

应用于地物识别的改进轮转森林算法-莱森光学
电子说
描述
引言
面对现今用来进行地物识别的遥感数据的数量以及种类越来越多,需要进行处理实际问题也越来越复杂的情况,单纯地对一种算法进行改进已经不能满足解决问题的需要,然而集成学习方法可以较好地解决该问题。集成学习方法按照分类器之间的种类关系可以分为异态集成学习和同态集成学习两种。异态集成学习指的是使用各种不同的分类器进行集成,它的优势在于异态集成学习中的某种基本算法会对某类特定数据样本比其他的基本算法更为有效,得到的效果也会更好;同态集成学习是指集成的基分类器都是同一类分类器,只是基分类器之间的参数有所不同,它针对各种不同的数据类型用抽样与集成进行结合,对原始训练集进行一系列抽样,产生多个分类器,然后用投票或合并的方式输出最终结果。
决策树的研究为这两种集成方式提供了研究平台,利用决策树来进行特征提取也是其中的一个研究方向,然而有学者提出决策树在构建过程中进行特征选择有不足之处:决策树中出现的特征是有等级的,浅节点的特征明显要比深节点处的特征更为重要,如果直接综合每个节点的特征来进行特征选择,就完全忽略了这种等级特性,有可能使特征子集的潜在作用得不到发挥。因此如何正确地使用决策树来进行特征选择也是一个研究热点,这也是轮转森林(Rot-F)提出的出发点。轮转森林对特征进行深层划分,将原特征集随机分为多个小的特征子集,利用PCA(主成分分析)变换得到的系数对原数据集进行改变,以此来建立树的过程要明显优于普通决策树在分叉过程中对原始数据的分类性能。然而决策树对遥感数据的分类往往会出现过分类的现象,所以考虑将具有自学习和自组织能力的径向基函数神经网络(RBFN)与之进行结合,用轮转森林转换各子集后的数据样本作为神经网络的输人,对应转换后的样本类标作为网络的输出,以此来构造多个子分类器集。通过将原数据集进行分化的方法,构造多个内部参数差异较大的同态集成基分类器,提升总体的分类精度,集成两种方法的优势达到对遥感地物的识别更加精确。
Rot-F和RBFNN的集成算法
异不显著 (表 2)。对树体水势的研究结果表明,3个地块中只有8号地内不同生长势植株间有显著的差异:生长势强的树中庸树其树体水势显著高于弱树; 其他两块地树势间无显著差异。轮转径向基函数神经网络首先是利用轮转森林对特征集的转换,得到多个新的特征子集,并将改变后的数据用于RBFN的分类过程。对原始数据集的处理过程如下:将原始数据按照特征集随机分为多个小的特征子集数据块,之后在每个特征子集的数据块中依据数据实例进行重采样,将重采样后的数据小块进行主成分分析,使得到的各特征值的重要性程度系数与原数据集进行相应的乘积变动。因采样过程得到的数据块要小于原始数据块,所以得到特征集的大小也就不同,以新特征集作为各个RBFN基分类器的输人来训练模型和预测数据。
为了利用训练样本集来构建这些子分类器,需要进行以下几个步骤:
1)随机的将F分为K个子集,这些子集可能是相对独立的,也有可能是相互交叉重复的。为了最大可能地增加多样性,选用相对独立的特征子集。同时为简化计算,假定K是一个可调的变量,那么对于每个特征子集所包含的特征个数为M=n/K。
