在Vivado中进行HDL代码设计,不仅需要描述数字逻辑电路中的常用功能,还要考虑如何发挥Xilinx器件的架构优势。目前常用的HDL语言有三种。
(1)VHDL语言的优势有:
语法规则更加严格;
在HDL源代码中初始化RAM组件更容易;
支持package;
自定义类型;
枚举类型;
没有reg和wire之间的混淆。
(2)Verilog语言的优势有:
与C语言类似的语法;
代码结构更紧凑;
支持块注释(老版VHDL不支持);
没有像VHDL一样的重组件实例化。
(3)SystemVerilog语言的优势有:
以博主接触的情况看,目前使用最广泛的应该是Verilog语言,替代VHDL成为国内大学教学的主流。SystemVerilog其实有更高级别的描述能力,无论是设计还是仿真性能也更强大,目前很多国外大学都使用SystemVerilog作为教学语言。本文以Verilog语言为基础讲述HDL代码编写技巧。
1.触发器、寄存器和锁存器
Vivado综合可以识别出带有如下控制信号的触发器(Flip-Flop)和寄存器(register):上升沿或下降沿时钟、异步置位或复位信号、同步置位或复位信号、时钟使能信号。Verilog中对应着always块,其敏感列表中应该包含时钟信号和所有异步控制信号。
使用HDL代码设计触发器、寄存器时注意如下基本规则:
寄存器不要异步置位/复位,否则在FPGA内找不到对应的资源来实现此功能,会被优化为其它方式实现。
触发器不要同时置位和复位。Xilinx的触发器原语不会同时带有置位和复位信号,这样做会对面积和性能产生不利影响。
尽量避免使用置位/复位逻辑。可以采用其它方法以更少的代价达到同样 的效果,比如利用电路全局复位来定义初始化内容。
触发器控制信号的输入应总是高电平有效。如果设置为低电平有效,会插入一个反相器,对电路性能会产生不利影响。
Vivado综合工具根据HDL代码会选择4种寄存器原语:
寄存器的内容会在电路上电时初始化,因此在申明信号时最好设定一个默认值。综合后,报告中可以看到寄存器的使用情况。下面给出一个寄存器的代码实例:
//上升沿时钟、高电平有效同步清0、高电平有效时钟使能8Bits寄存器
module registers_1(
input [7:0] d_in,
input ce, clk, clr,
output [7:0] dout
);
reg [7:0] d_reg;
always @ (posedge clk)
if(clr) d_reg <= 8'b0;
else if(ce) d_reg <= d_in;
assign dout = d_reg;
endmodule
Vivado综合还会报告检测出的锁存器(Latches),通常这些锁存器是由HDL代码设计错误引起的,比如if或case状态不完整。综合会为检测出的锁存器报告一个WARNING(Synth 8-327)。下面给出一个锁存器的代码示例:
//带有Postive Gate和异步复位的锁存器
module latches (
input G,
input D,
input CLR,
output reg Q
);
always @ *
if(CLR) Q = 0;
else if(G) Q = D;
endmodule
2.三态缓冲器
三态缓冲器(Three-state buffer),又称为三态门、三态驱动器,其三态输出受到使能输出端的控制,当使能输出有效时,器件实现正常逻辑状态输出(逻辑0、逻辑1),当使能输出无效时,输出处于高阻状态,即等效于与所连的电路断开。
三态缓冲器(Tristate buffer)通常由一个信号或一个if-else结构来建模,缓冲器可以用来驱动内部总线,也可以驱动外部板子上的总线。如果使用if-else结构,其中一个分支需要给信号赋值为高阻状态
当三态缓冲器通过管脚驱动外部总线时,使用OBUFT原语实现;当驱动内部总线时,使用BUFT原语,综合工具会将其转换为用LUT实现的逻辑电路。下面给出处理三态缓冲器的代码示例:
//使用always块描述三态
module tristates_1 (
input T, I,
output reg O
);
always @(T or I)
if (~T) O = I;
else O = 1'bZ;
endmodule
//使用并行赋值描述三态
module tristates_2 (
input T, I,
output O);
assign O = (~T) ? I: 1'bZ;
endmodule
3.移位寄存器
一个移位寄存器(Shift Register)就是一个触发器链,允许数据在一个固定的延迟段之间传递,也叫静态移位寄存器。其通常包括:时钟信号、可选的时钟使能信号、串行数据输入和输出。
Vivado综合可以用SRL类型的资源实现移位寄存器,如SRL16E、SRLC32E。根据移位寄存器的长度,综合时会选择采用一个SRL类型原语实现,或采用级联 的SRLC类型原语实现。下面给出移位寄存器的代码示例:
// 32Bits移位寄存器,上升沿时钟,高电平有效时钟使能信号
// 使用连接运算符{}实现
module shift_registers_0 (
input clk, clken, SI,
