

在英特尔独立显卡上部署YOLOv5 v7.0版实时实例分割模型
描述
作者:英特尔物联网创新大使 贾志刚
本文将介绍在基于 OpenVINO 在英特尔独立显卡上部署 YOLOv5 实时实例分割模型的全流程,并提供完整范例代码供读者使用。
1.1 YOLOv5 实时实例分割模型简介
YOLOv5 是 AI 开发者友好度最佳的框架之一,与其它YOLO 系列相比:
工程化水平好,工程应用时“坑”少
文档详实友好,易读易懂
既容易在用户的数据集上重训练又容易在不同的平台上进行部署
社区活跃度高(截至2022-11-27有33.2k GitHub 星, 287个贡献者)
项目演进速度快
默认支持 OpenVINO 部署
在典型行业(制造业、农业、医疗、交通等)有广泛应用。
2022年11月22日,YOLOv5 v7.0版正式发布,成为YOLO 系列中第一个支持实时实例分割(Real Time Instance Segmentation)的框架。从此,YOLOv5 框架不仅具有实时目标检测模型,还涵盖了图像分类和实例分割。
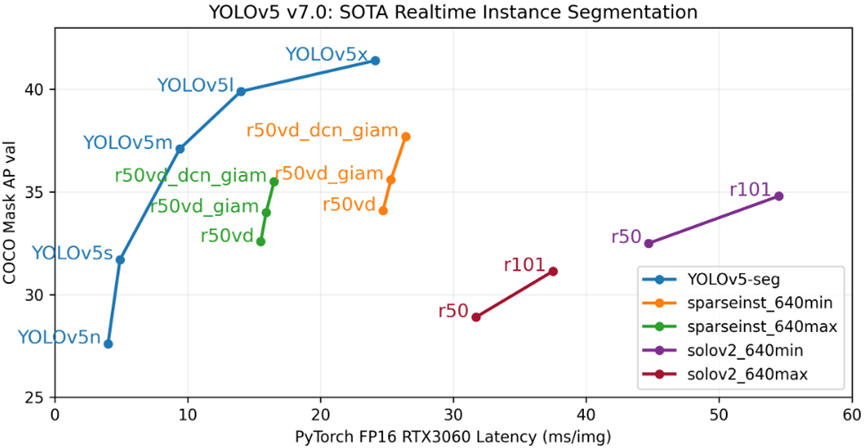
图片来源: https://github.com/ultralytics/yolov5/releases
与实时实例分割 SOTA 性能榜中的模型相比,YOLOv5 作者发布的 YOLOv5-Seg 模型数据,无论是精度还是速度,都领先于当前 SOTA 性能榜中的模型。
1.2英特尔 消费级锐炫 A系列显卡简介
2022年英特尔发布了代号为 Alchemist 的第一代消费级锐炫 桌面独立显卡,当前英特尔京东自营旗舰店里销售的主要型号为 A750 和 A770,其典型参数如下图所示。
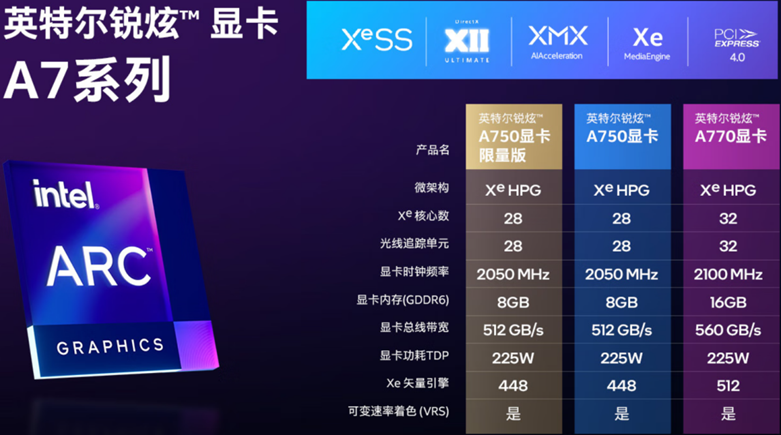
OpenVINO 从2022.2版开始支持英特尔独立显卡,包括英特尔 数据中心 GPU Flex 系列和英特尔 锐炫 系列。
1.3在英特尔独立显卡上部署
YOLOv5-seg 模型的完整流程
在英特尔独立显卡上部署 YOLOv5-seg 模型的完整流程主要有三步:
1搭建 YOLOv5 开发环境和 OpenVINO 部署环境
2运行模型优化器(Model Optimizer)优化并转换模型
