

YOLOv5解析之downloads.py 代码示例
编程语言及工具
描述
前言
代码仓库地址:https://github.com/Oneflow-Inc/one-yolov5欢迎star one-yolov5项目 获取最新的动态。如果您有问题,欢迎在仓库给我们提出宝贵的意见。如果对您有帮助,欢迎来给我Star呀~
源码解读:utils/augmentations.py
这个文件主要是负责从github/googleleaps/google drive 等网站或者云服务器上下载所需的一些文件。由于微信会吃掉一些超链接影响阅读,欢迎大家查看原始文档网站解读文章:https://start.oneflow.org/oneflow-yolo-doc/source_code_interpretation/utils/downloads_py.html
是一个工具类,代码比较简单,函数也比较少,主要难点还是在于一些包可能大家不是很熟悉,下面一起来学习下。
这个文件比较重要的是两个函数:safe_download和attempt_download。在train.py或者yolo.py等文件中都会用到。
1. 导入需要的包
""" Download utils """ import os # 与操作系统进行交互的模块 import platform # 提供获取操作系统相关信息的模块 import shutil # Python的高阶文件操作模块 import subprocess # 子进程定义及操作的模块 import time # 时间模块 import urllib # 用于操作网页 url 并对网页的内容进行抓取处理 如urllib.parse: 解析url from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块 from zipfile import ZipFile # 导入文件解压模块 import oneflow as flow # 导入深度学习框架oneflow包 import requests # 通过urllib3实现自动发送HTTP/1.1请求的第三方模块
2. gsutil_getsize
这个函数是用来返回网站链接 url 对应文件的大小。
def gsutil_getsize(url=""):
"""用在downloads.py的print_mutation函数当中 计算某个url对应的文件大小
用于返回网站链接url对应文件的大小,注意单位是bytes
gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du
"""
# 创建一个子进程在命令行执行 gsutil du url 命令(访问 Cloud Storage) 返回执行结果(文件)
# gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du
s = subprocess.check_output(f"gsutil du {url}", shell=True).decode("utf-8")
return eval(s.split(" ")[0]) if len(s) else 0 # bytes
3. safe_download、attempt_download
这两个函数主要是用来从 github 或者 googleleaps 云服务器中下载文件的,主要是下载权重文件。
one-yolov5 仓库中 attempt_download 函数调用 safe_download 函数。
3.1 safe_download
这个函数是用来下载 url(github) 或者 url2(谷歌云服务器) 网页路径对应的文件,
通常是下载权重文件,经常用在 attempt_download 函数中,代码如下:
def safe_download(file, url, url2=None, min_bytes=1e0, error_msg=""):
"""经常用在 attempt_download 函数中,也可以单独使用
下载 url/url2 网页路径对应的文件
Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
@params file: 要下载的文件名
@params url: 第一个下载地址 一般是github
@params url2: 第二个下载地址(第一个下载地址下载失败后使用) 一般是googleleaps等云服务器
@params min_bytes: 判断文件是否下载下来 只有文件存在且文件大小要大于min_bytes才能判断文件已经下载下来了
@params error_msg: 文件下载失败的显示信息 初始化默认为空
"""
# Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
file = Path(file)
assert_msg = f"Downloaded file '{file}' does not exist or size is < min_bytes={min_bytes}"
try: # url1 y: 尝试从 url 中下载文件 一般是 github 链接
print(f"Downloading {url} to {file}...")
// 使用 oneflow.hub.download_url_to_file 下载 url 链接对应的文件,
// 关于oneflow.hub 模块讲解可以看:https://www.bilibili.com/video/BV1YG4y1B72u/?spm_id_from=333.999.0.0
flow.hub.download_url_to_file(url, str(file))
# 判断文件是否下载下来了 (文件存在且文件大小要大于 min_bytes )
assert file.exists() and file.stat().st_size > min_bytes, assert_msg # check
except Exception as e: # url2 url1 不行就尝试从 url2 中下载文件 一般是googleleaps(云服务器)
# 移除之前下载失败的不完整文件
file.unlink(missing_ok=True) # remove partial downloads
print(f"ERROR: {e}
Re-attempting {url2 or url} to {file}...")
