个 vid 带着出边(out)和入边(in)以及相关属性。再看下上图右侧部分(紫色部分),可以看到一条边的两个点是存储在一起的,对应的点属性序列化保存。相当于说,KV 结构中的 key 便是我们的点的 vid,然后 value 便是属性的序列化结构。因为是序列化的结构,所以你的属性名是什么便会存成什么,比如这里原始数据 name 字段,它改命名为 family_name,实际存储就是序列化后的 family_name,也就是属性名越长,存储量越大。除了属性名之外,其实属性值也会导致存储量增大。举个例子,现在有个人(点),他的生平介绍要不要放在属性里进行存储?答案是:不应该。因为你的生平介绍会很长,这就会导致 LSM 的存储压力会很大。无论是 Compaction 还是读写,都会有很大的压力。类似比如存储进程实体,对应的进程描述文本也较大,会带来较大存储压力。
再来说下我们的边,Nebula Graph 中出边和入边保存在一个 KV 结构中(参考上图右侧橙色部分)。Nebula Graph 中有个词叫做前缀扫描,具体来说便是现在要查找某个 vid 对应的边,它是如何查找的呢?先按照 vid 来前缀扫描,在内存中这个过程是个二分查找,所以 Nebula Graph 查询快就是在这里。在 Neo4j 里面这种叫做“免索引邻接”。像上面的朋友的朋友的场景,传统数据库是通过索引进行查找的,而在这里直接扫描找寻某个人便可。在物理存储这块,点(人和相关的人)都是存储在一起的,找到了某个人便找到了他的朋友。查询上速度非常快,这也是原生图数据库带来的好处。
除了上面的存储结构,索引也是高性能 schema 设计的一个作用因素。像上图的右侧部分,上面的紫色部分存储着点,这里有 2 个点:第一个点是 vid1,name 是 wen,age 是 20;另外一个是 vid2,name 是 wei,age 是 20。这里我们创建了 2 个索引,一个是针对 name,一个是针对 age。这两个索引的存储结构参考上图右侧下方的白色部分,查找 name 为 wen 的数据时,按照上面我们科普过的会进行二分查找,扫描到对应的 name 索引的 wen 数据,然后再从索引数据中找到对应的点(vid1)数据,再借助 vid 数据来找寻它的相关信息。这里 vid 找关联数据的原理同上面的存储结构描述。
小结
小结下 Nebula Graph 存储结构和索引,在这里关系是一等公民,索引辅助查询(并非用来提速),重要的是抽象关系。
schema 设计
进入本文的重点——schema 的设计,schema 设计的三大基本原则:
尊重领域实体关系
以性能为目标
考虑可视化分析
