

什么是超异构计算?如何驾驭超异构计算?
处理器/DSP
描述
算力爆炸的时代,复杂计算充满挑战,对硬件灵活可编程性要求也越来越高。计算架构走到异构的今天,矛盾也凸显——单一处理器无法兼顾性能和灵活性。
而超大规模计算集群和复杂系统让超异构计算成为了可能,何出此言?超异构计算又到底是什么?从芯片龙头企业的产品布局上我们能发现什么?传统的计算架构发展又遭遇哪些瓶颈?
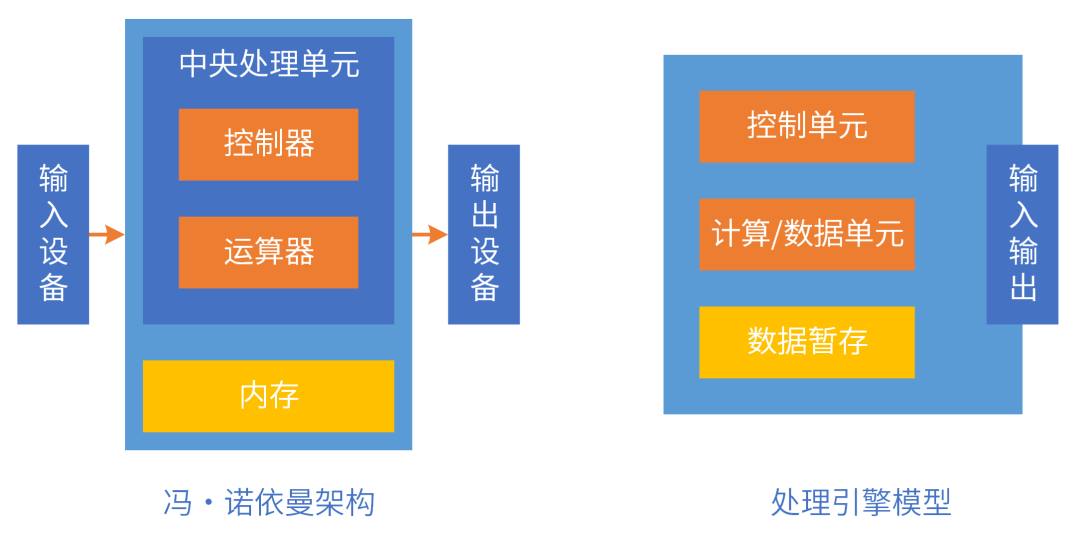
在12月6日芯智库【相约芯期二】第27期的“汽车芯片智能驾舱在线研讨会”上,上海矩向科技CEO黄朝波带来主题为“从英伟达 Thor,看大芯片发展趋势”的演讲。 以下是黄朝波的分享: 我给大家分享的是“从英伟达Thor,看大芯片的发展趋势”,当然它有更专业点的名字叫“超异构计算,新一代计算架构”。 我的介绍大概分为5个部分,第一部分对一些没有计算机相关基础的读者做一些基本的介绍;第二部分探讨下计算架构面临的挑战;第三部分就是介绍超异构相关的趋势案例,里面主要包含了英伟达和高通的案例;第四部分讨论下为什么现在会出现这个概念,而不是过去或者以后;最后部分介绍下我们认为未来会出现单芯片的整体解决方案,也就是我们称之为超异构处理器。 01 算力提升不仅是芯片 先简单介绍下冯·诺依曼架构。我们一切系统的运行是可以归一到计算的,计算系统是由输入、计算和输出三部分组成,这个架构就是冯·诺依曼架构,非常的简单。现在行业内有很多号称打破冯·诺依曼架构的系统,但背后逻辑都是遵照冯·诺依曼架构的指导思想,严格来说不存在打破的说法。
然后是摩尔定律。基于CPU的摩尔定律真的已经到了极限,虽然说我们现在晶体管的提升也是慢慢到了一个极限,但是如果我们把摩尔定律当做一个KPI的话,那么对行业来说它又是一个非常重要的路线图,大家需要持续不断地提升性能,所以说对于计算性能的追求其实是永无止境的。 另外,再简单介绍下软件和硬件。首先,指令是软件和硬件之间的媒介,那么指令的复杂度决定了这个软硬件的解耦程度。ISA(指令集架构)之下,CPU、GPU等各种处理器是硬件;ISA之上,各种程序、数据集、文件等是软件。
