

可用指南旨在使 AI 更安全
电子说
描述
介绍
人工智能 (AI) 领域准备进入一个新的领域——机器从补充人类用户的工具转变为自主智能代理,可以设定自己的目标,决定学习什么,决定如何学习,和更多。高度智能系统改变世界的潜力类似于以往工业革命带来的变化。问题不是智能系统是否会继续改变我们的生活;而是 问题是以什么方式和在什么程度上。
什么是人工智能安全工程?
AI Safety Engineering(或简称“AI Safety”)是一个拟议的 AI 开发框架,它将机器伦理学与心理学、经济学、金融学和其他领域相结合,以:
扩大对机器伦理的讨论,以包括狭义的、一般的和超人的智能
将最近和正在进行的人工智能伦理讨论与开发具有通用智能的机器的可用工程指南、流程和标准联系起来
针对智能系统中已知和潜在漏洞的来源
作为一个新兴的研究领域,人工智能安全的出现有几个原因。首先,人工智能的成功不仅仅以实现目标来衡量;成功的人工智能是以符合人类价值观和偏好的方式实现目标的人工智能。回顾 60 多年的 AI 发展,我们可以看到机器目标与人类价值观和偏好之间的不一致迟早会导致 AI 失败。正如本系列中所探讨的那样,将这种失调作为一个关键漏洞是开发安全人工智能的核心。
其次,人工智能的最新进展已经开始达到人工狭义智能系统的边界,这些系统在给定的上下文中执行单一或狭义定义的任务。传感器、大数据、处理,尤其是机器学习方面的进步使这些系统越来越像人类,并扩展了它们的能力和用途。考虑到这一点,达到人工智能的下一个层次——通用人工智能——即将到来,如果安全人工智能不是优先考虑的潜在后果也是如此。
Safe AI 的核心是假设通用人工智能会给人类带来风险。AI Safety 不是通过尝试在任务或目标级别将人类价值观和偏好传授给机器来解决这个问题——这可能是不可能的壮举——AI Safety 旨在:
以符合人类能力和/或
优先考虑人类福利、合作行为和为人类服务
这样做,我们将确保人工智能流程和目标在宏观层面尊重人类,而不是试图在微观层面实现同样的目标——让机器倾向于对我们友好,作为智能核心的一部分。
作为一种工程开发理念,AI Safety 将 AI 系统设计视为产品设计,对产品责任的每个角度进行检查和测试,包括使用、误用和潜在漏洞。图 1说明了 AI Safety 的新兴原则和建议。
