

统计压缩编码机理分析(下篇)
描述

文章转发自51CTO【ELT.ZIP】OpenHarmony啃论文俱乐部——《统计压缩编码机理分析》
上篇回顾:《统计压缩编码机理分析(上篇)》6. 算术编码
《上篇》中第五章的“哈夫曼编码”方法建立在符号和码字相对应的基础上。若对信源单符号进行编码,则符号间的相关性就无法考虑:若将 m 个符号合起来编码,第一是会增加设备复杂度,第二是 m+1 个符号间以及组间符号的相关性还是无法考虑。这就使信源编码的匹配原则不能充分满足,编码效率就有所折损。为了克服这种局限性,研究了非分组码的编码方法。
算术编码是一种非分组码,其基本原理是将编码的消息表示成实数0和1之间的一个间隔,消息越长,编码表示它的间隔就越小,表示这一间隔所需的二进制位就越多。
算数编码是一种在有损压缩与无损压缩算法中都经常使用的一种算法,主要应用于图像压缩。算数编码与其它统计编码不同,其它的统计编码通常是把输入的消息分割成符号后对其进行编码,而算数编码则将输入的字符划分成若干个子区间来代表一个字符,计算其概率,进行编码。
6.1 基本机理
算术编码的背后是深刻的数学思想,简单来说,它做了这样一件事情:
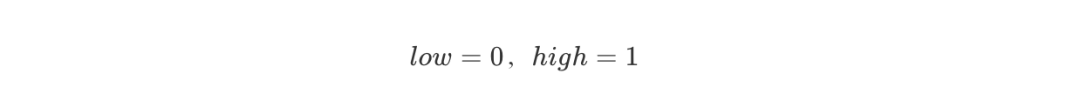
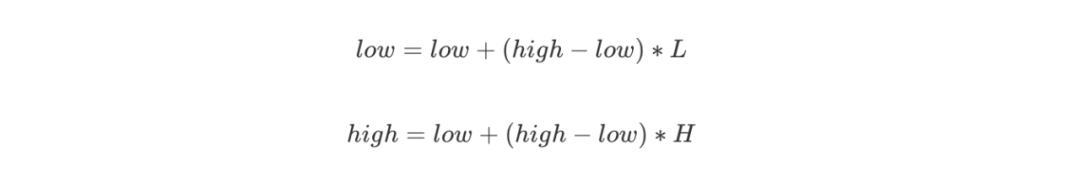
-
假设有一段数据需要编码,统计里面所有的字符和出现的次数
-
将区间 [0,1) 连续划分成多个子区间,每个子区间代表一个上述字符, 区间的大小正比于这个字符在文中出现的概率 p。概率越大,则区间越大。所有的子区间加起来正好是 [0,1)
-
编码从一个初始区间 [0,1) 开始,设置:
-
不断读入原始数据的字符,找到这个字符所在的区间,例如 [ L, H ),更新:
-
最后将得到的区间 [low, high)中任意一个小数以二进制形式输出即得到编码的数据:
6.2 编码过程
给出下面一段十分简单的原始数据:
ARBER
像所有统计编码一样,统计各字符出现的次数与概率:
| 字符 | 次数 | 概率 |
| A | 1 | 0.2 |
| B | 1 | 0.2 |
| E | 1 | 0.2 |
| R | 2 | 0.4 |
将这几个字符的区间在 [0,1) 上按照概率大小连续一字排开,我们得到一个划分好的 [0,1)区间:
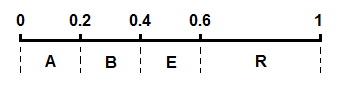
开始编码,初始区间是 [0,1)。注意这里又用了区间这个词,不过这个区间不同于上面代表各个字符的概率区间 [0,1)。这里我们可以称之为编码区间,这个区间是会变化的,确切来说是不断变小。我们将编码过程用下图完整地表示出来:
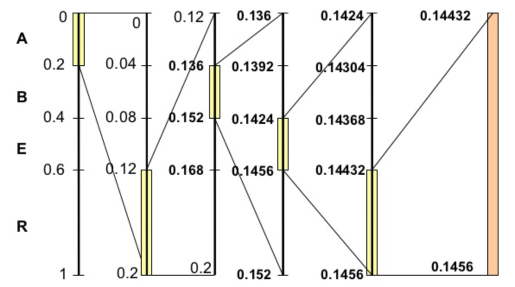
我们对其进行步骤拆解:
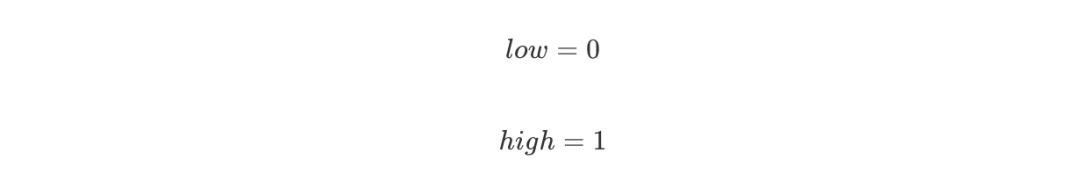
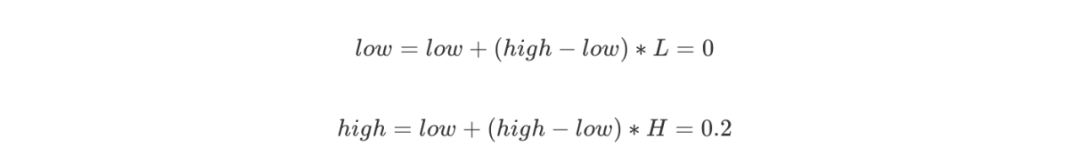
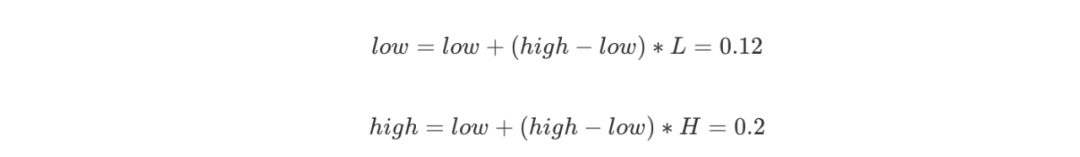
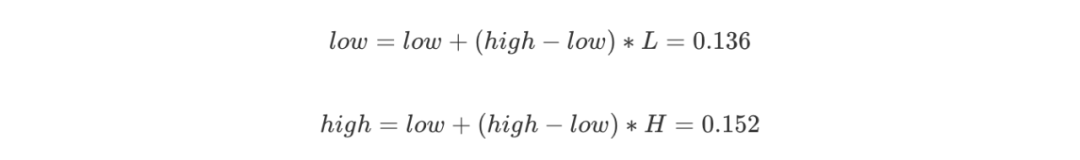
-
刚开始编码区间是 [0,1),即:
-
第一个字符A的概率区间是 [0,0.2),则 L = 0,H = 0.2,更新:
-
第二个字符R的概率区间是 [0.6,1),则 L = 0.6,H = 1,更新:
-
第三个字符B的概率区间是 [0.2,0.4),则 L = 0.2,H = 0.4,更新:
我们可以看到一个不断变化的小数编码区间。每次编码一个字符,就在现有的编码区间上,按照概率比例取出这个字符对应的子区间。例如一开始A落在0到0.2上,因此编码区间缩小为 [0,0.2),第二个字符是R,则在 [0,0.2)上按比例取出R对应的子区间 [0.12,0.2),以此类推。每次得到的新的区间都能精确无误地确定当前字符,并且保留了之前所有字符的信息,因为新的编码区间永远是在之前的子区间。最后我们会得到一个长长的小数,这个小数即神奇地包含了所有的原始数据,不得不说这真是一种非常巧妙的思想。
6.3 解码过程
