

基于智能状态和源代码插桩的C程序内存安全性动态分析
电子说
描述
作者介绍
陈哲,南京航空航天大学副教授,硕士生导师。研究方向:软件验证,程序分析,形式化方法等。
摘要
C 程序的内存错误可能导致程序崩溃和安全缺陷,因此使用动态分析工具在运行时自动发现内存错误是工业界面临的一个痛点,然而传统的内存安全性动态分析工具具有三个缺点:低有效性、优化敏感和平台依赖。
为了克服以上问题,我们提出了一种基于智能状态的监控算法和一种源代码级别的插桩框架,并依此实现了一款新的动态分析工具 —— Movec。实验表明,Movec 工具比 AddressSanitizer、Valgrind 等著名工具能找到更多的内存错误,在性能和可用性方面也非常有竞争力。这项长达五年的持续研究已经在 ISSTA’19 [1]、ISSTA’21 [2]、ICSE’22 [3]、IEEE TSE [4] 等顶级会议和期刊发表了 4 篇论文,并获得一次 ACM SIGSOFT 杰出论文奖。
以下为正文。
# 背景 #
今天为大家带来 C 程序内存安全性动态分析相关工作的分享,包含两个创新点,一个是 智能状态,一个是 源代码插桩。
C 语言经常被应用于系统软件的编程,比如嵌入系统、操作系统、编译器等,它可以对内存进行低级别的控制。然而由于开发人员水平参差不齐,C 程序极易出现内存错误,导致数据腐败、程序崩溃等一系列漏洞。
使用静态分析工具,可以在不运行程序的情况下,在程序编译期间发现错误。 但由于不可判定性,静态分析工具往往会产生误报。这时我们需要在准确性和性能之间做出平衡,往往需要牺牲一些精确性来获得更好的性能。
使用动态分析工具,可以在运行时动态分析程序执行有无错误。 动态分析工具一般情况下不会产生误报,但可能产生一些 运行时负载,即程序的运行速度会比未插桩分析之前的程序慢。但通常来说,动态分析工具一般用于测试阶段,这种为程序带来的慢是可以接受的,所以动态分析工具现在很流行。
# 内存错误类别
我们将内存错误分为四类:
空间错误 Spatial Errors
即对空指针或未初始化指针的解引用。比如数组越界,定义一个数组,大小是 10,如果访问第 11 个元素,那么就发生了越界,属于空间错误。
时间错误 Temporal Errors
包含悬空指针,或者对指针的二次释放。比如在堆里分配一个内存,把它释放掉后,接着又去访问它或者释放它。
段混淆错误 Segment Confusion Errors
即未根据指针预期的类型来使用指针。比如有一个函数指针,正常应该用指针去调用函数,但使用时却用指针来输出里面的指针所指向区域的数据。
内存泄漏错误 Memory Leaks
即堆内存上存在不会再被使用也未被释放的对象。比如,在内存中分配了一个对象,但其既未被使用,也未被释放,导致内存越用越少,形成内存泄露。
# 动态分析方法和工具
## 监控方法
动态分析的 监控方法 有很多种。这些监控方法有一个共同点,即 在运行时维护一些元数据。这些元数据用来描述程序当中的一些空间和时间信息,比如,一个对象“被分配了多少空间”、“是否现在还存在于内存当中”、“是否正在被使用”等等。根据这些元数据信息,可以判断程序当中是否有内存错误。
下面列出了动态分析的几种主要监控方法,以及支持的工具。比如 SoftBoundCETS [5],使用基于指针的方法和基于标识符的方法;Google 的 ASan [6] 使用了面向对象的方法和内存哨兵技术。保存元数据是这些工具基本的思想。
基于指针的方法:SoftBoundCETS
基于标识符的方法:SoftBoundCETS
面向对象的方法:Google's ASan, Valgrind [7]
内存哨兵技术:Google's ASan
举个例子,假设在内存当中使用 malloc 分配了一个内存空间,工具会记录 p 所指向的空间的基地址是 p 的值,上界是 p+100。如果程序访问的是 [p, p+100] 之间的内存,则工具会判定是合法的,若程序访问超出了这个范围的内存,比如 p+101,则工具会认定是一个内存错误。
int *p = malloc(100*sizeof(int)); // The base of p is "p". // The bound of p is "p + 100".
