

FreeSWITCH高可用部署与云原生集群部署知识分享
描述
大家好,我本次分享的主题是FreeSWITCH高可用部署与云原生集群部署,主要是谈一谈从高可用到弹性伸缩的一些技术应用。
具体包含以下相关内容:双机、三机,到可弹性伸缩的通信集群建设经验,包含⼀对⼀通话、呼叫中⼼及⾳视频会议、⽇志监控等场景,涉及FreeSWITCH、Kamailio、WebRTC、MCU、SFU、Docker、K8S、ETCD、NATS、Loki等相关技术。
主要会介绍我们用到的一些技术,希望能对大家有所帮助。上面提到的一些技术其实也不算是新技术,通信技术已经历几十年发展,早在二三十年前大家就已经在研究高可用相关技术。不过因为新时代的发展,最近大家开始关注云原生等相关技术,相应基础设施产生一些变化,通信与互联网的联系也越来越紧密,由此产生了更多新的玩法。
01 单点故障
其实,一切的起源都是来自“单点故障”这个问题,我们就由此展开来进行介绍。
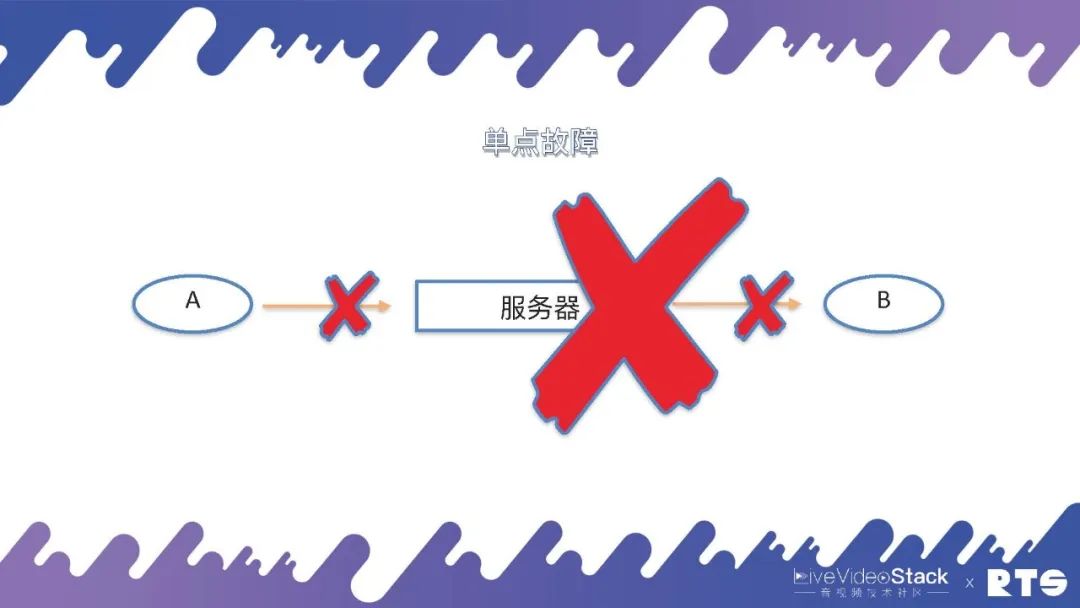
A和B两个通信的实体,两个电话(人)通过一台服务器进行通信,当然这个服务器可以是FreeSWITCH,也可以是任何其它服务器。假设这台服务器由于通信链路中断或者是网络连接中断,A和B则无法完成通信,这就是单点故障的起源。
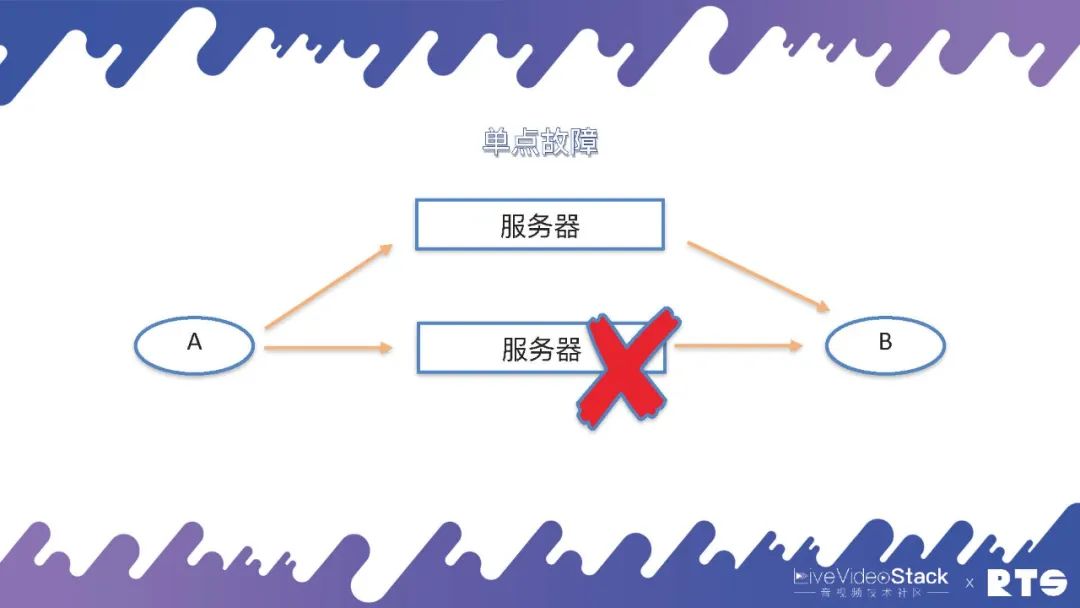
那要想解决这个单点故障,就需要另外的服务器通过迂回路由或是其它办法来克服单点故障的问题。
02 双机HA
一般来说,克服这个单点故障的方法就是双机HA(High Availability),即主备高可用。
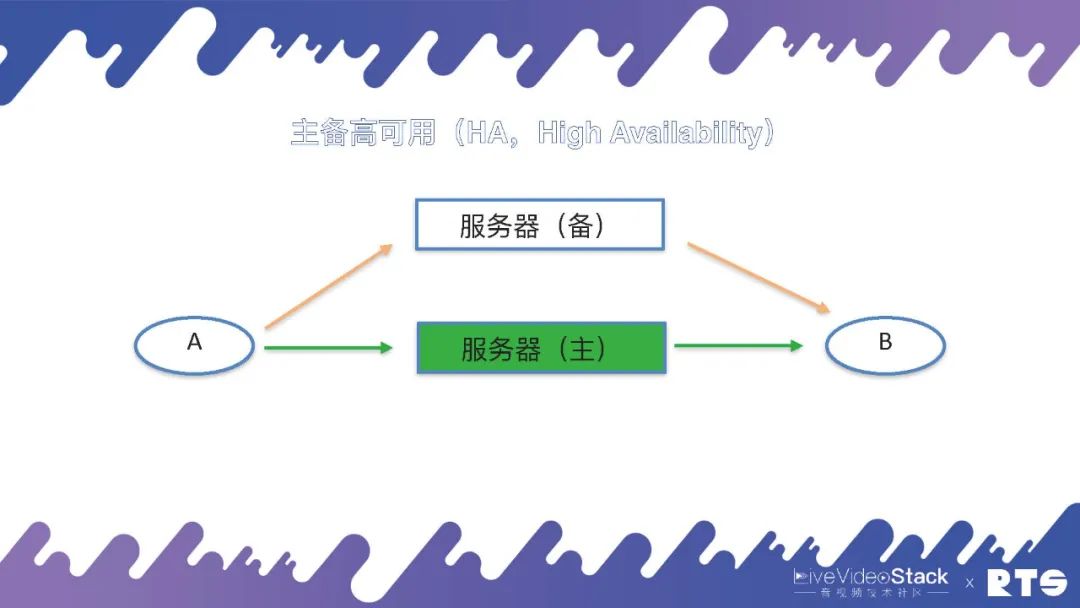
双机HA的主要原理是:有一台主机和一台备机,假如主机出现问题断连,备机可以接替成为主机继续进行工作,如此不断进行主备交换。主机与备机为同一IP地址,对于A和B来说可能感知的到或者根本感知不到主备机所进行的切换,因为通讯时A和B看到的仅仅只是IP地址,当任何一台服务器切换到主机时,它就占有了对外服务的IP地址,这个IP地址我们就叫做虚拟的IP,也叫业务IP或浮动IP。本身每台服务器底层还有一个IP,但对外提供服务的IP(即A和B看到的IP)其实是虚拟IP。
这样当服务器发生切换的时候,A和B仍然是和原来的IP进行通话,他们可能会感觉到网络的短暂卡顿,然后恢复正常,而感知不到服务器是否有进行切换,这就是主备高可用的原理。
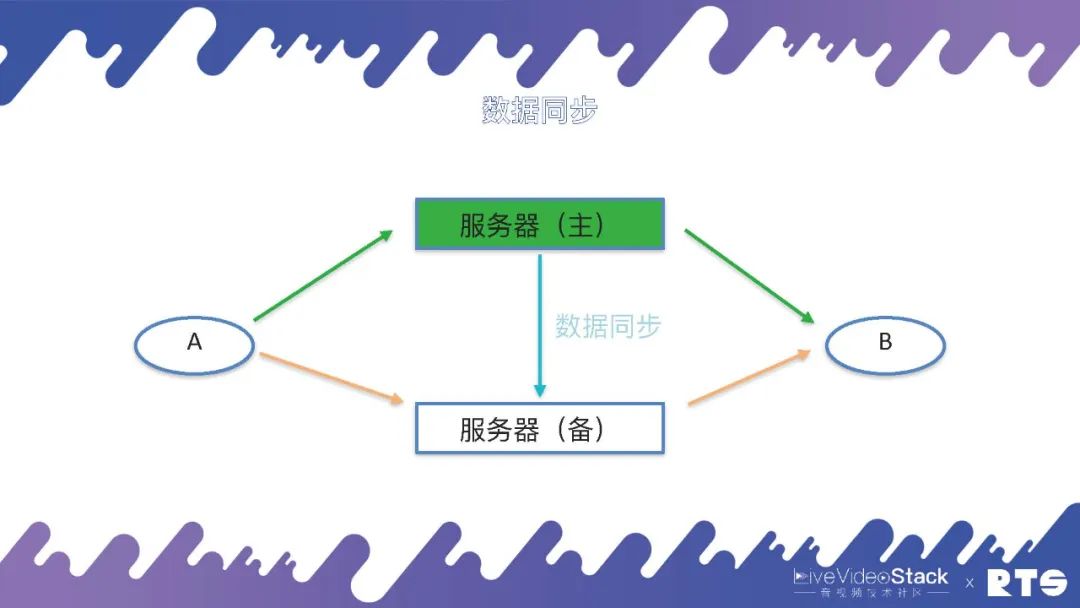
为了实现主备高可用,由于主服务器和备服务器之间有一些数据需要同步,所以就需要一种数据同步机制。
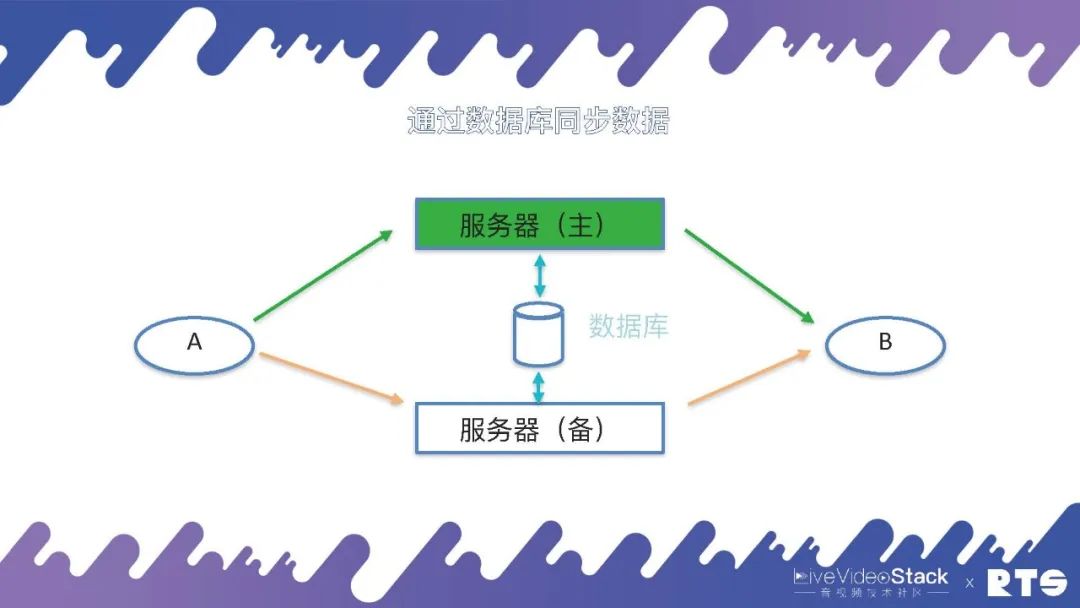
当然这个数据同步的机制有很多种,例如通过日志、消息队列等等,在FreeSWITCH中主要是通过数据库来同步这些数据。主服务器会实时将A和B(A和B可能有成千上万个)通话的数据写入到数据库当中,备机可以在数据库当中查询数据,一旦发生主备切换,备机从数据库当中取得数据,重新建立通话场景,A和B就可以继续进行通话。
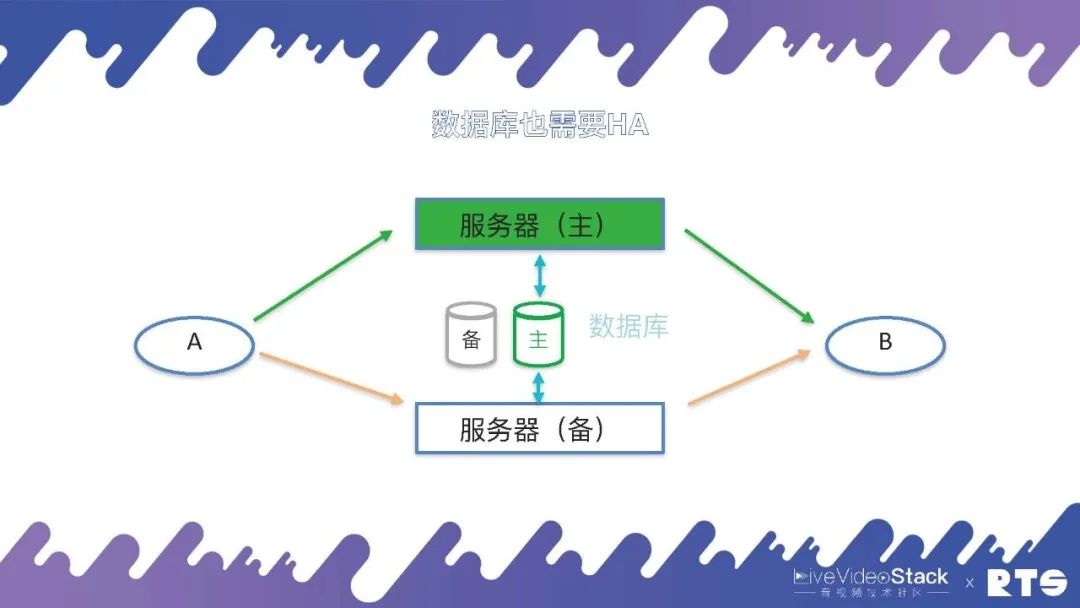
在这种情况下,数据库也就成为了一个单点,为了解决这个问题,数据库同样需要主备高可用。
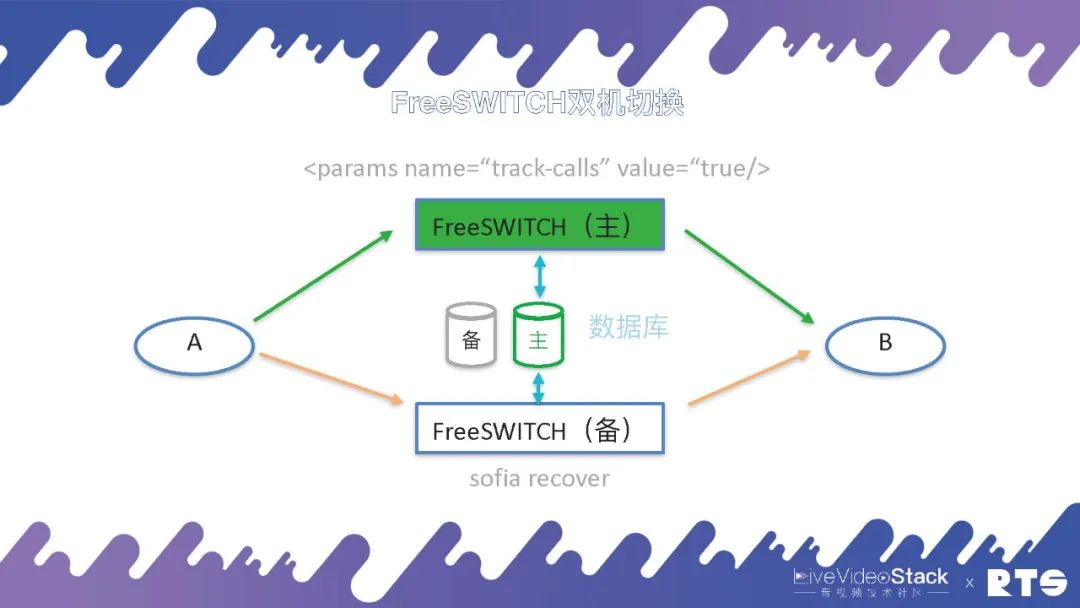
FreeSWITCH的主备切换原理:首先主机包含一个Param,参数为:
当备机发生切换的时候,备机会执行一个 sofia recover 命令,从数据库中取得数据重建通话的场景,向A和B发送 reINVITE。前面我们说A和B感知不到,其实也能感知到,因为A和B收到了重新建连的邀请,继续进行通话。一般这个通话过程大概在1-3秒内解决,A和B只是觉得会短暂的卡顿,不用挂断重新呼叫。
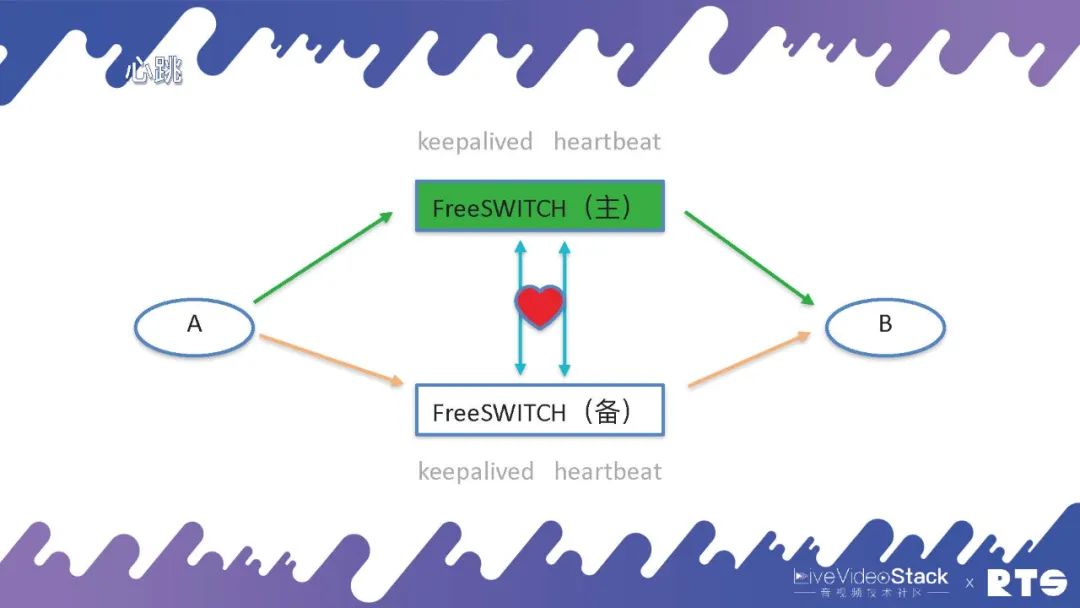
我们先排除数据库的影响(默认数据库是主备高可用的),来看FreeSWITCH的主备高可用。
为了能准确感知进行主服务器和备服务器之间的切换,需要有一个东西叫心跳(心跳线),一般心跳线在之前都是用串口线,因为心跳只是简单的传几个字节的信息,对带宽的要求不大。但现在在一些虚拟机中,不包含物理的串口,就只能用网线来实现。通过一个网线,不停的有心跳,备机可以借此感知主机的状态,一旦产生主机崩溃、断连,备机会接管IP。
当然这个情况下也可能会产生误判,考虑到心跳线本身的断开影响,我们可以通过两根心跳线或双网卡的方法避免出现这种误判的情况。总之,我们需要更多的机制来保护系统,避免出现两个服务器同时绑定同一个IP,同时写入服务器导致服务器错乱的情况产生。
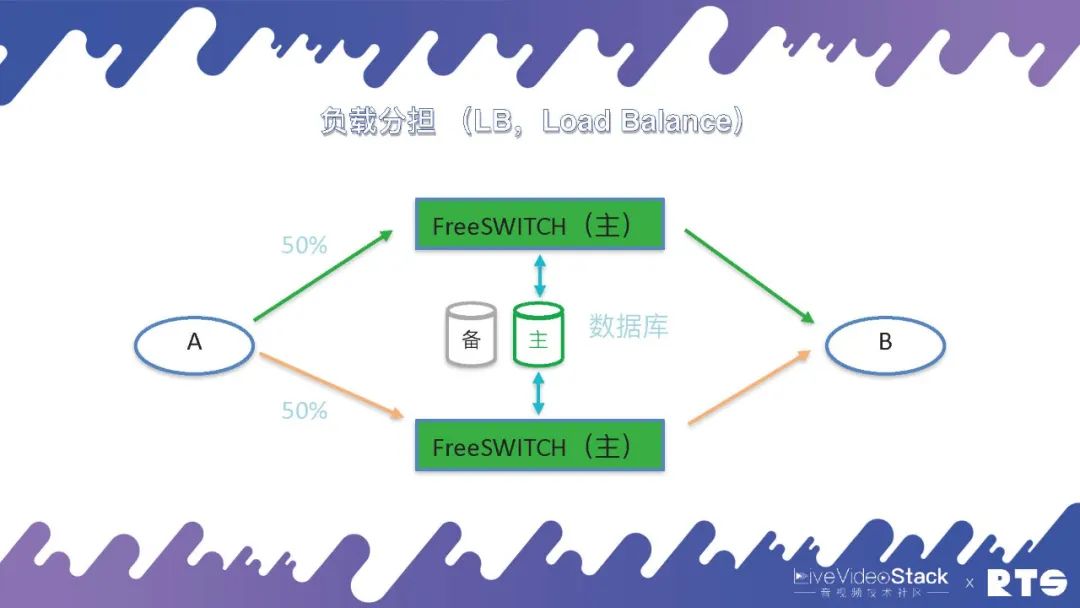