output SO
);
parameter WIDTH = 32;
reg [WIDTH-1:0] shreg;
always @(posedge clk)
if (clken) shreg = {shreg[WIDTH-2:0], SI};
assign SO = shreg[WIDTH-1];
endmodule
// 使用for循环实现
module shift_registers_0 (
input clk, clken, SI,
output SO
);
parameter WIDTH = 32;
reg [WIDTH-1:0] shreg;
integer i;
always @(posedge clk)
if (clken) begin
for (i = 0; i < WIDTH-1; i = i+1)
shreg[i+1] <= shreg[i];
shreg[0] <= SI;
end
assign SO = shreg[WIDTH-1];
endmodule
4.动态移位寄存器
动态移位寄存器(Dynamic Shift register)是指电路操作期间移位寄存器的长度可以改变。可以采用如下两种结构实现:
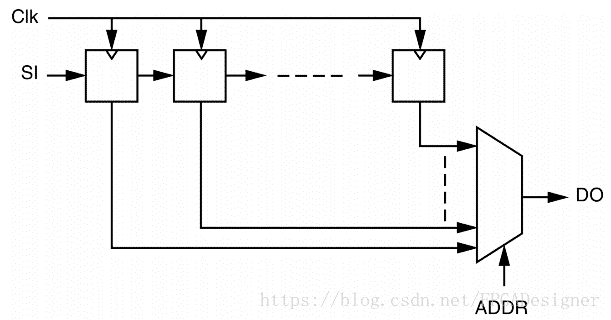
Verilog示例代码如下所示:
// 32-bit 动态移位寄存器
module dynamic_shift_register_1 (CLK, CE, SEL, SI, DO);
parameter SELWIDTH = 5;
input CLK, CE, SI;
input [SELWIDTH-1:0] SEL;
output DO;
localparam DATAWIDTH = 2**SELWIDTH;
reg [DATAWIDTH-1:0] data;
always @(posedge CLK)
if (CE == 1'b1) data <= {data[DATAWIDTH-2:0], SI};
assign DO = data[SEL];
endmodule
5.乘法器
综合工具从源代码中的乘法运算符来推测是否使用乘法器。乘法运算结果的位宽为两个操作数位宽之和。比如16Bits的信号乘以8Bits的信号,结果为24Bits。乘法器可以用Slice单元或DSP块实现,选择依据有两点:(1).操作数的大小;(2).是否需要最佳性能。通过第25篇介绍过的USE_DSP属性可以强制设定乘法器的实现方式,设置为no用slice实现;设置为yes用DSP块实现。
当使用DSP块实现乘法器时,Vivado综合可以发挥DSP块流水线能力的最大优势,综合时会在乘法操作数和乘法器后插入两级寄存器。当乘法器无法用一个DSP块实现时,综合时会拆分乘法运算,采用几个DSP块或DSP块加slice的方案实现。下面给出代码示例:
// 16*24-bit乘法器,操作数一级延迟,输出三级延迟
module mult_unsigned (
input clk,
input [15:0]A,
input [23:0]B,
output [39:0]RES
);
reg [15:0] rA;
reg [23:0] rB;
reg [39:0] M [3:0];
integer i;
always @(posedge clk)
begin
rA <= A;
rB <= B;
M[0] <= rA * rB;
for (i = 0; i < 3; i = i+1)
M[i+1] <= M[i];
end
assign RES = M[3];
endmodule
除了乘法器,综合工具还可以通过乘法器、加法器/减法器、寄存器的使用,推断出乘加结构(Multiply-Add)、乘减结构(Multiply-Sub)、乘加减结构(Multiply-Add/Sub)和乘累加结构(Multiply-Accumulate)。
5.复数乘法器
下面给出一个复数乘法器的代码示例,该设计会使用三个DSP48单元:
// 复数乘法器(pr+i.pi) = (ar+i.ai)*(br+i.bi)
module cmult # (parameter AWIDTH = 16, BWIDTH = 18)
(
input clk,
input signed [AWIDTH-1:0] ar, ai,
input signed [BWIDTH-1:0] br, bi,
output signed [AWIDTH+BWIDTH:0] pr, pi
);
reg signed [AWIDTH-1:0] ai_d, ai_dd, ai_ddd, ai_dddd ;
reg signed [AWIDTH-1:0] ar_d, ar_dd, ar_ddd, ar_dddd ;
reg signed [BWIDTH-1:0] bi_d, bi_dd, bi_ddd, br_d, br_dd, br_ddd ;
reg signed [AWIDTH:0] addcommon ;
reg signed [BWIDTH:0] addr, addi ;
reg signed [AWIDTH+BWIDTH:0] mult0, multr, multi, pr_int, pi_int ;