## 插桩框架
动态分析工具的另一个基础技术是 插桩框架。这些插桩框架需要在待验证的程序中插入一些代码片段,这些代码片段实现的就是监控元数据的方法。被插入的代码片段会随着程序的运行而运行,并收集数据来判定是否有内存错误。
现有的插桩框架都是在中间代码或者二进制层面上进行插桩,目前没有在源代码级别进行插桩的工具。
中间代码层 (中间表示):SoftBoundCETS, Google's ASan
二进制层 (目标代码,可执行文件):Valgrind
# 面临的挑战 #
现有的算法和框架,面临着三个挑战。
一是 有效性比较低 low effectiveness。现有的方法无法 确定地、完整地 找到所有的内存错误,包括子对象越界、释放后使用、段混淆、内存泄漏。
此外,现有的算法工具 对优化敏感 optimization sensitivity。不同的编译器优化级别会对检测的最终结果造成影响,一些在低优化级别能找到的内存错误在高优化级别下就找不到了。
第三个挑战是 平台依赖 platform dependence。现有工具只能在一些主流的平台上运行,如 Linux、Windows;无法在一些特定的领域系统上使用,如航空航天领域、嵌入式系统领域,操作系统如 VxWorks 和 uC/OS、架构如 MIPS, MicroBlaze, RISC-V 等。
下面是具体的挑战举例。
# 低有效性
段混淆错误
以非法的解引用为例。
下面的示例代码中,定义了一个指针 s 指向一个函数 (第七行)。但在使用时 (第八行),访问的是它所指向的内存空间里面的第 0 号元素。这个错误可能引起信息泄露 information leakage。
// Example 1: Using a function as data
// This error may cause information
// leakage.
1 void foo(); /* a func */
2 char *func(char *c) {
3 return c;
4 }
5 int main() {
6 void (*p)() = foo;
7 char *s = func(p);
8 char ch = s[0]; /*error*/
9 return 0;
10 }
下面示例代码中,定义了一个指针 p,指向数组里面的一个元素。但在使用时,把它当成了一个函数来调用 (第七行)。这种错误可能引起控制流劫持 control-flow hijacking。
// Example 2: Using data as a function
// This error may cause control-
// flow hijacking.
1 void (*f(void (*p)()))() {
2 return p;
3 }
4 int main() {
5 int a[100];
6 void (*p)() = f(a);
7 (*p)(); /*error*/
8 return 0;
9 }
这些错误已有的工具都是发现不了的。
子对象越界
下面示例代码中,有一个指针 p,指向一个结构体 s 的成员 m1 (第七行),但在使用时,超出了 m1 的范围 (第八行)。
// Example 3: Sub-object overflow
// An overflow from a field of a
// struct to another
1 typedef struct {
2 int m1;
3 int m2;
4 } st;
5 int main() {
6 st s;
7 int *p = &s.m1;
8 p[1] = 0; /*spatial error*/
9 return 0;
10 }
下面示例代码中,定义了数组 buf (第二行),但在访问时,超出了数组所指向的范围 (第七行)。由于 buf 是处于结构体的内部,所以已有的工具也发现不了。
// Example 4: Intra-array overflow
// An overflow from an array element
// to another
1 typedef struct {
2 char buf[10];
3 int i;
4 } st;
5 int main() {
6 st arr[5];
7 p[2].buf[20] = 'A';
8 /*spatial error*/
9 return 0;
10 }
内存释放后使用
这种错误指释放一个内存对象之后再访问它。对于这种错误,现有的工具只能以概率的方式 (lock key scheme) 或者部分的方式 (object-based 和 quarantine-based 方法) 来检测此种错误,受限于算法本身的缺陷,会造成假阴性 false negative 的结果。
内存泄漏
现有工具只能在程序终止时才能检测到内存泄漏,在程序运行过程当中,也就是内存泄漏发生的地方,工具是无法及时发现的。
# 优化敏感
空间错误
下面代码示例中有一个内存错误,指针 p 指向了变量 i 的地址 (第四行),在解引用时超出了 i 的范围 (第六行)。
// Example 5: A spatial error // *(p+5) causes a spatial eror. /* Option -O1 hides error. */ 1 #include2 int main() { 3 int a[10] = {0}; 4 int i=1, sum=0, *p=&i; 5 6 *(p+5) = 1; /* spatial error */ 7 8 for (i=0; i<10; i++) 9 sum += a[i]; 10 printf("sum is %d ", sum); 11 return 0; 12 }
针对上面的错误,已有的工具检测结果如下所示。当使用比较高级别的优化时,工具就没有那么有效了。

ASan and Valgrind are the same on other programs.
