

分布式系统关键路径分析的原理和技术实现方案
通信网络
描述
随着对用户体验的不断追求,延迟分析成为大型分布式系统中不可或缺的一环。本文介绍了目前在线服务中常用的延迟分析方法,重点讲解了关键路径分析的原理和技术实现方案,实践表明此方案效果显著,在耗时优化方面发挥了重要作用,希望这些内容能够对有兴趣的读者产生启发,并有所帮助。
背景
近年来,互联网服务的响应延迟(latency)对用户体验的影响愈发重要,然而当前对于服务接口的延迟分析却没有很好的手段。特别是互联网业务迭代速度快,功能更新周期短,必须在最短的时间内定位到延迟瓶颈。然而,服务端一般都由分布式系统构成,内部存在着复杂的调度和并发调用关系,传统的延迟分析方法效率低下,难以满足当下互联网服务的延迟分析需求。
关键路径分析(Critical Path Tracing)作为近年来崛起的延迟分析方法,受到Google,Meta,Uber等公司的青睐,并在在线服务中获得了广泛应用。百度App推荐服务作为亿级用户量的大型分布式服务,也成功落地应用关键路径延迟分析平台,在优化产品延迟、保障用户体验方面发挥了重要的作用。本文介绍面向在线服务常用的延迟分析方法,并详细介绍关键路径分析的技术实现和平台化方案,最后结合实际案例,说明如何在百度App推荐服务中收获实际业务收益。
常用分布式系统延迟分析方法
当前业界常用的服务延迟分析有RPC监控(RPC telemetry),CPU剖析(CPU Profiling),分布式追踪(Distributed Tracing),下面以一个具体的系统结构进行举例说明:
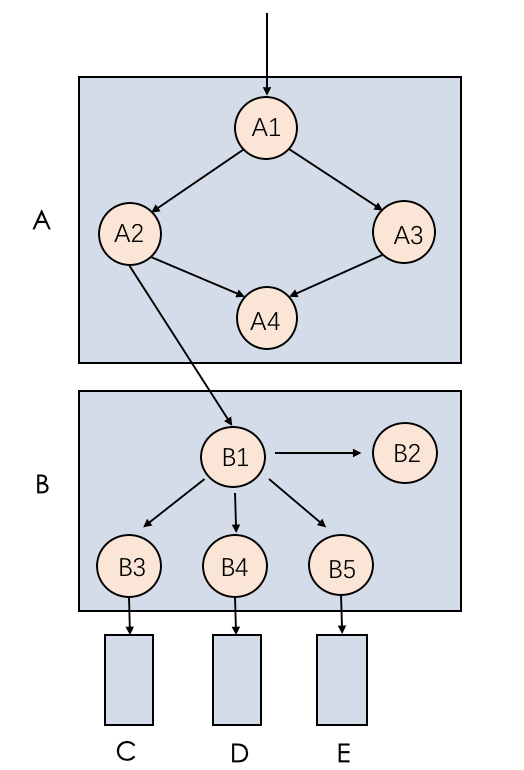
△图1 系统结构示例
A、B、C、D、E分别为五个系统服务,A1到A4、B1到B5分别为A、B系统内的子组件(可以理解为A、B系统内部进一步的细化组成部分),箭头标识服务或组件之间的调用关系。
2.1 RPC监控