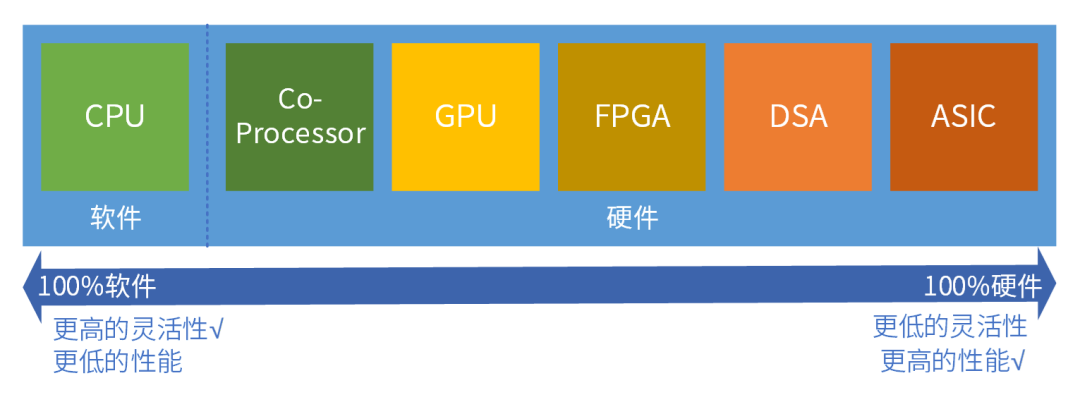
按照指令的复杂度,典型的处理器平台大致分为CPU、协处理器、GPU、FPGA、DSA、ASIC。从左往右,单位计算越来越复杂,性能越来越好,而灵活性越来越低。任务在CPU运行,则定义为软件运行;任务在协处理器、GPU、FPGA、DSA或ASIC运行,则定义为硬件加速运行。 我们现在是一个万物互联的时代,从云端的集中式超大规模服务器,然后到边缘端的小规模数据中心,再到终端的各种丰富多彩的设备,那么整个万物互联大概来说就分为这三个层次。 通常来说,终端是归于我们现实世界的一个接入层,它是整个大系统的一个I/O,然后负责现实世界和虚拟世界的交互,那么云端是最终任务的处理,边缘端通常来说是作为云端的一个代理,为终端去提供服务的,因此我们可以根据云边端将计算节点分类。 终端我们把它分为四类:IoT节点、IoT设备、智能终端、超级终端。云端分为三类:服务器、服务、用户业务运行环境。边缘分为两类:代理运行平台、近云端及近终端运行环境。
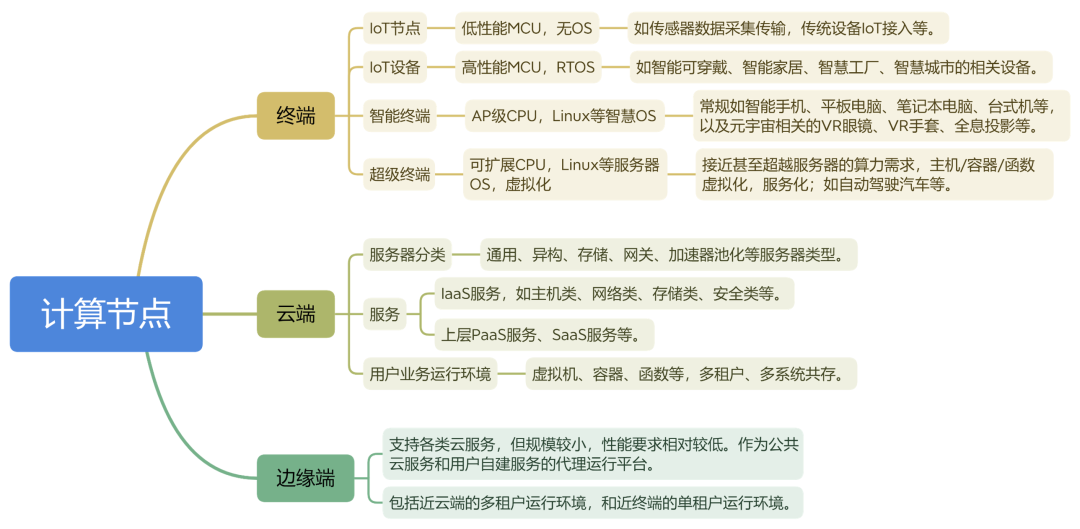
我们最终要宏观地去提升这些设备共同的算力,不能简单地只提升一个设备的性能,那是没有意义的。因为每一个设备如果只是一个孤岛的话,这些东西没法连成一个大的资源池是没有意义的,所以基于此,我们把这些统一起来,我们把微观层次作为单芯片性能,宏观层次就是整体的算力利用率。

这样的话,想提升算力,它仅仅是提升芯片的性能肯定是不够的,那就需要各方面全方位的优化。我们可以简单地把它作为一个公式,实际总算力与单芯片性能、数量、利用率相关,特别是后面两个参数,我们做芯片的可能不太关注,但这两块的作用又很关键。