os.system(f"curl -L '{url2 or url}' -o '{file}' --retry 3 -C -") # curl download, retry and resume on fail
finally:
# 检查文件是否下载下来了 或 文件大小是否小于min_bytes
if not file.exists() or file.stat().st_size < min_bytes: # check
# 下载失败 移除下载失败的不完整文件 remove partial downloads
file.unlink(missing_ok=True) # remove partial downloads
# 打印错误信息
print(f"ERROR: {assert_msg}
{error_msg}")
print("")
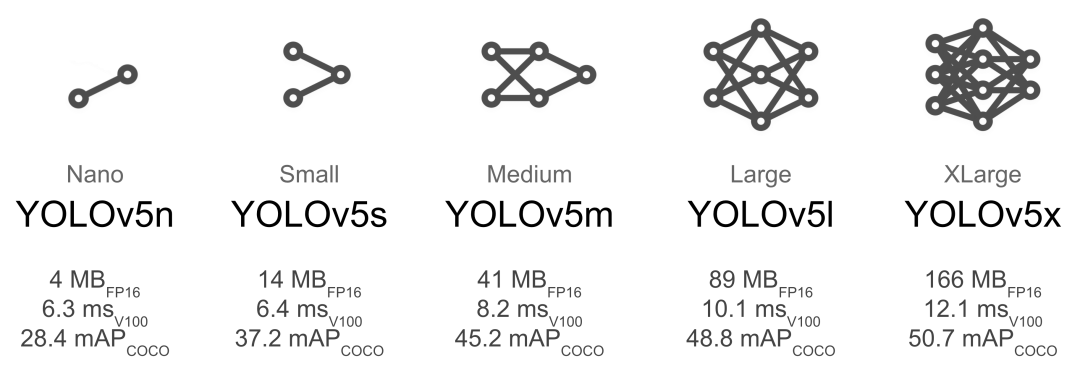
url = "https://github.com/Oneflow-Inc/one-yolov5/releases/download/v1.0.0/model_comparison.png"
safe_download("op.png", url)
Downloading https://github.com/Oneflow-Inc/one-yolov5/releases/download/v1.0.0/model_comparison.png to op.png... 0%| | 0.00/118k [00:00from PIL import Image display(Image.open("op.png")) # 显示下载的图片image
3.2 attempt_download
这个函数是实现从几个云平台 (github/googleleaps云服务器/xxx) 下载文件(在one-yolov5中一般是预训练模型),
会调用上面的 safe_download 函数。会用在 experimental.py 中的 attempt_load 函数和 train.py 中,都是用来下载预训练权重。代码详解如下:
def attempt_download(file, repo="Oneflow-Inc/one-yolov5"): # from utils.downloads import *; attempt_download()
"""用在attempt_download函数中 下载 url/url2 网页路径对应的文件 Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes :params file: 要下载的文件名 :params url: 第一个下载地址 一般是 github :params url2: 第二个下载地址(第一个下载地址下载失败后使用) 一般是googleleaps 等云服务器 :params min_bytes: 判断文件是否下载下来 只有文件存在且文件大小要大于min_bytes 才能判断文件已经下载下来了 :params error_msg: 文件下载失败的显示信息 初始化默认’‘ """ # Attempt file download if does not exist file = Path(str(file).strip().replace("'", "")) if not file.exists(): # 尝试从url中下载文件 一般是github # URL specified # urllib.parse: 解析url # .unquote: 对url进行解码 decode '%2F' to '/' etc. name = Path(urllib.parse.unquote(str(file))).name # decode '%2F' to '/' etc. # 如果解析的文件名是http:/ 或 https:/ 开头就直接下载 if str(file).startswith(("http:/", "https:/")): # download # url: 下载路径 url 对应的文件 url = str(file).replace(":/", "://") # Pathlib turns :// -> :/ # name: 要下载的文件名 file = name.split("?")[0] # parse authentication https://url.com/file.txt?auth... # 如果文件已经在本地存在了就不用下载了 if Path(file).is_file(): print(f"Found {url} locally at {file}") # file already exists else: safe_download(file=file, url=url, min_bytes=1e5) # 下载文件 return file # GitHub assets file.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required) try: # 利用 github api 获取最新的版本相关信息 这里的 response 是一个字典 response = requests.get(f"https://api.github.com/repos/{repo}/releases/latest").json() # github api assets = [x["name"] for x in response["assets"]] # release assets, i.e. ['yolov5s', 'yolov5m', ...] tag = response["tag_name"] # i.e. 'v1.0' except: # fallback plan 获取失败 就退而求其次 直接利用 git 命令强行补齐版本信息 assets = [ "yolov5n.zip", "yolov5s.zip", "yolov5m.zip", "yolov5l.zip", "yolov5x.zip", "yolov5n6.zip", "yolov5s6.zip", "yolov5m6.zip", "yolov5l6.zip", "yolov5x6.zip", ] try: # 创建一个子进程在命令行执行 git tag 命令(返回版本号 版本号信息一般在字典最后一个 -1) 返回执行结果(版本号 tag) tag = subprocess.check_output("git tag", shell=True, stderr=subprocess.STDOUT).decode().split()[-1] except: # 如果还是失败 就强行自己补一个版本号 tag='v1.1' ,比如这里在 one-yolov5 中直接补当前的最新版本 v1.1. tag = "v1.1" # current release if ".zip" not in name: name = name + ".zip" file = Path(name) if name in assets: safe_download( file, url=f"https://github.com/{repo}/releases/download/{tag}/{name}", # url2=f'https://storage.googleapis.com/{repo}/ckpt/{name}', # backup url (optional) min_bytes=1e5, error_msg=f"{file} missing, try downloading from https://github.com/{repo}/releases/", ) if ".zip" in name: new_dir = Path(name[:-4]) else: new_dir = Path(name) if not os.path.exists(new_dir): # 判断文件夹是否存在 