当然,这种情况下会有一些问题,两台机器作为一台机器使用,可能会造成资源的浪费。还有一套方式是负载分担(Load Balance),A和B之间有50%的话务分别放置于两台主机,两台主机可以同时达到满负荷承载。但这种情况同样存在一定问题,假设原本每台可以承受一千路通话,两台配合总共可以承受两千路通话,当其中一台主机出现问题,另一台在满负载的情况下,实际上系统的吞吐量只能达到一千,就会发生拥塞发生问题。
所以说一般主备负载分担的情况下,我们会保证两台FreeSWITCH主机每台的话务量不要超过其设计容量的50%,这样是比较安全的。当然,这样算起来我们实际上还是有50%的浪费,我们也可以采取通信降级的策略,当一台主机出现故障时,仅使用另外一台主机,根据实际业务需求,保证部分通话连接的正常使用。
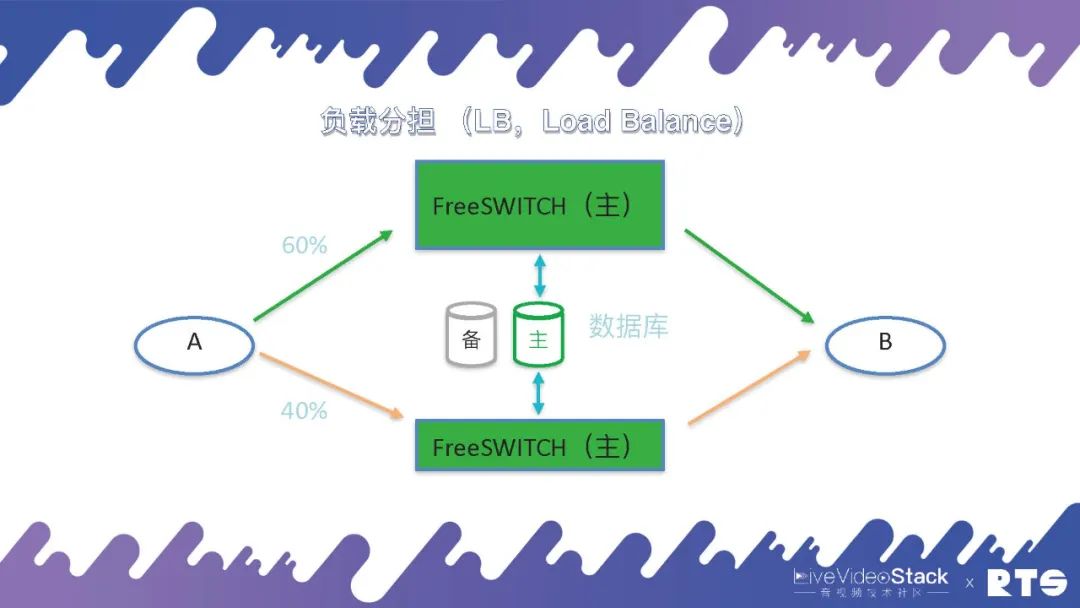
不过负载分担对于A和B会有一定的要求,前面我们说到主备的方式,A和B都只能看到一台服务器(实际上是两台服务器),是一个IP地址。但是在负载分担的情况下,A和B都能看到两台机器,这就需要一定的逻辑(在A和B上做),需要能够分发比如将50%的话务量分到一台主机,剩余50%分到另外一台主机。而且有时候两台主机的性能不一样,可能一个是64核,另一个是32核,需要根据主机性能对话务量进行分配,比如一个60%,一个40%。这样就会对A的要求比较高,需要能够感知主机来进行负载的分发。
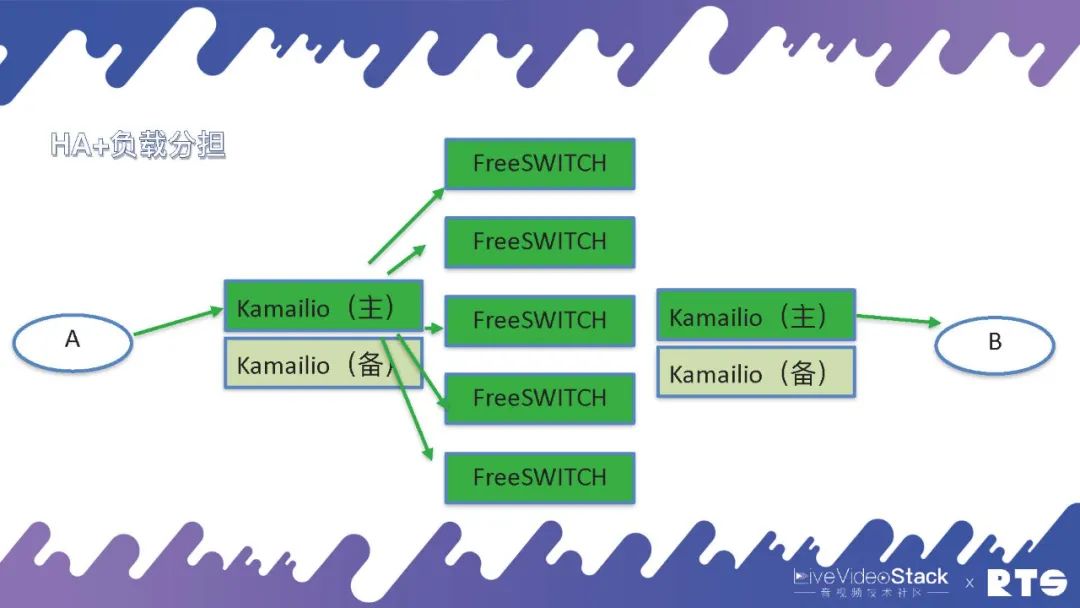
在实际的部署当中,我们一般都是采用这样的结构(如图所示)。FreeSWITCH作为媒体服务器,前面再放上代理服务器,一般是用Kamailio或者openSIPS做代理。Kamailio只代理SIP就是指处理通信的建立和分发,一台Kamailio后端可以放很多的FreeSWITCH。因为FreeSWITCH要过媒体,要进行录音、质检、分析等等媒体的处理,所以FreeSWITCH的处理能力就不如Kamailio强。这样前面放一个Kamailio,后端可以放很多FreeSWITCH进行通信。
当然Kamailio需要主备高可用,而Kamailio和FreeSWITCH之间是用Load Balance,这样用HA+负载分担的方式就完成了一种比较大的通信集群。而且由于A和B两侧的业务逻辑有可能会不一样,比如说一侧是中继,一侧是话务员是本次的系统电话,这时我们可以放两个不同的Kamailio,管理起来会更方便一些。
当然我们也可以使用一个Kamailio,将A和B放在一侧,但这样的话脚本和逻辑的判断上就会比较复杂。因为必须要判断通话是由A还是B过来的,还是从FreeSWITCH过来的,需要判断呼叫的方向,逻辑会相对比较复杂。
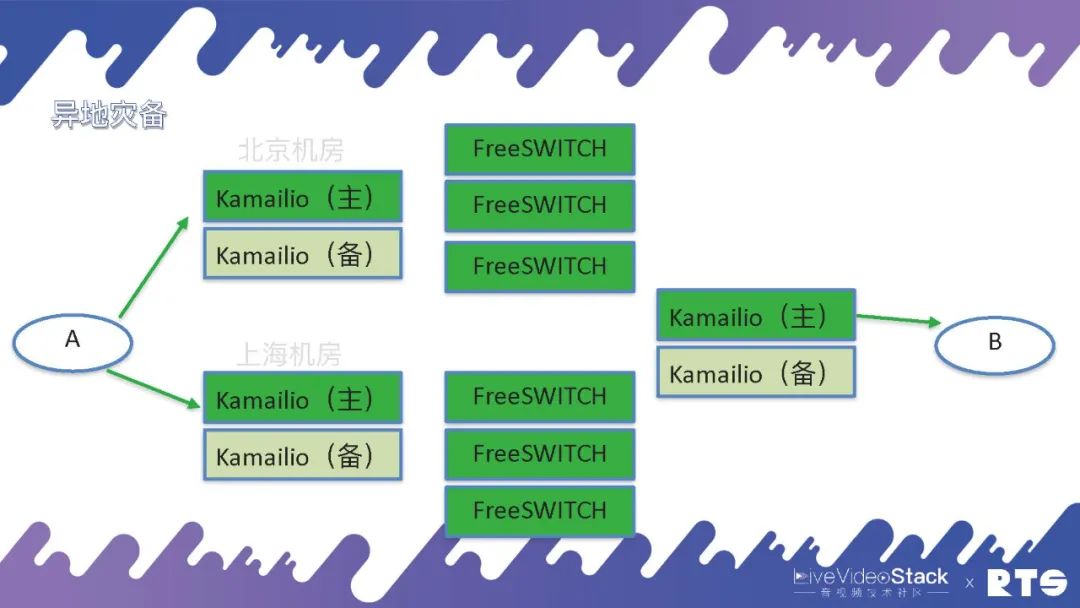
还有一种情况就是异地灾备,什么是异地灾备?举个例子,我们可能有两个机房分别在北京和上海,都用FreeSWITCH和主备高可用,这样平常主要通过北京的机房,一旦出现问题可以通过迂回路由经由上海的机房进行通信。
但是异地灾备同样需要一些数据的同步,这就又对A提出了一定要求,因为A面对的是北京和上海两个机房。所以说高可用是无穷无尽的,只要有需求只要改架构就需要相应的考虑,但万变不离其宗,其实就是HA和负载均衡这两种逻辑。当然具体地来说,A上可能靠DNS轮询,也可以将北京或上海的地址直接写进设备当中,自己执行策略根据情况来进行切换等等。
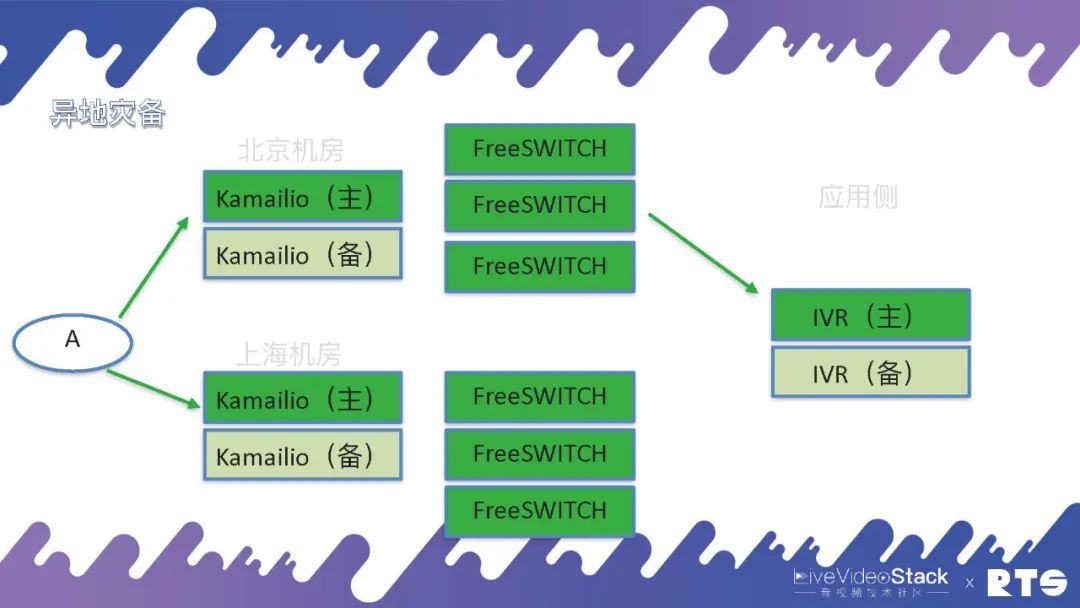
那么,我们来看B这一侧。A和B进行通话,有可能会呼叫进来之后执行IVR有些应用,这些应用同样需要主备高可用。比如有人打电话进来,Kamailio是负责信令的,FreeSWITCH负责媒体,但是具体的逻辑是由应用来负责的,需要由它来告诉FreeSWITCH应该什么时候处理媒体、什么时候录音、放音等等,所以应用侧同样需要主备高可用。
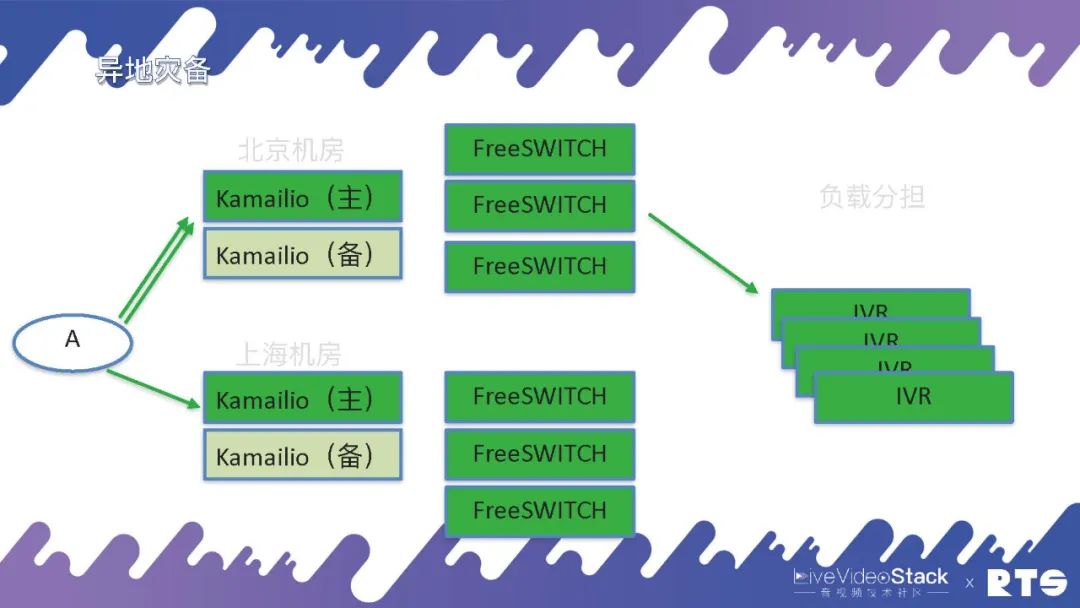
当然,一般的这种IVR我们认为它大体都是无状态的,接入通话挂断之后再接入一个新的通话同样还是这个IVR,所以一般都会用负载分担的方式,可以承担多个IVR的业务。
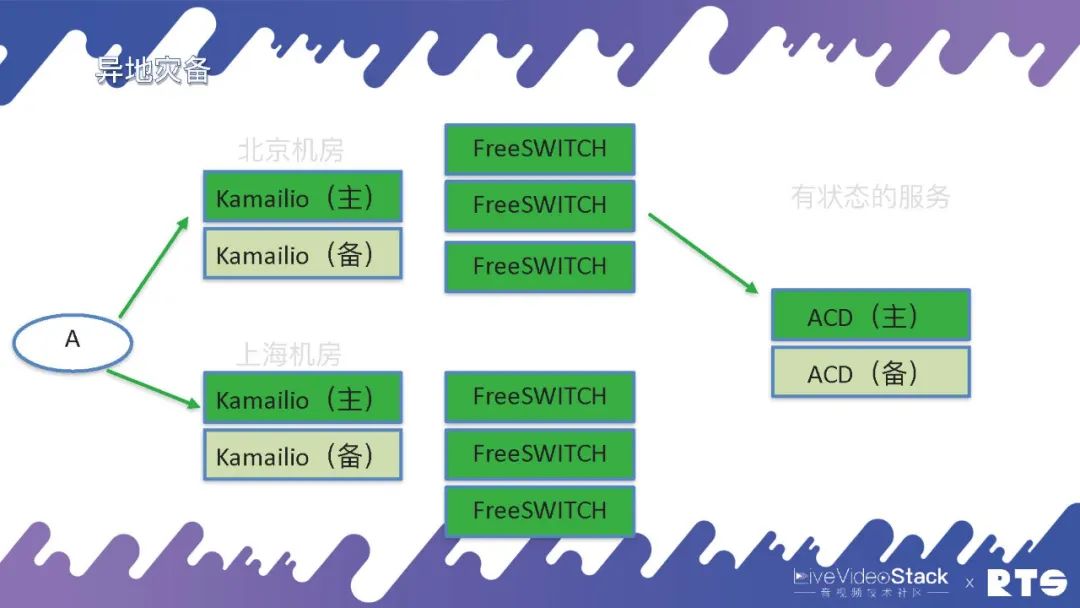
但是有一些服务它是有状态的,比如说呼叫中心当中常用的ACD。ACD需要check坐席的状态,以及队列的状态,有多少客户在等待、有多少坐席在服务、哪个坐席正在跟客户沟通、哪个坐席正处于空闲,它需要跟踪这些状态。一般来说对于这种有状态的服务,还是要采用主备高可用的方式。当然,双机HA同样可能会出现两台机器同时发生问题的情况,这时候我们就扩展到 —— 三机。
03 Raft
三台机器的场景更为麻烦,由此我们引入了一个协议叫做Raft,还有一个叫做PaxOS,不过现在比较常用的还是Raft协议。

