

SRD是什么呢?有哪些特点?
描述
SRD(Scalable Reliable Datagram,可扩展的可靠数据报文),是AWS年推出的协议,旨在解决亚马逊的云性能挑战。它是专为AWS数据中心网络设计的、基于Nitro芯片、为提高HPC性能实现的一种高吞吐、低延迟的网络传输协议。 
SRD 不保留数据包顺序,而是通过尽可能多的网络路径发送数据包,同时避免路径过载。为了最大限度地减少抖动并确保对网络拥塞波动的最快响应,在 AWS 自研的 Nitro chip 中实施 SRD。
SRD 由 EC2 主机上的 HPC/ML 框架通过 AWS EFA(Elastic Fabric Adapter,弹性结构适配器)内核旁路接口使用。
SRD的特点:
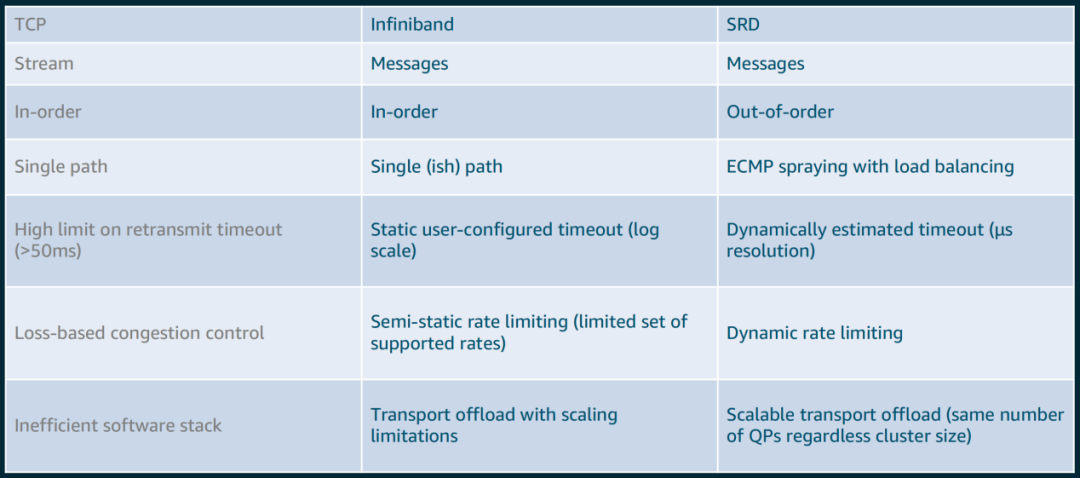
1)不保留数据包顺序,交给上层消息传递层处理
2)通过尽可能多的网络路径发包,利用ECMP标准,发端控制数据包封装来控制ECMP路径选择,实现多路径的负载平衡
3)自有拥塞控制算法,基于每个连接动态速率限制,结合RTT(Round Trip Time)飞行时间来检测拥塞,可快速从丢包或链路故障中恢复
4)由于无序发包以及不支持分段,SRD传输时所需要的QP(队列对)显著减少
为什么不是TCP?
TCP 是 IP 网络中可靠数据传输的主要手段,自诞生以来一直很好地服务于 Internet,并且仍然是大多数通信的最佳协议。
但是,它不适合对延迟敏感的处理,TCP 在数据中心最好的往返延迟差不多是 25us,因拥塞(或链路故障)等待导致的异常值可以是 50 ms,甚至数秒,带来这些延迟的主要原因是TCP丢包之后的重传机制。
另外,TCP传输是一对一的连接,就算解决了时延的问题,也难在故障时重新快速连线。 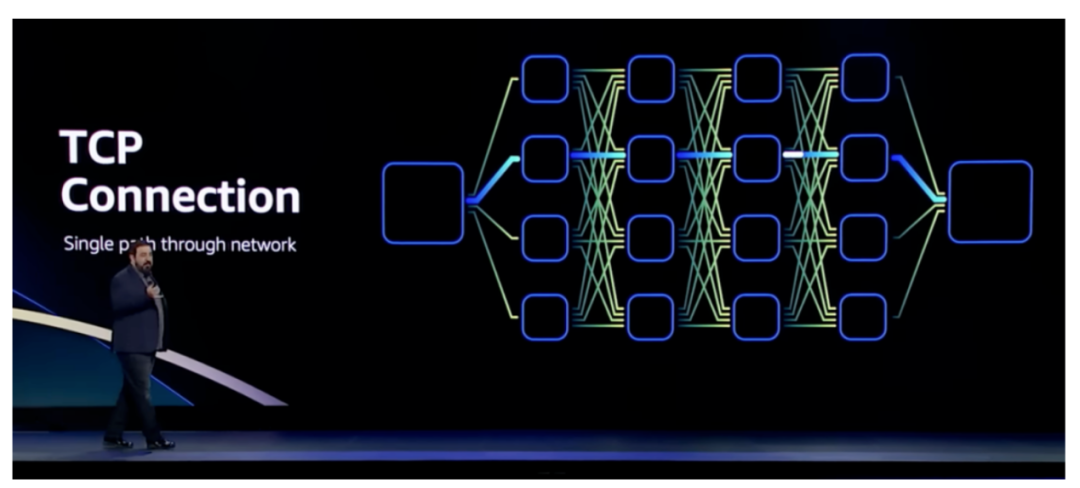
TCP 是通用协议,没有针对HPC场景进行优化,早在2020 年,AWS 已经提出需要移除TCP。
为什么不是RoCE?
