

使用MAX78000进行人脸识别
描述
MAX78000为超低功耗卷积神经网络(CNN)推理引擎,用于在物联网的微小边缘运行人工智能(AI)计算。然而,该设备可以执行许多复杂的网络,以实现关键和流行的应用。本文介绍一种在MAX78000上运行人脸识别(FaceID)的方法,该方法使用Maxim在PyTorch上的开发流程构建模型,使用不同的开放数据集进行训练,并部署在MAX78000评估板上。
介绍
40多年来,人脸识别系统一直是研究的主题。机器学习的最新进展导致了研究的急剧增加和许多成功方法的出现。面部识别或识别技术今天比过去任何时候都更加重要,因为它非常普遍,并且引入了有关如何捕获和共享面部信息的隐私问题。除了隐私问题外,这些应用程序的延迟和功耗对于许多移动或物联网设备也很重要。
本应用笔记研究了使用MAX78000 CNN推理引擎在边缘运行人脸识别(FaceID)以最小的延迟和优化的功耗。该应用面临的挑战是设计具有高性能的CNN架构,同时保持网络中的系数数量比许多尖端的深人脸识别网络(即DeepFace)少300倍。[1].
卷积神经网络(CNN)非常有用,因为它们允许从输入数据中学习位置和尺度无关的特征。卷积内核的长度一般较小,即 3 × 3、7 × 7 等,提供了极大的内存效率。随着许多不同的研究表明所提供的性能提升以及模型大小的减小,对这些网络的兴趣有所增加。这种架构的缺点是计算负载较高,可能会产生高能耗和延迟。本研究通过MAX78000的独特设计克服了这些问题。
本文简要介绍MAX78000 CNN推理引擎,并介绍开发模型以识别适合芯片的人脸的方法。然后描述所开发模型的综合,并解释MAX78000评估板的应用软件。
CNN 推理引擎 – MAX78000
The MAX78000[2]是一种新型人工智能 (AI) 微控制器,旨在使神经网络能够以超低功耗执行并生活在物联网边缘。该产品将最节能的AI处理与Maxim经过验证的超低功耗微控制器相结合。基于硬件的 CNN 加速器使电池供电的应用程序能够执行 AI 推理,同时仅消耗微焦耳的能量。这使其成为能源关键型应用的理想架构。MAX78000具有带浮点单元(FPU)CPU的Arm Cortex-M4,通过超低功耗深度神经网络加速器实现高效的系统控制。图1.MAX78000的结构显示了MAX78000的顶层架构。®®
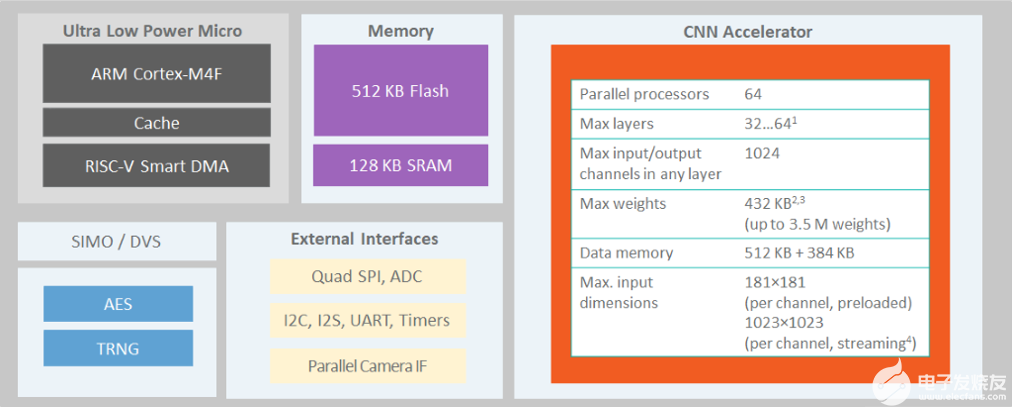
图1.MAX78000的结构
MAX78000评估板[3]提供一个平台,利用MAX78000的功能构建新一代AI器件。评估板具有板载硬件,如数字麦克风、串行端口、摄像头模块支持和3.5英寸触摸彩色薄膜晶体管(TFT)显示屏。