02 计算架构面临的挑战 计算架构最开始是单核处理器,然后走向了多核,计算从串行走向了并行。 再往后走,我们从同构并行到了异构并行,异构并行通常分为三类:基于GPU、基于FPGA、基于DSA。 这些异构并行都需要外挂一个CPU来控制,所以本质上异构并行就是CPU+XPU的形态,像最典型的就是GPU服务器。GPU并行计算性能效率比CPU高,并且场景覆盖较多,CUDA生态成熟。但性能效率比ASIC/DSA仍有很大差距;对一些轻量级异构加速场景,独立GPU显得太重。 复杂计算,通俗易懂的讲,就是需要支持虚拟化,支持多租户多系统运行的这些计算场景。在云计算、边缘计算以及一些超级终端的复杂计算场景,对灵活性的要求远高于对性能的要求。 也就是说通常情况下,如果CPU能够满足性能要求,大家一定是不希望用各种加速器。但对算力的需求不断增加,有时候不得不通过各种异构加速方式进行性能优化。实践证明,在复杂计算场景,提升性能的同时,不能损失通用灵活性。 最后我们总结一下异构计算存在的问题。系统越复杂,需要选择越灵活的处理器;性能挑战越大,需要选择越偏向定制的加速处理器。 本质矛盾是:单一处理器无法兼顾性能和灵活性;即使我们拼尽全力平衡,也只“治标不治本”。 CPU+XPU异构计算中的XPU,决定了整个系统的性能/灵活性特征。GPU灵活性较好,但性能效率不够极致;DSA性能好,但灵活性差,难以适应复杂计算场景对灵活性的要求;FPGA功耗和成本高,需要一些定制开发,落地案例不多;ASIC功能完全固定,难以适应灵活多变的复杂计算场景。 这就是目前的一个现状。还有另外一个原因就在于计算孤岛的问题。异构计算面向某个领域或场景,领域之间的交互困难。服务器物理空间有限,无法多个物理加速卡,需要把这些加速方案整合。整合,不是简单的拼凑,而是要架构重构。
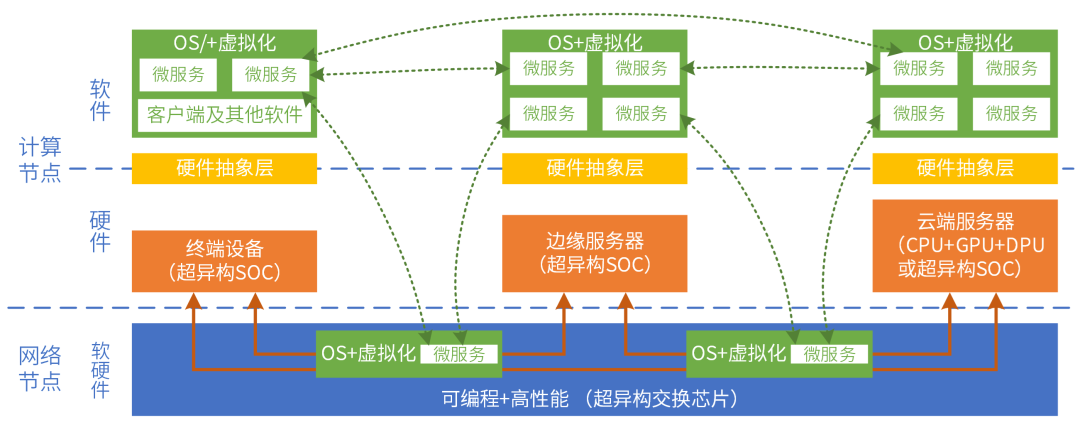
此外,我们所说的云网边端融合也面临着挑战。云网边端,算力需求不断提高,系统复杂度不断提高,对硬件的灵活可编程性要求也越来越高。微服务可自适应地在云、网、边、端运行,需要云数据中心内部,以及跨云边端的硬件平台一致性。需要芯片、系统、框架和库、以及上层应用的多方协同。
03 什么是超异构计算?
