

强化学习的基础知识和6种基本算法解释
电子说
描述
强化学习的基础知识和概念简介(无模型、在线学习、离线强化学习等)
机器学习(ML)分为三个分支:监督学习、无监督学习和强化学习。
- 监督学习(SL):关注在给定标记训练数据的情况下获得正确的输出
- 无监督学习(UL):关注在没有预先存在的标签的情况下发现数据中的模式
- 强化学习(RL):关注智能体在环境中如何采取行动以最大化累积奖励
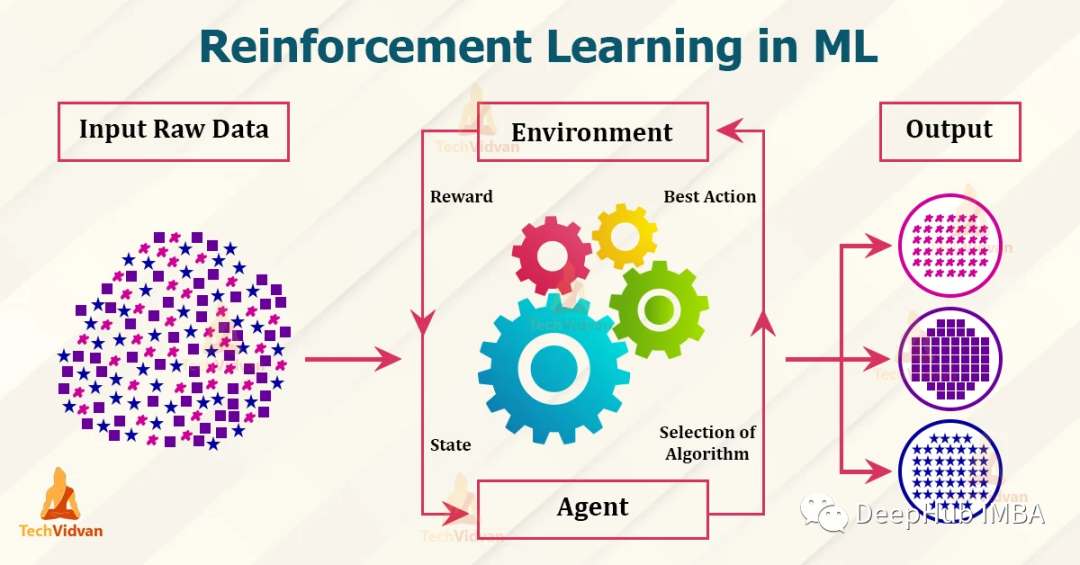 本文将涉及强化学习的术语和基本组成部分,以及不同类型的强化学习(无模型、基于模型、在线学习和离线学习)。本文最后用算法来说明不同类型的强化学习。
本文将涉及强化学习的术语和基本组成部分,以及不同类型的强化学习(无模型、基于模型、在线学习和离线学习)。本文最后用算法来说明不同类型的强化学习。本文的公式基于Stuart J. Russell和Peter Norvig的教科书《Artificial Intelligence: A Modern Approach》(第四版),为了保持数学方程格式的一致性所以略有改动。
强化学习
在深入研究不同类型的强化学习和算法之前,我们应该熟悉强化学习的组成部分。- Agent:从环境中接收感知并执行操作的程序,被翻译成为智能体,但是我个人感觉代理更加恰当,因为它就是作为我们人在强化学习环境下的操作者,所以称为代理或者代理人更恰当
- Environment:代理所在的真实或虚拟环境
- State (S):代理当前在环境中所处的状态
- Action (A):代理在给定状态下可以采取的动作
- Reward (R):采取行动的奖励(依赖于行动),处于状态的奖励(依赖于状态),或在给定状态下采取行动的奖励(依赖于行动和状态)
强化学习的目标是通过优化所采取的行动来最大化总累积奖励。和婴儿一样,我们不都想从生活中获得最大的累积利益吗?
