

谷歌提出FlexiViT:适用于所有Patch大小的模型
描述
太长不看版,果然还是延续谷歌的风格,创新不够,实验来凑。
废话不多说,直接上图,一图胜千言:
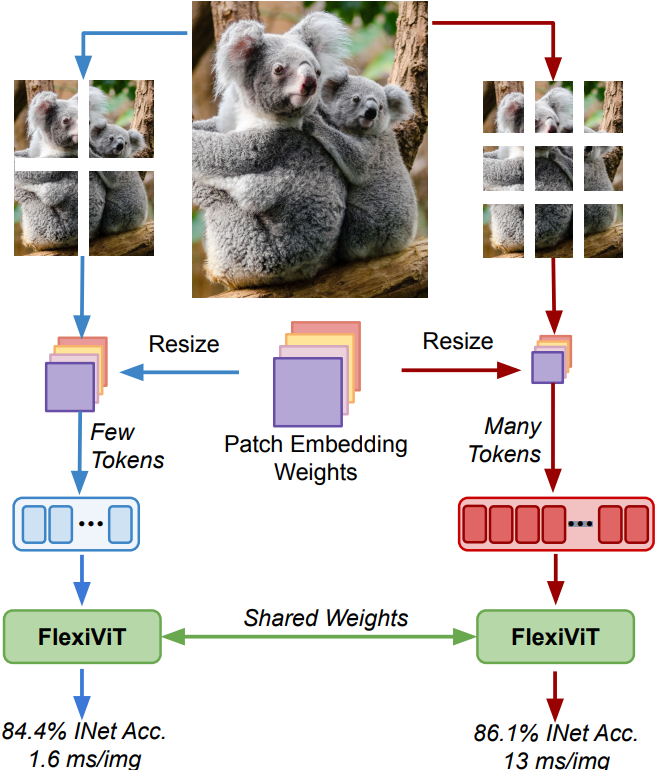
FlexiViT
顾名思义,FlexiViT,翻译过来不就是灵活的 ViT 嘛?
Ooo,那怎么体现灵活?我们先回顾下 Vision Transformers 的工作流程。
一句话总结就是,ViT 是一种通过将图像切割成一个个小方块(patch)将图像转换为序列从而输入到Transformer网络进行训练和推理的一种神经网络架构。
本文的重点便是在研究这些小块块对性能的最终影响。通常来说:
方块切的越小,精度会越高,但速度就变慢了;
方块切的越大,精度会降低,但速度就上来了;
So,我们究竟是要做大做强,还是做小做精致?不用急,来自谷歌大脑的研究人员为你揭晓答案:成年人才做选择,老子大小通吃。
正经点,让我们切回来,古哥通过燃烧了数不尽的卡路里向我们证明了,在训练期间随机改变方块的大小可以得到一组在广泛的方块大小范围内表现良好的权重(泛化性能好)。
这结论有什么用?那便是使得在部署时大家可以根据不同的计算预算来调整模型。
通过在以下五大版图进行广泛的投资,可以清晰的发现收益率远超沪深300:
图像分类
图像-文本检索
开放世界检测
全景分割
语义分割
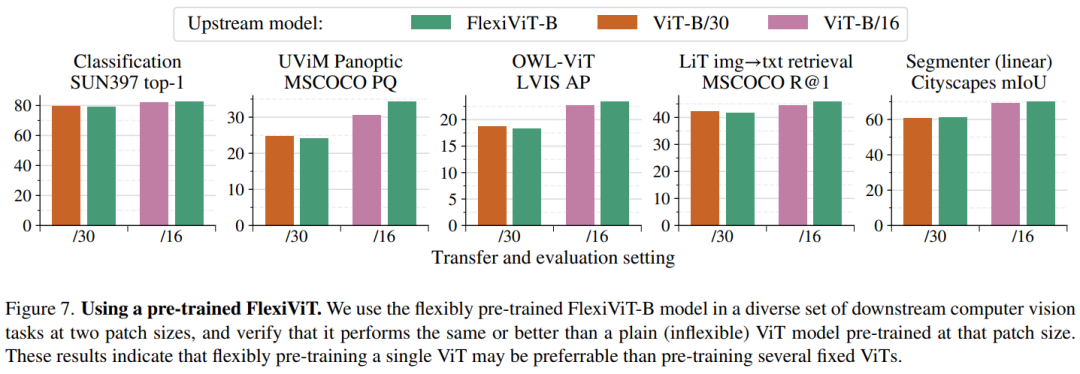
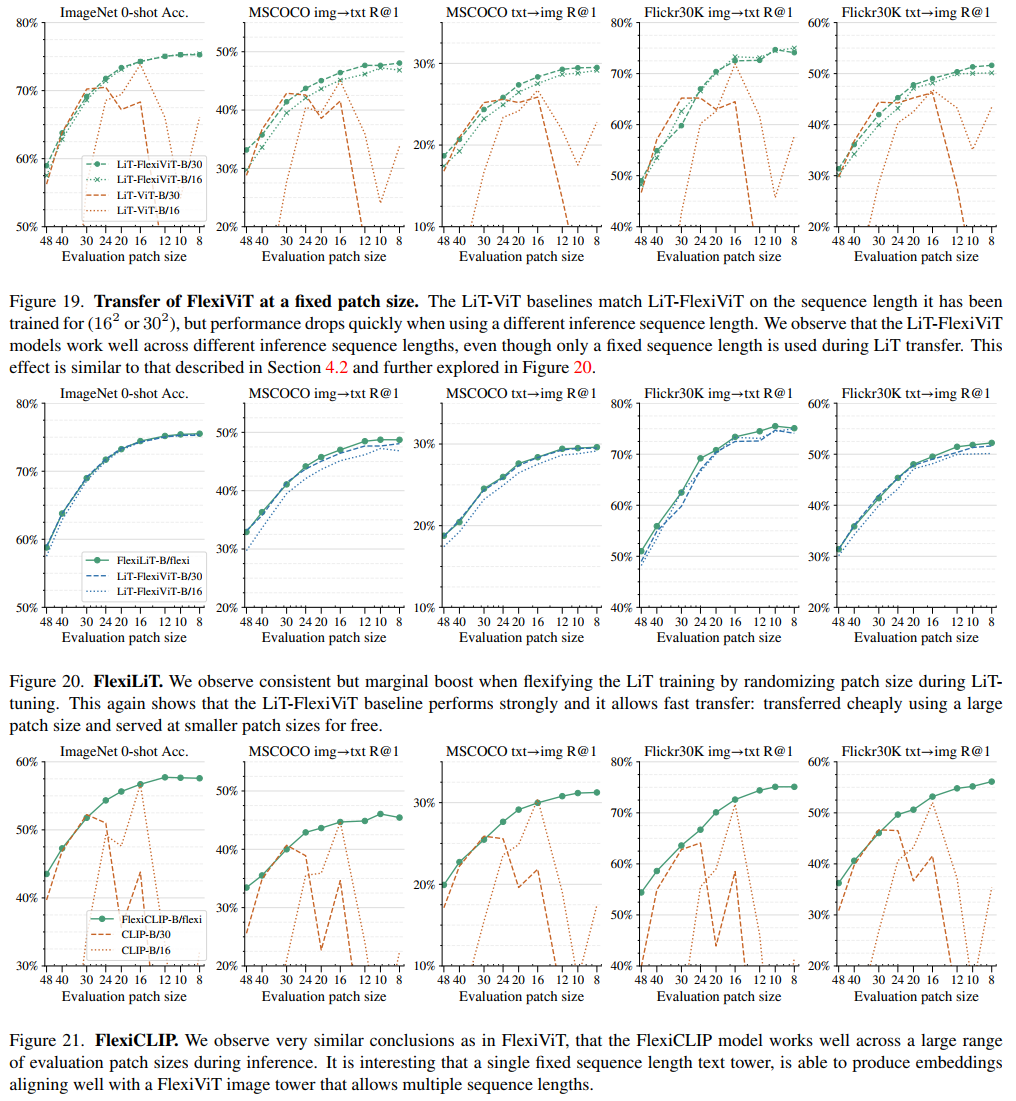
为了照顾下你们这些散(韭)户(菜),古哥说你们可以将它任意添加到大多数依赖ViT骨干架构的模型来实现计算自由,即模型可以根据不同的计算资源调整自己的工作方式,从而获得更好的性能和效率。
说了这么多,怎么做?直接把代号都发给你了,明天早盘直接梭哈即可:

看到看到这里了,总不能白嫖吧?点个赞友情转发下再走咯~~~
审核编辑 :李倩
-
同步工具适用于同步SRAM2019-02-13 2392
-
请问IIS模型适用于PIC18F46K22吗?2019-07-01 1545
-
字符分割部分适用于所有的C/C++的代码吗2021-12-17 1436
-
是否有适用于linux-qoriq的补丁程序?2023-05-05 567
-
USB标准适用于哪些应用2009-04-19 2447
-
适用于图书推荐的数据挖掘模型2018-01-04 966
-
FAIR和INRIA的合作提出人体姿势估计新模型,适用于人体3D表面构建2018-02-05 6570
-
电量监测计:适用于所有便携式电子设备2018-08-13 4065
-
欧司朗将提供适用于所有投影系统和类别的LED产品2018-10-13 2102
-
适用于所有场合的数字电源系统管理2021-03-20 796
-
适用于istContainer和所有视图的滑动菜单库2022-03-22 753
-
适用于所有atmega328p项目的通用板2022-08-03 720
-
适用于所有平台的便携式Web调试器2022-10-26 691
-
HomeAutomat适用于所有智能家居设备的简单集线器2022-11-28 700
-
LTE-M 连接适用于所有人2022-12-28 3767
全部0条评论

快来发表一下你的评论吧 !