reg signed [AWIDTH+BWIDTH:0] common, commonr1, commonr2 ;
always @(posedge clk)
begin
ar_d <= ar;
ar_dd <= ar_d;
ai_d <= ai;
ai_dd <= ai_d;
br_d <= br;
br_dd <= br_d;
br_ddd <= br_dd;
bi_d <= bi;
bi_dd <= bi_d;
bi_ddd <= bi_dd;
end
final products
//
always @(posedge clk)
begin
addcommon <= ar_d - ai_d;
mult0 <= addcommon * bi_dd;
common <= mult0;
end
// Real product
//
always @(posedge clk)
begin
ar_ddd <= ar_dd;
ar_dddd <= ar_ddd;
addr <= br_ddd - bi_ddd;
multr <= addr * ar_dddd;
commonr1 <= common;
pr_int <= multr + commonr1;
end
// Imaginary product
//
always @(posedge clk)
begin
ai_ddd <= ai_dd;
ai_dddd <= ai_ddd;
addi <= br_ddd + bi_ddd;
multi <= addi * ai_dddd;
commonr2 <= common;
pi_int <= multi + commonr2;
end
assign pr = pr_int;
assign pi = pi_int;
endmodule
6.DSP块中的预加器
当使用DSP块时,设计代码最好使用带符号数(signed)运算,这样需要一个额外的bit位宽来存储预加器(pre-adder)结果,这一位也可以封装在DSP块中。一个动态配置预加器(后面带一个乘法器和加法器)的Veirlog示例如下:
// 控制信号动态选择预加或预减
module dynpreaddmultadd # (parameter SIZEIN = 16)
(
input clk, ce, rst, subadd,
input signed [SIZEIN-1:0] a, b, c, d,
output signed [2*SIZEIN:0] dynpreaddmultadd_out
);
reg signed [SIZEIN-1:0] a_reg, b_reg, c_reg;
reg signed [SIZEIN:0] add_reg;
reg signed [2*SIZEIN:0] d_reg, m_reg, p_reg;
always @(posedge clk)
if (rst) begin
a_reg <= 0; b_reg <= 0;
c_reg <= 0; d_reg <= 0;
add_reg <= 0;
m_reg <= 0; p_reg <= 0;
end
else if (ce) begin
a_reg <= a; b_reg <= b;
c_reg <= c; d_reg <= d;
if (subadd)
add_reg <= a - b;
else
add_reg <= a + b;
m_reg <= add_reg * c_reg;
p_reg <= m_reg + d_reg;
end
// 输出累加结果
assign dynpreaddmultadd_out = p_reg;
endmodule
7.UltraScale DSP块中的平方电路
UltraScale DSP块的原语DSP48E2支持计算输入或预加器输出的平方。下面的示例代码计算了差值的平方根,该设计会使用一个DSP块实现,且有最佳的时序性能:
// DSP48E2支持平方运算,预加器配置为减法器
module squarediffmult # (parameter SIZEIN = 16)
(
input clk, ce, rst,
input signed [SIZEIN-1:0] a, b,
output signed [2*SIZEIN+1:0] square_out
);
reg signed [SIZEIN-1:0] a_reg, b_reg;
reg signed [SIZEIN:0] diff_reg;
reg signed [2*SIZEIN+1:0] m_reg, p_reg;
always @(posedge clk)
if (rst) begin
a_reg <= 0;
b_reg <= 0;
diff_reg <= 0;
m_reg <= 0;
p_reg <= 0;
end
else if (ce) begin
a_reg <= a;
b_reg <= b;
diff_reg <= a_reg - b_reg;
m_reg <= diff_reg * diff_reg;
p_reg <= m_reg;
end
assign square_out = p_reg;
endmodule
8.黑盒子