InfiniBand 是一种用于高性能计算的流行的高吞吐量低延迟互连,它支持内核旁路和传输卸载。RoCE(RDMA over Converged Ethernet),也称为 InfiniBand over Ethernet,允许在以太网上运行 InfiniBand 传输,理论上可以提供 AWS 数据中心中 TCP 的替代方案。
EFA 主机接口与 InfiniBand/RoCE 接口非常相似。但是 InfiniBand 传输不适合 AWS 可扩展性要求。原因之一是 RoCE 需要 PFC(优先级流量控制),这在大型网络上是不可行的,因为它会造成队头阻塞、拥塞扩散和偶尔的死锁。
PFC 更适合比 AWS 规模小的数据中心。此外,即使使用 PFC,RoCE 在拥塞(类似于 TCP)和次优拥塞控制下仍会遭受 ECMP(等价多路径路由)冲突。
为什么是SRD?
SRD是专为AWS设计的可靠的、高性能的、低延迟的网络传输。这是数据中心网络数据传输的一次重大改进。SRD受InfiniBand可靠数据报的启发,结合大规模的云计算场景下的工作负载,SRD也经过了很多的更改和改进。SRD利用了云计算的资源和特点(例如AWS的复杂多路径主干网络)来支持新的传输策略,为其在紧耦合的工作负载中发挥价值。
任何真实的网络中都会出现丢包、拥塞阻塞等一系列问题。这不是说每天会发生一次的事情,而是一直在发生。
大多数协议(如 TCP)是按顺序发送数据包,这意味着单个数据包丢失会扰乱队列中所有数据包的准时到达(这种效应称为“队头阻塞”)。而这实际上会对丢包恢复和吞吐量产生巨大影响。
SRD 的创新在于有意通过多个路径分别发包,虽然包到达后通常是乱序的,但AWS实现了在接收处以极快的速度进行重新排序,最终在充分利用网络吞吐能力的基础上,极大地降低了传输延迟。 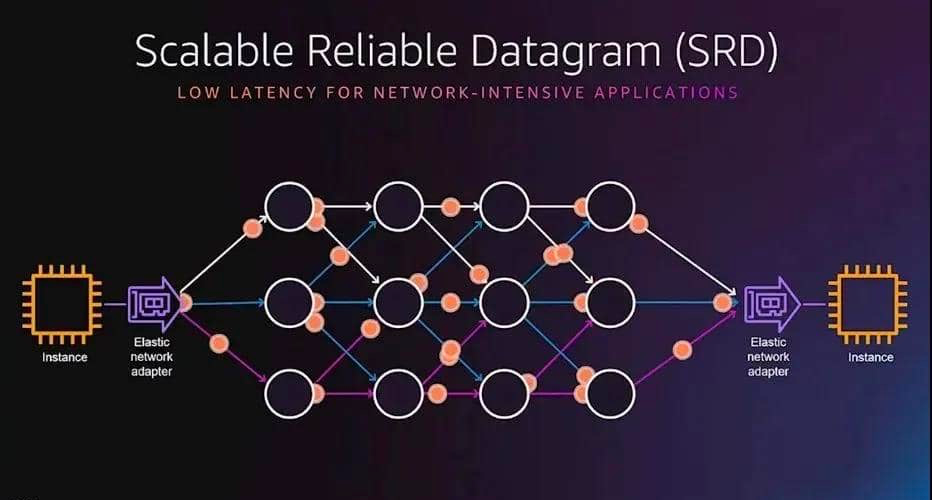
SRD 可以一次性将构成数据块的所有数据包推送到所有可能路径,这意味着SRD不会受到队头阻塞的影响,可以更快地从丢包场景中恢复过来,保持高吞吐量。 
众所周知,P99尾部延迟代表着只有1%的请求被允许变慢,但这也恰恰反映了网络中所有丢包、重传和拥塞带来的最终性能体现,更能够说明“真实”的网络情况。SRD能够让P99 尾延迟直线下降(大约 10 倍)。
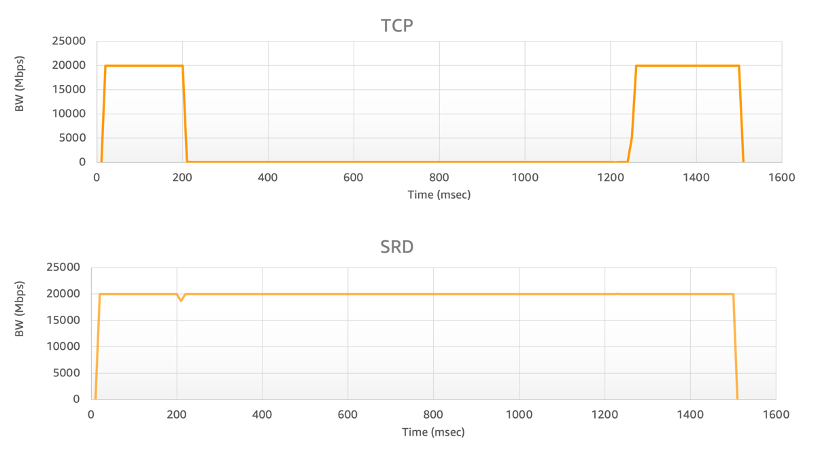
SRD的主要功能包括:
1)乱序交付:取消按顺序传递消息的约束,消除了队头阻塞,AWS在EFA用户空间软件堆栈中实现了数据包重排序处理引擎
2)等价多路径路由(ECMP):两个EFA实例之间可能有数百条路径,通过使用大型多路径网络的一致性流哈希的属性和SRD对网络状况的快速反应能力,可以找到消息的最有效路径。数据包喷涂(Packet Spraying)可防止出现拥塞热点,并可以从网络故障中快速无感地恢复
3)快速的丢包响应:SRD对丢包的响应比任何高层级的协议都快得多。偶尔的丢包,特别是对于长时间运行的HPC应用程序,是正常网络操作的一部分,不是异常情况