Raft其实是一个共识协议,它的主要作用是做Log。首先它是用一个分布式的系统,分布式系统主要是解决容错的问题。那么怎么解决呢?就是同步日志。比如一台机器上的日志,我要将这些日志副本同步到其它的服务器上去,当然我们说到的日志可能也是数据,数据库数据或者通话的数据或者是状态的数据等等。一般来说Raft都是奇数的,因为其遵循少数服从多数的原则,通过投票来进行选举。
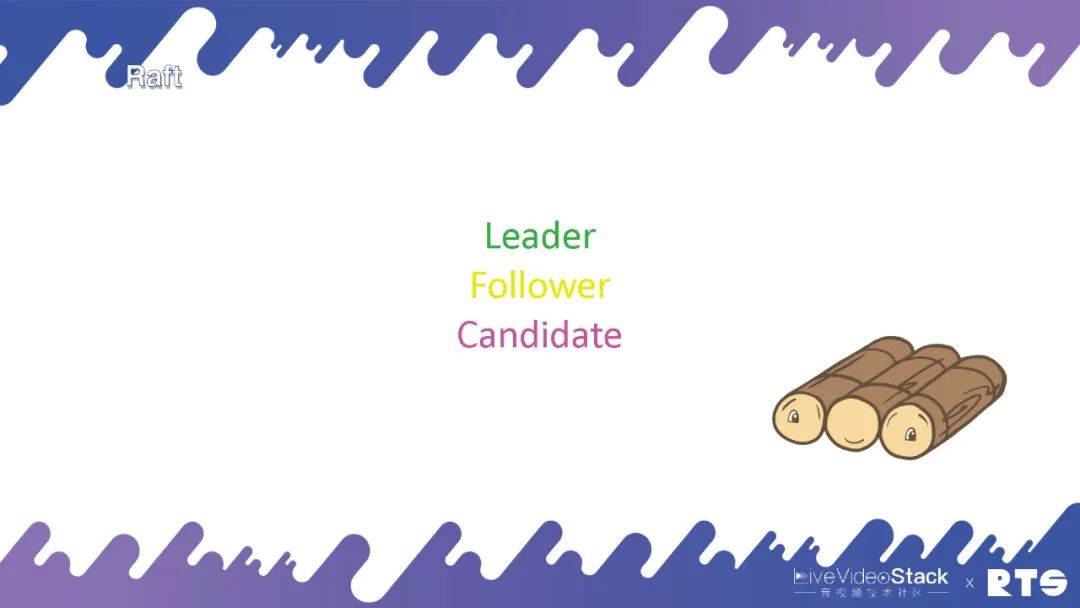
Raft中包含三个节点,Leader(领导)是一个主服务器,所有人会选举选出一个Leader来,由Leader来决定什么时候修改数据。然后它会把这些数据同步给Follower(追随者),所有的数据会从Leader上进行修改,之后会同步到Follower上。正常的情况下,集群内有Leader和Follower,数据就可以在服务器间进行同步。但又一种情况是作为Leader的主服务器挂掉了,其它所有的服务器就会变为Candidate(候选者),有机会被选举成为新的Leader,通过这个机制可以保证有一台服务器是可以保存这些数据的。
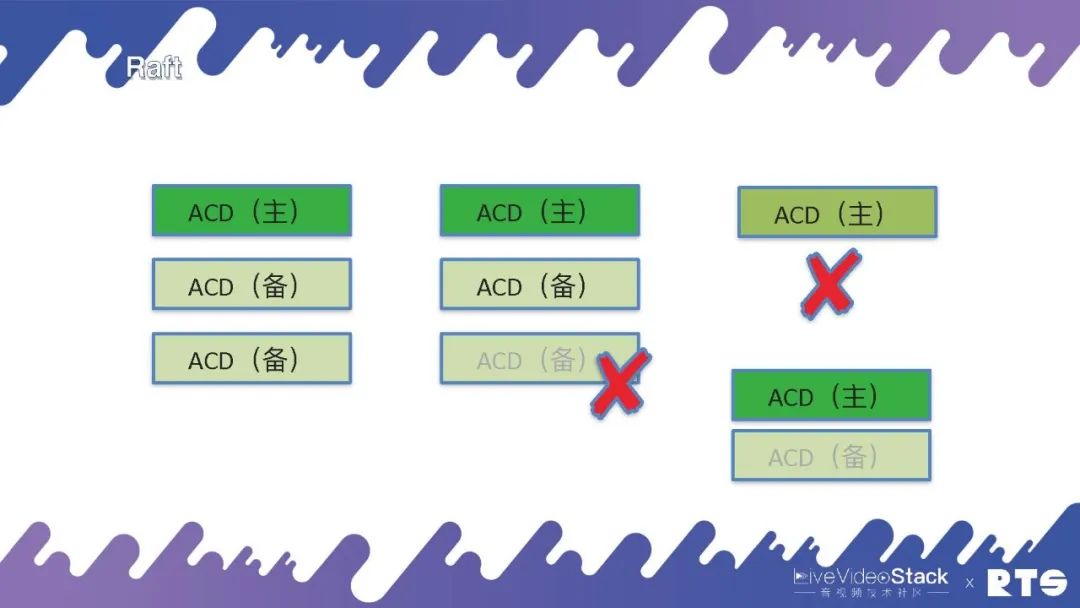
但是它虽然能保存数据却不能对外提供服务,Raft集群规定其中有一台主机负责写数据,另外两台负责备份,只有集群当中有多数的主节点和备节点活着的时候,比如说3个死了1个,则还可以继续对外提供服务。但是如果是死了两个,就不能继续对外提供服务了。
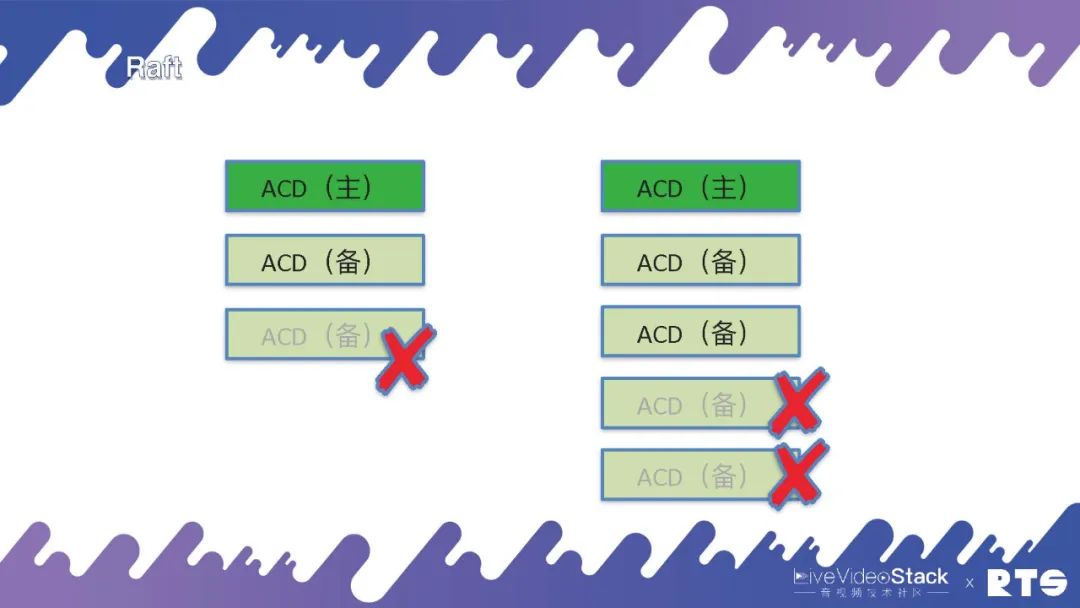
那么,这是为什么?如图最右侧我们来看,假设原来的主服务器与其它服务器断开链接,此时它还是能正常进行服务。而另外的两台服务器会根据当前情况判断,重新选举出一台作为主服务器。此时,整个集群当中就会同时出现两台主服务器产生冲突。所以一定要遵循少数服从多数的原则,只有当整个集群中有多数的节点活着的时候才能对外提供服务。
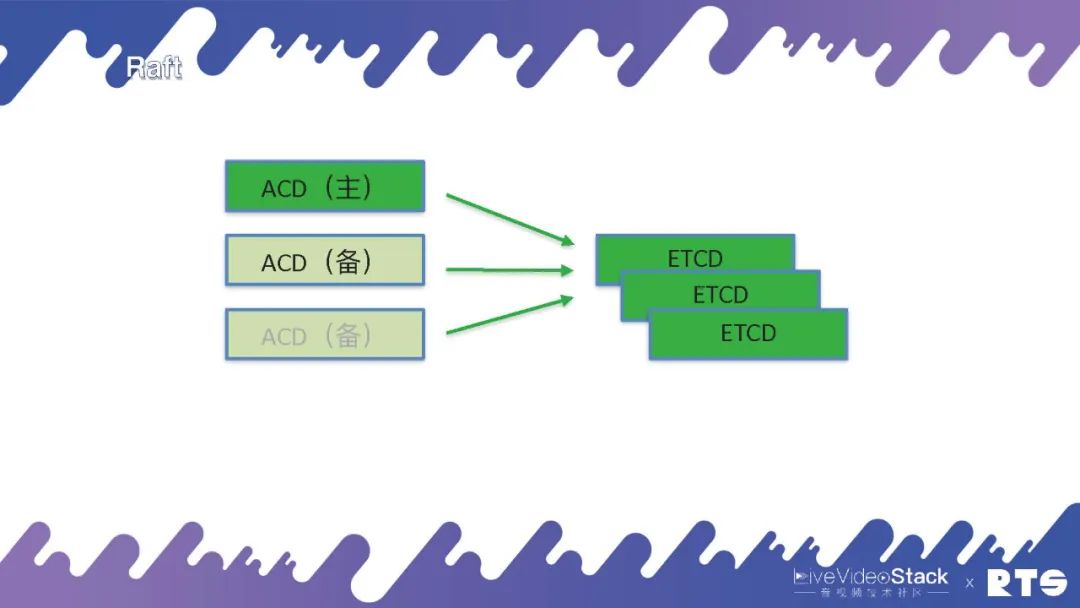
当然,如果我们说要把所有的ACD里面都要实现一个Raft是很难的。目前有一个应用叫做ETCD,我们可以直接将服务连接到ETCD上,它会告诉我们谁是主谁是备。但是这样又带来了一个问题,本来三台机器就可以,我们还需要另外再装三台ETCD,这样会带来更大的开销和浪费,多用了一倍的资源。
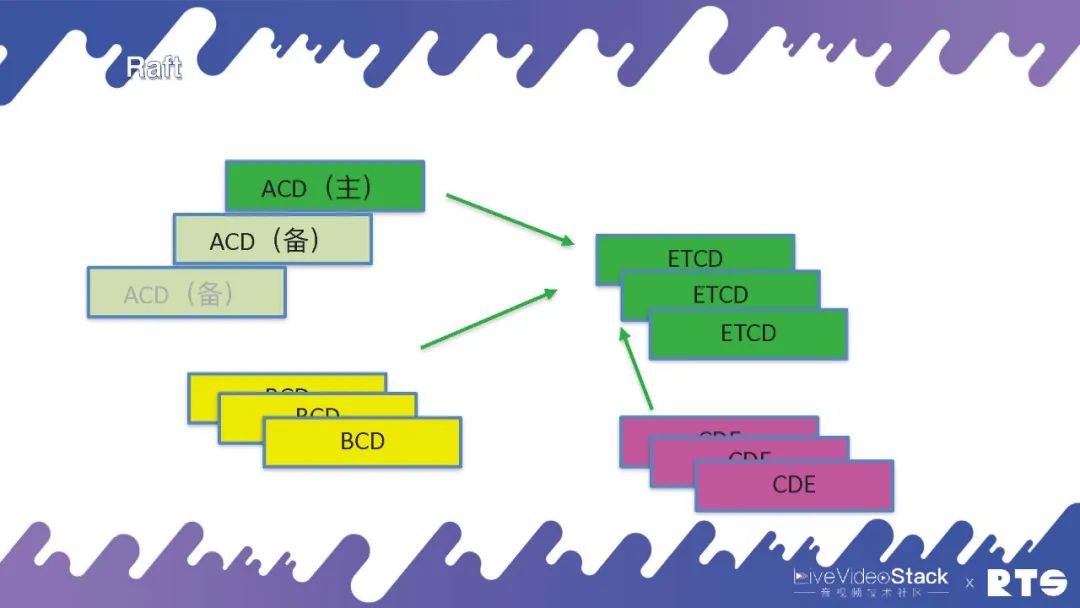
但是当我们的集群比较大的时候,比如除了ACD外我们还有其它服务如BCD、CDE等等。如果各种微服务的数量比较多,可以公用一个ETCD的话,相比较而言开销也就没那么大了。