3调用 OpenVINO Runtime API函数编写模型推理程序,完成模型部署
本文将按照上述三个步骤,依次详述。
1.3.1搭建 YOLOv5 开发环境和 OpenVINO 部署环境
最近的 YOLOv5 Github 代码仓,即 YOLOv5 v7.0,已经将 openvino-dev[onnx] 写入 requirement.txt 文件,当执行 pip install -r requirements.txt,会安装完 YOLOv5 开发环境和 OpenVINO 部署环境。
git clone https://github.com/ultralytics/yolov5 # clonecd yolov5 cd yolov5 pip install -r requirements.txt
向右滑动查看完整代码
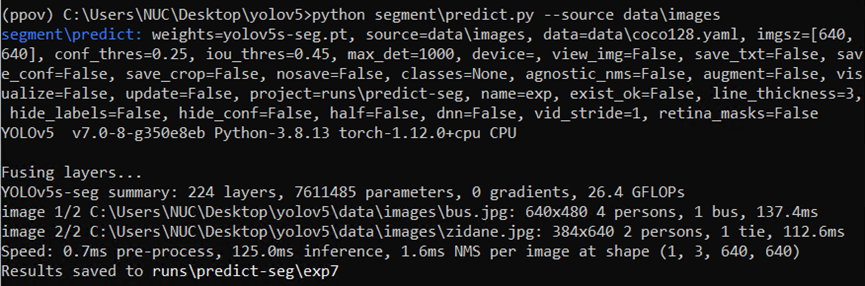
1.3.2验证 YOLOv5 开发环境和 OpenVINO 部署环境
执行完上述命令后,运行命令
python segmentpredict.py --source dataimages
向右滑动查看完整代码
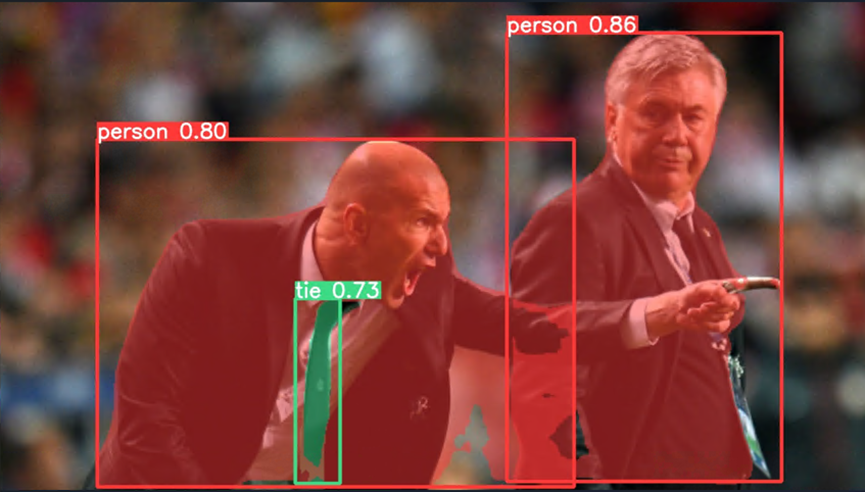
执行结果如下图所示,说明 YOLOv5 开发环境和OpenVINO 部署环境已搭建成功。
1.3.3导出 yolov5s-seg OpenVINO IR 模型
使用命令:
python export.py --weights yolov5s-seg.pt --include onnx
向右滑动查看完整代码
获得 yolov5s-seg ONNX 格式模型:yolov5s-seg.onnx
然后运行命令:
mo -m yolov5s-seg.onnx --data_type FP16
获得yolov5s-seg IR格式模型:yolov5s-seg.xml和yolov5s-seg.bin。
1.3.4用 Netron 工具查看 yolov5s-seg.onnx 模型的输入和输出
使用 Netron:https://netron.app/
查看 yolov5s-seg.onnx 模型的输入和输出,如下图所示:
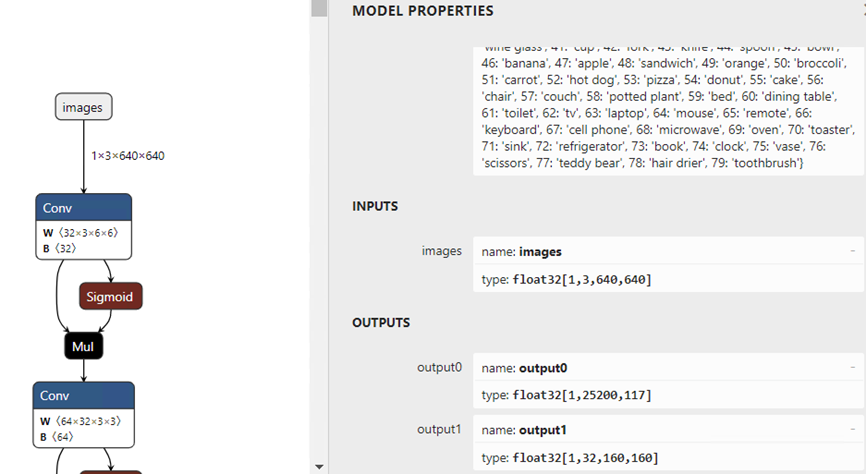
从图中可以看出:yolov5s-seg 模型
✓ 输入节点名字:“images”;数据: float32[1,3,640,640]
✓ 输出节点1的名字:“output0”;数据:float32[1,25200,117]。
其中117的前85个字段跟 YOLOv5 定义完全一致,即检测框信息;后32个字段用于计算掩膜数据。
✓ 输出节点2的名字:“output1”;数据:float32[1,32,160,160]。output1 的输出与 output0 后32个字段做矩阵乘法后得到的数据,即为对应目标的掩膜数据。
1.3.5使用 OpenVINO Runtime API 编写 yolov5s-seg 推理程序
由于 yolov5s-seg 模型是在 YoLov5 模型的基础上增加了掩膜输出分支,所以图像数据的预处理部分跟 YoLov5 模型一模一样。
整个推理程序主要有五个关键步骤:
第一步:创建 Core 对象;
第二步:载入 yolov5s-seg 模型,并面向英特尔独立显卡编译模型
第三步:对图像数据进行预处理
第四步:执行 AI 推理计算
第五步:对推理结果进行后处理,并可视化处理结果。
整个代码框架如下所示:
# Step1: Create OpenVINO Runtime Core
core = Core()
# Step2: Compile the Model, using dGPU A770m
net = core.compile_model("yolov5s-seg.xml", "GPU.1")
output0, output1 = net.outputs[0],net.outputs[1]
b,n,input_h,input_w = net.inputs[0].shape # Get the shape of input node
# Step3: Preprocessing for YOLOv5-Seg
# ...
# Step 4: Do the inference
outputs = net([blob])
pred, proto = outputs[output0], outputs[output1]