RPC是目前微服务系统之间常用的调用方式,业界主要开源的RPC框架有BRPC、GRPC、Thrift等。这些RPC框架通常都集成了统计打印功能,打印的信息中含有特定的名称和对应的耗时信息,外部的监控系统(例如:Prometheus)会进行采集,并通过仪表盘进行展示。
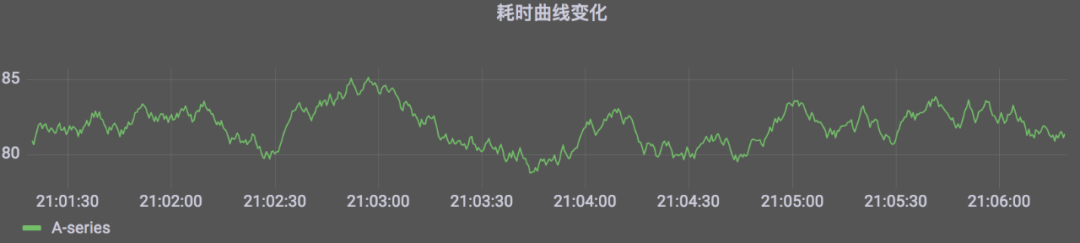
△图2 RPC耗时监控UI实例
此分析方式比较简单直接,如果服务之间的调用关系比较简单,则此方式是有效的,如果系统复杂,则基于RPC分析结果进行的优化往往不会有预期的效果。如图1,A调用B,A2和A3是并行调用,A3内部进行复杂的CPU计算任务,如果A2的耗时高于A3,则分析A->B的RPC延时是有意义的,如果A3高于A2,则减少A->B的服务调用时间对总体耗时没有任何影响。此外RPC分析无法检测系统内部的子组件,对整体延迟的分析具有很大的局限性。
2.2 CPU Profiling
CPU分析是将函数调用堆栈的样本收集和聚合,高频出现的函数认为是主要的延迟路径,下图是CPU火焰图的展示效果:
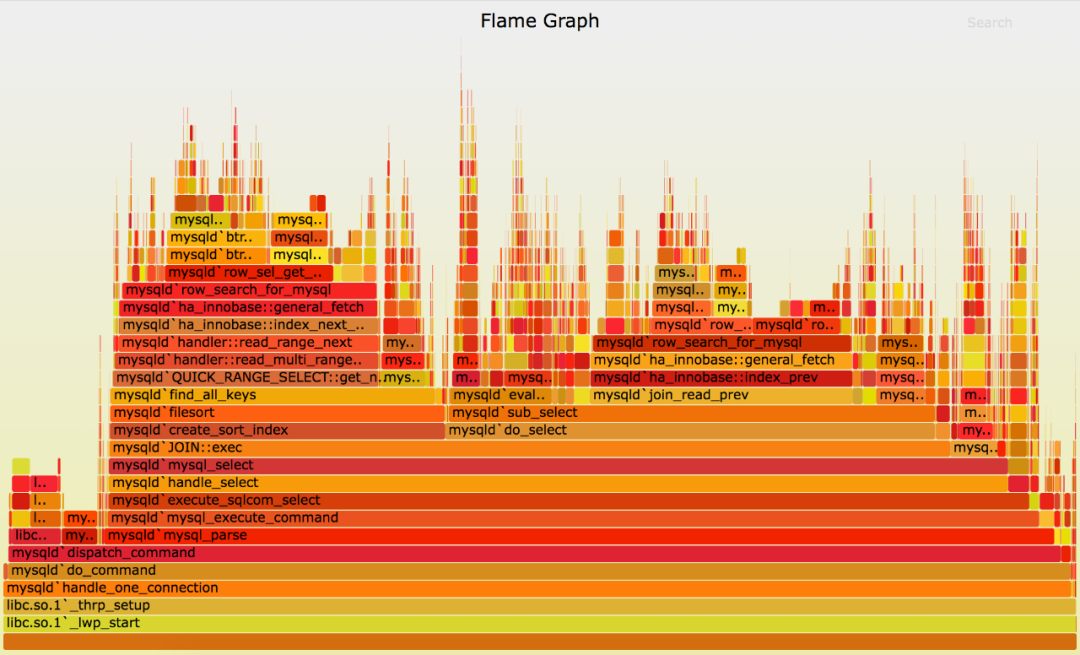
△图3 cpu火焰图
水平的宽度表示抽样的次数,垂直方向表示调用的关系,火焰图通常是看顶层的哪个函数宽度最大,出现“平顶”表示该函数存在性能问题。
CPU Profiling可以解决上面说的RPC监控的不足,然而由于依然无法知晓并行的A2和A3谁的耗时高,因此按照RPC链路分析结果还是按照CPU分析的结果进行优化哪个真正有效果将变得不确定,最好的方式就是都进行优化,然而这在大型复杂的系统中成本将会变得很大。可见CPU Profiling同样具有一定的局限性。
2.3 分布式追踪
分布式追踪目前在各大公司都有了很好的实践(例如Google的Dapper,Uber的Jaeger)。
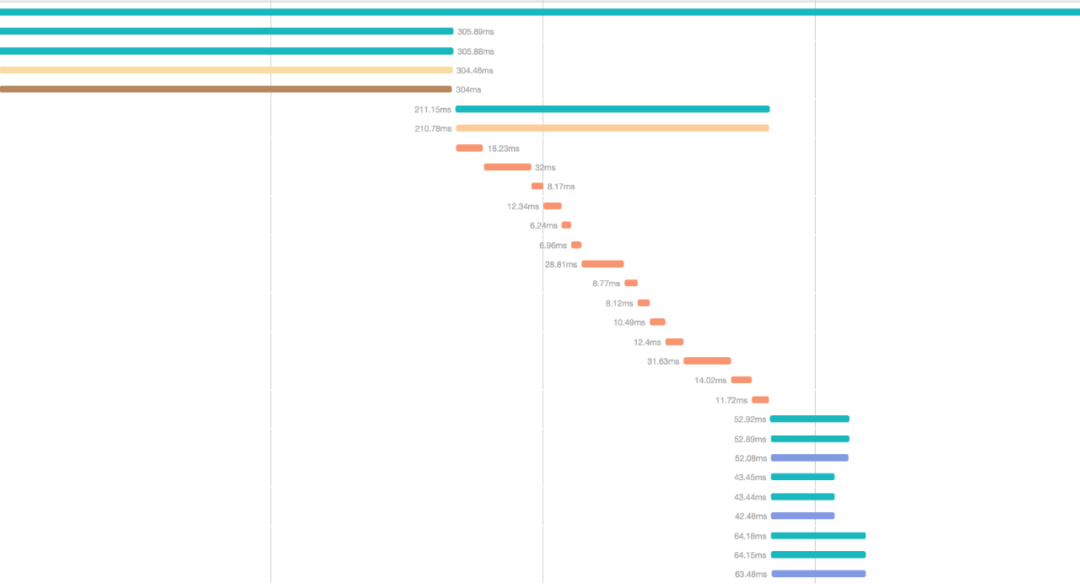
△图4 分布式追踪效果示例