简单的总结一下:
双机可以提⾼可靠性,但投⼊资源和获得回报不成正⽐;
为了节省服务器,把不同的服务放到相同的物理服务器或虚拟机上,可能适得其反;
集群可以提⾼可靠性,但只有集群⾜够⼤,资源才能有效利⽤;
双机需要的服务器数量是偶数的,⾄少2台;
分布式系统(集群)需要的服务器数量是奇数的,⾄少3台。
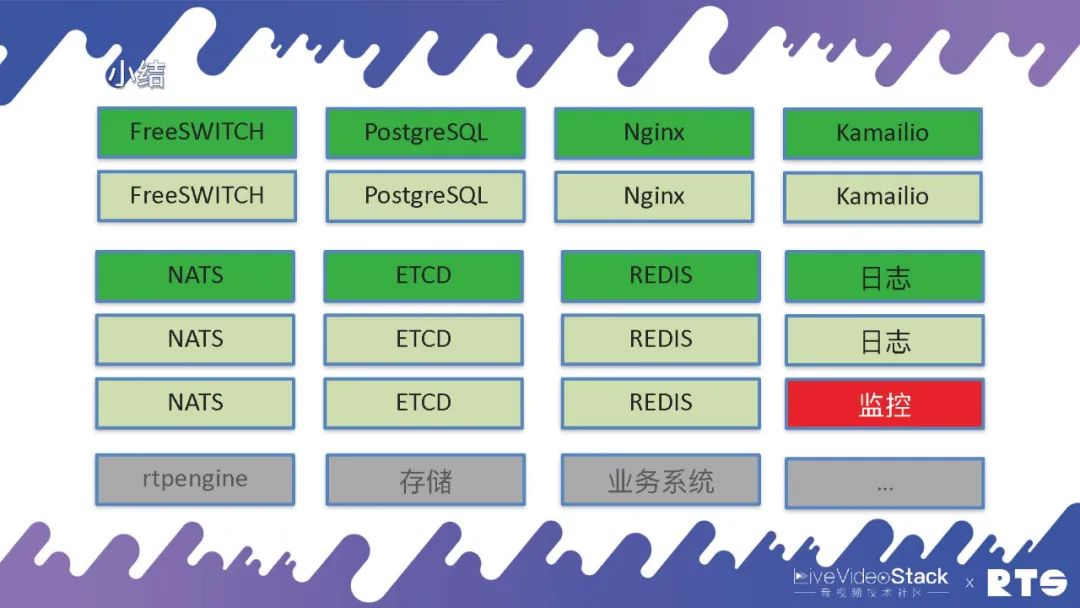
一般的来说,有一台FreeSWITCH服务器就够了,如果想双机设备的话就需要两台服务器,如果需要数据库的话就是四台。有可能还会放Nginx代理HTTP,还有可能会放Kamailio来代理SIP。当然我们主要使用NATS,这是一个消息队列。然后使用Etcd来做选主,有可能使用Redis来做缓存,还有可能做日志、监控等各种服务器。还有可能rtpengine、存储、业务系统......
总之,要是想建立一个可靠的系统至少需要十几台服务器,它对外所能提供的服务能力也超不过一台服务器的服务。所以如果集群规模比较小,那就没有什么意义,投入天文数字但实际上整体的收益很小。如果想要集群规模做的足够大,类似云服务,那么投入多少台服务器其实都无所谓了,因为开销是相对比较小了。当然,这些最终还是需要根据业务本身来做权衡。
04 XSwitch实践
接下来介绍一些XSwitch的具体实践。
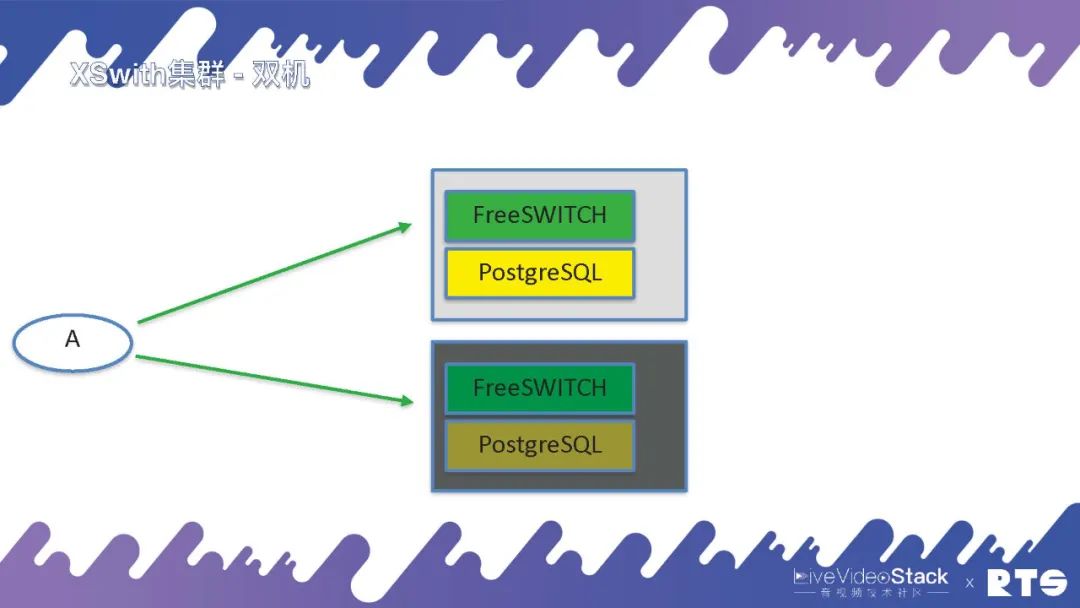
XSwitch即XSwitch集群,一般来说最小的配置就是双机,主备高可用,FreeSWITCH和PostgreSQL放在一块。
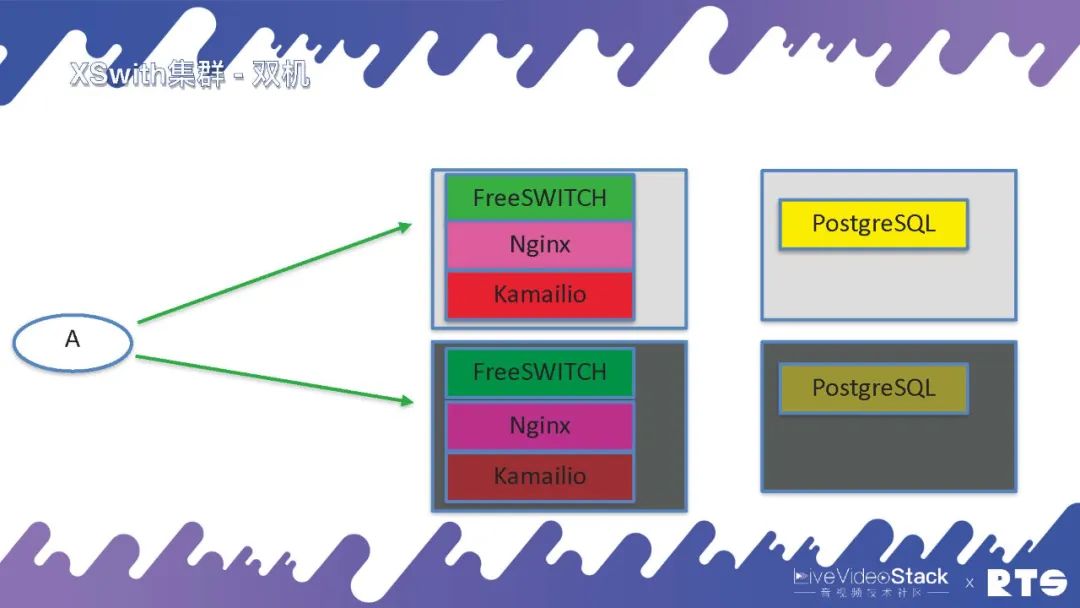
对于有一定预算的客户,我们就建议他们将数据库独立出来,放在独立的服务器上,总共4台服务器。Nginx一般我们可以跟FreeSWITCH放在一起,然后有可能我们会放Kamailio。
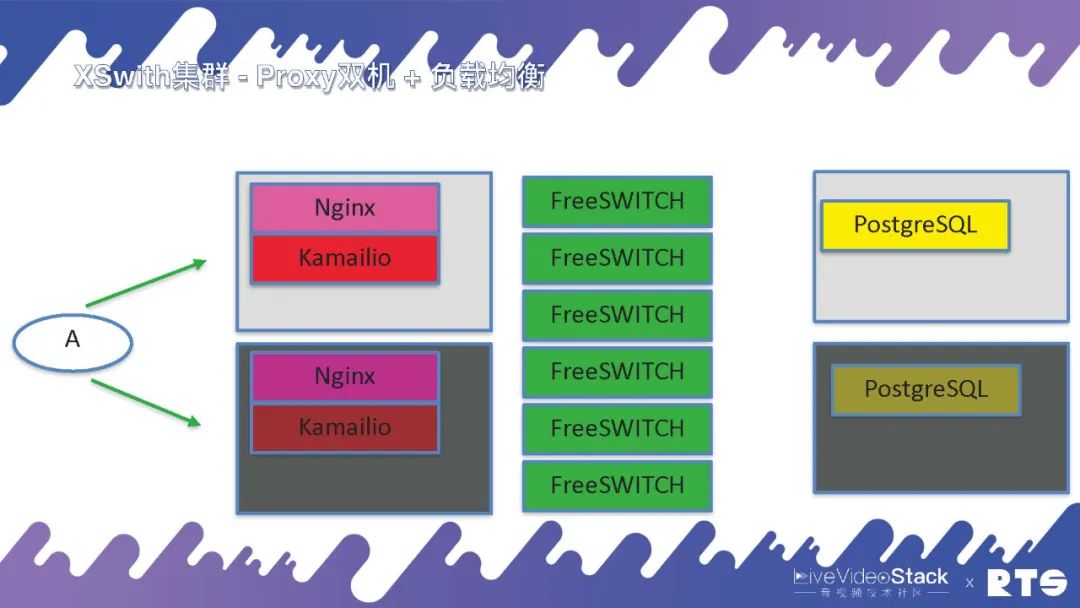
如果预算充足也可以将它们都独立出来,这样后面就可以放更多的FreeSWITCH。
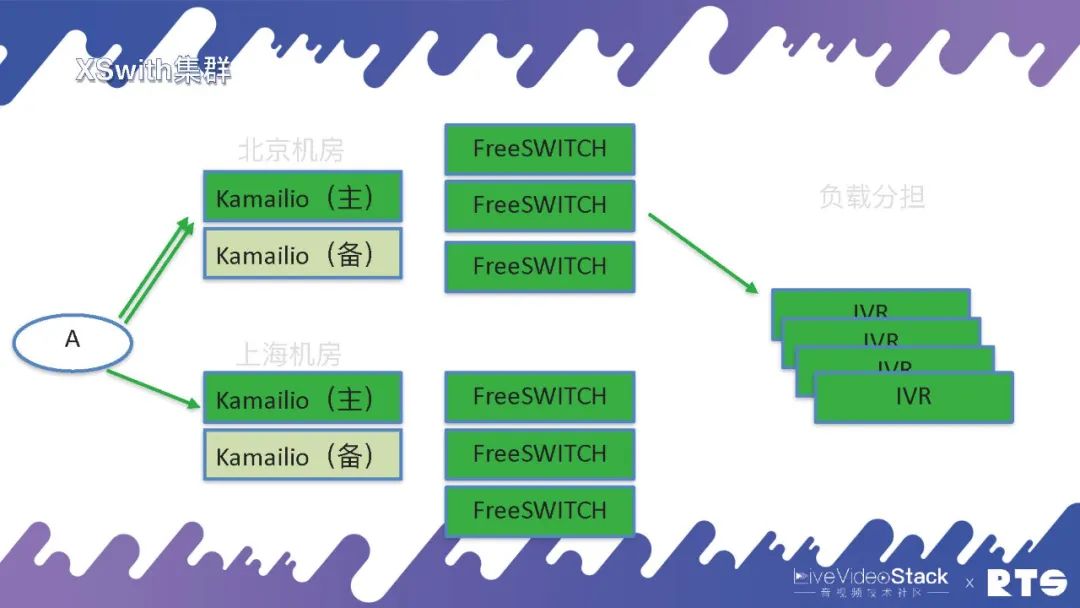
再就是异地的,负载分担。
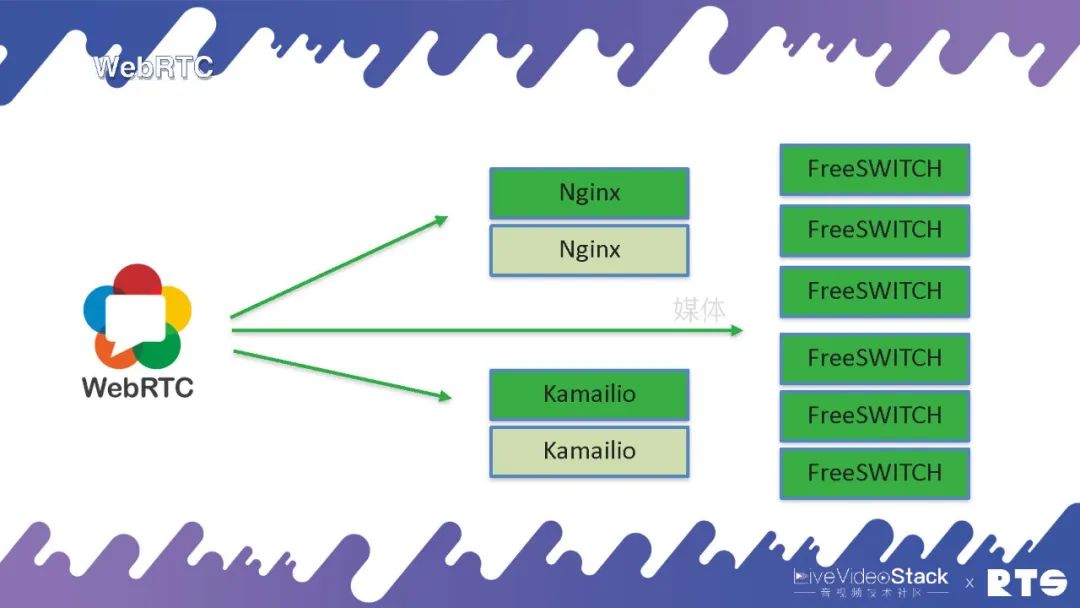
因为WebRTC只有媒体, 所以就是直接到FreeSWITCH,信令可以通过Nginx或者Kamailio实现,因为信令都是基于WebSocket来做的,这是WebRTC的高可用。当然,媒体前面我们提到有个rtpengine也可以做代理,可以把后台的FreeSWITCH隐藏起来,这就是更复杂的一些应用了。
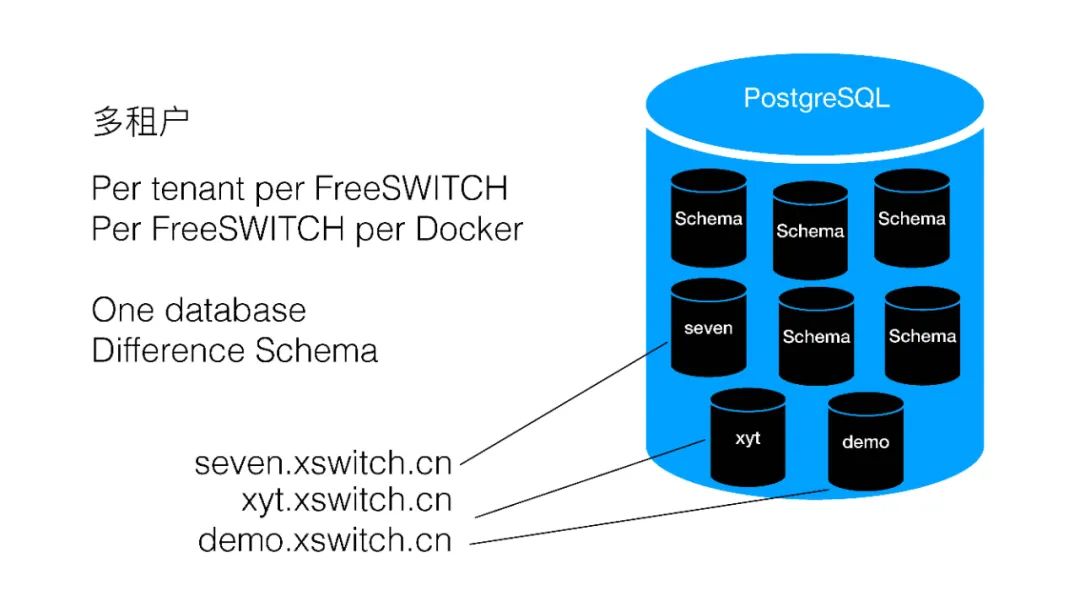
XSwitch如何实现多租户呢?其实我们有好多种方式,一种就是Per tenant per FreeSWITCH,每个租户给它一台FreeSWITCH,每个FreeSWITCH一个Docker,使用同一个数据库,我们用的是PostgreSQL,里面可以天然的分Schema,每个Schema都是彼此隔离的,这样的话可以给每个租户分一个Schema。
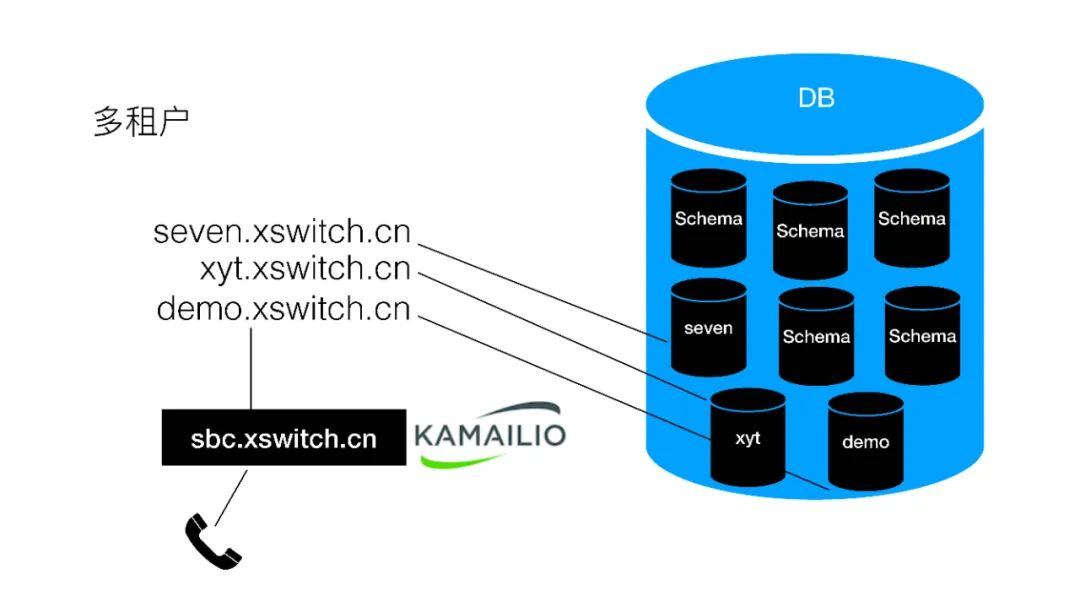