而三者并不冲突,上面三点其中某一点做得很好,另外两点也会做的不错。
Talking is cheap,下面我们来结合具体的例子来了解下三大原则。这些 case 图主要引用自 Neo4j,但是对于 Nebula Graph 相关的 schema 设计也有参考意义。
实体和关系的选择
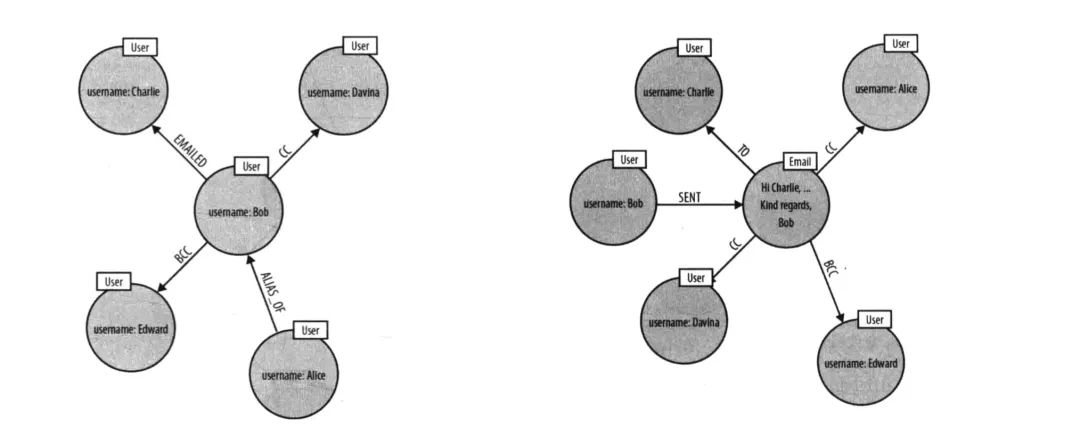
上图是 Neo4j 图数据库书籍中的示例图。简单描述下这个场景,Bob 和 Charlie 等人在发邮件。那你设计这么一个场景的 schema 是否很自然就会将发邮件变成关系边?因为 Bob 同 Charlie 发邮件,不是很明显就是发邮件关系吗?那我们来回顾下上面说的三大原则第一点:尊重领域实体关系。Bob 和 Charlie 建立联系自然不是通过发邮件这个行为,而是通过邮件本身来建立联系,所以这里便缺少了一个实体。在考虑可视化分析原则这边,你要分析实体之间的关系,你思考它们是通过什么来建立的联系。这时候就会发生之前提到过的发邮件设置为边的情况(把邮件放置在边上),单看 Bob 的话(左图),我们可以清楚地看到发邮件这个动作。左图上面部分,Bob Emailed Charlie。但如果这时候,要查看这个邮件抄送给了谁,还有这封邮件有哪些相关人,像左图的 schema 就不能很好地进行查询。因为缺少了 Email 这个实体。而上图右侧部分便能可以方便地找寻相关信息。
下面再来讲下如何进行实体和属性选择。
实体和属性选择
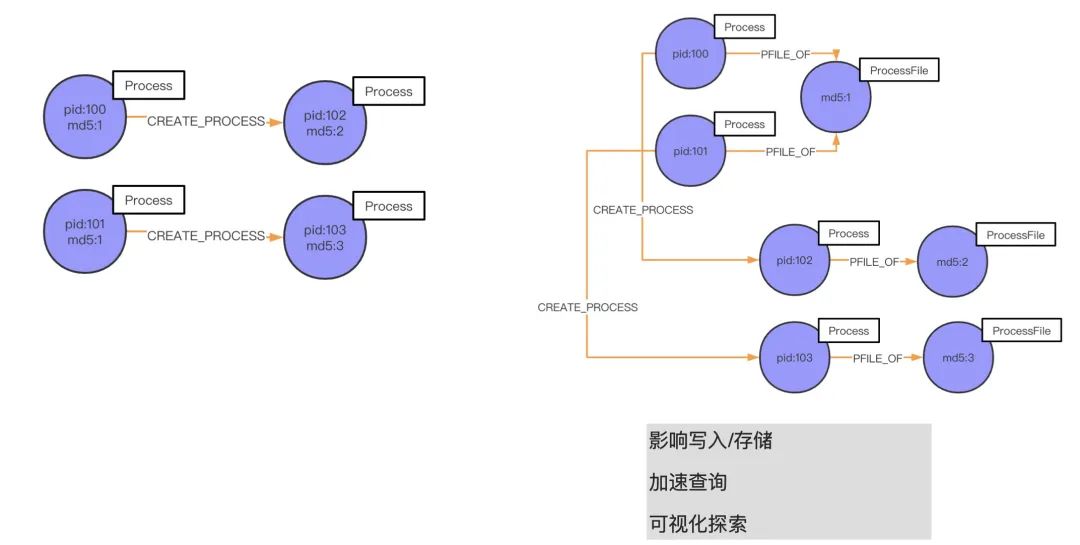
在这个部分,我将结合青藤云的情况来讲一个我们的 case——进程之间的父子关系。
如上图左侧所示,md5 为 1 的 pid 100 进程起了一个 pid 102 的子进程,这个子进程的 md5 是 2。同时,md5 也为 1 的 pid 101 也起了进程,pid 为 103、md5 为 3。按照我们之前的实现方法,是在 md5 上创建索引,继而建立起跟 pid 102、pid 103 的联系。但这种做法,上面讲过性能并不高,免索引复杂是 O(1),而这种做法的复杂度是 O(logn)。所以说,我们这时候应该基于 ProcessFile 进程文件 md5 来建立关系(进程间是基于 md5 联系起来的):我们先抽取 md5 建立一个名叫 ProcessFile 的实体,属性是 md5。如果我们要查询指定进程所关联的进程,很直观地去找寻和这个 ProcessFile 关联的进程就可以分析出来我们要的结果。举个例子,pid 102 的进程是一个木马,我想找寻是哪个父进程释放的它,或者是同它父进程同 md5 文件的进程,该怎么找?