时间错误
下面示例中,第九行 *n 存在时间错误。
// Example 6: A temporal error // Dereferencing n accesses an out-of // -scope stack variable x, resulting // in a temporal error. /* Option -O2 hides error */ 1 #include2 void foo(int **p_addr) { 3 int x; 4 *p_addr = &x; 5 } 6 int main() { 7 int *n; 8 foo(&n); 9 printf("%d ", *n); 10 /*temporal error*/ 11 return 0; 12 }
工具查找结果如下图所示。

出现这种问题的根本原因是 编译器优化。编译器优化会导致源代码和二进制代码之间并不完全一致,这会使得工具在对优化之后的代码进行插桩时出现一些问题,使得原来在源码中的错误无法被检测到。这也是在中间表示和二进制代码上插桩的局限性。
所以,我们在使用这些工具的时候,需要在性能和有效性上做一个平衡。比如使用 -O0 的时候,获得的有效性会比较高,但牺牲了性能;选择更高的优化水平,比如使用 -O3 时,就要接受其有效性可能会受到一定的损失。
# 平台依赖性
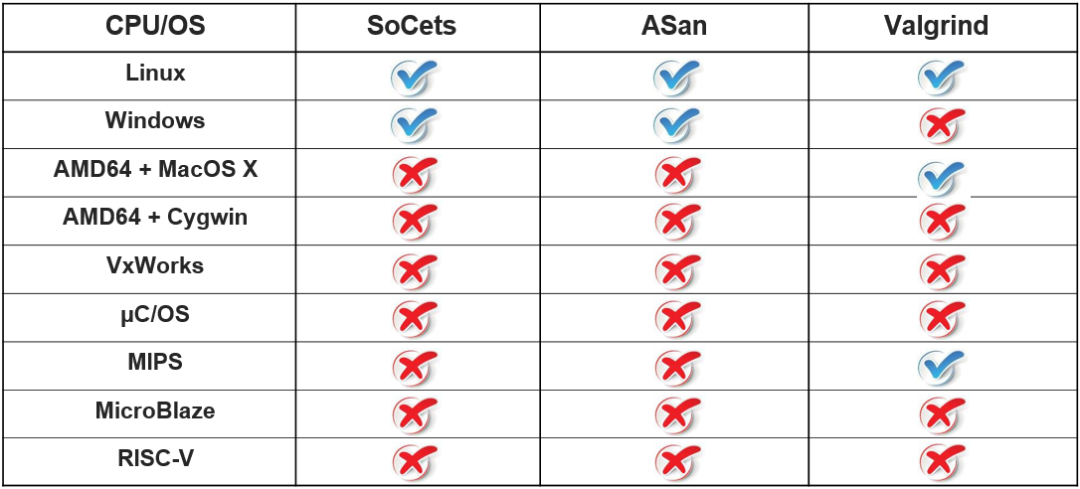
中间表示级或二进制级的工具总是被集成到有限的依赖于平台的宿主编译器中。比如基于 LLVM 的 SoCets 和 ASan,以及基于二进制级的框架 Valgrind。但 C 是一种跨平台的编程语言,这些强平台依赖的工具无法支持我们在不支持的平台上测试或者部署插桩代码。
下图总结了目前工具所适用的平台情况。
# 我们的工作 —— Movec #
有什么办法来解决上述的三个局限性呢?我们从两个方面来解决这三个问题。
第一个是在 监控算法 上面的创新。
我们提出一种 基于智能状态的监控算法 (smart-status-based, Smatus),该监控算法可以全面地检测到上文提到的所有内存错误。
其核心思想是使用了 状态节点,当在内存当中创建一个内存对象时,就会给这个对象创建一个状态节点,记录内存对象当前的状态,比如是否仍在活跃当中、是否已被释放等。除了跟踪每个指针所指的边界外,还会维护一个引用计数,用以记录这些内存状态到底被多少个指针所引用。由于有了这些额外的元信息,我们就可以找出现有工具找不出的内存错误。
第二,我们提出了一个新的 源代码级别的插桩框架。
这个插桩框架并不改写中间表示或二进制代码,而是直接对程序员所写的原始源代码进行操作,并且插入 ANSI C 的源代码片段,因此插桩后产生的源代码摆脱了平台依赖,可以使用任何的 C 编译器编译。
我们实现了一个工具 Movec,结合了上面两方面的技术。Movec 架构和工作流如下,包含了一个预处理器、一个 AST 解析器、一个 AST 访问器 (这个访问器里面实际上包含了源代码的插桩框架)。当输入一个 C 程序时,程序会依次经过 预处理器 -> 解析器 -> 访问器。
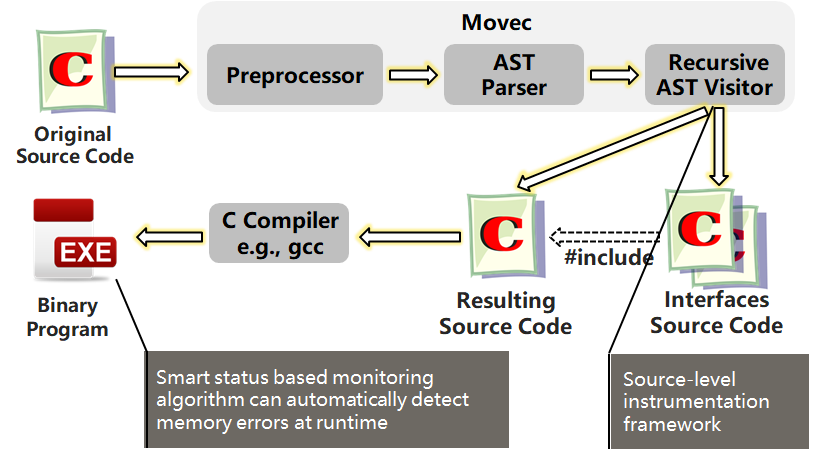
代码插桩发生在 AST 访问器 (AST Visitor) 里。Movec 会对源代码进行改写,生成一个修改后的源程序,以及一些接口源文件。这些接口源文件包含了监控算法的代码,会被自动地包含到修改后的 C 程序当中,通过对此时的 C 程序进行编译,就得到了一个可执行文件。运行该可执行文件时,基于智能状态的监控算法就能够自动地捕获程序里的错误。
# 基于智能状态的监控算法
## 算法实现原理
下面通过几个例子,说明基于智能状态的监控算法的基本原理,便于大家有一个更直观的理解。