也就是每个租户一个域名,每个租户一个Docker,每个租户一个Schema,数据库是同一个。前面放一个sbc,用Kamailio来做信令的代理,当然sbc现在我们是单机部署的,以后也可以做HA。
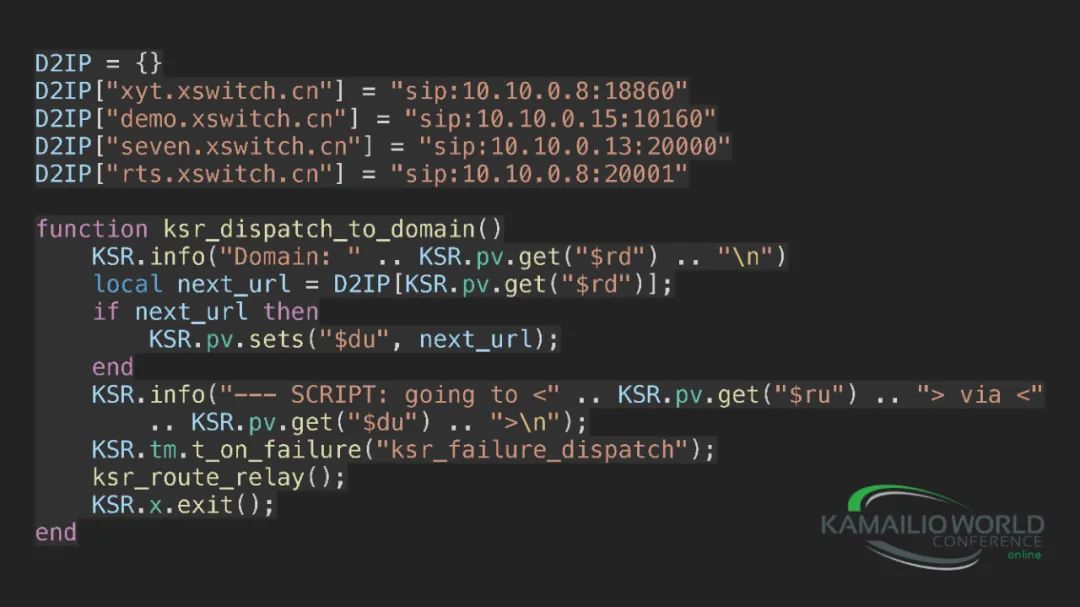
具体的代码其实我们就写了一个映射表,因为我们现在集群规模比较小,还没有放数据库,通过域名就可以直接查到对应的IP地址,来进行分发。我们使用的是Kamailio+Lua。
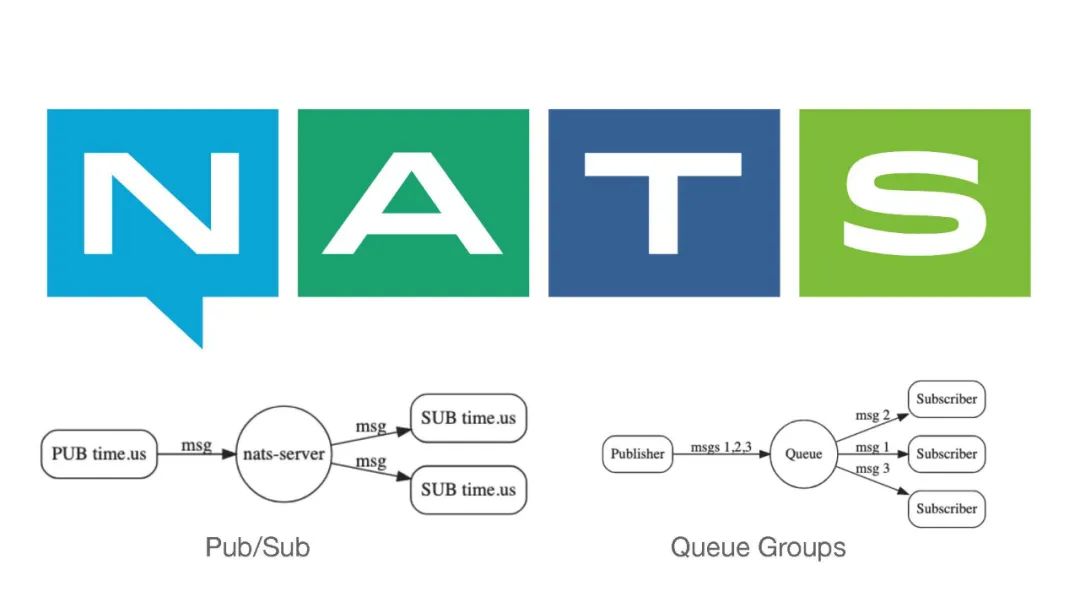
在应用侧我们就使用了NATS。NATS是一个消息队列,所以它具有消息队列的一些基本特性,比如说Pub/Sub来进行推送,还有一个就是Queue Groups,可以通过一个队列进行订阅,这种情况下就可以做负载分担。生产者生成了一条消息,消费者可以负载分担的消费这些消息。
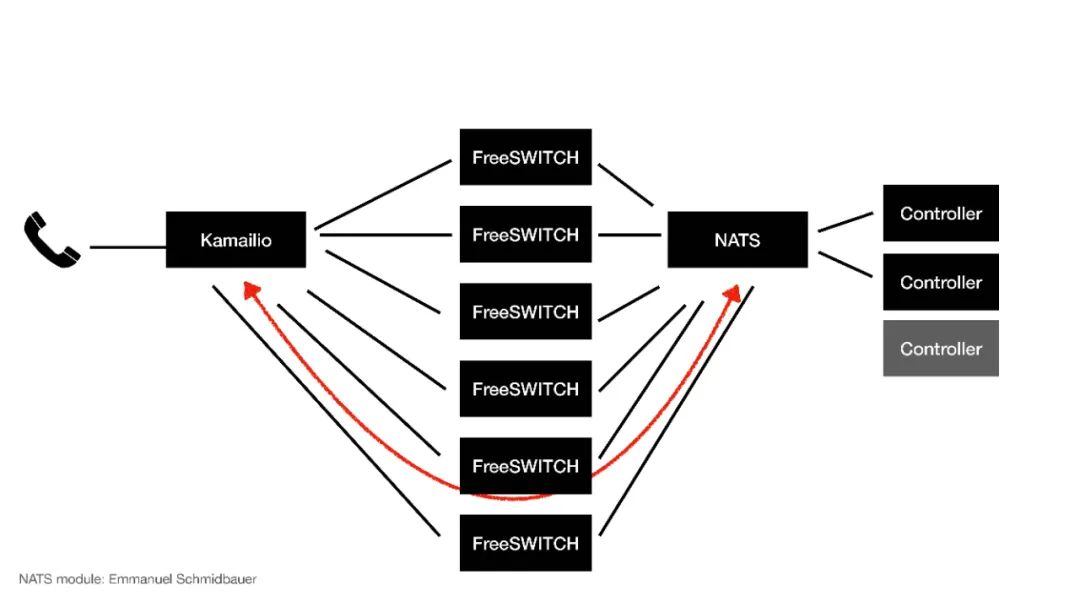
那么我们就用它来做集群的应用:来了一个电话到Kamailio进行分发,分发到不同的FreeSWITCH,通过NATS分配给不同的Controller,这个Controller就是应用侧,应用侧会控制通话的逻辑。
当来了一个电话到了FreeSWITCH以后,NATS会分给某一个Controller,这个时候Controller就跟某一台FreeSWITCH建立了一个虚拟的对应关系,在这个电话的生存期间它就可以控制这路电话的通话行为和呼叫流程。
当然,这个Controller也可以额外增加,FreeSWITCH也可以。NATS也连接到了Kamailio,Kamailio也可以感知到NATS,这时候如果我们扩展、弹性伸缩,FreeSWITCH不够用我们又加了几台,这个时候FreeSWITCH就会给NATS发一个消息,NATS会把这个消息发给Kamailio,Kamailio就感知到我现在有了6台FreeSWITCH,它就会重新计算它的路由表,我们用的是dispatcher模块,重载dispatcher模块的数据,然后它就会把新的通话分发给新的FreeSWITCH,这样就完成了一个扩容,这也就是弹性伸缩。
弹性伸缩的“伸”还是比较容易的,只需要往上加机器就行。“缩”才是比较困难的,有时候需要等所有的话务量都去掉之后才能进行。
当然,“缩”还有一个就是可能大家都认为的,比如其中一台机器挂掉了,我重启一下。其实重启之后它就不是原来那台机器了,我们这边用的都是FreeSWITCH的UUID,重启之后UUID会发生改变。虽然IP地址有可能变有可能不变,但我们认为它是变了,因为是一台新的机器了。
所以说在这个集群里面,即使是重启了以后,它也不是原来那台机器了。我们在哲学里曾学过:“⼈不能两次踏⼊同⼀条河流”就是这个意思。如果想要做集群,那就要把它做成是无状态的最好,这样才能大规模的分发和复用。
所以说使用的机制主要是Docker和K8S。当然,将FreeSWITCH放在K8S里面并不容易,首先我们先放到Docker里面,先完成容器化,然后再放到K8S里面。因为K8S它是一个网络,优点就是不知道它在哪台物理机上运行,想启动就启动,想关闭就关闭。但是FreeSWITCH、SIP,尤其是RTP,它们有一大堆的端口,就会比较麻烦。