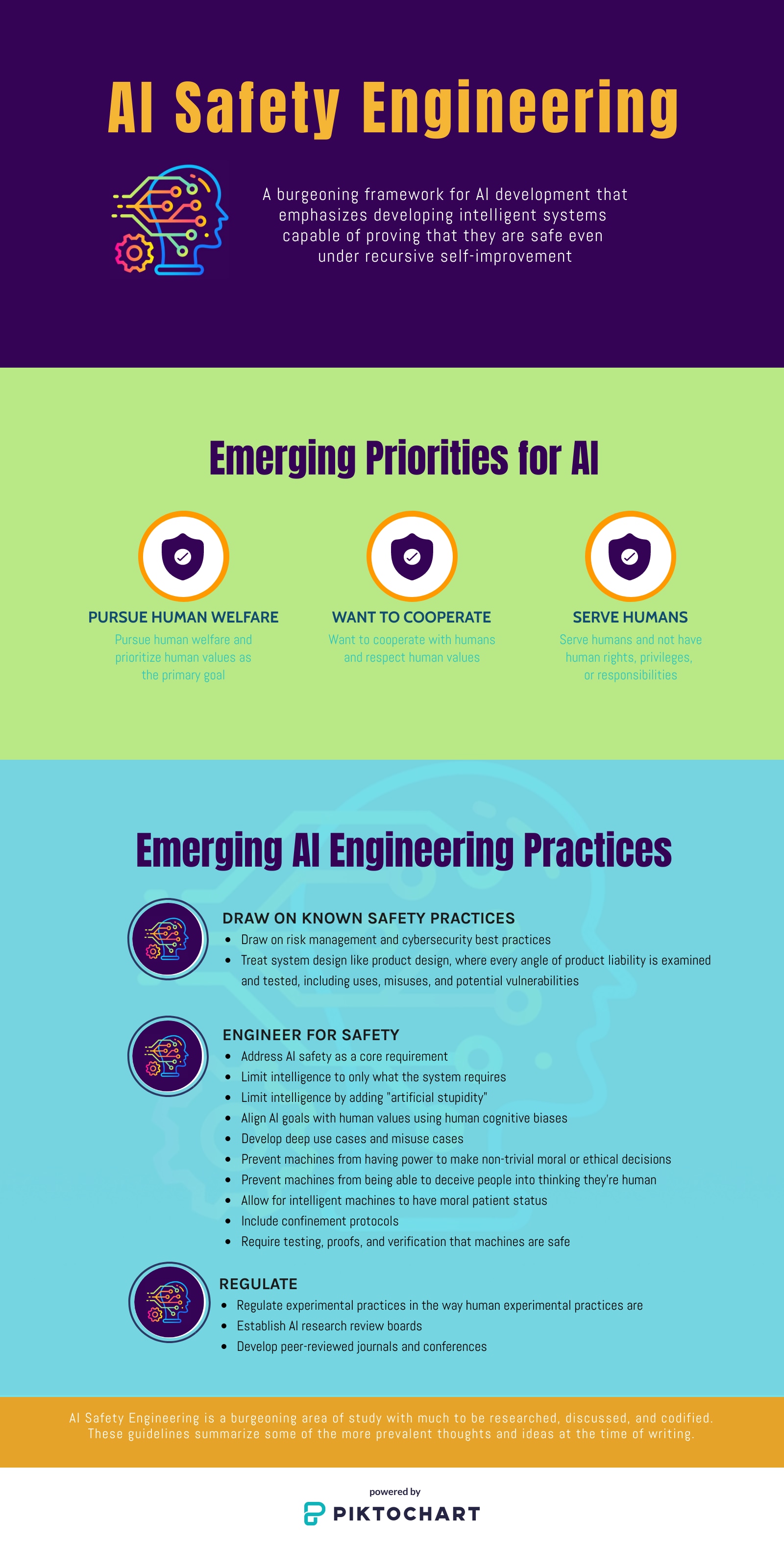
图 1:AI 安全工程强调开发智能系统,即使在递归自我改进的情况下也能证明它们是安全的。
在本系列中领先
AI 安全工程是一门新兴学科,有很多需要研究、讨论和编纂的内容。贸泽电子很高兴推出这个博客系列,让 AI 工程师了解关键概念并鼓励参与其持续开发:
本系列的第 2 部分重点介绍了我们从过去 60 多年的 AI 开发中学到的经验,即 AI 失败的原因是机器目标与人类价值观和偏好之间的不一致。它还讨论了为什么将人类价值观和偏好传授给机器是一个无法解决的问题,并指出了安全人工智能的必要性。
第 3 部分讨论了需要 AI 安全的另一个原因:AI 的进步正在突破人工狭义智能 (ANI) 系统的界限,并将人工智能 (AGI) 纳入视野。
第 4 部分探讨了实施 AI 安全的其他挑战:不可预测性、不可解释性和不可理解性。
第 5 部分描述了 AI 安全将改变工程的方式。开发深入用户价值核心的用例和检查情报漏洞是这里的两个关键主题。
第 6 部分以关于使用“人工愚蠢”来帮助我们开发安全人工智能的讨论作为结尾。限制机器能力以及理解认知偏差是这里的关键主题。
审核编辑 hhy
-
C2000™第2代至第3代MCU功能安全使能器迁移指南2024-11-28 557
-
Type-C端口保护方案指南——就是更安全!2023-10-07 2347
-
华为云网站高可用解决方案,保障企业业务连续可用,数据更安全2023-07-04 1300
-
虚拟现实如何使街道更安全2023-06-07 1633
-
XANDAR 旨在在安全关键型多核设计中生成代码2022-07-20 1542
-
「Spring」认证安全架构指南2022-06-27 1787
-
Type-C端口保护方案指南——就是更安全2022-05-26 3055
-
未来的AI开发将注重每个环节的安全和风险管理2021-05-18 2348
-
如何让边缘计算更安全?2021-02-26 1584
-
AI:对物联网安全的影响2019-05-29 3399
-
功能安全与人工智能2018-10-30 2968
-
汽车电子技术使我们的汽车更安全-汽车车身网络系统2015-08-18 5701
-
聚合物锂电安全使用指南2009-10-24 936
全部0条评论

快来发表一下你的评论吧 !