马尔可夫决策过程(MDP)
由于强化学习涉及一系列最优行为,因此它被认为是一个连续的决策问题,可以使用马尔可夫决策过程建模。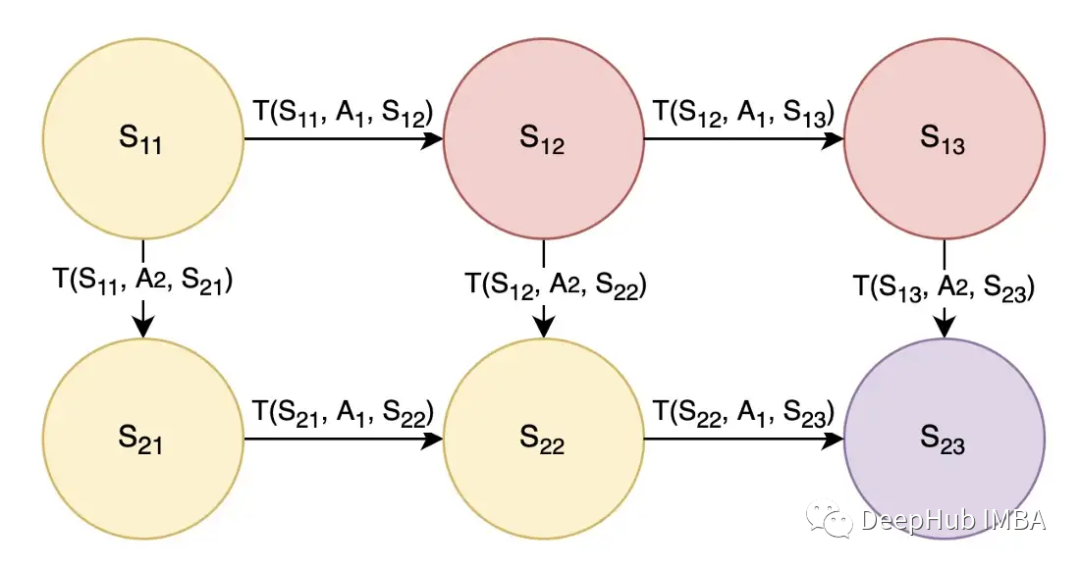 这里的状态(用S表示)被建模为圆圈,动作(用A表示)允许代理在状态之间转换。在上图2中,还有一个转换概率(用T表示),T(S11, A1, S12)是在状态S11采取A1动作后转换到状态S12的概率。我们可以认为动作A1是向右的动作A2是向下的。为了简单起见,我们假设转移概率为1,这样采取行动A1将确保向右移动,而采取行动A2将确保向下移动。参照图2,设目标为从状态S11开始,结束于状态S23,黄色状态为好(奖励+1),红色状态为坏(奖励-1),紫色为目标状态(奖励+100)。我们希望智能体了解到最佳的行动或路线是通过采取行动A2-A1-A1来走向下-右-右,并获得+1+1+1+100的总奖励。再进一步,利用金钱的时间价值,我们在奖励上应用折扣因子gamma,因为现在的奖励比以后的奖励更好。综上所述,从状态S11开始执行动作A2-A1-A1,预期效用的数学公式如下:
这里的状态(用S表示)被建模为圆圈,动作(用A表示)允许代理在状态之间转换。在上图2中,还有一个转换概率(用T表示),T(S11, A1, S12)是在状态S11采取A1动作后转换到状态S12的概率。我们可以认为动作A1是向右的动作A2是向下的。为了简单起见,我们假设转移概率为1,这样采取行动A1将确保向右移动,而采取行动A2将确保向下移动。参照图2,设目标为从状态S11开始,结束于状态S23,黄色状态为好(奖励+1),红色状态为坏(奖励-1),紫色为目标状态(奖励+100)。我们希望智能体了解到最佳的行动或路线是通过采取行动A2-A1-A1来走向下-右-右,并获得+1+1+1+100的总奖励。再进一步,利用金钱的时间价值,我们在奖励上应用折扣因子gamma,因为现在的奖励比以后的奖励更好。综上所述,从状态S11开始执行动作A2-A1-A1,预期效用的数学公式如下:
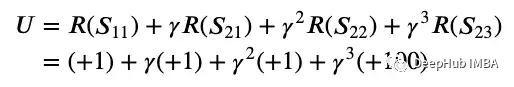
- 转移概率不可能是1,因为需要在行动中考虑不确定性因素,例如采取某些行动可能并不总是保证成功地向右或向下移动。因此,我们需要在这个不确定性上取一个期望值
- 最优动作可能还不知道,因此一般的表示方式是将动作表示为来自状态的策略,用π(S)表示。
- 奖励可能不是基于黄色/红色/紫色状态,而是基于前一个状态、行动和下一个状态的组合,用R(S1, π(S1), S2)表示。
- 问题可能不需要4步就能解决,它可能需要无限多的步骤才能达到目标状态
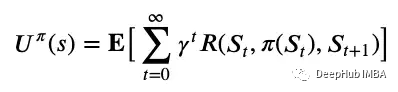
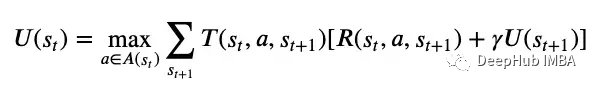
MDP一般用(S, A, T, R)表示,它们分别表示一组状态,动作,转移函数和奖励函数。MDP假设环境是完全可观察的,如果代理不知道它当前处于什么状态,我们将使用部分可观察的MDP (POMDP) 图5中的Bellman方程,可以使用值迭代或策略迭代来求解最优策略,这是一种将效用值从未来状态传递到当前状态的迭代方法。