那么下一步,我们认为是持续往前走向超异构,为什么这件事情能够存在? 我们认为有几个原因使得超异构成为可能。那么首先一点就是超大规模的计算集群,其次是复杂宏系统,是由分层分块的组件(系统)组成。单服务器的宏系统复杂度,以及超大规模的云和边缘计算,使得“二八定律”在系统中普遍存在:把相对确定的任务沉淀到基础设施层,相对弹性的沉淀到弹性加速部分,其他继续放在CPU(CPU兜底)。
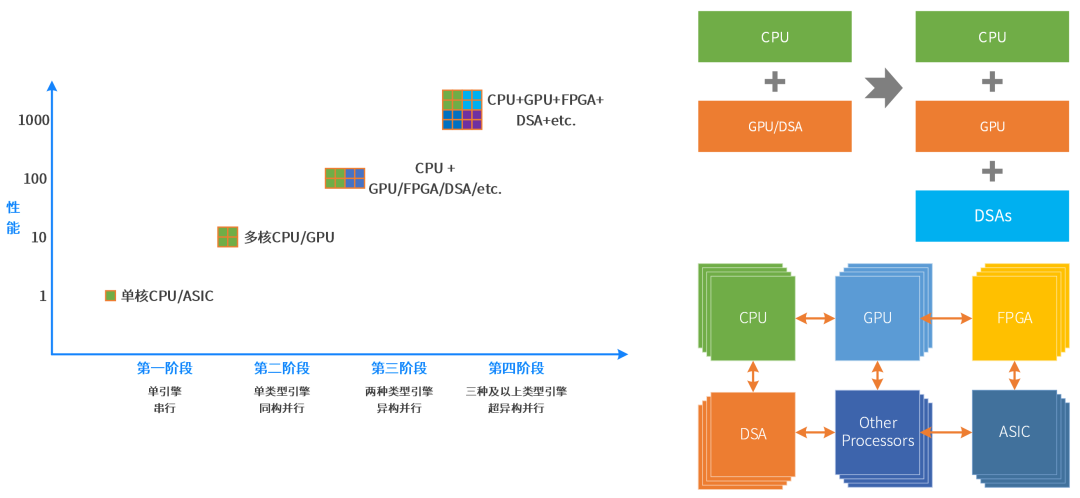
把更多的异构计算整合重构,各类型处理器间充分的、灵活的数据交互,形成超异构计算。未来就会有三个和三个以上类型的处理引擎,共同组成超异构并行。 接下来我们介绍一些案例,首先是英特尔提出的超异构相关概念。当它提出来之后,并没有给出来完整的一个产品,反而是在超异构概念周边做了很多工作,最终我觉得会有很完整的东西出来。 2019年,英特尔提出超异构计算相关概念:XPU是架构组合,包括CPU、GPU、FPGA 和其他加速器;OneAPI是开源的跨平台编程框架,底层是不同的XPU处理器,通过OneAPI提供一致性编程接口,使得应用跨平台复用。 