子对象越界
定义结构体 st 中有两个成员 m1 和 m2。
声明一个结构体 s,假设给 s 分配的内存空间范围是 [0x3000, 0x3016]。此时,监控算法会给 s 创建一个状态节点,包括状态 stack,和一个引用计数 1。
接下来执行第二行代码,让一个指针 p 指向 s.m1,这个时候会给 p 创建一个元数据,元数据里面会记录 p 指向的上界 0x3008 和下界 0x3000。元数据里还有一个指针会指向 s 的状态节点,通过指针就能够找到它所指向的变量是在堆中还是栈中。同时,引用计数变成 2。
第三行代码中,使用 p[1] 访问 p 所指向的对象,这时候监控算法会去查询元数据,看到它能够访问的正常范围 [0x3000, 0x3008],而我们要访问的范围实际上是 [0x3000, 0x3016],显然超出了所记载的范围,这个时候工具就会报错,因为访问的范围超过了元数据中所记录的范围。

段混淆
程序中有一个函数 foo(),在内存当中会给这个函数分配一个空间。假设它的内存地址是 [0x1000, 0x1256]。接下来会给这个函数创建一个状态节点,说明它的状态是一个函数 function,它的引用计数初始值是 1。
第一行代码中,用一个指针 p 指向这个函数,给指针 p 创建一个元数据,记录它所指向的上界和下界。由于它是一个函数,进行特殊处理后,记录上界是 0x1000,下界是 0x1001。它也有一个指针指向它的状态节点,引用计数变成 2。
第二行代码中,指针变量 s 也指向这一个函数。也会给 s 创建一个元数据,它的上界是 0x1000,下界是 0x1001。它有一个指针指向状态节点,同时引用计数变成 3。
第三行代码中,用 s[0] 来访问元素,监控算法会去查询它所指向的对象是什么。图中显示是一个函数 function,但是解引用的方式却使用了数组元素解引用的方式,所以会发现它的段类型和使用指针的方式并不匹配,是一个段混淆错误。

时间错误
首先,使用 malloc 在堆里面分配一个内存对象,范围是 [0x2000, 0x2008]。接下来给这个内存对象创建一个状态节点,说明它的状态是 heap,计数器初始值是 0。
在执行 p1 = (int*)malloc(8) 时,给 p1 创建一个元数据,p1 的状态节点指针也指向这一个状态节点,计数器为 1,现在有一个指针指向它。接下来 p2=p1,给 p2 也创建一个指针元数据,记录 base 和 bound,它的指针也指向这一个状态节点,计数器变成 2。
接下来程序执行 free(p1),释放堆中的内存,将状态节点中的状态从 heap 改成 invalid,表示它已经被释放。
对 p2 进行解引用,监控算法会去检查 p2 所指向的对象是否还存在于内存当中。结果发现状态变成了 invalid,显然这是一个已经被释放的对象,所以工具会发现在访问一个已经被释放的内存对象,是一个时间错误。

内存泄露
在内存中分配一个堆中的对象,给它创建一个状态节点,指针 p1、p2 的元数据指向这个状态节点,计数器变成 2。
接下来使用 p1、p2 指向 i 的地址,i 是一个栈里面的变量,这时 i 的计数器变为 2,heap 的计数器变为 0。
这时监控算法会发现有一个堆中的状态节点,计数器是 0,也没有指针指向它,报出一个内存泄漏的错误。

## 算法数据结构
接下来,我会对 Smatus 算法中的基本数据结构做一个介绍。
为了检测对象和子对象层面的空间错误,Smatus 算法会维护一个指针元数据 (pointer metadata, PMD) 的结构,包括所指向内存的 base 和 bound,还有一个指针指向内存块的状态节点。
typedef struct {