那么,我们是怎么做的呢?我们使⽤Kamailio做Ingress,负责信令进来。Kamailio还是双机,然后它分发给后端的FreeSWITCH,FreeSWITCH不够用了就执行Scale Up,相反就Scale Down。
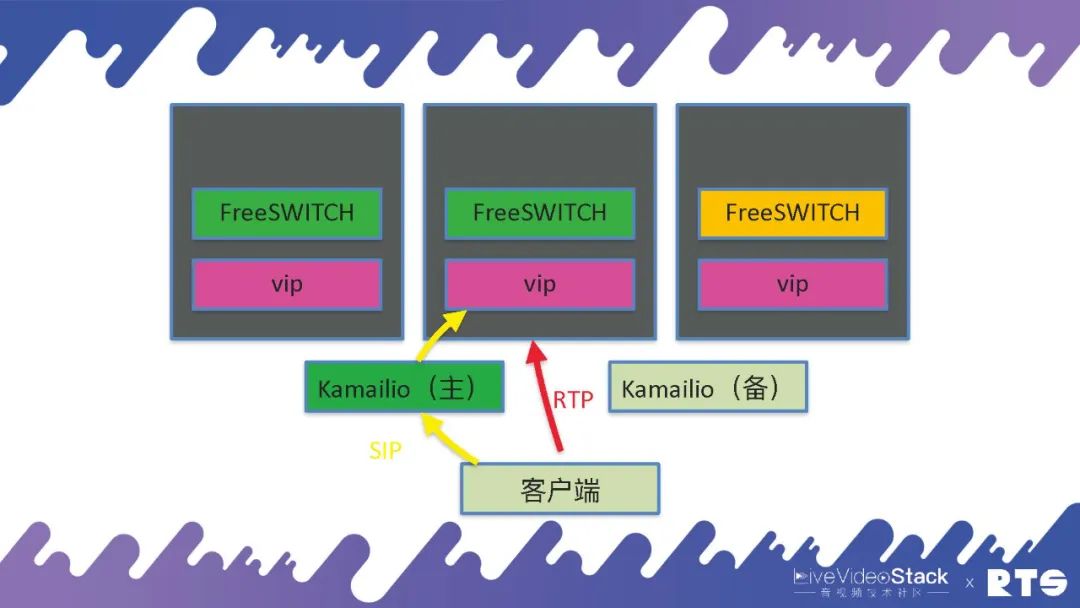
但是具体的我们使用了一个东西叫做VIP,这个VIP是我们自己写的一个协议,因为现在的K8S主要是针对HTTP来优化的,对SIP类的应用就会比较麻烦。所以我们就自己写了一个应用,在每台物理机或者虚拟机上,都有一个VIP的服务。当FreeSWITCH启动的时候,同样每台机器上也只启动一个FreeSWITCH,它告诉VIP打开一对端口,然后VIP就把这些端口通过iptables打开,就可以正常分发了。万一这台机器死了之后,端口就是空着不用也无所谓,因为FreeSWITCH也死了,不会有服务往这上面发了。当机器重启之后,端口仍旧还是使用这几个端口段,所以也没有问题。这种情况下RTP就是直接到FreeSWITCH,前端还是通过Kamailio进行分发SIP。