上图的展示了两种形式,第一种(左侧)的话就需要找索引;第二种(右侧)通过 CREATE_PROCESS 就可以直接找到 pid 102 的父进程 pid 100,再通过 PFILE_OF 关系你可以找到它同 md 文件的进程 pid 101。
好的,简单结合 schema 设计三大原则来回顾下这个 case:
属性上创建索引会影响写入,此外属性放在 ProcessFile 还是放在 Process 中,存储性能是不一样的。这里主要涉及到写入量,因为 Process 进程是一直可以不停地启动,但是 md5 文件可能本身并不多。如果是放在 Process 中,进程起得越多,数据写入量也就会越大,进而查询压力也会增大查询变慢。
可视化探索这块主要和不定需求有关。因为一开始我们设计 schema 的时候可能并没有全方位考量,或者说像是一些安全、防作弊规则并未拟定,不知道它会是什么样。而这时你要根据这种不确定来设计 schema,就需要将图“释放”给相关业务人员,让他在图里点击,设计他的关系,所以相对应的我们就不能通过索引来实现这种需求,因为业务人员可能没有相关的技术背景。
添加属性
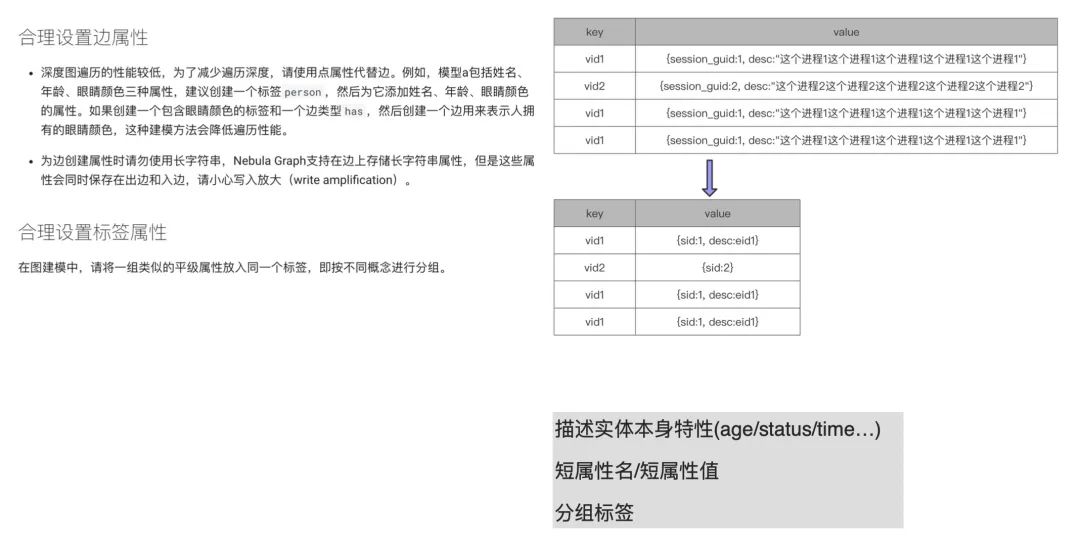
上图左边描述文字截自 Nebula Graph v2.0 的官方文档:
https://docs.nebula-graph.com.cn/2.0/3.ngql-guide/1.nGQL-overview/2.graph-modeling/#_3。
在合理设置边属性的第二部分提到,“为边创建属性时请勿使用长字符串”。这个和我们之前提到过的,属性名和属性值都应该短,不应该长是一个意思。像上图右侧部分,很明显可以看到 vid 重复写多次的话,每次写就是重复的流量和存储,这会大大增大内存占用和磁盘容量。如果我们把 session_guid 变成 sid 会节约很多存储。而后面的描述信息,也有两种处理方式。第一种,直接删除描述;第二种,将过长的描述存储在外部,比如放置在 Elasticsearch,然后将 ES 存储这块内容的 eid 存储在上图的 value 中。这样也可以大大减少存储量,提升写入 / 查询性能。