强化学习类似于求解MDP,但现在转移概率和奖励函数是未知的,代理必须在训练期间执行动作来学习
无模型与基于模型的强化学习
上面提到的MDP示例是基于模型的强化学习。基于模型的强化学习具有转移概率T(s1, a, s2)和奖励函数R(s1, a, s2),它们是未知的,他们表示要解决的问题。基于模型的方法对仿真很有用。基于模型的强化学习的例子包括值迭代和策略迭代,因为它使用具有转移概率和奖励函数的MDP。无模型方法不需要知道或学习转移概率来解决问题。我们的代理直接学习策略。无模型方法对于解决现实问题很有用。无模型强化学习的例子包括Q-learning 和策略搜索,因为它直接学习策略。
离线学习vs.在线学习
离线学习和在线学习又称为被动学习和主动学习。离线学习在离线(被动)学习中,通过学习效用函数来解决该问题。给定一个具有未知转移和奖励函数的固定策略,代理试图通过使用该策略执行一系列试验来学习效用函数。例如,在一辆自动驾驶汽车中,给定一张地图和一个要遵循的大致方向(固定策略),但控制出错(未知的转移概率-向前移动可能导致汽车稍微左转或右转)和未知的行驶时间(奖励函数未知-假设更快到达目的地会带来更多奖励),汽车可以重复运行以了解平均总行驶时间是多少(效用函数)。离线强化学习的例子包括值迭代和策略迭代,因为它使用使用效用函数的Bellman方程(图5)。其他的一些例子包括直接效用估计、自适应动态规划(Adaptive Dynamic Programming, ADP)和时间差分学习(Temporal-Difference Learning, TD),这些将在后面详细阐述。在线学习在线(主动)学习中,通过学习规划或决策来解决问题。对于基于模型的在线强化学习,有探索和使用的阶段。在使用阶段,代理的行为类似于离线学习,采用固定的策略并学习效用函数。在探索阶段,代理执行值迭代或策略迭代以更新策略。如果使用值迭代更新策略,则使用最大化效用/值的一步前瞻提取最佳行动。如果使用策略迭代更新策略,则可获得最优策略,并可按照建议执行操作。以自动驾驶汽车为例,在探索阶段,汽车可能会了解到在高速公路上行驶所花费的总时间更快,并选择向高速公路行驶,而不是简单地沿着大方向行驶(策略迭代)。在使用阶段,汽车按照更新的策略以更少的平均总时间(更高的效用)行驶。在线强化学习的例子包括Exploration、Q-Learning和SARSA,这些将在后面几节中详细阐述。当状态和动作太多以至于转换概率太多时,在线学习是首选。在线学习中探索和“边学边用”比在离线学习中一次学习所有内容更容易。但是由于探索中的试错法,在线学习也可能很耗时。需要说明的是:在线学习和基于策略的学习(以及基于策略的离线学习)是有区别的,前者指的是学习(策略可以更改或固定),后者指的是策略(一系列试验来自一个策略还是多个策略)。在本文的最后两部分中,我们将使用算法来解释策略启动和策略关闭。在理解了不同类型的强化学习之后,让我们深入研究一下算法!