分布式追踪将要追踪的“节点”通过span标识,将spans按照特定方式构建成trace,效果如图4所示,从左到右表示时间线上的不同节点耗时,同一个起始点表示并发执行。这需要收集所有跨服务请求的信息,包括具体的时间点以及调用的父子关系,从而在外部还原系统调用的拓扑关系,包含每个服务工作的开始和结束时间,以及服务间是并行运行还是串行运行的。
通常,大多数分布式跟踪默认情况下包括RPC访问,没有服务内部子组件信息,这需要开发人员根据自身系统的结构进行补全,然而系统内部自身运行的组件数目有时过于庞大,甚者达到成百上千个,这就使得成本成为了分布式跟踪进行详细延迟分析的主要障碍,为了在成本和数据量之间进行权衡,往往会放弃细粒度的追踪组件,这就使得分析人员需要花费额外的精力去进一步分析延迟真正的“耗费点”。
下面介绍关键路径分析的基本原理和实际的应用。
关键路径分析
3.1 介绍
关键路径在服务内部定义为一条耗时最长的路径,如果将上面的子组件抽象成不同的节点,则关键路径是由一组节点组成,这部分节点是分布式系统中请求处理速度最慢的有序集合。一个系统中可能有成百上千个子组件,但是关键路径可能只有数十个节点,这样数量级式的缩小使得成本大大降低。我们在上图的基础上加上各个子模块的耗时信息。
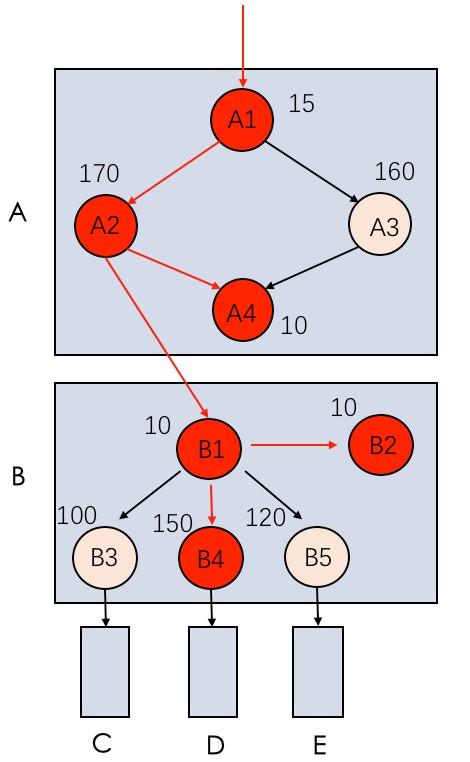
△图5 加上耗时信息的示例系统结构
如图5所示,在B中B1并行调用B3、B4、B5,延迟分别为100,150,120,然后再调用内部的B2,进行返回,关键路径为B1->B4->B2,延迟为10 + 150 + 10 = 170,在A中A1并行调用A2,A3。A2和A3都完成后再调用A4,然后返回,关键路径为A1->A2->A4,延迟为15 + 170 + 10 = 195 ,因此这个系统的关键路径为红色线条的路径 A1->A2->B1->B4->B2->A4。
通过这个简单的分布式系统结构表述出关键路径,其描述了分布式系统中请求处理速度最慢步骤的有序列表。可见优化关键路径上的节点肯定能达到降低整体耗时的目的。实际系统中的关键路径远比以上描述的复杂的多,下面进一步介绍关键路径分析的技术实现和平台化方案。
3.2 实际应用解决方案