如果理解了编码的原理,那么解码的方法显而易见,就是编码过程的逆推。从编码得到的小数开始,不断地寻找小数落在了哪个概率区间,就能将原来的字符一个个地找出来。例如得到的小数是0.14432,则第一个字符显然是A,因为它落在了 [0,0.2)上,接下来再看0.14432落在了 [0,0.2)区间的哪一个相对子区间,发现是 [0.6,1), 就能找到第二个字符是R,依此类推。在此不再赘述具体步骤。
6.4 算法实现
char inStr[100], chSet[20]; //输入字符串和字符集
float P[20]; //每个字符的概率
float pZone[20]; //概率区间
int strLen; //输入字符串长度
int chNum; //字符集中字符个数
int binary[100];
float infoLen; //信息量大小
void compress(); //编码函数
void uncompress(); //解码函数
int main()
{
int i,j;
printf("input the length of char set:
");
scanf("%d", &chNum);
getchar();
printf("input the char and its p
");
for (i=0; i < chNum; i++) {
printf("input char: ");
scanf("%c", &chSet[i]);
getchar();
//printf("sssss%c ", chSet[i]);
printf("
input its p: ");
scanf("%f",&P[i]);
getchar();
printf("
");
}
/* test
for (i = 0; i < chNum; ++i)
printf("%c<-------------->%f
", chSet[i], P[i]);
*/
// 计算概率区间
pZone[0] = 0;
for (i=1; i < chNum; ++i)
pZone[i] = pZone[i-1] + P[i-1];
printf("input the string
");
fgets(inStr, 100, stdin);
strLen = strlen(inStr);
/************* test ***************/
printf("the string is:
");
puts(inStr);
printf("*********** compress **************
");
compress();
printf("
*********** uncompress **************
");
uncompress();
return 0;
}
void compress()
{
float low = 0, high = 1;
float L, H, zlen = 1;
float cp; //输入字符的概率
float result; //结果
int i, j;
for (i=0; i < strLen; i++) {
for (j=0; j < chNum; j++) {
if (inStr[i] == chSet[j]) {
//cp = P[j];
//L = pZone[j];
low = low + zlen * pZone[j];
zlen *= P[j];
break;
}
}
//low = low + zlen * L;
//zlen *= cp;
}
result = low;
printf("the result is %f
", result);
infoLen = log(1/zlen) / log(2); //计算香农信息量
if(infoLen > (int)infoLen)
infoLen = (int)infoLen + 1;
else
infoLen = (int)infoLen;
for (i=0; i < infoLen; i++) {
result *= 2;
if (result > 1) {
result = result - 1;
binary[i] = 1;
} else if (result < 1) {