MAX78000开发流程
PyTorch或TensorFlow-Keras工具链可用于开发MAX78000的模型。该模型是使用一系列表示硬件的已定义子类创建的。池化或激活等一些操作融合到 1D 或 2D 卷积层以及全连接层。还添加了舍入和剪裁以匹配硬件。
该模型使用浮点权重和训练数据进行训练。权重可以在训练期间(量化感知训练)或训练后(训练后量化)量化。可以在评估数据集上评估量化结果,以检查由于权重量化而导致的精度下降。
MAX78000合成器工具(ai8xize)接受PyTorch检查点或TensorFlow导出的ONNX文件作为输入,以及YAML格式的模型描述。输入示例数据文件(.npy文件)也提供给合成器,以验证硬件上的合成模型。将此数据文件的推理结果与预合成模型的预期输出进行比较。
MAX78000频率合成器自动生成C代码,可在MAX78000上编译和执行。C 代码包括应用程序编程接口 (API) 调用,用于将权重以及提供的示例数据加载到硬件,对示例数据执行推理,并将分类结果与预期结果进行比较,作为通过/失败健全性测试。此生成的 C 代码可用作创建自定义应用程序的示例。图2所示为MAX78000的整体开发流程。
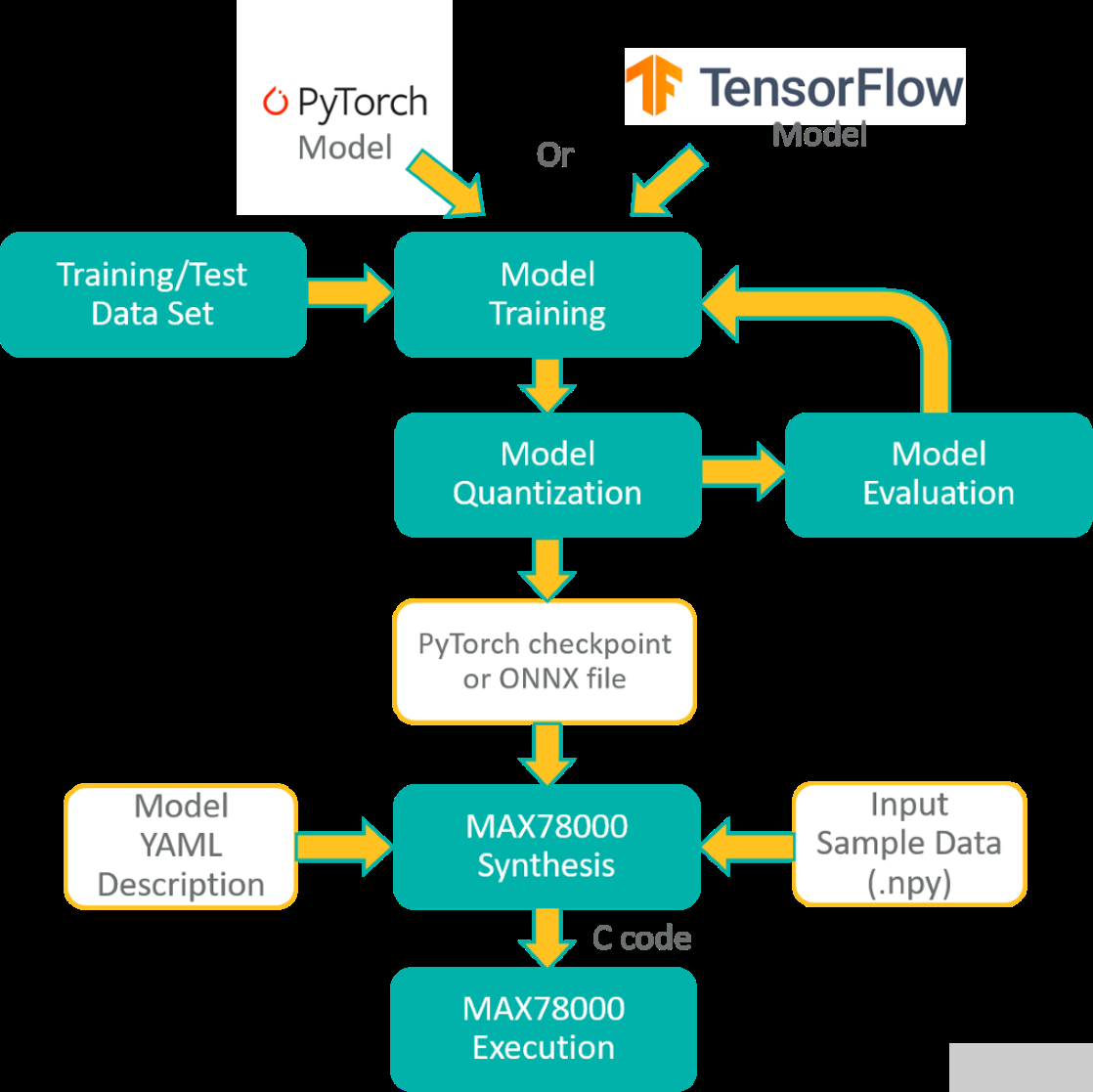
图2.MAX78000的开发流程
面容模型开发方法
人脸识别问题分三个主要步骤解决:
人脸提取:检测图像中的人脸以提取仅包含一个人脸的矩形子图像。
面部对齐:确定子图像中面部的旋转角度(3D),以通过仿射变换补偿其效果。
人脸识别:使用提取和对齐的子图像识别人。
前两个步骤有不同的方法。多任务级联卷积神经网络 (MTCNN)[4]解决人脸检测和对齐步骤。人脸识别通常作为一个不同的问题来研究,这是本次演示的重点。MAX78000评估板用于识别未裁剪的人脸,每张脸仅包含一个人脸。
所采用的方法基于为每个面部图像学习签名,即嵌入,其与另一个嵌入的距离可以衡量面部的相似性。预计可以观察到同一个人的脸之间的距离很小,而不同人的脸之间的距离很大。
面网[5]是为基于嵌入的人脸识别方法开发的最流行的基于 CNN 的模型之一。三重损失是其成功背后的关键。此损失函数采用三个输入样本:锚点、与定位点来自同一恒等的正样本和来自不同恒等式的负样本。当锚点的距离接近正样本而远离负样本时,三重损失函数给出较低的值(图 3)。
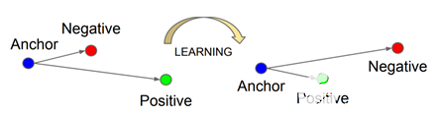
图3.三重损耗使锚点和正极之间的距离最小化,并使锚点和负极之间的距离最大化[2].