关键路径数据的采集到可视化分析的流程如图所示:
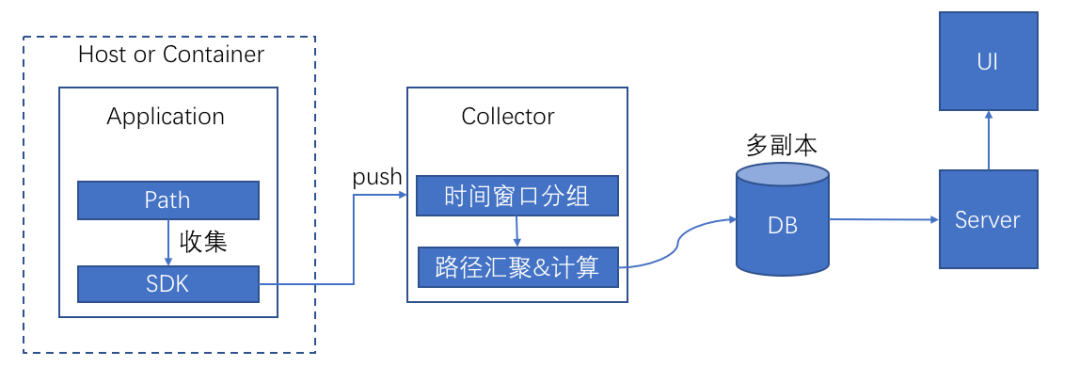
△图6 数据处理流程
3.2.1 核心关键路径的产出和上报
关键路径由服务自身进行产出,一般大型分布式服务都会采用算子化执行框架,只要集成到框架内部,所有依赖的服务都可以统一产出关键路径。
对于算子化执行框架,考虑到如下简单的图结构:
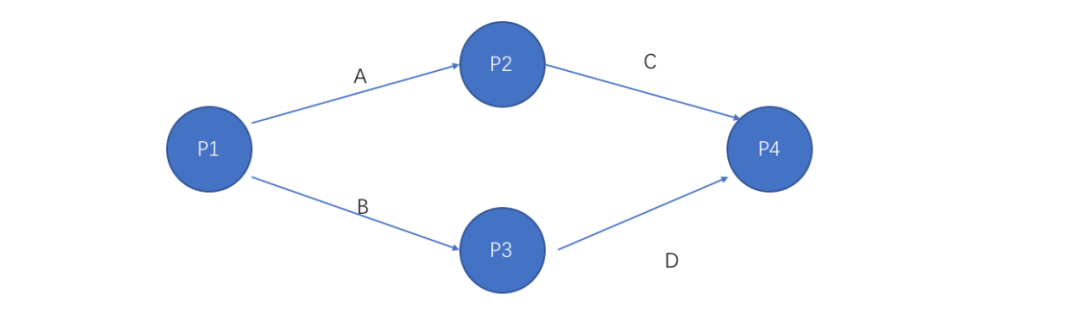
△图7 一种简单的图结构
P1-P4是4个策略算子,按照图示调度执行。采集SDK收集每个算子开始和结束的运行时刻,汇总为关键路径基础数据上报。
3.2.2 核心关键路径的汇聚和计算
一个服务内部的关键路径往往反映不了整个分布式系统延时的常态情况,这就需要将不同服务内部关键进行汇聚。这里的汇聚是按照时间段进行汇聚,这就需要collector收到数据后按照上传携带过来的时间点分到对应时间的窗口内,收集完成后进行各种延时指标的计算以及关键路径的汇聚,这里有三种汇聚方式:
1、节点关键路径汇聚
这里是将系统的关键路径拼接到一起,组成一条完整路径,将各个节点进行汇聚,选择出现次数最多的路径作为最“核心”的关键路径。
2、服务关键路径汇聚
节点关键路径是节点粒度的表示形态,然而在一个系统中服务的路径关系是怎样的呢?这就需要服务关键路径来表示。为了更好的表征服务内部的耗时情况,对节点进行聚合抽象。将所有计算型节点统一归为一个叫inner的节点,作为起始节点,其他访问外部服务的节点不变,在重新转换后的路径中选择出现次数最多的路径作为服务关键路径,聚合后的路径可以标识服务“自身”和“外部”的延时分布情况。
3、平铺节点类型汇聚
这部分主要是对于核心路径比较分散的子节点,例如B中B1访问B3/B4/B5等多个下游(在实际的系统中可能有数十个节点出现在关键路径中,但是没有一个节点有绝对的核心占比,各个节点在关键路径中相对比较分散,且经常周期性改变),对这种情况直接统计并筛选出核心占比>x%(x%根据特定需求进行确定,x越小则收集到的关键节点越精细)的节点,需要注意的是这里是平铺取的节点,并不是一条“核心”的关键路径。