除了这点之外,我们还要注意合理设置分组标签。青藤云暂时没遇到类似 case,所以这里讲下这句话什么意思。简单来说,就是写入这边需要做一个 tag 的区分,结合上文提到的二分查找,你就比较好理解了。举个简单例子,这里有个人,他的公司相关信息,或者年龄相关的信息,或者是个人喜好之类的信息用相关的 tag 区分开,这样查询时可以更快地找到对应的信息。
最后回到文档「合理设置边属性」中第一部分中的“深度图遍历的性能较低,为了减少遍历深度,请使用点属性代替边。例如,模型 a 包括姓名、年龄、眼睛颜色三种属性,建议您创建一个标签 person,然后为它添加姓名、年龄、眼睛颜色的属性。”,按照官方举的例子,固然是这样的。但实际应用中,并非一定要遵循这一原则——属性用点属性而不是用边,该用实体的时候还是得用实体。所以我这里下面备注写了:描述实体本身特性。像实体本身的特性 age / status,边的 time / count 这些属性会变成相对应的属性,这样能更好地描述本质特性,也能起到比较好的辅助效果。
添加索引
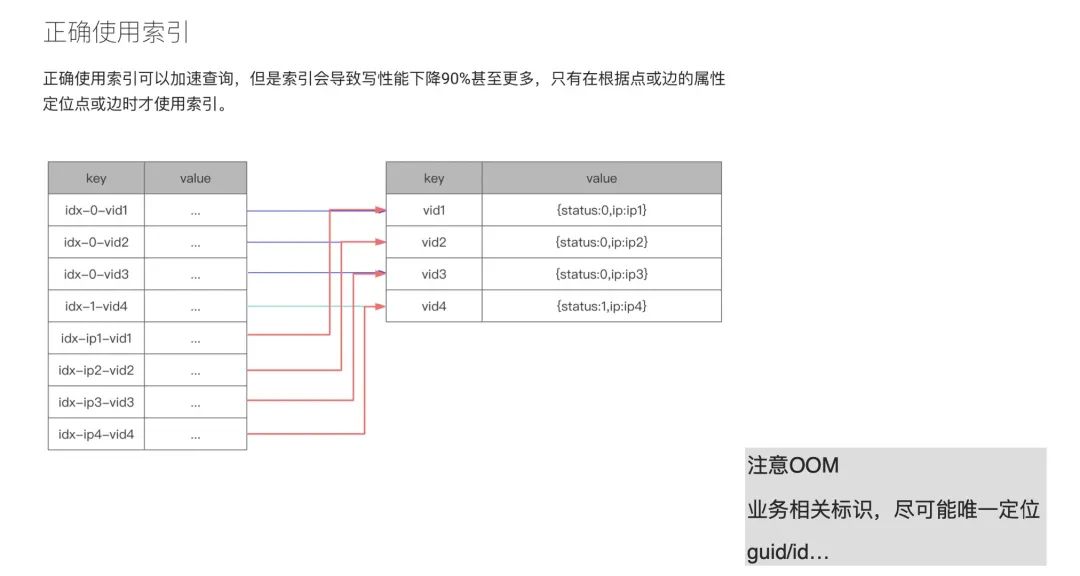
借助之前我们的实践经验,来讲下索引这块内容。在 Nebula Graph 的官方文档中提及了:尽量少用索引。那么问题来了,到底什么时候应该用索引呢?我们先从原理上来解释下索引。在上图的例子中,value 中存储了 2 样东西:一个是 status,状态;另外一个是 ip。右侧的表格是对应的 KV 存储结构,key 是个点结构。给点加索引之后,它便会变成左侧表格的结构,idx-x-vid1。如果我们要查询 status 等于 0 的这列值的时候,由于加了索引之后数据结构是以 0(status)为前缀,vid 放在 0 后面;如果我们要查询 ip 的话,存储结构则将 ip 变成前缀,vid 存储在后面。这样会产生何种问题呢?status 如果只有 1 和 0,现在你有 1 万亿的点,这样添加索引是没有意义的。