但是,该型号有750万个参数,对于MAX78000来说太大了。它还需要 1.6G 浮点运算,这使得该模型很难在许多移动或物联网设备上运行。因此,设计了小于450k参数的新模型架构,以适应MAX78000。
采用知识蒸馏方法来开发FaceNet的这个更小的CNN模型,因为它是FaceID应用程序广泛赞赏的神经网络。
机器学习中的知识蒸馏是将知识从大型模型转移到较小模型的过程[6].大型模型比小型模型具有更高的知识容量。然而,这一能力可能没有得到充分利用。因此,这里的目的是将大网络的确切行为传授给较小的网络。
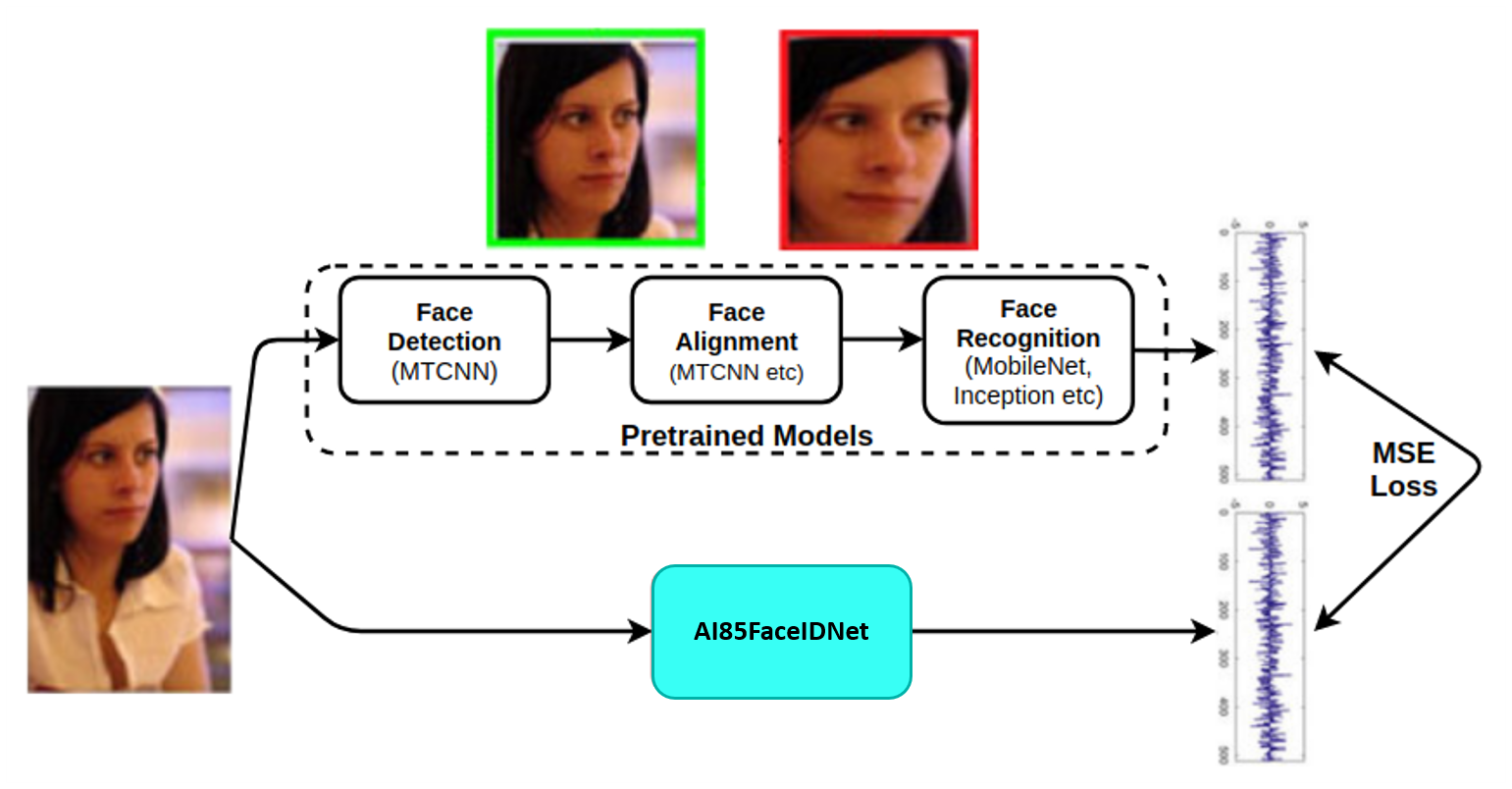
图4.模型开发的方法。
图4.模型开发方法总结了如何利用预训练的MTCNN和FaceNet模型来开发紧凑的FaceID模型AI85FaceIdNet。嵌入FaceNet模型被用作AI85FaceIdNet的目标。没有中心损失、三重损失等,因为这些都由 FaceNet 模型覆盖。模型开发中使用的损失是目标嵌入和预测嵌入之间的均方误差 (MSE),这也是定义人脸相似性的距离。
数据
模型的训练是使用以下数据集完成的:
VGGFace-2 [7]:一个大规模的人脸识别数据集。
YouTube面孔[8]:旨在研究不受约束的人脸识别问题的人脸视频数据库。
根据网络上找到的六张图像为选定的 15 位女性和 15 位男性名人创建一个数据集来测试模型。此数据集在本文档的其余部分中称为 MaximCeleb。
数据集生成和扩充
数据集中的每个图像随机裁剪 120 × 160 × 3(宽度×高度×深度)子图像。由预训练的MTCNN模型在子图像中检测到并对齐的人脸被馈送到预训练的FaceNet模型以创建嵌入。请注意,两个重新训练的模型都取自[9].因此,生成的嵌入的长度为 512。最后,将 120 × 160 个 RGB 面部图像与其所有者和嵌入一起存储,以便在训练期间使用。
面部在新图像中的位置和方向各不相同。预计它应该有一个模型,该模型对图像中头部的少量转换具有鲁棒性。