binary[i] = 0;
} else {
break;
}
}
if (i >= infoLen) {
for (j=i; j >= 1; j--) {
binary[j-1] = (binary[j-1]+1)%2;
if (binary[j-1] == 1)
break;
}
}
printf("****************** the compress result*****************
");
for (j=0; j < i; j++)
printf("%d ", binary[j]);
}
void uncompress()
{
int i,j;
float w = 0.5;
float deResult=0;
float newLow,newLen;
float low=0,zlen=1;
for (i=0; i < infoLen; i++) {
deResult += w*binary[i];
w *= 0.5;
}
printf("uncompress to ten:%f
", deResult);
printf("uncompress result:
");
for (i=0; i < strLen; i++) {
for (j=chNum; j > 0; j--) {
newLow = low;
newLen = zlen;
newLow += newLen * pZone[j-1];
newLen *= P[j-1];
if (deResult >= newLow) {
low=newLow;
zlen=newLen;
printf("%c ",chSet[j-1]);
break;
}
}
}
}
6.5 与哈夫曼编码的比较我们首先回顾一下哈夫曼编码,换一组数据并统计字符的出现次数,生成哈夫曼树,我们可以得到以下字符编码集:| 字符 | 次数 | 编码 |
| a | 3 | 0 |
| b | 3 | 1 |
| c | 2 | 10 |
| d | 1 | 110 |
| e | 2 | 111 |
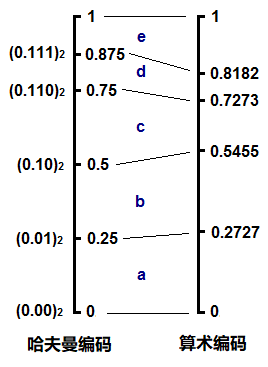
如果点上小数点,把它也看成一个小数,其实和算数编码的形式很类似,不断地读入字符,找到它应该落在当前区间的哪一个子区间,整个编码过程形成一个不断收拢变小的区间。
由此我们可以看到这两种编码,或者说熵编码的本质。概率越小的字符,用更多的bit去表示,这反映到概率区间上就是,概率小的字符所对应的区间也小,因此这个区间的上下边际值的差值越小,为了唯一确定当前这个区间,则需要更多的数字去表示它。我们仍以十进制来说明,例如大区间0.2到0.3,我们需要0.2来确定,一位足以表示;但如果是小的区间0.11112到0.11113,则需要0.11112才能确定这个区间,编码时就需要5位才能将这个字符确定。其实编码一个字符需要的bit数就等于 -log ( p ),这里是十进制,所以log应以10为底,在二进制下以2为底,也就是香农公式里的形式。
哈夫曼编码的不同之处就在于,它所划分出来的子区间并不是严格按照概率的大小等比例划分的。例如上面的d和e,概率其实是不同的,但却得到了相同的子区间大小0.125;再例如c,和d,e构成的子树,c应该比d,e的区间之和要小,但实际上它们是一样的都是0.25。我们可以将哈夫曼编码和算术编码在这个例子里的概率区间做个对比:
7. 数据压缩的定义、背景与分类
首先我们要知道什么是数据压缩。数据压缩是指在不丢失有用信息的前提下,缩减数据量以减少储存空间,提高其传输、储存和处理效率,或按照一定的算法对数据重新组织,减少数据的冗余和存储空间的一种技术方法。
那么为什么会出现数据压缩这门技术呢?一门技术的快速发展必然有其背景,有其诞生的必要性。
数据压缩背景摘要:在信息储存和数据传输日益增长的今天,数据压缩变得越来越重要,数据压缩是一种用来减小数据大小的技术。当一些巨大的文件必须通过网络传输存储在数据存储设备上,且其大小超过数据存储的容量或将消耗大量的网络传输带宽时,这是非常有用的。随互联网和资源有限的移动设备的出现,数据压缩变得更加重要。它可以有效地用于节省储存空间和带宽,从而减少了下载时间.