就是说我任何一个应用,我既可以在CPU运行,又可以在GPU运行,又可以在专用的ASIC上运行,通过OneAPI就可以跨不同的处理器平台,就可以自适应的去在平台上也有不同的计算资源。 再说说英特尔的IPU,英特尔IPU跟现在市面上比较火爆的DPU是一个概念。
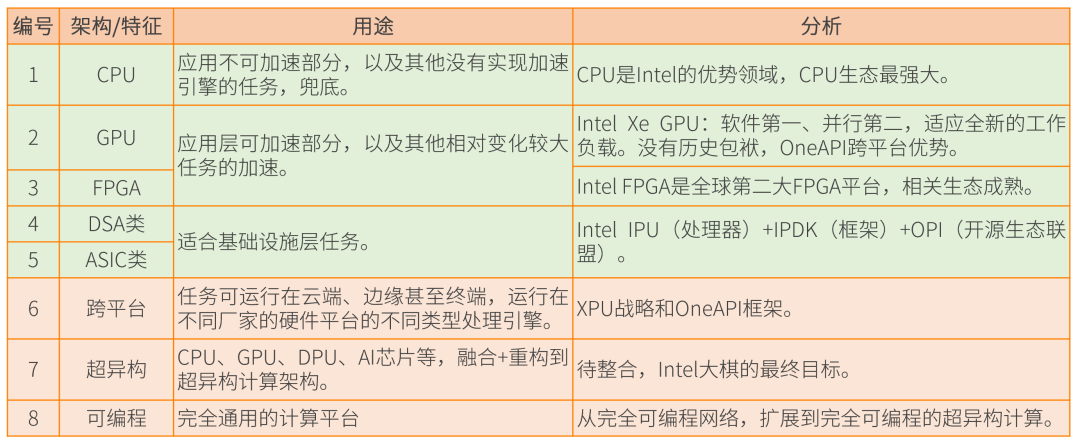
我们对英特尔的超异构计算进行一个总结,那它有CPU、GPU、FGPA,以及DSA和ASIC所组成的IPU,并且有了这个跨平台,也就是它所谓的XPU战略和oneAPI框架,最终把它整合成一个大芯片,
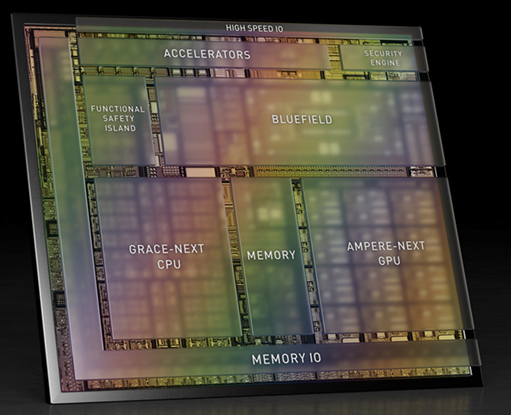
(上图为Atlan架构示意图,Atlan和Thor同架构) 我们再来看英伟达Thor,这里很关键,为什么是数据中心架构?它所使用CPU、GPU、DPU跟数据中心里面用的架构一模一样,区别仅仅在于规格的不同,比方说数据中心可能有50个核,在终端可能用到30个核。 超级终端与传统终端最大的区别在于:支持虚拟化,支持多系统运行,支持微服务。手机、平板、个人电脑等传统AP是一个系统:部署好OS,上面运行各种应用,软件附属于硬件而存在。