CNN 模型训练
MAX78000 FaceID型号AI85FaceIdNet由8个顺序卷积模块组成。图7.AI85FaceIdNet网络结构显示了CNN模型。某些图层包括池化操作以减小输入的大小。类似地,将 512 × 5 × 3 大小的张量与 (5 × 3) 核平均,以获得最后一层的 512 大小的嵌入。

图7.AI85人脸网络结构。
使用以下命令使用Maxim工具对模型进行训练:
train.py –epochs 100 –optimizer Adam –lr 0.001 –deterministic –compress schedule-faceid.yaml –model ai85faceidnet –dataset FaceID --batch-size 100 –device MAX78000 –regression
该脚本在训练过程结束时创建模型的检查点文件,并在验证集上得分最高。然后,对浮点权重进行量化,MAX78000为整数运算器件。使用以下命令的Maxim工具进行转换也很简单:
./quantize.py --device MAX78000 -v -c networks/faceid.yaml –scale 1.05
模型性能
使用包含30位名人(15位女性和15位男性)面孔的MaximCeleb数据集分析模型的性能。
对于女性和男性数据集,通过使用其自身嵌入到其余89张图像嵌入的距离,根据每个图像的识别准确性,分别评估模型的性能。用于定义最近嵌入的距离度量和算法也是应用程序中的度量和算法。
在此分析中,选择 L2(欧几里得)范数作为嵌入之间的距离。提取所有主体的嵌入到给定图像嵌入的平均距离,以确定最近的主体。然后,该算法返回其嵌入平均最接近给定嵌入的主题。表1显示了MTCNN和FaceNet组合的性能,以及MAX78000上运行的AI85FaceIdNet的性能。图 8 和图 9 显示了每个数据集的混淆矩阵。
| 马克西西勒布数据集 | ||||
| 女性 | 雄 | |||