void *base;
void *bound;
SND *snda;
} PMD;
Smatus 也会为每个内存对象维护一个状态节点 (status node, SND)。状态节点的结构包括一个记录状态的成员 stat,和一个引用计数的成员 count。状态 stat 主要记录内存块是有效还是无效,是在堆中还是栈中等。引用计数 count 主要记录有多少个指针指向它。
typedef enum {
function, ...
} status;
typedef struct {
status stat;
size_t count;
} SND;
对不同内存错误的检查会用到不同的成员。若是检查空间错误,主要使用 base 和 bound;如果检查时间错误和段混淆错误,主要使用状态 status;如果检查内存泄漏错误,主要使用引用计数 count。
Smatus 也会为每个有指针参数或返回指针的函数创建并维护一个函数元数据 (function metadata, FMD)。当把一些指针传到函数里面,或者是函数返回一个指针的时候,FMD 会储存这个指针的元数据。
对于库函数的调用,Smatus 也有一些特殊的处理。如果库函数是有源代码的,可以用工具直接插桩,不需要做额外的处理。如果没有源代码,是预编译的,需要给它提供一些包装函数 wrapper functions,并且在调用原始函数之前,检查参数的 PMDs 以确保内存安全,在调用后更新存储返回值的变量的 PMDs。
在 Movec 中,我们已经为 C 语言自带的一些库函数写好了包装函数,这部分是可以直接使用的。更多的技术细节在 ISSTA2021 [2] 的论文中,会具体描述监控算法是如何起作用的,此处不再赘述。
# 源代码插桩框架
## 传统基于 IR 的插桩框架
传统的 IR 级别的插桩,会先定义三个基本的接口:
pmd_tbl_lookup() 主要用来查找元数据表,查询元数据的状态、base、bound 等
pmd_tbl_update() 主要用来更新元数据表,当给一个指针进行赋值的时候,需要更新它的元数据
check_dpv() 是当在对指针进行解引用的时候,用来检查是否有产生内存错误
插桩过程举例。
T *p; 定义一个指针 p,通过 pmd_tbl_update 更新 p 的元数据。
p = &i; 给 p 赋值,再次通过 pmd_tbl_update 更新 p 的元数据。根据 p 的地址索引到它的元数据,将元数据更新为 i 的状态、起始地址、结束地址。
p1 = p; 需要将 p1 的元数据更新成和 p 的元数据一致。首先通过 pmd_tbl_lookup 找出 p 的元数据,存到 pmd 变量中,然后通过 pmd_tbl_update 将 pmd 更新到 p1 的元数据中,这样 p1 就获得了它所指向对象的元数据。
i = *p1; 最后对 p1 解引用之前,需要通过 check_dpv 检查 p1 所指向的元数据和它要访问的范围。
T *p; /* or T *p = NULL */ pmd_tbl_update(&p, NULL, NULL, NULL); p = &i; pmd_tbl_update(&p, i_status, &i, &i+1); p1 = p; /* p1 = p + i or p1 = &p[i] */ pmd = pmd_tbl_lookup(&p); pmd_tbl_update(&p1, pmd->status, pmd->base, pmd->bound); check_dpv(pmd_tbl_lookup(&p1), p1, sizeof(*p1)); i = *p1;/* or *p1 = i */