而且,因为 Nebula Graph 的查找是二分查找,复杂度收敛到 O(n),相当于有多少数据就查多少数据。即便你添加了一个 limit,但是在 Nebula Graph 这边(注:本次分享时,Nebula Graph 的最新版本为 v2.0.1)limit 并没有下推,所以所有数据会先捞上来到计算层,在内存中使用 limit 进行数据过滤。
正是由于这种情况,所以在 v2.5 之前的 Nebula Graph 用户会经常在论坛反馈 OOM 问题,其实就是内存爆炸。
所以说,索引应该是尽可能和业务相关的标识。
细粒度关系和通用关系
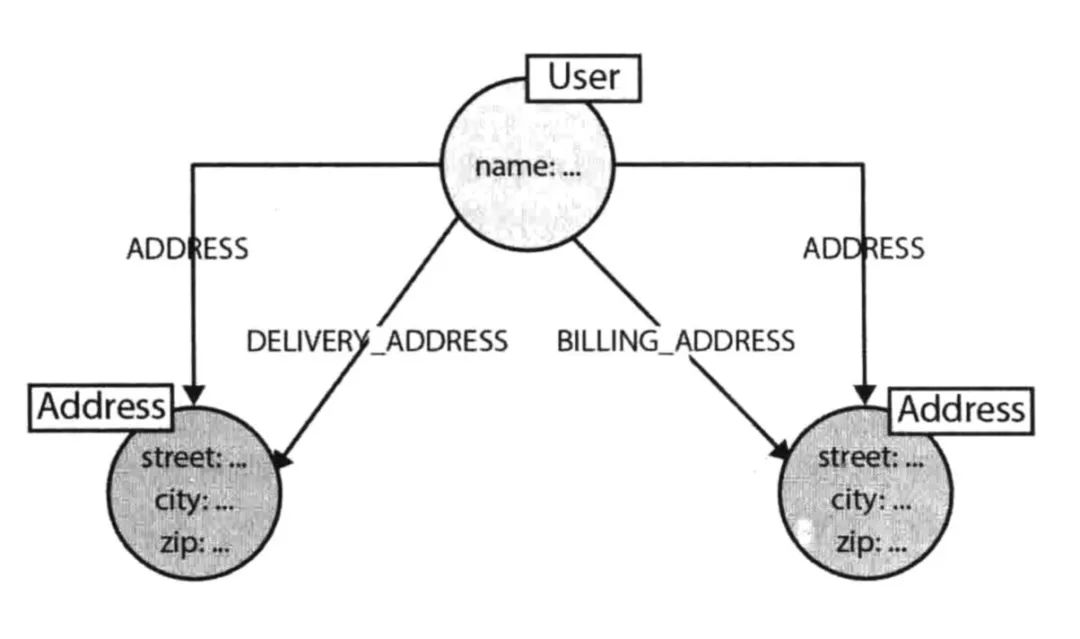
通过上面的 Neo4j 这个 case 我们来讲解下颗粒度问题。
像上面的人有 2 个地址,一个是收件地址,另外一个是付款地址。如果此时,我们想找寻这个人的地址,如果没有 ADDRESS 这个通用标签的话,DELIVERY_ADDRESS 和 BILLING_ADDRESS 这两个关系都得查下。这时候如果用的是二分查找,如果这堆关系本身存储在一起还好,可以一次性查找出来;但,如果关系不在一起,就需要分 2 次查询,这会降低它的查询速率。
因此,我们可以再创建一个通用标签,但是要注意的是,标签的建立是基于对某个业务有强需求。像上面的例子,需要知道用户的所有地址,也要知道他的单独地址,比如:收件地址。这种情况下,建立一个通用标签才是一个加速的方法,但注意要谨慎使用。同样的,通用标签设计时,也需要考虑可视化的情况。
加速查询
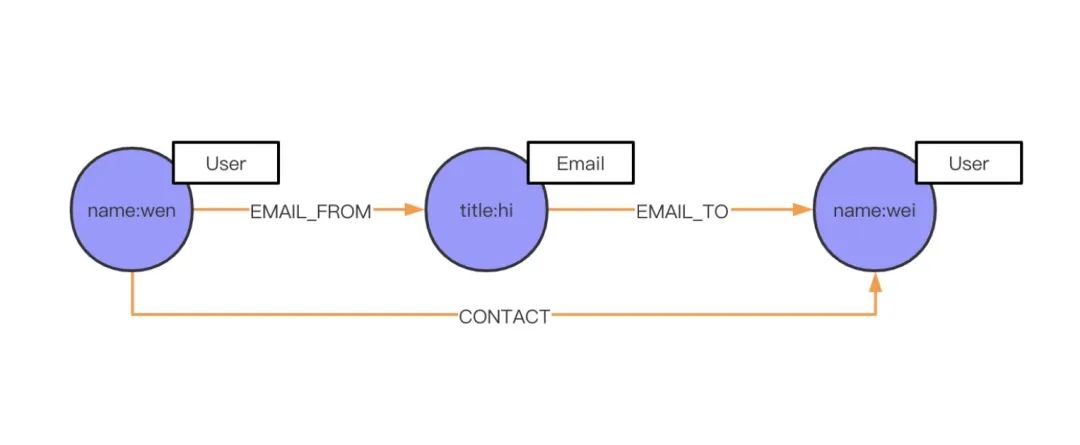
之前我们讲过一个发邮件的例子,但是现在场景有所变化了,我现在不关心发邮件这个事情,我只关心人和人之间的关系,比如,wen 这个人的联系关系,有谁和他联系过,而这个联系方式可能是 Email,也可能是手机(Phone),或者是微信。这时候我应该如何设计 schema 呢?当然之前的设计是可以沿用的,但为了加速查询,满足业务上的需求。这里加了 CONTACT 属性,用来加速查找。