| MTCNN+FACENET | AI85面孔 | MTCNN+FACENET | AI85面孔 | |
| 准确度 (%) | 94.4 | 78.9 | 94.4 | 88.9 |
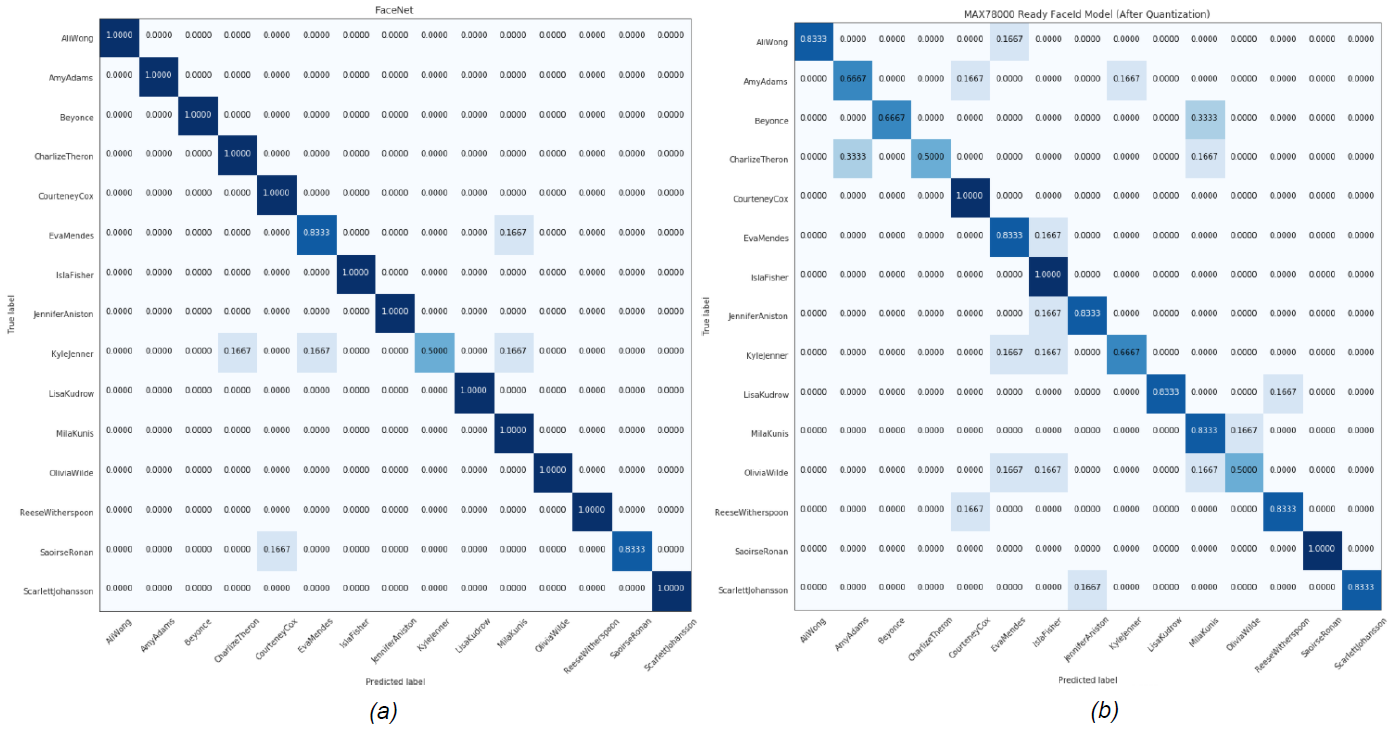
图8.女性MaximCeleb数据集的(a)MTCNN+FaceNet (b)AI85FaceIdNet模型的混淆矩阵。
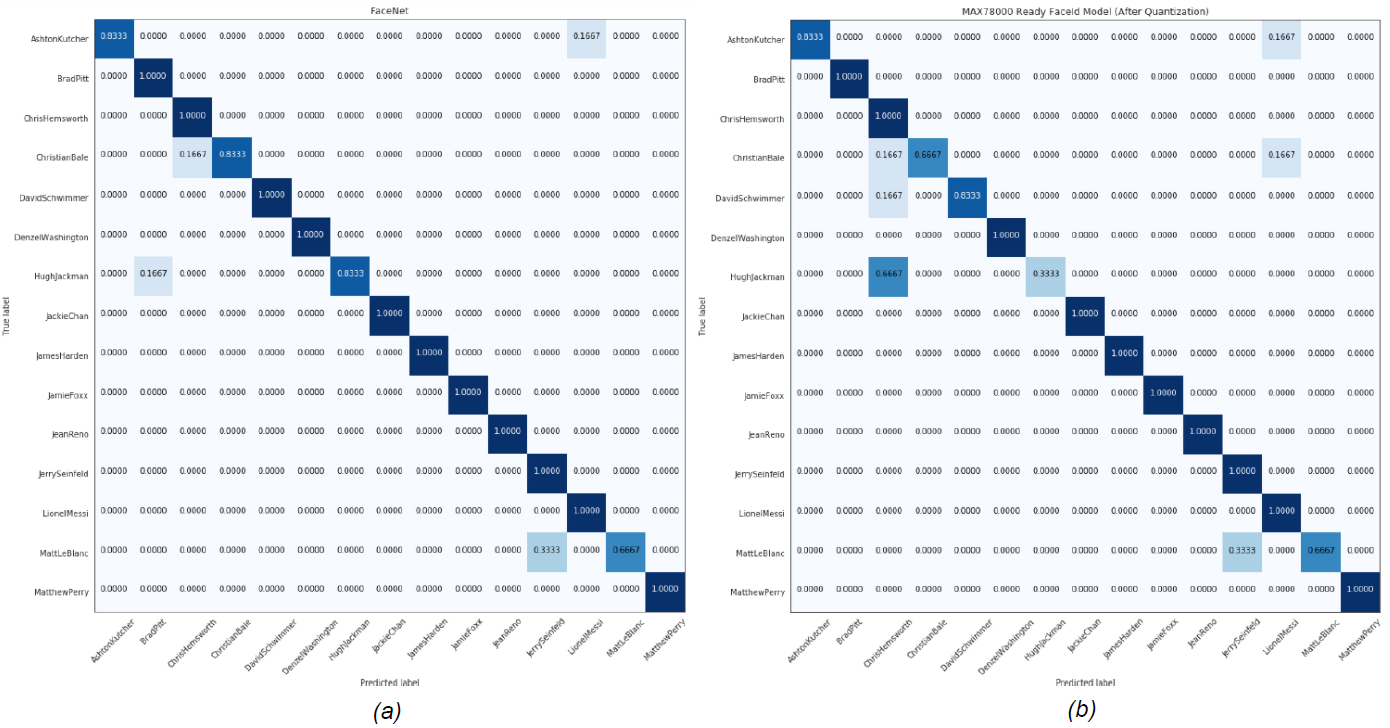
图9.男性MaximCeleb数据集的(a)MTCNN+FaceNet(b)AI85FaceIdNet模型的混淆矩阵。
识别未知受试者
利用所开发模型的受试者工作特征(ROC)曲线来识别未知受试者。ROC 曲线是一个图形图,说明了二元分类器系统在其区分阈值变化时的诊断能力[10].
上一节将人脸到主体的距离定义为人脸嵌入到为每个主体存储的整个嵌入的平均 L2 距离。决定是在确定与面部嵌入的距离最小的受试者时做出的。可以使用模型的 ROC 确定最小距离的阈值,因为每个图像都被标识为数据库中的主体之一。
ROC 曲线是通过绘制不同阈值下的真阳性 (TP) 率与假阳性 (FP) 率的对比来创建的。因此,当它在ROC曲线上移动时,阈值设置会发生变化,并且可以相对于所选性能确定阈值。
30个受试者的Maxim Celebrity数据集用于生成ROC曲线,其中数据库中仅假设有15名女性(或男性)受试者。其余的被确定为未知受试者。正确分类的样品可提高 TP 率,而其他样品可提高 FP 率。图 10 显示了男性和女性数据集的 AI85FaceId 模型的 ROC 曲线。
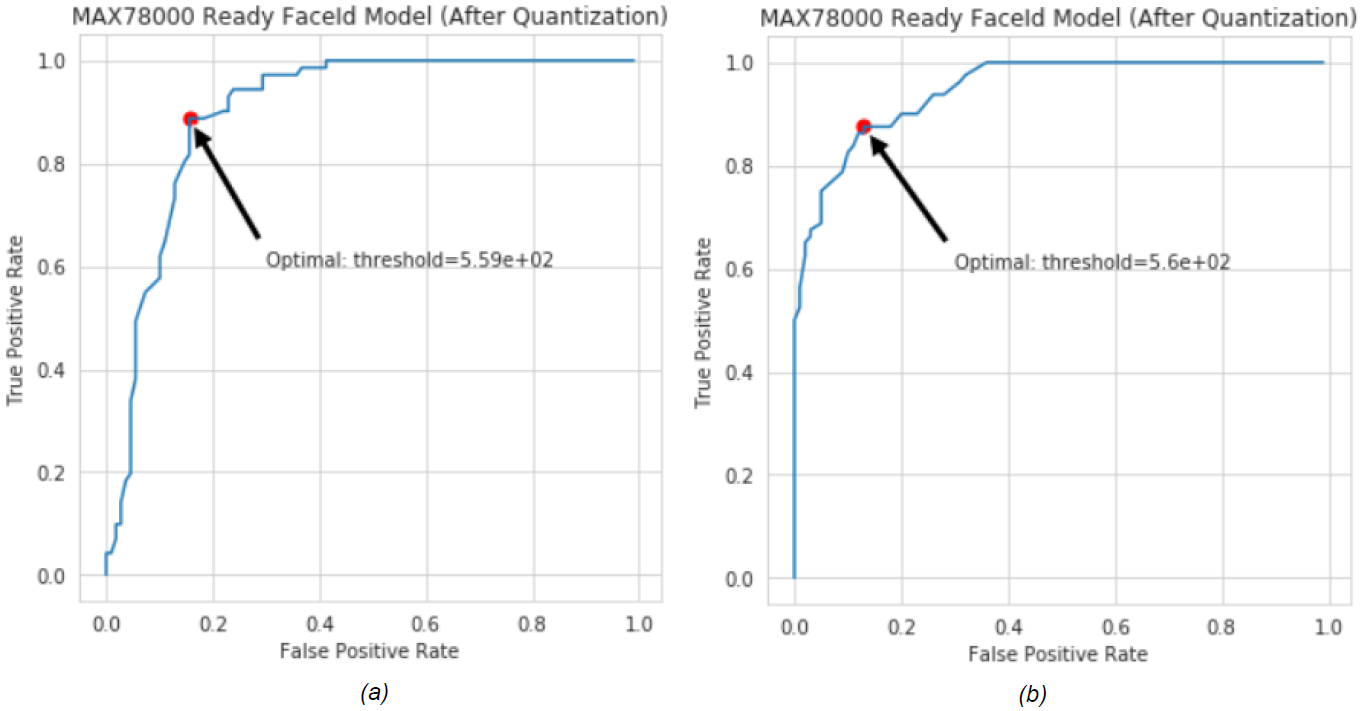
图 10.AI85FaceIdNet的ROC曲线,用于(a)女性和(b)男性MaximCeleb数据集。
有不同的方法可以确定最佳阈值。ROC 曲线上最接近该点 (TP = 1.0, FP = 0.0) 的点被选为阈值(图 10)。两组的最佳值都非常接近 560。因此,FaceID 应用程序的未知主体阈值设置为 560。