3.2.3 核心关键路径的存储和展示
数据库存储的是计算好的结果,以时间、用户类型、流量来源等作为查询关键字,方便进行多维度分析。这里使用OLAP Engine进行存储,方便数据分析和查询。
展示的内容主要有以下几部分:
核心占比:节点出现在关键路径中的概率
核心贡献度:节点出现在关键路径中时,自身耗时占整个路径总耗时的比例
综合贡献度:核心占比和核心贡献度两者相乘,作为综合衡量的标准
均值:节点耗时的平均值
分位值:节点耗时的不同分位值。分位值是统计学中的概念,即把所有的数值从小到大排序,取前N%位置的值即为该分位的值,常用的有50分位、80分位、90分位等
核心占比高贡献度很低或者贡献度高占比很低的节点优化的效果往往不是很显著,因此使用综合贡献度做为核心占比和核心贡献度的综合考量,这个指标高的节点是我们需要重点关注的,也是优化收益较大的。
从耗时优化的角度出发,这里有两个主要的诉求,一个是查询某个时间段的关键路径,依此来指导进行特定节点或阶段的优化。另一个是需要进行关键路径的对比,找到diff的节点,挖掘具体的原因来进行优化,整体延时的退化往往是由于特定节点的恶化造成的,这里的对比可以是不同时间、不同地域、甚至是不同流量成分的对比,这样为延迟分析提供了多维度的指导依据。
关键路径的效果如图8所示,在页面上可以按照特定维度进行排序,便于进一步的筛选。

△图8 核心关键路径示例
应用
百度App推荐系统内部建设了关键路径延迟分析平台Focus,已上线1年多,成功支持了日常的耗时分析和优化工作,保证了百度App Feed流推荐接口的毫秒级响应速度,提供用户顺滑的反馈体验。获得研发,运维和算法团队的一致好评。
以推荐服务的一个实际线上问题举例,某天监控系统发现系统出口耗时突破监控阈值,关键路径延迟分析平台自动通过服务关键路径定位到是某个服务B出了问题,然后通过观察服务B的节点关键路径发现是节点X有问题,然而节点X下游请求的是多个下游,这时通过平铺节点类型发现平时耗时比较低的队列Y延时突增,核心占比和贡献度都异常高,通知下游负责的owner进行定位,发现确实是服务本身异常,整个定位过程全自动化,无需人工按个模块排查。