os.mkdir(new_dir) # 新建文件夹 if ".zip" in name: print("unzipping... ", end="") # ZipFile(new_file).extractall(path=file.parent) # unzip f = ZipFile(file) f.extractall(new_dir) os.remove(file) # remove zip tmp_dir = "/tmp/oneyolov5" if os.path.isdir(tmp_dir): shutil.rmtree(tmp_dir) if ".zip" in name: path1 = os.path.join(name[:-4], name[:-4]) else: path1 = os.path.join(name, name) shutil.copytree(path1, tmp_dir) shutil.rmtree(new_dir) shutil.copytree(tmp_dir, new_dir) shutil.rmtree(tmp_dir) return str(file)attempt_download("yolov5n")Downloading https://github.com/Oneflow-Inc/one-yolov5/releases/download/v1.0.0/yolov5n.zip to yolov5n.zip... 0%| | 0.00/3.53M [00:004. get_token & gdrive_download(没使用)
这两个函数是实现从 google drive 上下载压缩文件并将其解压, 再删除掉压缩文件。但是这好像并没有在代码中使用,所以这两个函数可以随便了解下就好,主要还是要掌握上面的两个下载函数用的比较多。
4.1 get_token
这个函数实现从 cookie中 获取令牌 token 。会在 gdrive_download 中被调用。
get_token函数代码:
def get_token(cookie="./cookie"):
"""在gdrive_download中使用 实现从cookie中获取令牌token """ with open(cookie) as f: for line in f: if "download" in line: return line.split()[-1] return ""4.2 gdrive_download
这个函数实现从 google drive 上下载压缩文件并将其解压, 再删除掉压缩文件。这个函数貌似没用到,随便看下就好。
gdrive_download函数代码:
def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'): """ 实现从 google drive 上下载压缩文件并将其解压, 再删除掉压缩文件 :params id: url的?后面的 id 参数的参数值 :params file: 需要下载的压缩文件名 """ t = time.time() # 获取当前时间 file = Path(file) # Path将str转换为Path对象 cookie = Path('cookie') # gdrive cookie print(f'Downloading https://drive.google.com/uc?export=download&id={id} as {file}... ', end='') file.unlink(missing_ok=True) # 移除已经存在的文件(可能是下载失败/下载不完整的文件) cookie.unlink(missing_ok=True) # 移除已经存在的cookie # 尝试下载压缩文件 out = "NUL" if platform.system() == "Windows" else "/dev/null" # 使用 cmd 命令从 google drive 上下载文件 os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={id}" > {out}') if os.path.exists('cookie'): # 如果文件较大 就需要有令牌 get_token (存在 cookie 才有令牌)的指令 s 才能下载 # get_token() 函数在上面定义了,用于获取当前 cookie 的令牌 token s = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={get_token()}&id={id}" -o {file}' else: # 小文件就不需要带令牌的指令 s 直接下载就行 s = f'curl -s -L -o {file} "drive.google.com/uc?export=download&id={id}"' # 执行下载指令 s 并获得返回值 如果 cmd 命令执行成功 则 os.system()命令会返回 0 r = os.system(s) cookie.unlink(missing_ok=True) # 再次移除已经存在的cookie # 下载错误检测 如果 r != 0 则下载错误 if r != 0: file.unlink(missing_ok=True) # 下载错误 移除下载的文件(可能不完整或者下载失败) print('Download error ') # raise Exception('Download error') return r # 如果是压缩文件 就解压 file.suffix 方法可以获取 file 文件的后缀 if file.suffix == '.zip': print('unzipping... ', end='') os.system(f'unzip -q {file}') # cmd命令执行解压命令 file.unlink() # 移除 .zip 压缩文件 print(f'Done ({time.time() - t:.1f}s)') # 打印下载 + 解压过程所需要的时间 return r总结
这个文件的代码比较少,真正有用的函数也比较少。
也就是safe_download和attempt_download两个函数比较重要,大家重点掌握这两个函数即可。
Reference
【YOLOV5-5.x 源码解读】google_utils.py
编辑:黄飞
-
【YOLOv5】LabVIEW+YOLOv5快速实现实时物体识别(Object Detection)含源码2023-03-13 3604
-
Yolov5算法解读2023-05-17 14461
-
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)2023-08-21 2414
-
在K230上部署yolov5时 出现the array is too big的原因?2025-05-28 824
-
在k230上使用yolov5检测图像卡死,怎么解决?2025-08-11 430
-
怎样使用PyTorch Hub去加载YOLOv5模型2022-07-22 3586
-
YOLOv5网络结构解析2022-10-31 6782
-
使用Yolov5 - i.MX8MP进行NPU错误检测是什么原因?2023-03-31 981
-
如何YOLOv5测试代码?2023-05-18 669
-
基于YOLOv5的目标检测文档进行的时候出错如何解决?2023-09-18 624
-
YOLOv5在OpenCV上的推理程序2022-11-02 3549
-
YOLOv5全面解析教程:计算mAP用到的numpy函数详解2022-11-21 3746
-
使用旭日X3派的BPU部署Yolov52023-04-26 2096
-
yolov5和YOLOX正负样本分配策略2023-08-14 4805
-
yolov5训练部署全链路教程2025-07-25 2212
全部0条评论

快来发表一下你的评论吧 !