CNN 模型合成
通过CNN模型训练部分给出的步骤得到的量化模型是MAX78000使用Maxim工具中的python脚本合成的。此脚本生成一个 C 代码,其中包括初始化 CNN 加速器、加载量化的 CNN 权重、为给定的示例输入样本运行模型以及在准备好以下三项后从设备获取模型输出的函数:
量化的 PyTorch 检查点文件或 TensorFlow 模型导出为 ONNX 格式。
网络模型 YAML 说明。
一个示例输入,其中包含要包含在生成的 C 代码中进行验证的预期结果。
运行以下脚本以生成合成代码:
./ai8xize.py -e --verbose --top-level cnn -L --test-dir --prefix faceid --checkpoint-file --config-file networks/faceid.yaml --device MAX78000 --fifo --compact-data --mexpress --display-checkpoint --unload
准系统C代码用作构建FaceID演示应用程序的基础,以初始化设备,加载权重(内核),推送示例输入并获取结果。
生成嵌入集
更改包含主题嵌入的头文件 embeddings.h,以创建自定义数据集以运行 FaceID 演示。db_gen文件夹中的 Python 脚本 generate_face_db.py 用于此目的。脚本的示例用法在gen_db.sh中给出。该脚本将存储主题图像的文件夹名称作为参数。此文件夹必须包括每个主题的单独子文件夹,并且这些子文件夹必须以主题的名称或标识符命名。图 11 显示了示例 db 文件夹结构。受试者的图像放置在关联的文件夹中。
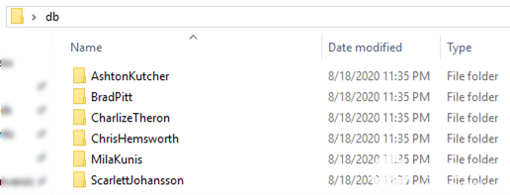
图 11.用于生成自定义嵌入集的示例数据库文件夹结构。
像gen_db.sh和generate_face_db.py一样使用参数调用,会自动生成嵌入 embeddings.h,其中包含 db 文件夹中的图像和主题。更改文件后,下一个构建将成为具有更新嵌入列表的自定义版本。