小结 schema 设计
讲到这里,我们总结下上面的例子,其实我们的例子都是围绕着三大原则来展开的,即:性能、可视化、领域关系。
典型 schema 设计
下面来我们来讲下有些典型场景下的 schema 设计。
时间设计
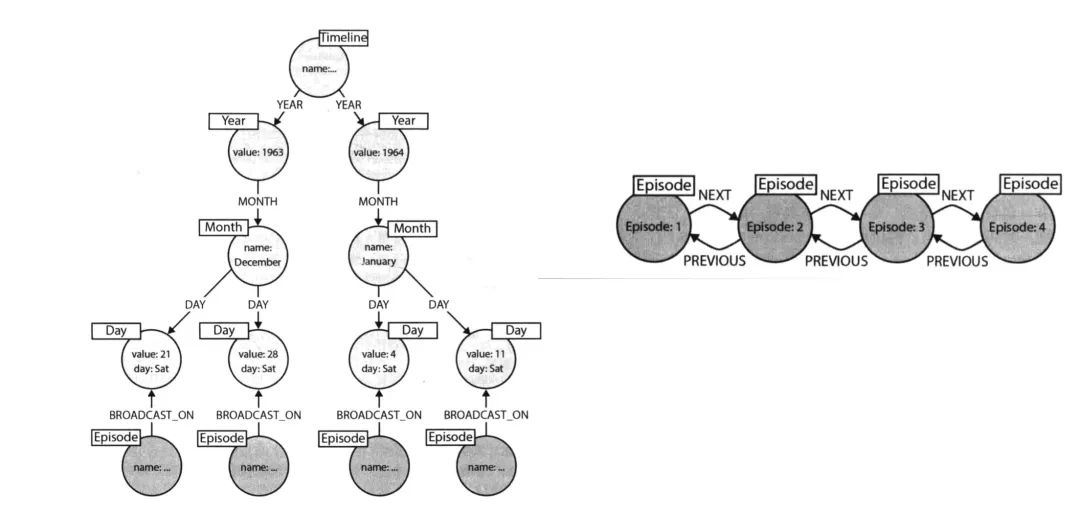
现在有个场景,有一堆发生过的事件,现在想查询在某个月,或者是某个时间段内,发生了哪些事件,我们该如何设计 schema 呢?也许我们可以在时间属性上创建个索引,把这个时间当作索引来存储,但这样的话,查询速度不会很快,尤其是数据量较大的情况下。那我们应该怎么做呢?Neo4j 给了一种设计思路叫做时间树,就是说时间本身是有层级关系的。如上图所示,时间有个层级,想要查询某个事件同时间段内的其他事件,可以通过这个层级快速找到。
上图右侧则是一个时序关系,可以快速找寻某事件发生的时间前后有哪些事情发生,而在 Nebula Graph 中,你可以通过 rank 来实现时序图功能。
上面的例子只是给大家一个参考,并不代表会应用在青藤云实际业务中。
地址设计
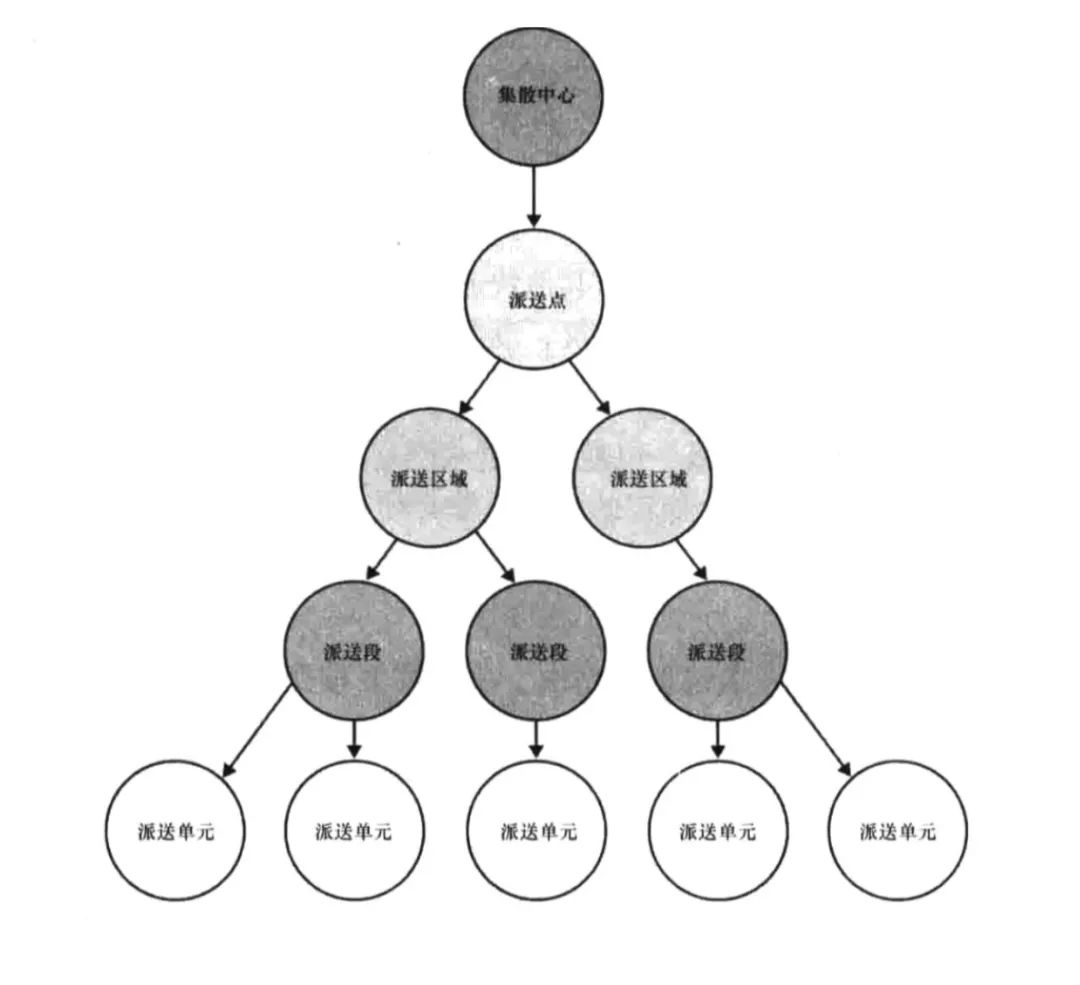
上面这个是地址的设计,可能大家都会遇到。假如,现在我们要查询北京朝阳太阳宫在发生事件 A 时,同一个地理位置有多少用户 / IP 在这。传统的设计方法中,添加属性是无法满足该业务需求的。那怎么实现呢?其实这些地址划分可以作为实体,而且地址之间是有关系的。以上述的物流为例,上面的例子:中国-北京-朝阳-太阳宫,就可以通过集散中心-派送点-派送区域-派送段形式进行查询。如果你要查询同一个街道或者是同个市,也可以按照这个关系快速进行查询。
像我们遇到的地址位置,或者是网络层问题,都可以参考这种设计。之前在 BOSS 直聘(分享嘉宾曾就职 BOSS 直聘)中,我们就是参考了类似的实现来找寻某个区域的相关用户。
图最佳实践
上面讲述的内容主要是围绕 schema 设计,下面这块当作补充资料,主要讲的是图的最佳实践。
命名规范