自动驾驶等超级终端,需要通过虚拟化将硬件切分成不同规格,供不同形态的多个系统运行,并且各个系统之间需要做到环境、应用、数据、性能、故障、安全等方面的隔离。 再然后看一下英伟达在数据中心的布局,NVIDIA Grace Hopper超级芯片是CPU+GPU,NVIDIA计划从Bluefield DPU四代起,把DPU和GPU两者集成单芯片。Chiplet技术逐渐成熟,未来趋势是CPU+GPU+DPU的超异构芯片。 为什么显而易见?这里面有英伟达自己的一个说法,我把这个进行了一个总结。首先,计算和网络不断融合:计算面临很多挑战,需要网络的协同;网络设备也是计算机,加入计算集群,成为计算的一部分。
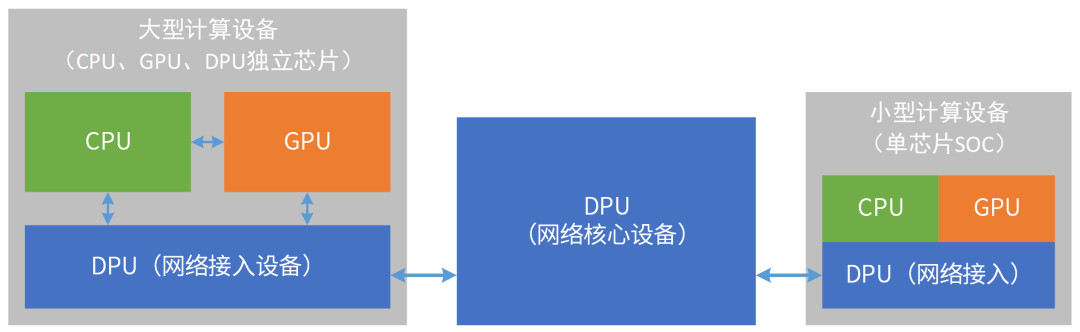
数据在网络中流动,计算节点依靠数据流动来驱动计算。所有系统的本质是数据处理,那么所有的设备就都是DPU。以DPU为基础,不断融合CPU和GPU的功能,DPU会逐渐演化成数据中心统一的超异构处理器。
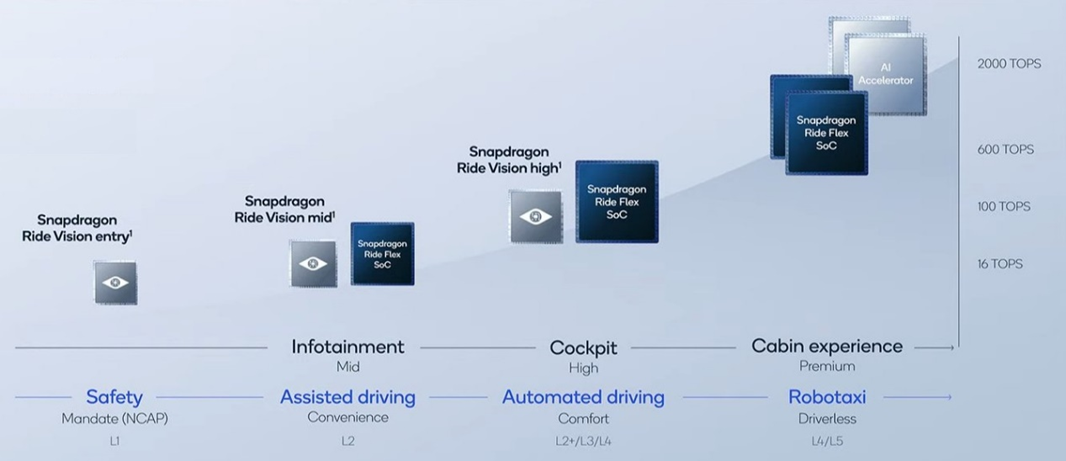
我们再来看高通。高通在手机端是很厉害的存在,往汽车域控制上发展也会有先天优势,但如果以最终的超级单芯片来讲,相对于英伟达还是有点劣势的。
04 如何驾驭超异构计算?