$ ./gen_db.sh
用MTCNN进行人脸识别,用检测到的人脸裁剪120×160帧,并在generate_face_db.py中进行照明校正。图像必须大于 120 × 160,并且只能包含一个面向相机的主体。建议每个受试者至少五张图像,以提高识别准确性。
面容演示平台
人脸识别在MAX78000评估板上使用FaceID固件进行演示。评估板(图12.MAX78000上的FaceID应用截图和图11所示的主题数据库)由TFT屏幕和视频图形阵列(VGA)摄像头组成,均朝上以在自拍模式下工作。演示应用程序持续运行并报告每个帧的一个预测。如果提取的嵌入与数据库中主题的接近程度不超过预定义的阈值,则会报告未知类。阈值是按照前面部分所述获得的,可以更新(embedding_process.h 中的变量thresh_for_unknown_subject)。 可以使用 L1(曼哈顿)距离代替 L2 范数,因为它需要较少的计算。但必须相应地重复未知阈值确定步骤。

图 12.MAX78000上的FaceID应用截图,主题数据库如图11所示。
MAX78000评估板上的演示以纵向位置运行,更适合拍摄和显示自拍照。人脸必须位于蓝色矩形中,因为此部分是要裁剪以进行处理的区域的中心。从原始捕获中裁剪出三个 120 × 160 图像,具有不同的 X 和 Y 偏移。这些被馈送到CNN模型,以提高作为增强方法的准确性。在报告预测之前,通过向CNN发送多张覆盖面部的图像来测试预测的一致性。同样,还测试了连续时间样本中预测的一致性。这可能会给识别速度带来一些滞后,但会增加应用程序的鲁棒性。图 13 显示了应用程序的流程图。
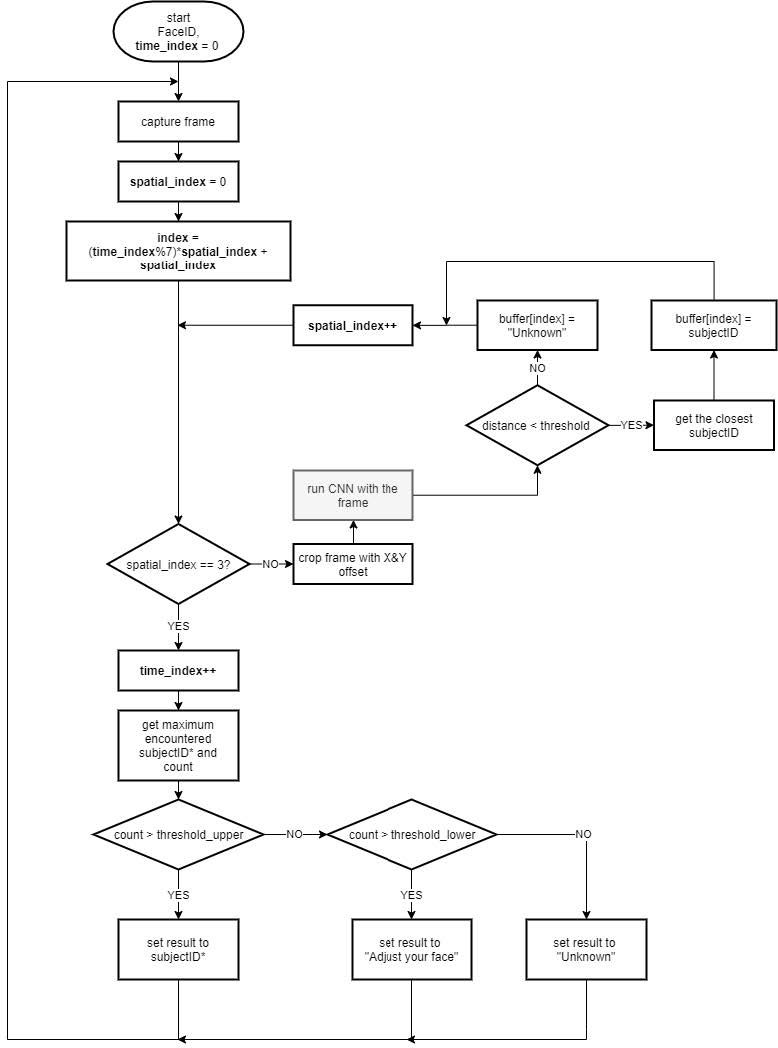
图 13.MAX78000上FaceID演示应用的工艺流程
结论