如果你要编写一个比较长的语句,不知道你有没有注意过,这个语句该如何快速区分哪些是实体,哪些是关系,哪些又是属性。所以,这里就要提一下命名规范问题。一旦命名规范了,一条长查询语句也可能快速辨别实体、关系、属性。
你可以参考下面的命名规范:
实体采用驼峰方式,例如:User、Email、Process;
关系采用全部大写,包含动词和副词,例如:HAS_IP;
属性采用英文小写简写,例如:title、sid、pid
图计算
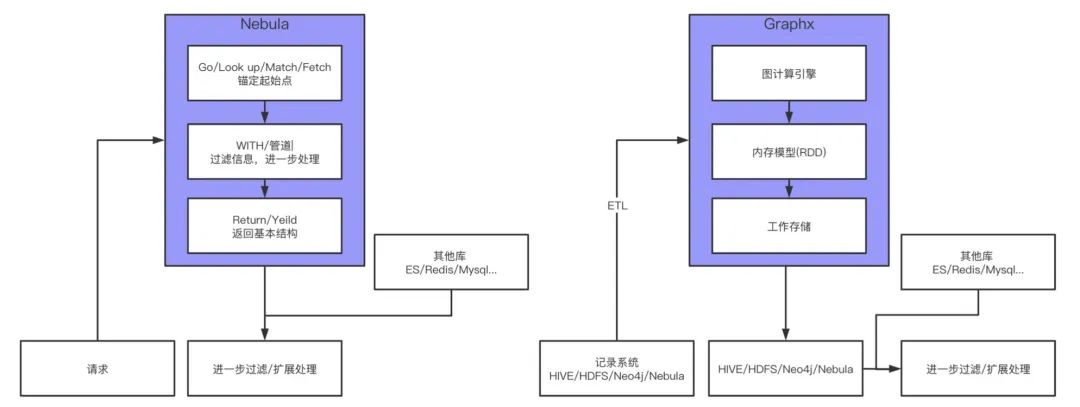
上图给出了图数据库和图计算的工作流,可以直观地查看到二者的区别。图数据库的工作流相对简单,拿我们常见的一个场景举例,已知某个有问题的进程 A,要溯源找寻它的源头。对应到图这边,图数据库的查询一般会 GO / LOOKUP / MATCH / FETCH 锚定某个起始点,比如这里的进程 A,然后管道 / WITCH 进行下一步的处理,最后用 RETURN / YIELD 来返回基本结构。但,注意,这个基本结构会进行二次加工。刚设计 schema 的时候提到过,并不是所有的属性都会设计进去,只有和业务相关的核心属性才会设计进入。像请求接口之类的操作,都会在下一步过滤 / 扩展处理时完成。
上面说的是图的直接业务简单查询,但还有一种场景是用图来进行机器学习,比如 GNN 和 GCN 用图来做特征,这块本文就不展开讲述,流程和上面有所不同。
那,什么时候用图数据库,什么时候用图计算呢?

如上图所示,有限点的拓展就比较适合用图数据库,或者说 Nebula Graph 来实现;而全局挖掘就比较适合用图计算。从图计算的流程上来看,简单粗暴地讲,图计算就是把一批数据捞到内存中,一次性计算完,然后“吐”出来,再进行下一步的过滤和处理。至于它是如何计算的,图计算里面配有计算引擎。
现在我们来问个问题,如果要找全图点度 Top10 的点,应该用什么?
自然是图计算,图计算也就是 OLAP 主打的是吞吐,即一次性能处理多少数据;而图数据库,主要是应对 OLTP 场景,侧重低延迟,就是查询有多快,以及支持多大量的并发请求 QPS。