FPGA设计可以包含EDIF网表,这些网表必须通过实例化与其它设计部分连接在一起。在HDL源代码中使用BLACK_BOX属性完成实例化,这部分实例化还可以使用一些特定的约束。使用BLACK_BOX属性后,该实例将被视作黑盒子。下面给出示例代码:
//模块定义
(* black_box *) module black_box1
(
input in1, in2,
output dout
);
endmodule
//模块实例化
module black_box_1
(
input DI_1, DI_2,
output DOUT
);
black_box1 U1 (
.in1(DI_1),
.in2(DI_2),
.dout(DOUT)
);
endmodule
9.FSM状态机
默认情况下,Vivado综合可以从RTL设计中提取出有限状态机(FSM),使用-fsm_extraction off可以关闭该功能。通常需要设计者设置FSM的编码方式,便于综合时根据设置调整优化目标。
Vivado综合支持Moore和Mealy型状态机。一个状态机由状态寄存器、下一个状态功能、输出功能三部分组成,可用如下框图表示:
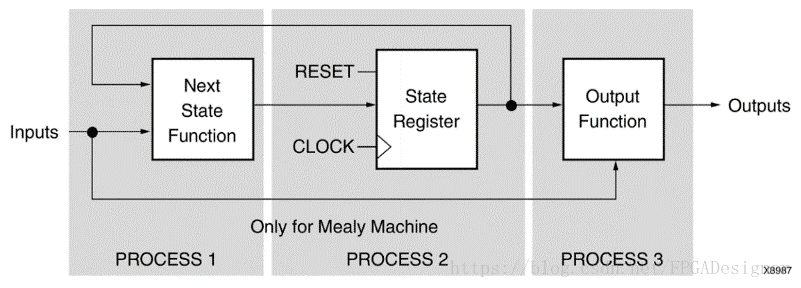
Mealy状态机需要从输出到输入的反馈路径。尽管状态寄存器也支持异步复位,但最好还是使用同步复位方式。设置一个复位或上电状态,综合工具即可识别出FSM。默认状态编码为auto,综合时会选择最佳的编码方式:
独热码(One-Hot):最多支持32个状态,有最快的速度和较低的功耗,每个状态由一个独立的bit(对应一个触发器)表示,状态间转换时只需要改变两个bit的状态。
格雷码(Gray):两个连续状态之间转换时只需要改变一个Bit的状态,可以最小化冒险和毛刺现象,有最低的功耗表现。
Johnson编码:适用于包含没有分支的长路径的状态机;
顺序编码:使用连续的基数值表示状态,跳转到下一个状态的状态方程最简单。
下面给出一个FSM的Verilog示例:
// 顺序编码的FSM
module fsm_1(
input clk, reset, flag,
output reg sm_out
);
parameter s1 = 3'b000;
parameter s2 = 3'b001;
parameter s3 = 3'b010;
parameter s4 = 3'b011;
parameter s5 = 3'b111;
reg [2:0] state; //状态寄存器
always@(posedge clk)
if(reset) begin
state <= s1;
sm_out <= 1'b1;
end
else begin
case(state)
s1: if(flag) begin
state <= s2;
sm_out <= 1'b1;
end
else begin
state <= s3;
sm_out <= 1'b0;
end
s2: begin state <= s4; sm_out <= 1'b0; end
s3: begin state <= s4; sm_out <= 1'b0; end
s4: begin state <= s5; sm_out <= 1'b1; end
s5: begin state <= s1; sm_out <= 1'b1; end
endcase
end
endmodule
10.ROM设计方法
Read-only memory(ROM)使用HDL模型实现与RAM非常相似。使用ROM_STYLE属性选择使用寄存器或块RAM资源来实现ROM。使用块RAM资源实现ROM的示例代码如下:
//使用块RAM资源实现ROM
module rams_sp_rom_1 (
input clk, en,
input [5:0] addr,
output [19:0] dout
);
(*rom_style = "block" *) reg [19:0] data;
always @(posedge clk)
if (en)
case(addr)
6'b000000: data <= 20'h0200A; 6'b100000: data <= 20'h02222;
6'b000001: data <= 20'h00300; 6'b100001: data <= 20'h04001;
6'b000010: data <= 20'h08101; 6'b100010: data <= 20'h00342;
......
6'b011110: data <= 20'h00301; 6'b111110: data <= 20'h08201;
6'b011111: data <= 20'h00102; 6'b111111: data <= 20'h0400D;
endcase
assign dout = data;
endmodule

至芯科技12年不忘初心、再度起航12月17日北京中心FPGA工程师就业班开课、线上线下多维教学、欢迎咨询!
欢迎加入至芯科技FPGA微信学习交流群,这里有一群优秀的FPGA工程师、学生、老师、这里FPGA技术交流学习氛围浓厚、相互分享、相互帮助、叫上小伙伴一起加入吧!