上述方法仅适用于基于 IR 的插桩 (比如 SSA 格式),如果要在源代码上做插桩,该方法会带来一些问题。
首先是内嵌的表达式。比如当两个操作符写在一个语句里面时,在 IR 级别,语句会被拆成两个语句。我们可以在中间插入一些语句进行检测。但是在源代码级别,我们是无法在一个内嵌的语句中间插入一个语句的。
/* nested expressions */ *(--p); /* at the IR-level */ --p; /* we can insert a check here */ /* which is impossible at the source-level*/ check_dpv(pmd_tbl_lookup(&p), p, sizeof(*p)); *p;
类似地,还有指针算术运算、副作用、内嵌的函数调用等问题。
## 源代码插桩
那么如何解决上述问题?
第一步,我们需要将程序中所有可能出现指针的地方列出来。我们定义了一个系统的分类,如下所示,用以表示类型可能在什么地方出现。

Types and storage classes.
具体来说,表中 dlr 表示类型有可能出现在一个指针变量的定义处 (d - definition),还有可能出现在指针变量赋值表达式的左边 (l - lhs),或者是一个赋值表达式的右边 (r - rhs);e 表示指针的解引用 (e - dereference);vpa 表示函数的定义和调用处 (v - return value, p - parameter, a - argument)。除此之外,在结构体和数组当中,也可能包含指针,也需要考虑进去。
我们的源代码插桩框架,主要是通过一个递归的 AST 访问器来遍历整个 AST,并在可能出现指针的地方进行插桩。
我们定义了很多的接口,包括一系列针对不同情况下更新元数据的方法、以及检测的方法,这边不再细述。
/* Interfaces of metadata tables */
/*Lookup for the pmd of a pointer variable by address.*/
PRFpmd *PRFpmd_tbl_lookup(ptr_addr);
/*Update the pmd of a pointer var using status, base and bound.*/
PRFpmd *PRFpmd_tbl_update_as(ptr_addr, status, base, bound);
/*Update the pmd of a pointer var and return the last param.*/
void *PRFpmd_tbl_update_as_ret(ptr_addr, status, base, bound, ret);
/*Update the pmd of a pointer var using the pmd of another one.*/
PRFpmd *PRFpmd_tbl_update_ptr(ptr_addr, ptr_addr2);
/*Update the pmd of a pointer var and return the last param.*/
void *PRFpmd_tbl_update_ptr_ret(ptr_addr, ptr_addr2, ret);
/* Interfaces of checking pmd */
/*Check dereferences of pointer variables.*/
void *PRFcheck_dpv(pmd, ptr, size, ...) {
stat = PRFpmd_get_stat(pmd);
/*Check pointer validity.*/