2)定义Fi,j为Di个子分类器用来进行训练的第j个特征子集。利用Botstrap进行随机抽样选取一组数据样本,抽样的比例为该子集数据的75%。仅利用Fi,j中的M个特征进行PCA变换,将得到的主成分系数进行存储,每个系数的维数为M×1。对于上述的矩阵,得到的特征值有可能是0,所以可能得不到所有的M个向量,即Mj≤M。因此通过在这些子集中运用PCA技术而不是在所有的数据集中应用,其目的就是为了避免在不同的子分类器中对于相似特征子集产生类似的系数。
3)将所获得的带有主成分系数的向量进行综合,构造一个具有稀疏性的轮转矩阵Ai,
4)用来进行训练Di个子分类器的训练数据集为XAi*,将这样的训练集作为输人对RBFN进行训练来建立神经网络模型,训练部分分为两个阶段:
(1)训练输人层和隐含层之间的径向基函数,即确定基函数的中心和方差。隐含层的径向基函数有多种形式,最常用的是高斯函数。
(2)训练隐含层和输出层之间的线性权值。通过采样和样本聚类生成RBFN的中间节点参数,中间层状态确定法选用K-means聚类,该方法采用最小平方误差和作为分类准则,通过迭代获得聚类中心点集,即中间层的状态,节点个数等于聚类数。
3)该集成模型解决的是一个c类的模式分类问题,集成的规模为P(即有P个子分类器)通过期望的输人输出编码映射关系对P个成员网络进行训练。
数据的选取及实验结果分析
实验区采用扎龙湿地,它位于黑龙江省西部,乌裕河下游齐齐哈尔市及富裕、林甸、杜蒙、泰来县交界地域。扎龙湿地保护区是以芦苇沼泽为主的内陆湿地和水域生态系统。它是中国北部最完整、最原始和广阔的湿地生态系统,已被列人国际重要湿地名录。该地区地物类型主要包括盐碱地、草地(包括芦苇)、水体、沼泽(轻度和重度沼泽归为一类)这些具有比较代表性的类物。选用的遥感图像为2001-10-05获取的xandsatETMI图像,图像大小为500X500像素,待分类图像采用TM影像7个波段中的3、2、1共3个波段的真彩色合成图像,如图1所示。
图 1 研究区域影像
经目视判读,结合土地利用现状图,确定湿地影 像区域内主要包括六大类地物:盐碱地、草地、水域、 沼泽地、受火区域以及农用地(包括农用耕地和农用居住地)。
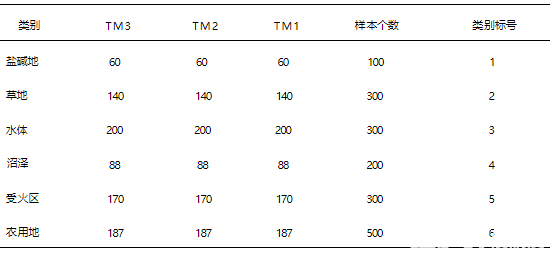
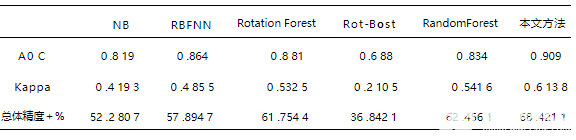
xandsatTM+ETMI影像的3、2、1波段组合能较好地反映土地植被特征。根据目视判读结果,并且结合土地利用现状图和2003年5月/11月的实地调查资料,在真彩色合成影像上共选取1700个样本点,其中1020个像素点作为轮转神经网络的训练样本,340个像素点作为校验样本,剩余的340个用来测试分类精度.为进一步减小输人数据的不同所造成不同算法之间的差异性,将所有的原始输人数据都归一化到[-1,1]之间,具体结果如下表1所示 。分别应用朴素贝叶斯(NB)方法、传统径向基函数神经网络方法(RBFN)、普通轮转森林方法(RotationForest)方法、文献中的方法(Rot-Bost)、随机森林方法(RandomForest)以及本文方法(Rot-RBFN)对所选的区域ETMI遥感影像进行分类,分类结果如图2。对应每个类标的分类 结果量化后如表2所示.由表2和图2的6幅分类效果图可以看出随机森林算法对水体的分类精度要高,但是对于训练样本较少的盐碱地和草地以及农用地等分类,精度要低于本文方法,本文方法的精度分别达到了0.917,0.6,0.795。而且从图中可以看出采用决策树作为基分类器的分类方法中出现了过分类现象,所以有较多的斑点出现,文献中的方法虽然在农用地的精度上要略高一些,但是对于 其他几类地物出现了明显分辨不出的情况。此外,从图2可以看出,本文方法虽没有NB方法看起来清晰、明亮,但从精度上却明显优于NB算法。