只要我们记住图数据库和图计算各自的擅长场景,就比较好处理相关的业务。
大图优化
像传统关系型数据库中,业务无限膨胀的话,就需要做分库分表。图也是类似的,在大图上做某些查询时,你会发现性能很差,这时候你就需要进行分图处理。像上面说到过的关系细化和加速查询,比如我现在只关心进程关系,在特定业务场景下就需要将进程关系单独设计成一张图。这就是图的一个优化手段。或者,你也可以进行业务隔离。像现在的业务是针对推荐场景,剩下的安全场景是否要放置在同一个图空间下呢?如果业务量不大的情况下,是可以的。但是如果是数据量大的话,还是需要同传统数据库一样进行业务隔离,什么业务进入什么图。
这里延伸一下,分图场景下如何进行多图查询呢?简单来说就是进程一张图,网络是一张图,这时候要查询进程和网络的关系。业界的话,管这个叫做查询端融合。虽然你要查询的数据是 2 张图,但是我假装你是在一张图上进行查询。
编辑:黄飞
-
MySQL索引的常用知识点2023-09-30 1312
-
MySQL为什么选择B+树作为索引结构?2023-07-20 2023
-
列存储索引的空间使用2023-06-25 1548
-
gRPC-Nebula微服务框架2022-06-22 1025
-
数据库中的schema2022-06-07 8094
-
GRAPH顺控器的结构及如何实现创建2022-03-09 5767
-
基于POI分布的空间索引结构TDG2021-06-25 870
-
如何利用Flood多维索引技术实现优化数据存储布局2020-09-22 4781
-
如何利用二步索引算法改进字符索引结构的OSD电路?2019-08-13 1628
-
基于KD树和R树的多维索引结构2018-01-25 1579
-
基于存储系统SILT基本结构的详细解析2018-01-22 6547
-
双层索引的起源图查询方法2017-12-07 1090
-
基于分段哈希码的倒排索引树结构2017-11-28 1060
-
Schema2008-10-07 2517
全部0条评论

快来发表一下你的评论吧 !