数据压缩算法发展至今,已经有了相当多的算法,按数据质量可分为有损压缩和无损压缩两大类。无损算法可以从压缩的信息中精确地重构原始消息,有损算法只能近似地重构原始消息。
8. 游程编码(RLE)
设想一下,一旦一个像素呈现出一种特定的颜色(黑色或白色),下面的像素极有可能也是相同的颜色。因此,与其单独编码每个像素的颜色,我们可以简单地编码每个颜色的运行长度。RLE是一种非常简单的数据压缩形式,其中数据序列(称为游程,重复的字符串)存储在两个部分:单个数值和计数。这对于包含许多这样的运行的数据是最有用的,例如,简单的图形图像,如图标、线条图和动画。但它对于运行次数不多的文件是没有用的,因为它可能会大大增加文件的大小。
例如:纯白色背景上的纯黑色文本,b 代表一个黑色像素,w 代表一个白色像素:wwwwwbwwwwwbbbwwwwwbwwwww 用RLE表示为:5w1b5w3b5w1b5w
由于游程编码执行无损数据压缩,它非常适合基于调色板的图像,如纹理。但通常不应用于现实的图像,如照片。另外,游程编码用于传真机非常高效,因为大多数传真文件都有很多空白,偶尔会有黑色的干扰。
9. Lempel-Ziv算法
lempel-Ziv 算法是一种基于字典的编码算法,而以往的算法往往基于概率编码,它是文件无损压缩的首选方法。这主要是由于它对不同文件格式的适应性但是对于小文件,字典的长度可能会超过原始文件的长度,但是对于大文件,这种方法是非常有效的。
Ziv 和 Lempel 在1977年和1978年的两篇独立论文中描述了该算法的两个主要变体,通常被称为 LZ77和 LZ78。
LZ77 算法基于滑动窗口的思想,该算法只在距离当前位置固定距离内的窗口查找匹配项。而 LZ78 算法基于一种更保守的方法向字典中添加字符串。
lempel-ziv-welch(LZW) 是目前使用最多的 Lempel-Ziv 算法。它是在 LZ77 和 LZ78 压缩算法的基础上改进的。编码器建立一个自适应字典来表示变长字符串,不需要任何先验概率信息。解码器根据接收到的代码动态地在编码器中构建相同的字典。
现在 LZW 应用于 GIF 图像,UNIX 压缩等。
基本步骤:
-
初始化字典。
-
将输入数据的符号按顺序组合到缓冲区中,直到在字典中找到最长的字符串
-
在缓冲区中发送表示的代码。
-
将缓冲区中的字符串与下一个空代码中的下一个符号结合保存到字典中。
-
清空缓冲区,然后重复步骤 2~5,直到全部数据结束。
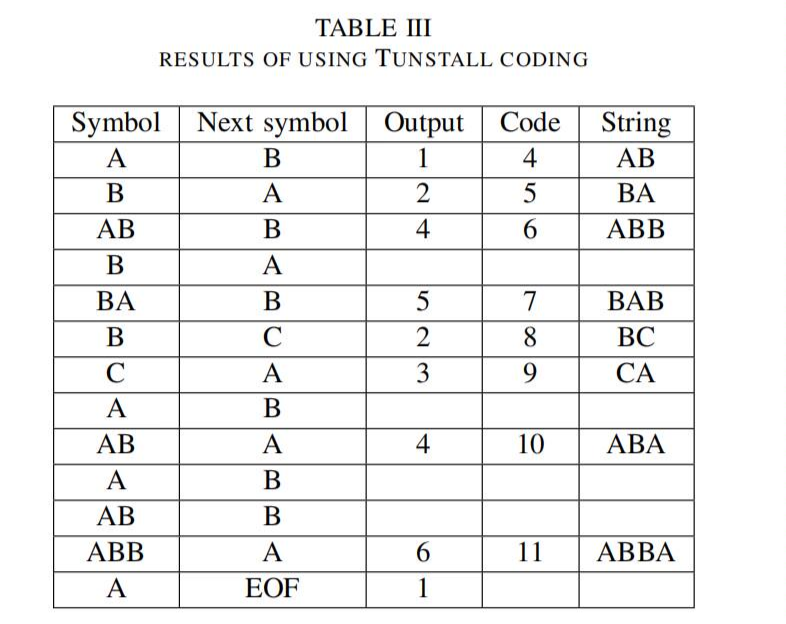
表3是一个LZW的例子,输入字符串为ABABBABCABABBA,初始码为1、2、3,分别表示A、B、C。
编码后的字符串为“124523461”。14个字符压缩为9个字符。因此压缩比为14/9=1.56。
9.1 LZ编码的应用
在LZ的变体中,最流行的是LZW算法然而,LZW最初是实用最多的算法,专利问题导致越来越多的使用LZ算法。LZ算法最受欢迎的实现是Phil Katz最初设计的deflate算法。Deflate是一种无损数据压缩算法,使用了LZ算法和哈夫曼算法的组合,下面列举LZ算法的主要应用:
9.1.1 文件压缩 UNIX 压缩
UNIX compress 命令是LZW最早的应用之一。字典的大小是自适应的。当字典被填满时,大小逐渐增加一倍。代码字的最大大小bmax可以由用户设置为9到16之间,16位是默认值。而一旦字典包含2bmax条目,压缩就会成为一种静态字典编码技术,此时算法监视压缩比。如果压缩比低于阈值,则将刷新字典,并重新启动字典构建过程。这样一来,字典总是能反映源的地方特征。
9.1.2 图像压缩 gif 格式
图形交换格式(GIF)是 Compuserve 信息服务公司开发的图形图像编码格式。它是 LZW 算法的另一种实现,与 Unix 中的 compress 命令非常相似,正如我们在前面的应用程序中提到的那样。
9.1.3 图像压缩 png 格式
PNG 标准是互联网上最早开发的标准之一。1994 年12 月,Unisys 公司(该公司从 Sperry 那里获得了 LZW的专利)和 CompuServe 公司宣布,他们将开始向支持GIF 的软件的作者收取版税。该公告导致了数据压缩领域的一场革命,行成了Usenet组comp.compression的核心。社区决定开发一种无专利的 GIF 替代品,三个月内 PNG 诞生了。Modem sV.42 上的压缩ITU-T 建议 V.42 之二是为通过电话网络使用而制定的压缩标准,并附有 C CITT 建议 V.42 中所述的纠错程序。该算法用于连接计算机和远程用户的调制解调器。该算法有两种运行模式和压缩模式。在透明模式下,数据以不压缩的形式传输,在压缩模式下,数据使用LZW算法进行压缩。
10. 多媒体压缩JPEG和MPEG
10.1 背景
媒体图像已经成为日常生活中一个至关重要且无处不在的组成部分。图像中编码的信息量是相当大的。即使有了带宽和储存能力的进步,如果图像不被压缩,许多应用程序的成本将会太高。
10.2 图像压缩:JPEG压缩算法
JPEG用于静态图像,图像压缩是减少表示数字图像所需的数据量的过程,这是通过删除所有冗余或不必要的信息来实现的。一个未压缩的图像需要大量的数据来表示。
编码算法:
1、颜色空间转换
如果颜色分量是独立的(不相关的),则可以获得最好的 压缩结果,例如在YCbCr中,大部分信息集中在亮度上,而色度上的信息较少。RGB颜色分量可以通过线性变换转换为YCbCr分量,如下式:

2、色度下降采样
使用YCbCr颜色空间,我们还可以通过压缩Cb和Cr分量的分辨率来节省空间。它们是色度分量,我们可以减少它们以使用图像压缩。由于亮度对眼睛的重要性,我们不需要色度像亮度一样频繁,所以我们可以对其进行下降采样。因此可以除去部分Cb和Cr的元素。因此,例如将RGB44格式转换为YCbCr42的格式,这样就可以获得一个1:5的数据压缩比,不过此步骤是一个可选的过程。
3、离散余弦变换(DCT)
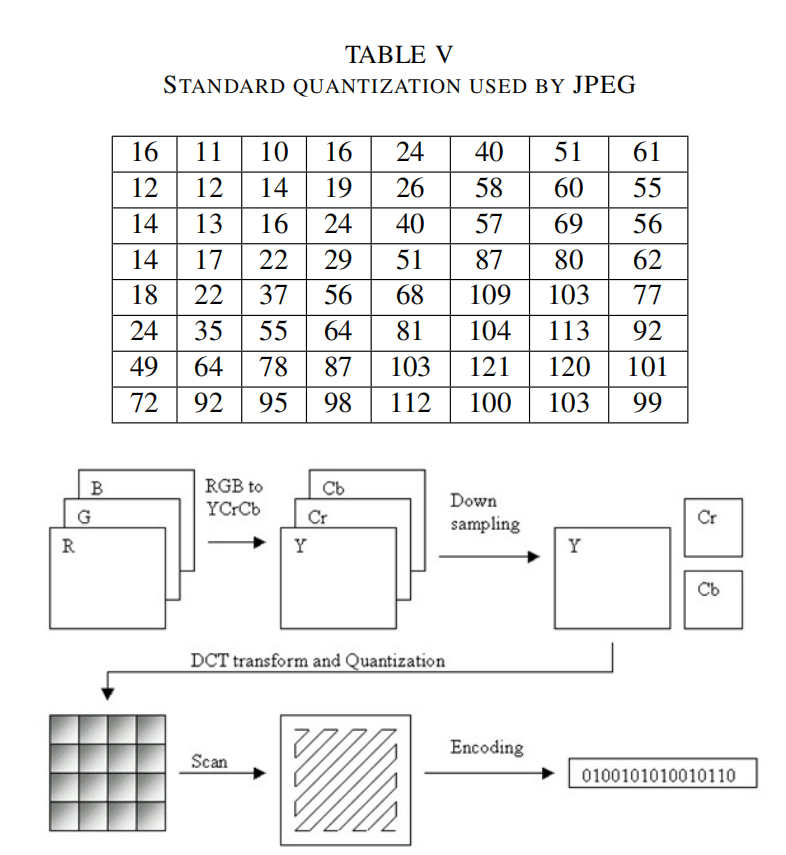
在这一步,每88块的分量(Y,Cb,Cr)被转换成频域表示。DCT方程是一个相当复杂的方程,有两个余弦系数。细节参考JPEG标准。