表 1 波段值和总体样本数目
将上述结果采用R-C曲线下面积(A0C)的大小以及用误差矩阵的主要参考指标总体精度和Kappa系数来进行评估。其中Kappa系数是综合整个误差矩阵的信息提出的一个精度表达系数,可以比较不同分类器的误差矩阵在精度上的差异,得到 的结果如表4所示。从表3结果可以看出,本文方法在A0C、Kappa系数和总体精度上都比其他几种算法高,分别达到了0.909,0.6138和68.4211,相比于其他5种常用的算法,本文方法效果更好。A0C值越大说明该分类器的分类结果越靠近于R-C坐标的纵轴,对应分类器的分类效果和泛化性能也就越好;Kappa系数越高则说明对应该算法的过度拟合情况越小,也就从侧面说明该分类器所建模型的泛化能力越强。而总体精度则从准确率方面说明所提方法的有效性更强。从上述3个方面来说,本文方法更能给出较高的分类精度和较好的泛化性能。从算法耗时来讲,本文方法耗时稍微较长一些,达到24.21s。而其他几种算法的耗时基本在10s左右。
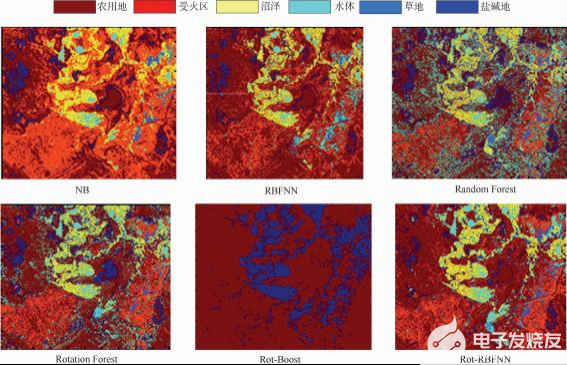
图 2 不同分类器的分类结果
总结
应用遥感技术测定NDVI能快速评价葡萄生长势的差异,为确定与之相适应的栽培管理技术决策提供依据,其结果数据可以更好地与越来越广泛的机械化操作相适应,从而提高酿酒葡萄原料质量均一性,保证获得高品质的葡萄酒。这一技术在未来葡萄生产中使用具有广阔的前景。
表 2 不同校验样本的生产者精度对比表
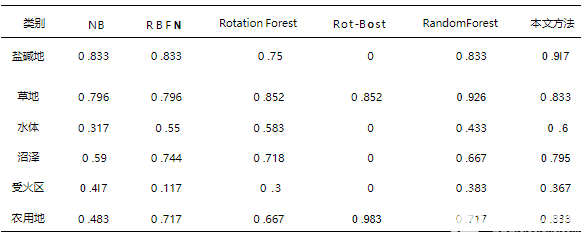
表 3 不同算法下评价指标结果比较
欢迎关注公众号:莱森光学,了解更多光谱知识。
莱森光学(深圳)有限公司是一家提供光机电一体化集成解决方案的高科技公司,我们专注于光谱传感和光电应用系统的研发、生产和销售。
审核编辑 黄昊宇
- 相关推荐
- 热点推荐
- 高光谱
-
基于Apriltags识别的改进算法2017-11-05 1659
-
地物光谱仪的主要特征体现在哪些方面?2022-09-08 1407
-
地物光谱仪应该如何正确操作?-莱森光学2022-11-04 2572
-
地物光谱仪的应用-莱森光学2022-11-09 1498
-
便携式地物光谱仪都应用于哪些方面?-莱森光学2022-11-11 1445
-
应用地物光谱仪有哪些优势?-莱森光学2022-12-01 1204
-
地物光谱仪的组成及应用领域-莱森光学2022-12-14 2027
-
什么是地物光谱仪?-莱森光学2023-01-05 1530
-
深圳大学洋涌河水体光谱数据采集服务圆满完成-莱森光学2023-01-09 1349
-
详解地物光谱仪的应用-莱森光学2023-04-27 2665
-
地物光谱仪的原理是什么?-莱森光学2023-05-04 4534
-
地物光谱仪在森林火灾监测中的应用2023-07-24 1351
-
人脸识别的算法有哪些2023-08-09 9628
-
莱森光学CIOE2023中国光博会圆满成功!2023-09-11 2023
-
地物光谱仪在森林树冠研究中的具体应用2024-11-08 921
全部0条评论

快来发表一下你的评论吧 !
