

轻松学Pytorch之Deeplabv3推理
描述
Deeplabv3
Torchvision框架中在语义分割上支持的是Deeplabv3语义分割模型,而且支持不同的backbone替换,这些backbone替换包括MobileNetv3、ResNet50、ResNet101。其中MobileNetv3版本训练数据集是COCO子集,类别跟Pascal VOC的20个类别保持一致。这里以它为例,演示一下从模型导出ONNX到推理的全过程。ONNX格式导出
首先需要把pytorch的模型导出为onnx格式版本,用下面的脚本就好啦:
model = tv.models.segmentation.deeplabv3_mobilenet_v3_large(pretrained=True)
dummy_input = torch.randn(1, 3, 320, 320)
model.eval()
model(dummy_input)
im = torch.zeros(1, 3, 320, 320).to("cpu")
torch.onnx.export(model, im,
"deeplabv3_mobilenet.onnx",
verbose=False,
opset_version=11,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=['input'],
output_names=['out', 'aux'],
dynamic_axes={'input': {0: 'batch', 2: 'height', 3: 'width'}}
)
模型的输入与输出结构如下:
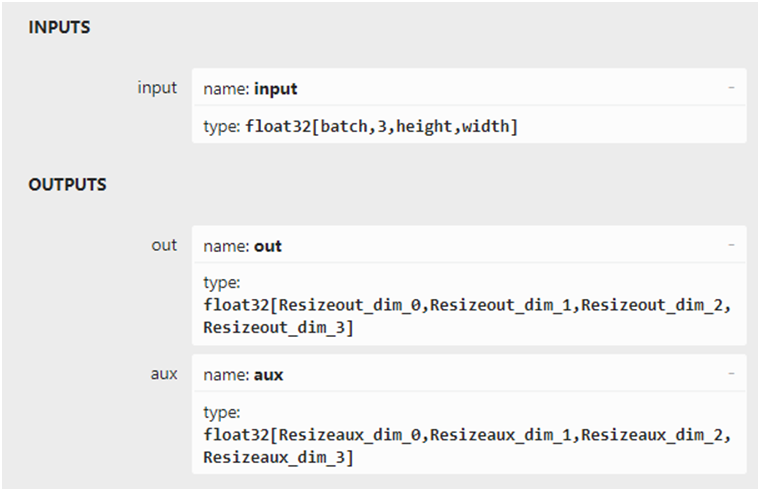
推理测试
模型推理对图像有个预处理,要求如下:
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
意思是转换为0~1之间的浮点数,然后减去均值除以方差。
剩下部分的代码就比较简单,初始化onnx推理实例,然后完成推理,对结果完成解析,输出推理结果,完整的代码如下:
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
sess_options = ort.SessionOptions()
# Below is for optimizing performance
sess_options.intra_op_num_threads = 24
# sess_options.execution_mode = ort.ExecutionMode.ORT_PARALLEL
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
ort_session = ort.InferenceSession("deeplabv3_mobilenet.onnx", providers=['CUDAExecutionProvider'], sess_options=sess_options)
# src = cv.imread("D:/images/messi_player.jpg")
src = cv.imread("D:/images/master.jpg")
image = cv.cvtColor(src, cv.COLOR_BGR2RGB)
blob = transform(image)
c, h, w = blob.shape
input_x = blob.view(1, c, h, w)
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# compute ONNX Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(input_x)}
ort_outs = ort_session.run(None, ort_inputs)
t1 = ort_outs[0]
t2 = ort_outs[1]
labels = np.argmax(np.squeeze(t1, 0), axis=0)
print(labels.dtype, labels.shape)
red_map = np.zeros_like(labels).astype(np.uint8)
green_map = np.zeros_like(labels).astype(np.uint8)
blue_map = np.zeros_like(labels).astype(np.uint8)
for label_num in range(0, len(label_color_map)):
index = labels == label_num
red_map[index] = np.array(label_color_map)[label_num, 0]
green_map[index] = np.array(label_color_map)[label_num, 1]
blue_map[index] = np.array(label_color_map)[label_num, 2]
segmentation_map = np.stack([blue_map, green_map, red_map], axis=2)
cv.addWeighted(src, 0.8, segmentation_map, 0.2, 0, src)
cv.imshow("deeplabv3", src)
cv.waitKey(0)
cv.destroyAllWindows()
运行结果如下:
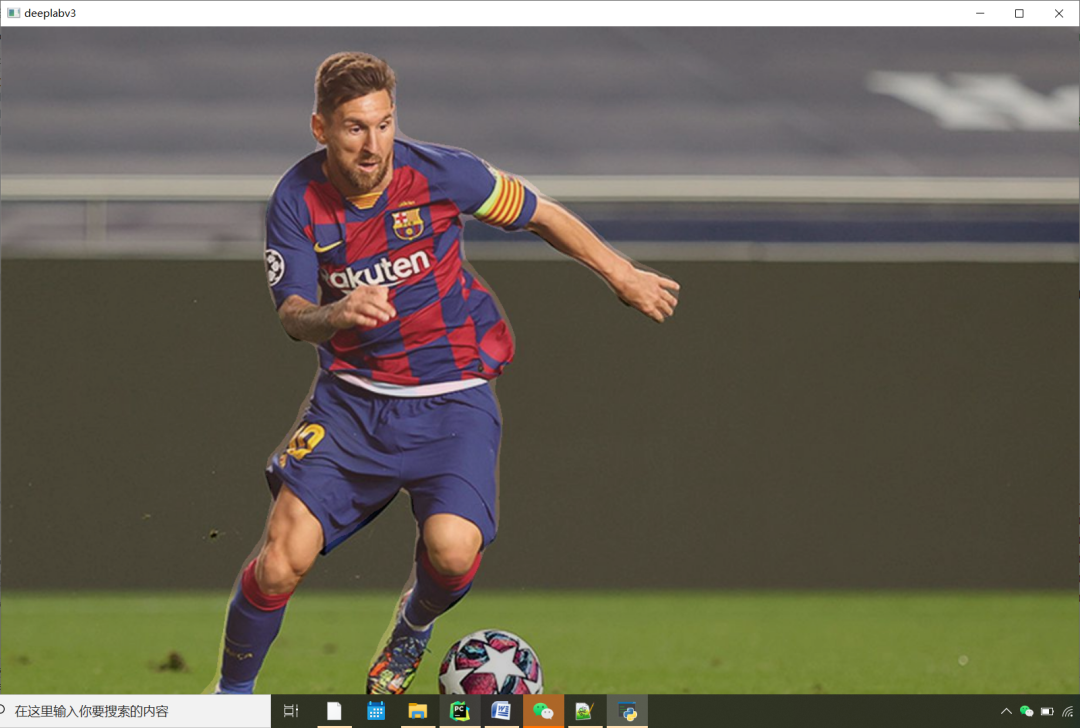
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
北京迅为itop-3588开发板NPU例程测试deeplabv3 语义分割2025-07-22 1201
-
2.0优化PyTorch推理与AWS引力子处理器2023-08-31 1603
-
DeepLabV3开发板应用2023-06-20 736
-
PyTorch教程18.3之高斯过程推理2023-06-05 647
-
使用LabVIEW实现 DeepLabv3+ 语义分割含源码2023-05-26 2094
-
使用LabVIEW实现基于pytorch的DeepLabv3图像语义分割2023-03-22 2685
-
基于Deeplabv3架构的串联空洞卷积神经网络2021-04-29 973
-
Pytorch入门之的基本操作2020-05-22 2779
全部0条评论

快来发表一下你的评论吧 !