接下来讨论下,为什么现在才提超异构这个概念。这里面其实有很多原因,我们总结了大概4个部分,第一个首先是业务需求驱动,现在软件新应用层出不穷,两年一个新热点;并且,已有的热点技术仍在快速演进。
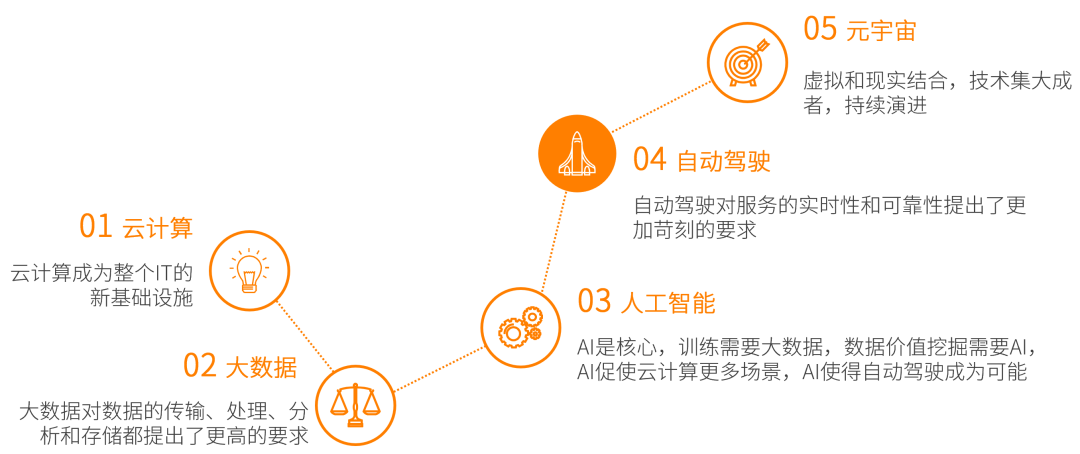
第二点,元宇宙是继互联网和移动互联网之后的下一个互联网形态,元宇宙需要源源不断的“算力能源”。要想实现元宇宙级别的体验,需将算力提升1000倍。受限于算力瓶颈,许多元宇宙的美好设想难以落地:沉浸感所需的16K效果,需要280.7Gbps带宽。目前的算力基础设施,还难以达到这么高数据量的传输、处理和存储;宏观AI算力需要数量级提升:①支撑单个数字人的AI算力需求急速增长;②元宇宙快速发展,数字人的数量猛增。 第三点,就是工艺在进步,那么这里有一个非常有优势的技术。Chiplet使得在单芯片层次,可以构建规模数量级提升的超大系统。系统越大,超异构的优势越明显。 第四点,异构编程很难,超异构编程更是难上加难。该如何更好的驾驭超异构?我们给出的解决方案是软硬件融合。软硬件融合从以下几个方面入手: 性能和灵活性。单引擎平衡,多引擎兼顾。 可编程及易用性。利用系统的特征,软件无缝卸载, 实现“软件定义一切,硬件加速一切”。 产品的弹性。满足用户需求,还需要满足不同用户差异化的需求,以及用户需求的快速迭代。 通过软硬件融合,实现大芯片的通用性(灵活性、可编程性、易用性以及弹性等特征的集合): 覆盖更多的用户、更多的场景和更长期的迭代; 适配复杂宏系统的快速变化; 实现芯片的大规模落地。 05 超异构计算的未来 最后我们介绍一下,最终落地的到底是个什么东西? 在这里我们需要说一下,图灵奖获得者John H.和David P. 2017年提出“计算机体系结构的黄金年代”,给出的解决方案是特定领域架构DSA。
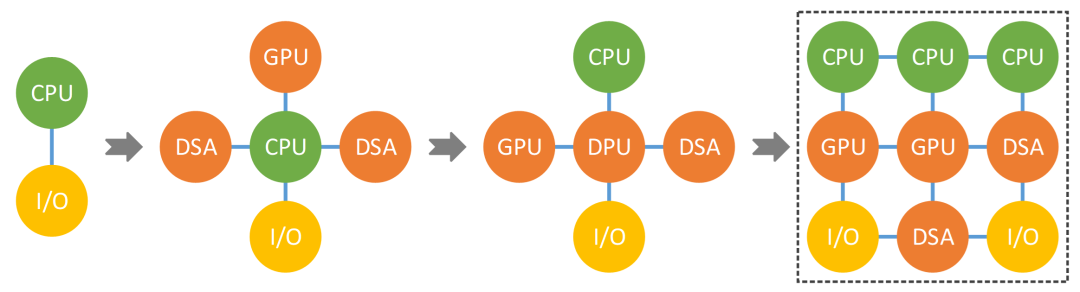