4、量化
对人眼来说,亮度比色度更重要。对眼睛来说,在大范围内看到亮度的微小差异比高频亮度变化的确切强度更容易分辨。利用这一特性,我们可以大大减少高频成分中的信息。JPEG编码通过简单地将频率域中的每个分量除以该分量中的一个常数,然后四舍五入到最近的整数来实现这一点。因此,许多高频分量被四舍五入到零,其余大部分分量变成了小的正数或负数,占用更少的比特来储存。
5、熵编码
熵编码是一种无损数据压缩的方法。在这里,我们将图像组件排序为锯齿形,然后使用游程编码(RLE)算法,将相似的频率连接在一起,以压缩序列。
6、哈夫曼算法
应用前面的步骤,我们得到的数据就是DCT系数序列。这一步即是最后一步,我们用哈夫曼编码或者算数压缩算法来压缩这些系数。该方案主要采用Huffman压缩,将其视为第二次无损压缩。
10.3 视频压缩:MPEG压缩算法
MPEG压缩算法的基本思想是将离散样本流转换为符号的比特流。以减少占用空间,理论上,视频流是一组离散图像。MPEG使用这种连续帧之间的特殊或时间关系来压缩视频流。在一段数据中,利用这些关系的技术越有效,对数据的压缩就越有效。
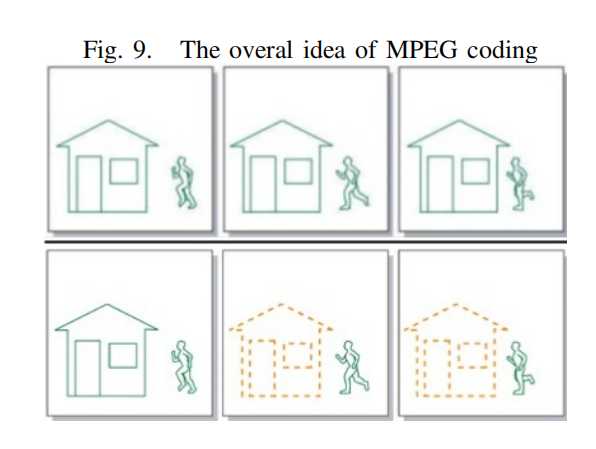
在MPEG编码算法中,我们只对视频序列中的新部分和视频中运动部分的信息进行编码。例如,考虑图9,上面的三张图。对于压缩我们只需考虑新的部分,如图9,我们只需要考虑底部的三个序列。视频压缩的基本原理是图像对图像的预测。一组图像中的第一个图像是i帧。这些帧显示开始一个心得场景,因此不需要被压缩,因为他们没有依赖于该图像之外。但其他帧可以使用第一张图片的一部分作为参考。从一个参考图像预测的图像称为p帧,从两个其他参考图像双向预测的图像称为B帧。因此,总的来说,我们将有以下帧MPEG编码:
-
I-frames:独立的;不需要参考帧预测
-
P帧:从最后一个I或P参考帧预测
-
B-frames:双向:从两个参考帧预测,一个在过去,一个在未来,将考虑最佳匹配。
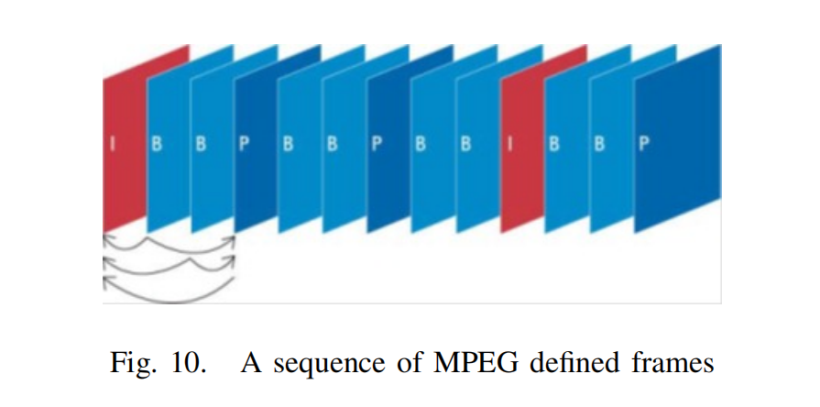
MPEG应用程序:MPEG在现实世界中有很多的应用。我们在此列举其中一些:
1、有限电视。一些电视系统通过有线电视线路发送MPEG-II节目
2、直接广播卫星。MPEG视频流被跌形/解码器接收,它提取的数据为标准NTSC电视信号。
3、媒体的金库。Silicon Graphics、Storage Tech和其他供应商正在生产按需视频系统,在一个安装上有两万个文件MPEG编码的电影。
4、实时编码,这仍是专业人士的专属领域。结合特殊用途的并行硬件,实时编码器的成本可达2万至5万美元。
11. 今天的数据压缩:应用程序和问题
11.1 网络
今天随着用户数量的增加和远程办公,以及使用云计算的应用程序部署模型的出现,更多正在传输的数据对网络连接的压力导致了额外的问题。
数据压缩重要的作用之一是将其应用于计算机网络。然而,在带宽有限的网络环境下,实现高的压缩比是提高应用程序性能的必要条件,如果压缩比过低,网络将保持饱和,性能增益将非常小。同样,如果压缩速度过低,压缩机也会成为瓶颈。许多网络数据的传输优化解决方案都只关注网络层的优化。这些解决方案不仅缺乏灵活性,而且没有包含能够进一步增强通过网络链接传输数据的应用程序性能的优化。