本应用笔记演示了在MAX78000中实现人脸识别模型,以及如何在超低功耗MAX78000平台上部署,用于资源受限的边缘或物联网应用。该应用遵循基于知识蒸馏的模型开发方法,以满足MAX78000的要求。因此,本文档也可以作为将高性能大型网络迁移到边缘设备的指南。应用笔记介绍了模型的性能分析以及合成模型以部署MAX78000所需的步骤。
审核编辑:郭婷
-
MAX78000进串口通信的验证和调试2024-02-18 546
-
MAX78000: Artificial Intelligence Microcontroller with Ultra-Low-Power Convolutional Neural Network Accelerator Data Sheet MAX78000: Artific2023-10-17 84
-
MAX78000人工智能设计大赛第二季回归!赛题广任意玩,奖励足直接冲!2023-09-13 1775
-
厉害了,这3个项目获得了MAX78000设计大赛一等奖!2023-03-10 2027
-
用于MAX78000模型训练的数据加载器设计2023-02-21 2340
-
在MAX78000上开发功耗优化应用2023-02-17 1973
-
如何对RK3399的HDMI进行人脸识别呢2022-03-07 2312
-
基于MAX78000FTHR的机器学习实时处理方案2021-01-16 5340
-
美信半导体新型神经网络加速器MAX78000 SoC2021-01-04 4949
-
Maxim Integrated新型神经网络加速器MAX78000 SoC在贸泽开售2020-12-09 3435
-
MAX78000将能耗和延迟降低100倍,从而在IoT边缘实现复杂的嵌入式决策2020-11-04 2960
-
opencv和face++如何进行人脸检测吗?2020-06-10 1484
-
行人再识别技术是如何应用的,与人脸识别有什么区别?2019-03-22 3857
-
Dragonboard 410c USB摄像头进行人脸识别2018-09-21 2964
全部0条评论

快来发表一下你的评论吧 !
