

浅谈GPU和CUDA技术
处理器/DSP
描述
图形处理单元(GPU)在类似的价格和功率范围内提供比CPU高的指令吞吐量和内存带宽。许多应用程序在GPU上比在CPU上运行得更快。其他计算设备,如FPGA,也非常节能,但提供的编程灵活性低于GPU。 GPU和CPU之间的功能差异之所以存在,是因为它们的设计目标不同。虽然CPU被设计为尽可能快地执行一系列操作(称为线程),并且可以并行执行几十个线程,但GPU被设计为擅长并行执行数千个线程(用较慢的单线程性能以实现更高的吞吐量)。 GPU专门用于高度并行计算,因此设计为更多晶体管用于数据处理,而不是数据缓存和流控制。如图显示了CPU与GPU的芯片资源分布。
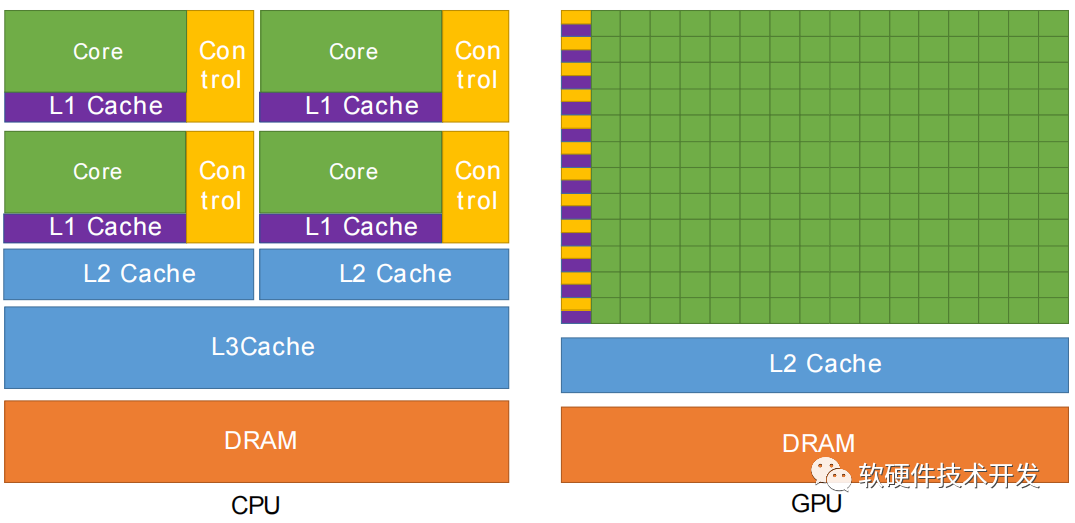
图1.GPU将更多晶体管用于数据处理 将更多的晶体管用于数据处理(例如浮点计算)对于高度并行的计算是有益的;GPU可以通过计算避免内存访问延迟,而不是依赖于大型数据缓存和复杂的流控制来避免长的内存访问延迟。 通常,应用程序有并行部分和顺序部分的混合,因此系统设计时混合使用GPU和CPU,以最大化整体性能。具有高度并行性的应用程序可以利用GPU的这种大规模并行性来实现比CPU更高的性能。
通用并行计算平台和编程模型
2006年11月,英伟达推出了CUDA,这是一种通用并行计算平台和编程模型,它利用NVIDIA GPU中的并行计算引擎,以比CPU更高效的方式解决许多复杂的计算问题。 CUDA附带了一个软件环境,允许开发人员使用C++作为高级编程语言。如图2所示,CUDA也支持其他语言、应用程序编程接口或基于指令的方法,如FORTRAN、DirectCompute、OpenACC。CUDA旨在支持各种语言和应用程序编程接口。
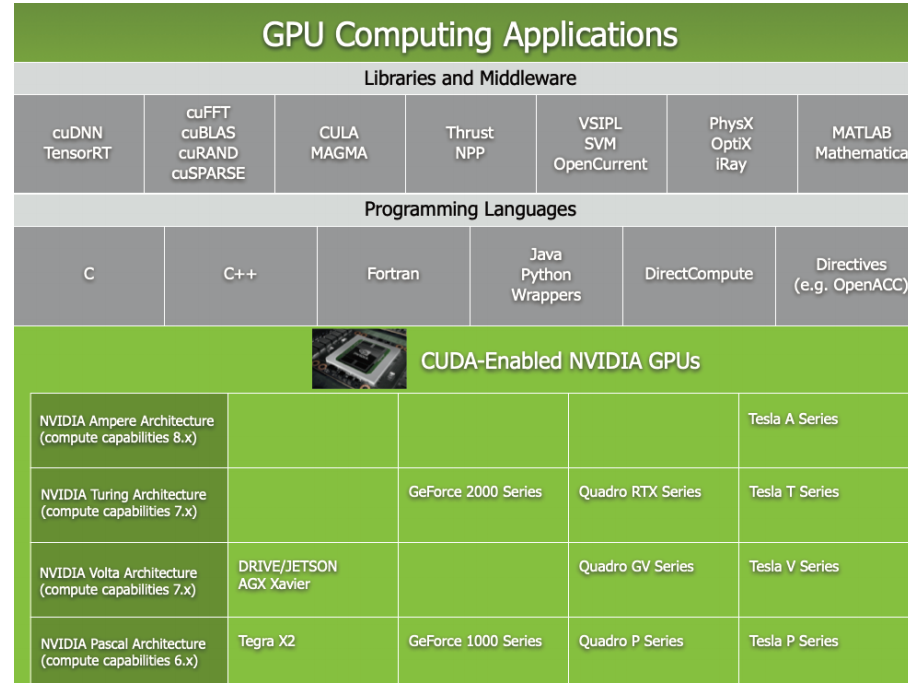
图2.GPU计算应用程序
一种可扩展编程模型
多核CPU和多核GPU的出现意味着现在主流处理器芯片都是并行系统。挑战在于开发能够方便地扩展其并行性的应用程序软件,以利用不断增加的处理器核,就像3D图形应用程序方便地将其并行性扩展到具有大量不同核的多核GPU一样。 CUDA并行编程模型旨在克服这一挑战,同时为熟悉C等标准编程语言的程序员降低学习难度。它的核心是三个关键抽象——线程组的层次结构、共享内存和栅障同步,这些抽象仅作为一组最小的语言扩展向程序员公开。 这些抽象提供了数据并行和线程并行,需要程序员将问题划分为可由线程块独立并行解决的粗略子问题,并将每个子问题划分为更精细的部分,可由块内的所有线程协同并行解决。