if(ptr == NULL) print_error ();
/*Check temporal safety.*/
if(pmd == NULL || stat == PRFinvalid) print_error();
/*Check spatial safety.*/
if(ptr < pmd -> base || ptr + size > pmd -> bound) print_error();
return ptr;
}
/* More checking functions */
/*Check dereferences of pointer constants.*/
void *PRFcheck_dpc(base, bound, ptr, size, ...);
/*Check dereferences of function pointer variables.*/
void *PRFcheck_dpfv(pmd, ptr, ...);
/*Check dereferences of function pointer constants.*/
void *PRFcheck_dpfc(base, bound, ptr, ...);
除此之外,还有几个核心的操作。
Getting KPE
第一个是获得核心指针表达式的操作 (比如为了处理加法操作符),如下图所示。在这一个表达式里面,实际上有三个指针 p、p1、p2,在插桩的时候,程序应该要能够自动分析出 p 是指向 p1 所指向的对象,还是 p2 所指向的对象。这里需要使用静态分析的方法,根据类型来进行推导,由于 p1 是一个指针,而 p2 是一个整数,所以右边的表达式中最主要的表达式是 p1,因此 p 应该将其元数据更新为与 p1 一致。

Getting Address
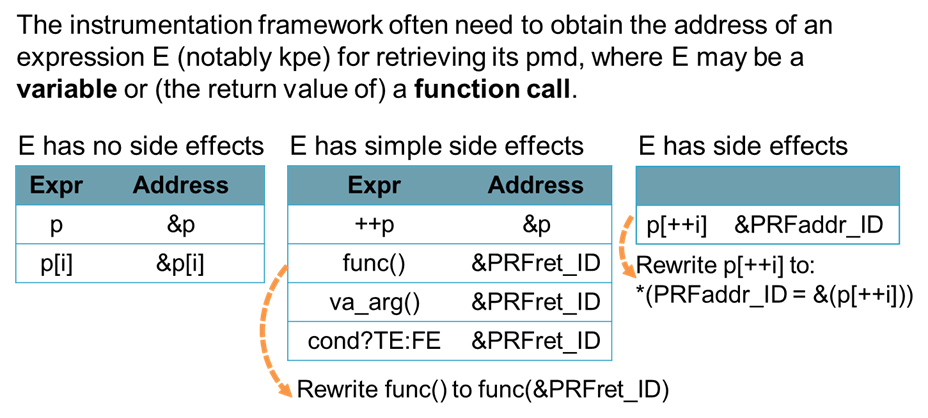
第二个是获得表达式的地址的操作。在存储元数据时,是用指针的地址来作为索引的。所以在更新指针的时候,首先要获得表达式的地址,才能更新它的元数据。简单的变量是很好处理的,比如一个指针变量 p,地址就是 &p。同样地,对于一个数组下标表达式,在前面加一个取地址符即可。
但对于一些复杂的情况,比如 ++p,我们需要先把 p 的地址给存起来 (而不是 ++p 的地址)。对于函数,我们会构造一个新变量 PRFret_ID 去存它的地址,并且将原函数 func() 重写为 func(&PRFret_ID),得到函数返回值的地址,再去索引其函数返回值的元素。
Getting Status, Base, and Bound
类似地,对于一个指针常量,需要获得它的状态、基地址、上界,也是需要静态分析去做的。

有了这些基本的分析以后,就解决了上文基于 IR 插桩中存在的挑战。
当然,在开发的过程中,我们也面临着一些设计上的选择。比如使用了分离的元数据空间 disjoint metadata space,这可能会在运行时带来更高的负载,但是它的兼容性更好。我们还使用了多种存储元数据的方法,包括哈希表和 Trie 中。此外,还可以将一部分元数据当成变量存起来,这样可以带来更快的查找速度,一定程度上降低时间上的负载。
如果大家感兴趣,可以去看我们 ISSTA 2019 [1]、IEEE TSE 2022 [3] 的论文。
# 实验结果 #
工具 Movec 实现了前述的技术。
我们在包括 SARD、MiBench、SPEC、以及自行构建的多个测试集上进行了大量测试,用以评估 Movec 的有效性和性能。
1197 benchmarks from Suites IDs 81, 88 and 89 of the NISTSoftware Assurance Reference Dataset (SARD).