# Step 5 Postprocess and Visualize the result
# ...
向右滑动查看完整代码
其中 YOLOv5-seg 的前处理跟 YOLOv5 一样,范例代码如下:
im, r, (dh, dw)= letterbox(frame, new_shape=(input_h,input_w)) # Resize to new shape by letterbox im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB im = np.ascontiguousarray(im) # contiguous im = np.float32(im) / 255.0 # 0 - 255 to 0.0 - 1.0
向右滑动查看完整代码
由于 YOLOv5 系列模型的输入形状是正方形,当输入图片为长方形时,直接调用 OpenCV 的 resize 函数放缩图片会使图片失真,所以 YOLOv5 使用 letterbox 方式,将图片以保持原始图片长宽比例的方式放缩,然后用灰色color=(114, 114, 114)填充边界,如下图所示。
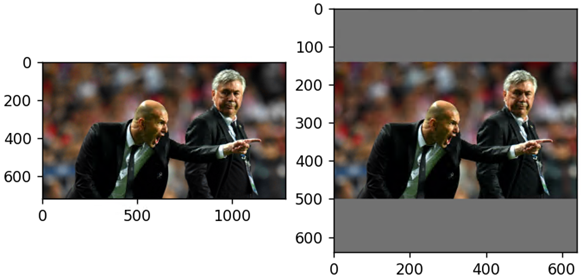
Letterbox 放缩效果
https://github.com/ultralytics/yolov5/blob/master/utils/augmentations.py#L111
YOLOv5-seg 的后处理跟 YOLOv5 几乎一样,需要对推理结果先做非极大值抑制。本文直接使用了 YOLOv5 自带的 non_max_suppression() 函数来实现非极大值抑制,并拆解出检测框(bboxes), 置信度(conf),类别(class_ids)和掩膜(masks)。关键代码如下:
from utils.general import non_max_suppression pred = torch.tensor(pred) pred = non_max_suppression(pred, nm=32)[0].numpy() #(n,38) tensor per image [xyxy, conf, cls, masks] bboxes, confs, class_ids, masks= pred[:,:4], pred[:,4], pred[:,5], pred[:,6:]
向右滑动查看完整代码
yolov5seg_ov2022_sync_dgpu.py 运行结果如下图所示:
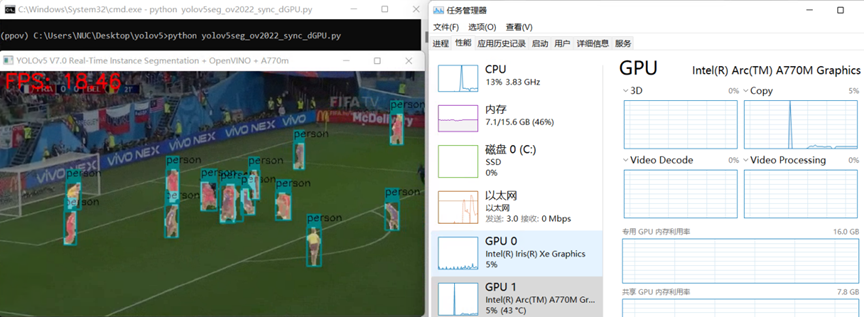
源代码链接:
https://gitee.com/ppov-nuc/yolov5_infer/blob/main/yolov5seg_ov2022_sync_dGPU.py
1.4结论
YOLOv5 的实时实例分割程序通过 OpenVINO 部署在英特尔独立显卡上,可以获得高速度与高精度。读者还可以将程序通过 OpenVINO 异步 API 升级为异步推理程序或者用 OpenVINO C++ API 改写推理程序,这样可以获得更高的 AI 推理计算性能。
-
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型2022-11-18 3934
-
在C++中使用OpenVINO工具包部署YOLOv5-Seg模型2023-12-21 4153
-
yolov5转onnx在cubeAI上部署失败的原因?2024-03-14 713
-
请问如何在imx8mplus上部署和运行YOLOv5训练的模型?2025-03-25 1138
-
在K230上部署yolov5时 出现the array is too big的原因?2025-05-28 822
-
如何YOLOv5测试代码?2023-05-18 668
-
英特尔推出了英特尔锐炬Xe MAX独立显卡2020-11-01 9919
-
YOLOv5 7.0版本下载与运行测试2022-11-30 6226
-
在C++中使用OpenVINO工具包部署YOLOv5模型2023-02-15 12514
-
使用旭日X3派的BPU部署Yolov52023-04-26 2076
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 2983
-
使用PyTorch在英特尔独立显卡上训练模型2024-11-01 3440
-
在树莓派上部署YOLOv5进行动物目标检测的完整流程2024-11-11 5549
-
yolov5训练部署全链路教程2025-07-25 2202
-
迅为如何在RK3576上部署YOLOv5;基于RK3576构建智能门禁系统2025-11-25 2200
全部0条评论

快来发表一下你的评论吧 !