4)可扩展的传输卸载:使用SRD,与其他可靠协议(如InfiniBand可靠连接IBRC)不同,一个进程可以创建并使用一个队列对与任何数量的对等方进行通信
SRD 实际工作的关键不在于协议,而在于它在硬件中的实现方式。换种说法,就目前而言,SRD 仅在使用 AWS Nitro DPU 时才有效。
SRD乱序交付的数据包需要重新排序才能被操作系统读取,而处理混乱的数据包流显然不能指望“日理万机”的 CPU。即便真通过CPU 来完全负责 SRD 协议并重新组装数据包流,无疑是高射炮打蚊子——大材小用,那会使系统一直忙于处理不应该花费太多时间的事情,而根本无法真正做到性能的提升。
在SRD这一不寻常的“协议保证”下,当网络中的并行导致数据包无序到达时,AWS将消息顺序恢复留给上层,因为它对所需的排序语义有更好的理解,并选择在AWS Nitro卡中实施SRD可靠性层。其目标是让SRD尽可能靠近物理网络层,并避免主机操作系统和管理程序注入的性能噪音。这允许快速适应网络行为:快速重传并迅速减速以响应队列建立。
AWS说他们希望数据包在“栈上”重新组装,他们实际上是在说希望 DPU 在将数据包返回给系统之前,完成将各个部分重新组合在一起的工作。系统本身并不知道数据包是乱序的。系统甚至不知道数据包是如何到达的。它只知道它在其他地方发送了数据并且没有错误地到达。
这里的关键就是 DPU。AWS SRD 仅适用于 AWS 中配置了 Nitro 的系统。现在不少使用AWS的服务器都安装和配置了这种额外的硬件,其价值在于启用此功能将能够提高性能。用户需要在自己的服务器上专门启用它,如果需要与未启用 SRD 或未配置 Nitro DPU 的设备通信,就不会得到相应的性能提升。
至于很多人关心的SRD未来是否会开源,只能说让我们拭目以待吧!
审核编辑:刘清
-
X电容有什么特点和用途呢?2023-05-22 3993
-
什么是UVLED点光源及其特点和应用有哪些呢?2022-12-14 4961
-
单片机与嵌入式系统的特点有哪些呢2022-01-24 1358
-
变频器的功能和特点有哪些2022-01-20 8673
-
iTOP-Exynos4412开发板的特点有哪些呢2021-12-27 1459
-
STM32的UART特点有哪些呢2021-12-07 1382
-
STM32的通用定时器有何特点及其应用呢2021-11-23 1878
-
SPI是什么?SPI的特点有哪些呢2021-11-03 1827
-
IGBT模块有哪些特点和应用呢2021-11-02 2878
-
STM32的ADC有哪些重要特点呢2021-10-28 5699
-
基于8098微机的SRD电机控制系统2021-09-30 1147
-
雷达信号有什么特点?和通信信号的差异在哪里呢?2021-03-04 15799
-
对苹果SRD计划规则不满 谷歌等不再参与iPhone的SRD安全计划2020-07-23 1155
-
使用8098微机设计SRD电机控制系统的资料说明2019-10-28 1031
全部0条评论

快来发表一下你的评论吧 !