这种应用就是每个Node上只运⾏⼀个FreeSWITCH,每个Node上运⾏⼀个vip。当然,VIP这个东西叫做DaemonSet,每台机器上只起一个VIP服务,这个服务也在集群当中。通过这种方式我们就可以动态的打开SIP和RTP的端口,这样可以做弹性的伸缩。这是我们做的一些应用。

当然,如果一个Node 64核、128核,能不能运行多个FreeSWITCH?可以的,其实这样就需要按端口段来分开,可以做成两个Pod,一个占10000-20000,另一个占30000-50000。这样的话通过这种方式,保证两个FreeSWITCH同时启动的时候互不影响,同样管理也会更加复杂。
下面是在Kamailio中使用NATS的一些基本代码:


05 会议
下面还有一种就是会议。
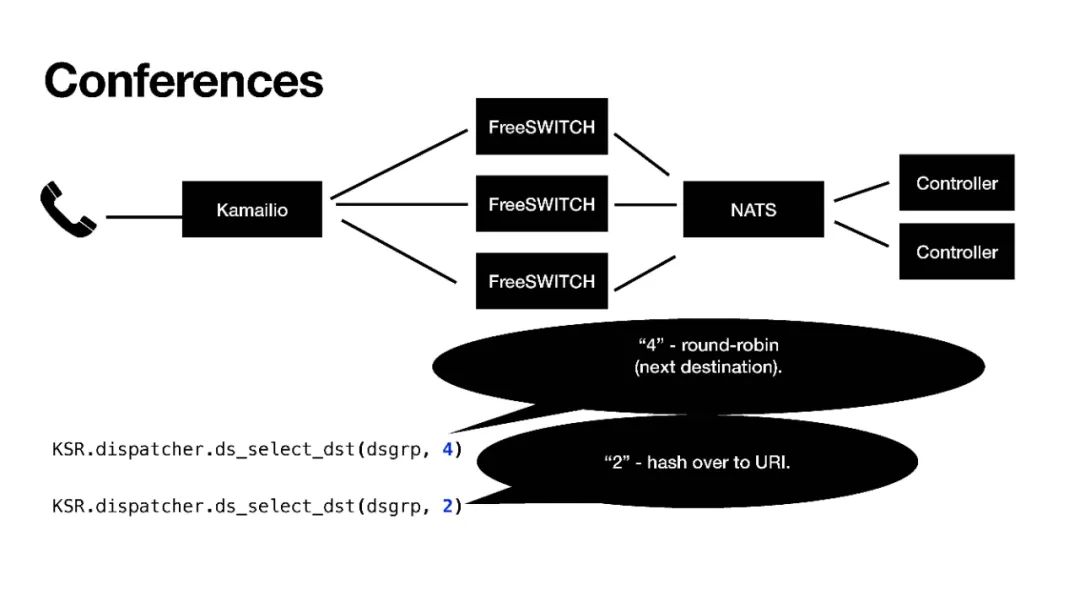
我们平常的负载分担分发是尽量平均的分发到不同的FreeSWITCH,这是最好的分发策略。但是会议不能,会议需要把呼入同一个会议号的,都分发到同一台FreeSWITCH上。这里我们用了Kamailio中一个“2”的策略,“hash over to URI”。