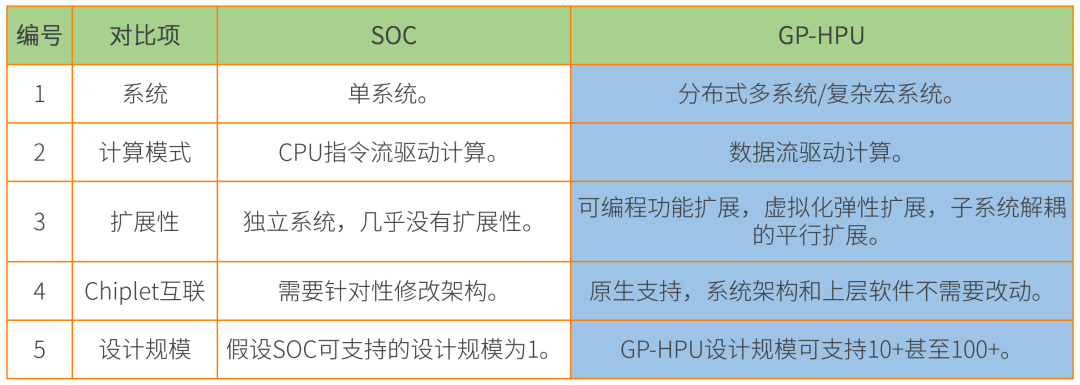
我们认为,DSA架构分离的趋势导致平台和生态碎片化,未来正确的趋势应该是从分离再回到融合。 也就是将目前CPU、GPU、DPU进行整合,我们把它叫做GP-HPU,那么可能大家就会有一个疑问,这不就是SOC吗?

它的确是把整个系统放到了一个基本面上,但是他跟我们传统的SOC有很多不同。
最后展望一下,超异构更加广泛的应用领域。
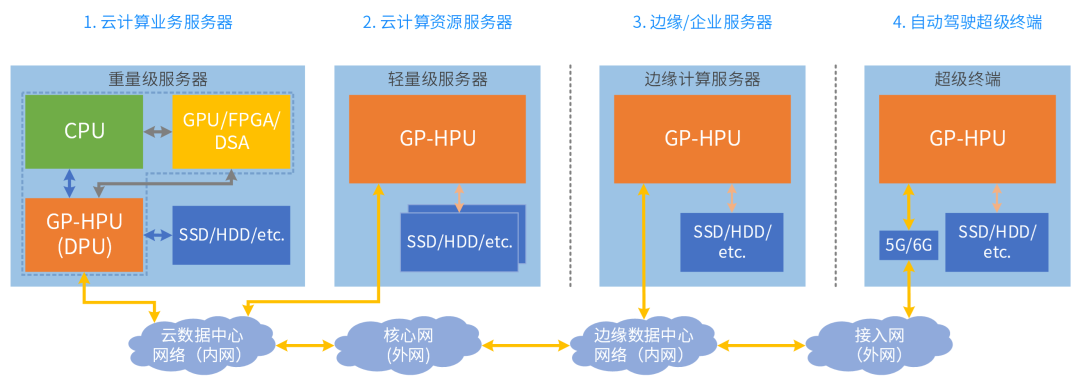
那么通常来说一开始做的相对小一些,它用在边缘是比较合适的,但随着扩展,那么未来用在这个数据中心里面,或者自动驾驶上。跨云网边端融合,需要计算架构的统一。通用HPU优势:更多功能复用,更多场景覆盖,跨平台架构统一。
编辑:黄飞
-
【一文看懂】什么是异构计算?2024-12-04 4450
-
异构计算:解锁算力潜能的新途径2024-07-18 30222
-
新一代计算架构超异构计算技术是什么 异构走向超异构案例分析2023-08-23 1737
-
异构计算场景下构建可信执行环境2023-08-15 1133
-
异构计算面临的挑战和未来发展趋势2023-04-26 3390
-
异构计算真就完美无缺吗2021-12-21 2859
-
异构计算的前世今生2021-12-17 5915
-
什么是异构并行计算2021-07-19 2328
-
异构计算在人工智能什么作用?2019-08-07 3719
-
异构计算,你准备好了么?2018-09-25 819
-
异构计算:架构与技术2018-09-18 1269
-
异构计算的两大派别 为什么需要异构计算?2018-04-28 23616
-
基于FPGA的异构计算是趋势2018-04-25 11755
-
异构计算芯片的机遇与挑战2017-09-27 1537
全部0条评论

快来发表一下你的评论吧 !