124 benchmarks from a new suite to cover typical memory errors that are not included in the SARD.
20 MiBench benchmarks and 5 pure-C SPEC CPU 2017 benchmarks.
我们将 Movec 与三个最先进的工具进行比较,即谷歌的 ASan、SoCets 和Valgrind。
Movec 和相关实验已通过了 Artifact Evaluation [8]。

实验结果如下。
在检测能力 (即有效性) 方面,Movec 在 SARD 测试集中找出了全部错误,而其他的工具或多或少都会漏掉一些。此外,在打开编译器 O3 优化的情况下,Movec 依然不受影响地找出了全部错误,但是其他的工具找到的错误会大幅度减少。在其他的测试集上,Movec 找到的错也是最多的。
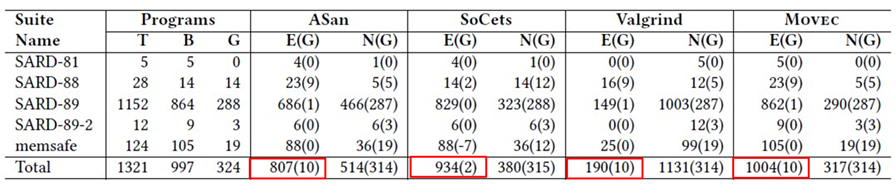
在性能方面,ASan 的速度可能会更快一些,但是它耗费的内存比 Movec 要多。而相比 SoCets 和 Valgrind,Movec 在速度和内存方面都更优。
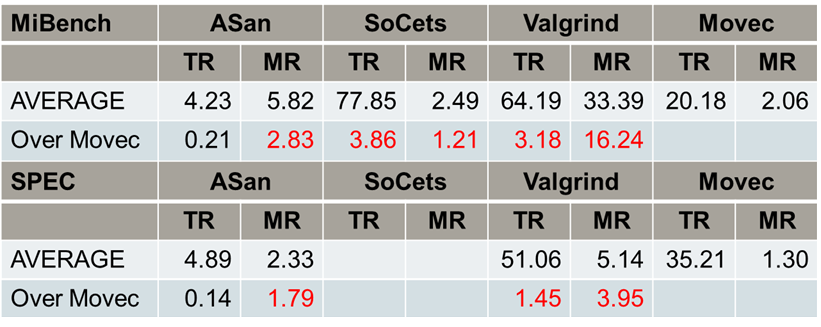
在可用性方面,Movec 支持跨平台,并且报错友好度更高。

# 总结 #
本次分享中,我们提出了一种新的、全面的智能监测算法 Smatus,其中智能的状态是这个方法的核心。Smatus 可以同时检测空间错误、时间错误、段混淆错误和内存泄漏。
我们还提出了一种新的基于源码级的插桩框架,并从中获得了很多好处,比如找到了更多的错误、优化不敏感、支持跨平台、报错友好度更高等。
实验结果表明,Movec 有着更强的错误查找能力和可用性,并且开销适中。
审核编辑:汤梓红
-
智能系统的安全性分析2024-10-29 1664
-
有什么想法可以增强代码安全性吗?2023-04-18 432
-
通过动态分析确定软件安全性2022-11-11 1481
-
请问使用动态内存分配安全吗?2021-12-15 1452
-
Glibc内存管理之Ptmalloc2源代码分析2021-07-29 1293
-
基于定理证明的内存安全验证工具算法综述2021-04-20 4137
-
如何支持物联网安全性和低功耗要求设计2018-12-26 4140
-
安全闪存铸就高安全性智能卡2018-12-07 2340
-
边缘智能的边缘节点安全性2018-10-22 3848
-
VB内存搜索程序及控件源代码2012-10-17 1602
-
动态路由协议安全性分析2011-06-07 1129
-
KIOCWORK:通过源代码分析保证软件安全性2011-04-03 616
-
lc72130的应用C程序源代码2008-07-31 3006
-
mcp2515 c程序源代码2008-06-06 3582
全部0条评论

快来发表一下你的评论吧 !