11.2 基于报文或会话的压缩
许多网络压缩系统是基于数据包的。基于数据包的压缩系统使用解压器缓冲发送到远程网络的数据包。然后,这些数据包在单个时间内或作为一个组被压缩,然后发送到解压器,在那里这个过程被逆转。
当压缩数据包时,这些系统必须在将小数据包写入网络和执行额外的工作来聚合和封装多个数据包写入网络和执行额外的工作来聚合和封装多个数据包之间做出选择,这两种选择都不会产生最佳效果。向网络写入小数据包会增加TCP/IP报头的开销,而聚合和封装数据包会增加流的封装报头。
11.3 字典压缩大小
几乎所有压缩实用程序的一个共同限制是有限的储存空间。
与对网络的请求相似,并不是所有在网络上传输的字节都以相同的频率重复。一些字节模式出现的频率很高,因为他们是流行文档或公共网络协议的一部分。其他字节模式只出现一次,并且永远不重复。经常重复的字节序列和不经常重复的字节序列之间的关系可以在Zipfs定律中看到。
11.4 基于块或基于字节的压缩
基于块的压缩系统储存先前在网络上传输的数据片段。当第二次遇到这些块时,对这些网块的引用被传输到远程设备,然后远程设备重新构建原始数据。
基于块的系统的一个关键缺点是,重复的数据几乎从不与块的长度完全相同。因此,匹配通常只是部分匹配,不压缩一些重复的数据。如图12说明了使用256字节块的系统试图压缩512自治街的数据时会发生什么。

11.5 能源效率
能源效率领域,尤其是无线传感器网络是当今世界最热门的网络研究领域之一。无线传感器网络由分布在空间上的传感器组成,用于检测物理或环境条件,如温度、声音、振动、压力、运动或污染物,并协同将他们的数据通过网络传递到主要位置。而传感器的大小和成本限制导致了资源的限制,如能源、内存、计算速度和通信带宽。巨大共享传感器之间的数据需要能量高效、低延迟和高精度。
目前,如果传感器系统设计者想要压缩获得的数据,他们必须卡法特定于应用程序的压缩算法,或者使用非为资源所限的传感器节点设计的现成算法。
主要的尝试是实现一种专门为传感器网络设计的传感器Lempel-Ziv(S-LZW)压缩算法。针对无线传感网络中设计高效数据压缩算法的趋势,Vidhyapriyal和P.Vanathi设计并实现了两种集成了最短路径路由技术的无损数据压缩算法,以减少原始数据的大小,并在传感器网络中实现速率、能量和精度之间的最佳权衡。
12. 总结
在数据存储和信息传输量不断增长的今天,数据压缩技术发挥着重要作用。即使在带宽和存储能力方面有了进步,如果数据没有被压缩,许多应用程序的成本将太高,用户无法使用他们。本文我们尝试介绍了无损压缩和有损压缩两种压缩类型,以及数据压缩中的一些主要概念、算法和方法,并讨论了他们的不同应用和工作方式,然后我们探讨了两个主要的日常应用;以JPEG为例进行图像压缩,以MPEG为例进行了视频压缩。最后我们讨论了当今数据压缩的主要应用和存在的问题。
< 本文完>
ELT.ZIP是谁?
ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。
成员:
上海工程技术大学大二在校生 闫旭
合肥师范学院大二在校生 楚一凡
清华大学大二在校生 赵宏博
成都信息工程大学大一在校生 高云帆
黑龙江大学大一在校生 高鸿萱
山东大学大三在校生 张智腾

ELT.ZIP是来自6个地方的同学,在OpenHarmony成长计划啃论文俱乐部里,与来自华为、软通动力、润和软件、拓维信息、深开鸿等公司的高手一起,学习、研究、切磋操作系统技术...
写在最后
OpenHarmony 成长计划—“啃论文俱乐部”(以下简称“啃论文俱乐部”)是在 2022年 1 月 11 日的一次日常活动中诞生的。截至 3 月 31 日,啃论文俱乐部已有 87 名师生和企业导师参与,目前共有十二个技术方向并行探索,每个方向都有专业的技术老师带领同学们通过啃综述论文制定技术地图,按“降龙十八掌”的学习方法编排技术开发内容,并通过专业推广培养高校开发者成为软件技术学术级人才。
啃论文俱乐部的宗旨是希望同学们在开源活动中得到软件技术能力提升、得到技术写作能力提升、得到讲解技术能力提升。大学一年级新生〇门槛参与,已有俱乐部来自多所高校的大一同学写出高居榜首的技术文章。
如今,搜索“啃论文”,人们不禁想到、而且看到的都是我们——OpenHarmony 成长计划—“啃论文俱乐部”的产出。
OpenHarmony开源与开发者成长计划—“啃论文俱乐部”学习资料合集
1)入门资料:啃论文可以有怎样的体验
https://docs.qq.com/slide/DY0RXWElBTVlHaXhi?u=4e311e072cbf4f93968e09c44294987d
2)操作办法:怎么从啃论文到开源提交以及深度技术文章输出 https://docs.qq.com/slide/DY05kbGtsYVFmcUhU
3)企业/学校/老师/学生为什么要参与 & 啃论文俱乐部的运营办法https://docs.qq.com/slide/DY2JkS2ZEb2FWckhq
4)往期啃论文俱乐部同学分享会精彩回顾:
同学分享会No1.成长计划啃论文分享会纪要(2022/02/18) https://docs.qq.com/doc/DY2RZZmVNU2hTQlFY
同学分享会No.2 成长计划啃论文分享会纪要(2022/03/11) https://docs.qq.com/doc/DUkJ5c2NRd2FRZkhF
同学们分享会No.3 成长计划啃论文分享会纪要(2022/03/25)
https://docs.qq.com/doc/DUm5pUEF3ck1VcG92?u=4e311e072cbf4f93968e09c44294987d
现在,你是不是也热血沸腾,摩拳擦掌地准备加入这个俱乐部呢?当然欢迎啦!啃论文俱乐部向任何对开源技术感兴趣的大学生开发者敞开大门。

扫码添加 OpenHarmony 高校小助手,加入“啃论文俱乐部”微信群
后续,我们会在服务中心公众号陆续分享一些 OpenHarmony 开源与开发者成长计划—“啃论文俱乐部”学习心得体会和总结资料。记得呼朋引伴来看哦。
原文标题:统计压缩编码机理分析(下篇)
文章出处:【微信公众号:开源技术服务中心】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 开源技术
- OpenHarmony
-
视音频压缩编码技术的发展2009-07-29 621
-
图像压缩编码原理2009-09-19 1608
-
基于分形和小波的混合图像压缩编码2009-10-26 514
-
数字压缩编码技术2010-01-27 930
-
matlab压缩编码效率很高的静止图像压缩编码算法SPIHT2010-02-08 724
-
IP网络电话中常用的语音压缩编码技术的性能分析2010-07-22 806
-
AMBE-2000TM语音压缩编码电路分析2010-07-06 3142
-
图像压缩编码和解码原理2010-09-27 4842
-
MPEG-2压缩编码器原理2011-03-15 5537
-
图像压缩编码和解码原理知识介绍2012-08-21 4133
-
JPEG压缩编码标准2016-02-18 986
-
使用FPGA实现MELP语音压缩编码器的详细资料说明2021-01-22 1449
-
基于DCT快速变换的图像压缩编码算法_张爱华2021-07-26 1153
-
DCT的图像压缩编码算法的MATLAB实现2021-09-23 1140
-
统计压缩编码机理分析(上篇)2022-12-21 2408
全部0条评论

快来发表一下你的评论吧 !