1、直接效用估计 Direct Utility Estimation
无模型的离线学习在直接效用估计中,代理使用固定策略执行一系列试验,并且状态的效用是从该状态开始的预期总奖励或预期奖励。以一辆自动驾驶汽车为例,如果汽车在一次试验中从网格 (1, 1) 开始时,未来的总奖励为 +100。在同一次试验中,汽车重新访问该网格,从该点开始的未来总奖励是+300。在另一项试验中,汽车从该网格开始,未来的总奖励为 +200。该网格的预期奖励将是所有试验和对该网格的所有访问的平均奖励,在本例中为 (100 + 300 + 200) / 3。优点:给定无限次试验,奖励的样本平均值将收敛到真实的预期奖励。缺点:预期的奖励在每次试验结束时更新,这意味着代理在试验结束前什么都没有学到,导致直接效用估计收敛非常慢。
2、自适应动态规划 (ADP)
基于模型的离线学习在自适应动态规划 (ADP) 中,代理尝试通过经验学习转换和奖励函数。转换函数是通过计算从当前状态转换到下一个状态的次数来学习的,而奖励函数是在进入该状态时学习的。给定学习到的转换和奖励函数,我们可以解决MDP。以自动驾驶汽车为例,在给定状态下尝试向前移动 10 次,如果汽车最终向前移动 8 次并向左移动 2 次,我们了解到转换概率为 T(当前状态, 向前,前状态)= 0.8 和 T(当前状态,向前,左状态)= 0.2。优点:由于环境是完全可观察的,因此很容易通过简单的计数来学习转换模型。缺点:性能受到代理学习转换模型的能力的限制。这将导致这个问题对于大状态空间来说是很麻烦的,因为学习转换模型需要太多的试验,并且在 MDP 中有太多的方程和未知数需要求解。
3、时间差分学习(TD Learning)
无模型的离线学习在时间差分学习中,代理学习效用函数并在每次转换后以学习率更新该函数。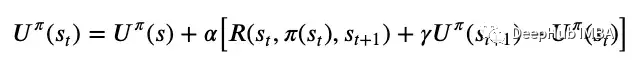 这里的时间差分(temporal difference)是指连续状态之间的效用差异,并根据此误差信号更新效用函数,由学习率缩放,如上图6所示。学习率可以是一个固定的参数,也可以是对一个状态访问量增加的递减函数,这有助于效用函数的收敛。与直接效用估计在每次尝试后进行学习相比,TD学习在每次转换后进行学习,具有更高的效率。与ADP相比,TD学习不需要学习转换函数和奖励函数,使其计算效率更高,但也需要更长的收敛时间。ADP和TD学习是离线强化学习算法,但在线强化学习算法中也存在主动ADP和主动TD学习!
这里的时间差分(temporal difference)是指连续状态之间的效用差异,并根据此误差信号更新效用函数,由学习率缩放,如上图6所示。学习率可以是一个固定的参数,也可以是对一个状态访问量增加的递减函数,这有助于效用函数的收敛。与直接效用估计在每次尝试后进行学习相比,TD学习在每次转换后进行学习,具有更高的效率。与ADP相比,TD学习不需要学习转换函数和奖励函数,使其计算效率更高,但也需要更长的收敛时间。ADP和TD学习是离线强化学习算法,但在线强化学习算法中也存在主动ADP和主动TD学习!4、Exploration
基于模型的在线学习,主动ADPExploration 算法是一种主动ADP算法。与被动ADP算法类似,代理试图通过经验学习转换和奖励函数,但主动ADP算法将学习所有动作的结果,而不仅仅是固定的策略。它还有一个额外的函数,确定代理在现有策略之外采取行动的“好奇程度”。这个函数随着效用的增加而增加,随着经验的减少而减少。如果状态具有高效用,则探索函数倾向于更频繁地访问该状态。探索功能随着效用的增加而增加。如果状态之前没有被访问过或访问过足够多次,探索函数倾向于选择现有策略之外的动作。如果多次访问状态,则探索函数就不那么“好奇”了。由于好奇程度的降低,探索功能随着经验的增加而降低。优点:探索策略会快速收敛到零策略损失(最优策略)。缺点:效用估计的收敛速度不如策略估计的快,因为代理不会频繁地出现低效用状态,因此不知道这些状态的确切效用。
5、Q-Learning
无模型的在线学习,主动TD学习Q-Learning 是一种主动的 TD 学习算法。图 6 中的更新规则保持不变,但现在状态的效用表示为使用 Q 函数的状态-动作对的效用,因此得名 Q-Learning。被动 TD 学习与主动 TD 学习的更新规则差异如下图 7 所示。
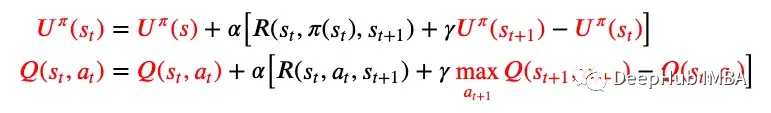
缺点:它不看到未来的情况,所以当奖励稀少时可能会遇到困难。与 ADP 相比,它学习策略的速度较慢,因为本地更新不能确保 Q 值的一致性。
6、SARSA