当然,实际使用的时候会议规模比较大,一台FreeSWITCH不能满足,我们需要放到多台FreeSWITCH上,这个时候我们就用了“7”这个策略,“hash over the content of PVs string”。我们可以自己创建一个字符串,只要是计算出来不同的终端,它在一个组内,通过分组,只要计算出来字符串是相同的,就会分配到同一台FreeSWITCH。
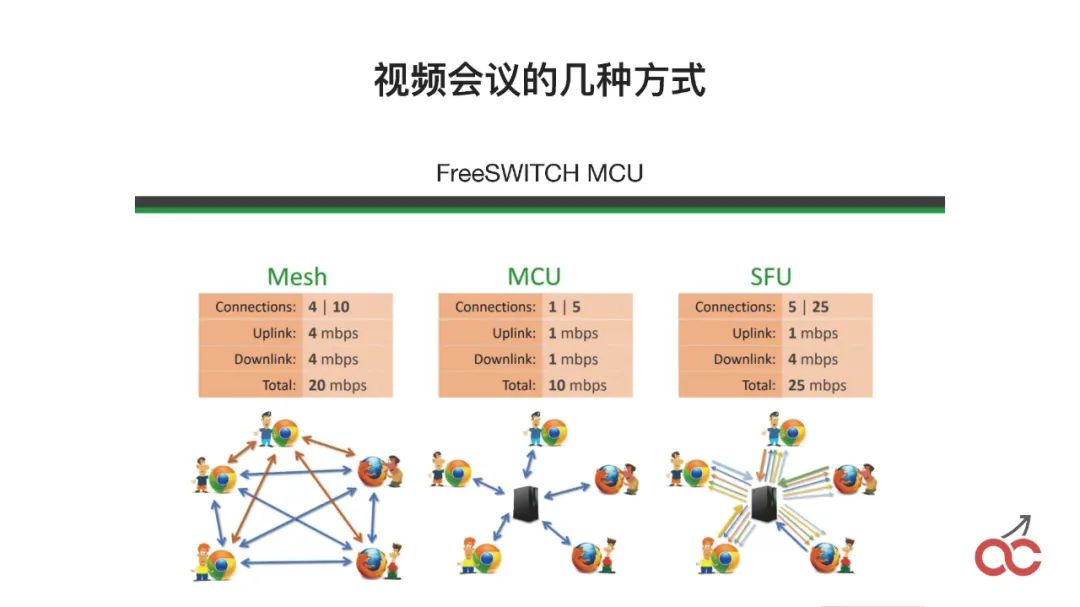
视频会议有这么几种方式:Mesh是无状态的,MCU就是所有的东西都通过中间融屏,SFU是通过它进行分发,不融屏。
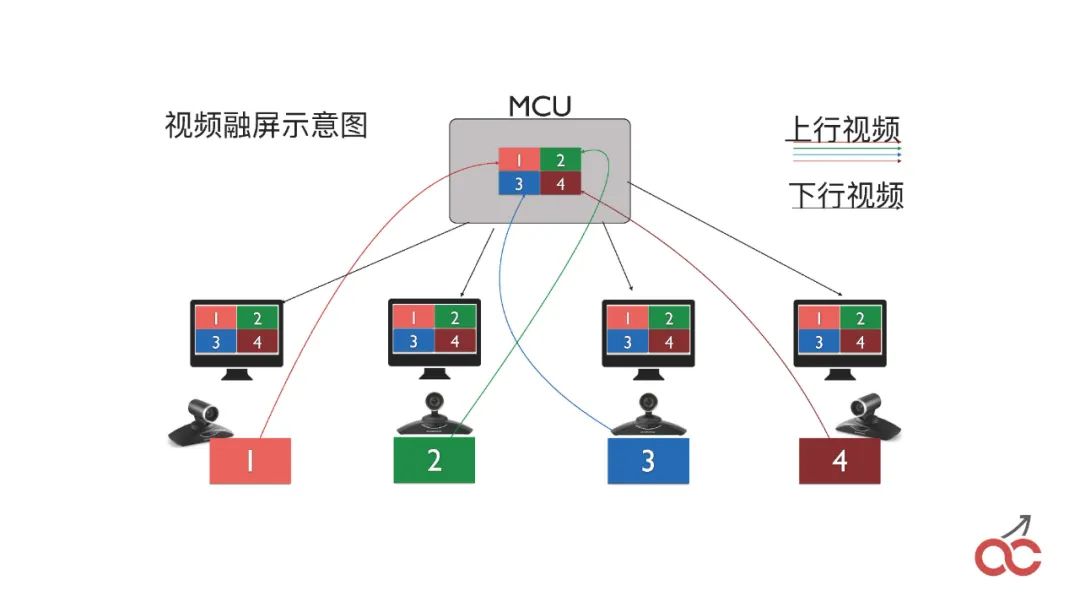
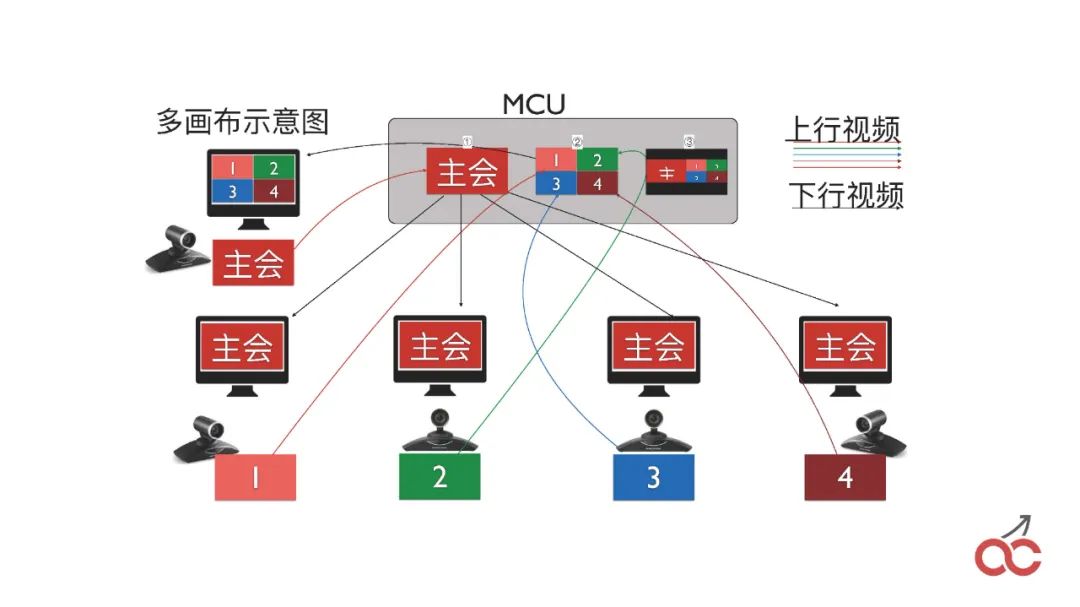
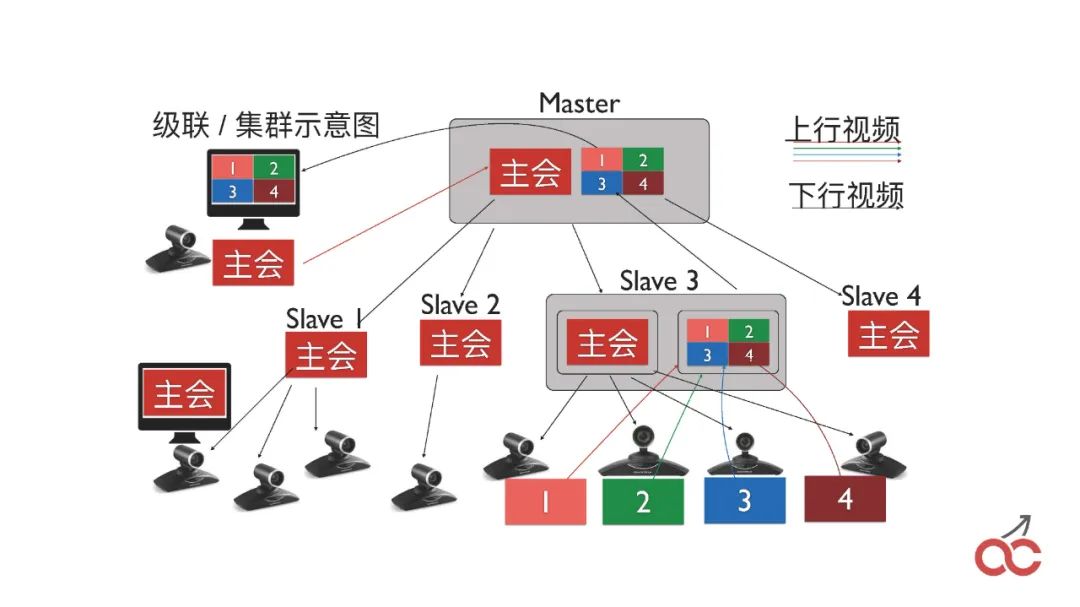
我们也会做会议的级联,通过多个FreeSWITCH级联来实现较大规模的会议。
级联也会出现一个问题,叫做“看对眼”,就是出限类似无限循环的效果,如上图中的样子。

那么,我们是怎么做的?我们在会议当中,首先我们说怎么将两个FreeSWITCH的会议串起来。
很简单,就是在第一台FreeSWITCH里面 conference 3000(会议号),然后呼叫另外一台FreeSWITCH也呼3000,另外一台FreeSWITCH收到呼叫以后,直接conference 3000 加入会议,这个时候就是把两个会议进行串起来。

串起来之后,我们就可以设置两个画布,第一个是“video_initial_canvas”,表示我把我的图像放在哪个canvas上;第二个是“video_initial_watching_canvas”,表示我看哪个canvas。

通过这种方式,我们也完成了MCU和SFU的互通。我们现在打通了Agora、TRTC以及MediaSoup之类的应用。
06 日志
最后一个我想说的就是日志。

日志很简单,都有一些现成的服务:
Homer是做SIP的日志的,它的实现原理就是FreeSWITCH或Kamailio插入一个Agent,会将收到的消息转发给它,将SIP的图画出来;Loki就是存放日志的,我们会把所有的日志都发给它;另外还有Zabix、Grafana、Promuthus。

这里面关键的一点是,每天成千上万路的通话并发,我们需要知道哪一路通话跟哪一路是相关的。所以说要有一个uuid,FreeSWITCH里面每一路通话都有一个uuid,这个UUID要跟call-id关联起来。通过call-id就可以找到对应的uuid,通过uuid就可以找到另外一条腿的uuid。

上面是呼入,呼出的时候使用的是这个参数:outbound-use-uuid-as-callid。

如果FreeSWITCH对外发出一路呼叫,在SIP当中的Call-ID和内部的uuid是一致的,这样就可以找到它们的对应关系,日志和SIP的对应关系。
这样的话,A进来,通过A的Call-ID就可以找到uuid,通过B的uuid就可以找到对应的Call-ID。通过Other-Leg-Unique-ID,这个在事件里面会有,或者Channel-Call-UUID,都能找到到对方,找到A和B。
07 总结

最后,简单的总结一下。通信的集群我们要用到各种各样的开源软件,要有双机、三机,弹性伸缩,包括⼀对⼀通话、呼叫中⼼及⾳视频会议、⽇志监控等场景。最终还是万变不离其宗,不管使用的是任何软件,它们的基本原理是不变的。
审核编辑:刘清
-
云原生AI服务怎么样2025-01-23 1271
-
云原生LLMOps平台作用2025-01-06 1049
-
如何选择云原生机器学习平台2024-12-25 1008
-
什么是云原生MLOps平台2024-12-12 1226
-
K8S学习教程(二):在 PetaExpress KubeSphere容器平台部署高可用 Redis 集群2024-07-03 1873
-
Helm部署MinIO集群2023-12-03 1812
-
只需 6 步,你就可以搭建一个云原生操作系统原型2022-09-15 11204
-
云原生技术概述 云原生火爆成为升职加薪核心必备2022-07-27 2108
-
redis集群的如何部署2020-05-29 1649
-
开放应用模型(OAM):全球首个云原生应用标准定义与架构模型2019-10-23 2443
-
Flink集群的部署方法2019-04-23 1876
-
Hadoop的集群环境部署说明2018-10-12 2670
-
Kubernetes Ingress 高可靠部署最佳实践2018-04-17 3054
全部0条评论

快来发表一下你的评论吧 !