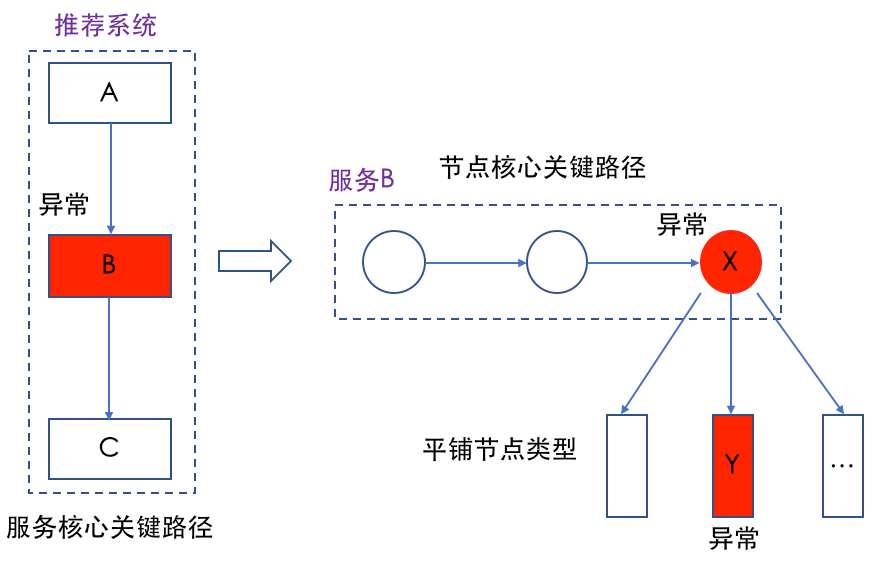
△图9 系统延迟异常后的自动定位分析过程
总结
在当下大型分布式系统中,服务接口的低响应延迟是保证用户体验的重要关键。各大公司也纷纷投入大量精力来优化延时,然而复杂的系统结构使得优化难度较大,这就需要借助创新的优化方法。本文通过具体的例子介绍了关键路径分析的原理,在百度App推荐系统中实际应用落地的平台化方案,最后分享了实际案例。延迟耗时分析方向还有很多新的发展方向和创新空间,也欢迎对该方向感兴趣的业界同仁一起探讨。
编辑:黄飞
- 相关推荐
- 热点推荐
- 分布式系统
-
分布式光伏发电监测系统技术方案2025-08-22 3592
-
分布式无纸化交互系统的实现原理2023-09-04 1471
-
OpenHarmony 分布式硬件关键技术2023-08-24 826
-
如何高效完成HarmonyOS分布式应用测试?2021-12-13 2394
-
HDC2021技术分论坛:分布式调试、调优能力解决方案2021-11-22 1867
-
HDC2021技术分论坛:跨端分布式计算技术初探2021-11-15 2467
-
HDC技术分论坛:分布式调试、调优能力解决方案2021-10-28 2807
-
分布式电源对配电系统的影响分析2021-09-29 1568
-
Qorvo分布式Wi-Fi网格解决方案2020-11-02 2838
-
如何设计分布式干扰系统?2019-08-08 2610
-
分布式能源系统当微型电网技术应用2011-06-13 4154
-
GL Studio的分布式虚拟训练系统关键技术2011-03-22 975
-
分布式软件系统2009-07-22 5425
-
基于多Agent 技术的分布式测控系统研究2009-06-01 786
全部0条评论

快来发表一下你的评论吧 !