无模型的在线学习,主动TD学习SARSA是一种主动TD学习算法。算法名称SARSA源自算法的组件,即状态S、动作A、奖励R、(下一个)状态S和(下一个)动作A。这意味着SARSA算法在更新Q函数之前,要等待下一个状态下执行下一个动作。相比之下,Q-Learning是一种“SARS”算法,因为它不考虑下一个状态的动作。SARSA 算法知道在下一个状态下采取的动作,并且不需要在下一个状态下的所有可能动作上最大化 Q 函数。Q-Learning与SARSA的更新规则差异显示在下面的图8中。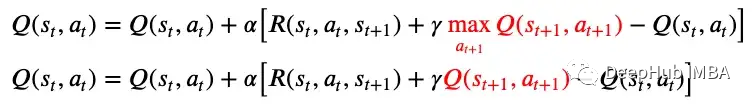 SARSA 以“策略”或者当前正在运行的策略的下一个状态的效用的q函数为目标,这样就能够获得下一个状态下的实际动作。也就是说如果Q-Learning不探索其他操作并在下一个状态下遵循当前策略,则它与SARSA相同。优点:如果整个策略由另一个代理或程序控制,则适合使用策略,这样代理就不会脱离策略并尝试其他操作。
SARSA 以“策略”或者当前正在运行的策略的下一个状态的效用的q函数为目标,这样就能够获得下一个状态下的实际动作。也就是说如果Q-Learning不探索其他操作并在下一个状态下遵循当前策略,则它与SARSA相同。优点:如果整个策略由另一个代理或程序控制,则适合使用策略,这样代理就不会脱离策略并尝试其他操作。缺点:SARSA不如Q-Learning灵活,因为它不会脱离策略来进行探索。与 ADP 相比,它学习策略的速度较慢,因为本地更新无法确保与 Q 值的一致性。
总结
在本文中我们介绍了强化学习的基本概念,并且讨论了6种算法,并将其分为不同类型的强化学习。 这6种算法是帮助形成对强化学习的基本理解的基本算法。还有更有效的强化学习算法,如深度Q网络(Deep Q Network, DQN)、深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)等算法,具有更实际的应用。
这6种算法是帮助形成对强化学习的基本理解的基本算法。还有更有效的强化学习算法,如深度Q网络(Deep Q Network, DQN)、深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)等算法,具有更实际的应用。我一直觉得强化学习很有趣,因为它阐明了人类如何学习以及我们如何将这些知识传授给机器人(当然也包括其他应用,如自动驾驶汽车、国际象棋和Alpha Go等)。希望本文能够让你对强化学习有了更多的了解,并且知道了强化学习的不同类型,以及说明每种类型的强化学习的算法。
END
欢迎加入Imagination GPU与人工智能交流2群 入群请加小编微信:eetrend89
入群请加小编微信:eetrend89(添加请备注公司名和职称)
推荐阅读 对话Imagination中国区董事长:以GPU为支点加强软硬件协同,助力数字化转型ICCAD 2022,Imagination邀您共聚厦门!
Imagination Technologies 是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech!
原文标题:强化学习的基础知识和6种基本算法解释
文章出处:【微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- imagination
-
反向强化学习的思路2019-04-03 2492
-
深度强化学习实战2021-01-10 2967
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28889
-
人工智能机器学习之强化学习2018-05-30 1887
-
基于强化学习的MADDPG算法原理及实现2018-11-02 23275
-
如何构建强化学习模型来训练无人车算法2018-11-12 5766
-
懒惰强化学习算法在发电调控REG框架的应用2020-01-16 1473
-
基于PPO强化学习算法的AI应用案例2020-07-29 3671
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1452
-
一种新型的多智能体深度强化学习算法2021-06-23 1069
-
7个流行的强化学习算法及代码实现2023-02-03 2052
-
强化学习的基础知识和6种基本算法解释2023-01-05 2203
-
什么是深度强化学习?深度强化学习算法应用分析2023-07-01 2359
-
基于强化学习的目标检测算法案例2023-07-19 1266
-
如何使用 PyTorch 进行强化学习2024-11-05 1988
全部0条评论

快来发表一下你的评论吧 !