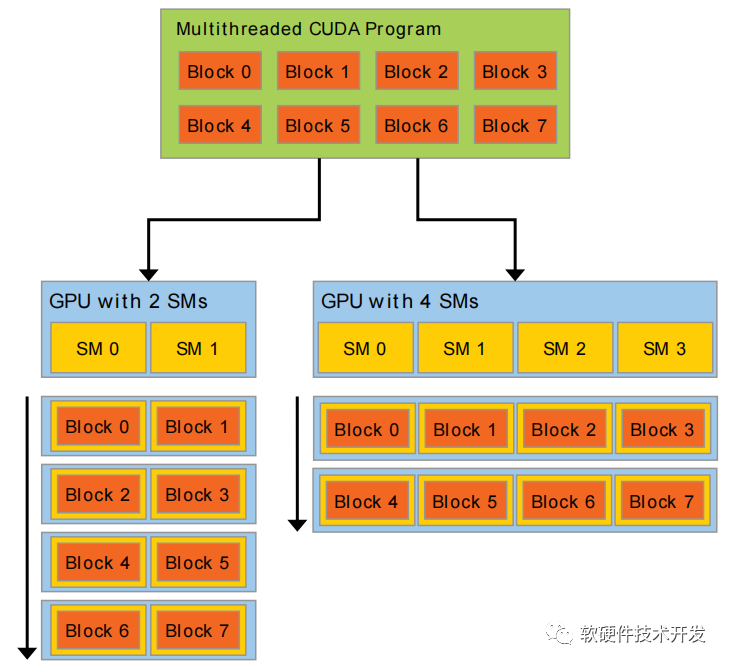
事实上,每个线程块(block)可以在GPU内的任何可用多处理器上以任何顺序、并发或顺序进行调度,这样编译后的CUDA程序可以在任何数量的多处理器上执行,如图3所示,并且只有运行时系统才需要知道实际的多处理器数量。 这种可扩展编程模型允许GPU架构通过简单地扩展多处理器和内存分区的数量来适应不同的显卡:从高性能爱好者GeForce GPU、专业的Quadro和Tesla计算显卡到各种廉价的主流GeForce GPU(请参阅以获取所有支持CUDA的GPU的列表)。
编辑:黄飞
-
基于CUDA技术的视频显示系统设计方案2018-01-18 6400
-
有没有大佬知道NI vision 有没有办法通过gpu和cuda来加速图像处理2024-10-20 8290
-
在K520上能使用两个GPU进行CUDA作业吗2018-09-26 3182
-
linux安装GPU显卡驱动、CUDA和cuDNN库2019-07-09 3778
-
GPU加速的L0范数图像平滑(L0 Smooth)【CUDA】2020-07-08 3040
-
请问CPU和GPU的关系是什么?2021-09-27 2089
-
GPU高性能运算之CUDA2010-08-16 862
-
CUDA学习笔记第一篇:一个基本的CUDA C程序2020-12-14 1994
-
CUDA简介: CUDA编程模型概述2022-04-20 4291
-
国产GPU绕不开的CUDA生态2022-11-29 6036
-
使用CUDA进行编程的要求有哪些2023-01-08 3638
-
GPU平台生态,英伟达CUDA和AMD ROCm对比分析2023-05-18 4102
-
CUDA核心是什么?CUDA核心的工作原理2023-09-27 12052
-
在Python中借助NVIDIA CUDA Tile简化GPU编程2025-12-13 1638
-
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程2026-02-10 716
全部0条评论

快来发表一下你的评论吧 !
