

南开/南理工/旷视提出CTKD:动态温度超参蒸馏新方法
描述
论文题目:Curriculum Temperature for Knowledge Distillation
论文(AAAI 2023):https://arxiv.org/abs/2211.16231
开源代码(欢迎star):
https://github.com/zhengli97/CTKD
一句话概括:
相对于静态温度超参蒸馏,本文提出了简单且高效的动态温度超参蒸馏新方法。
背景问题:
目前已有的蒸馏方法中,都会采用带有温度超参的KL Divergence Loss进行计算,从而在教师模型和学生模型之间进行蒸馏,公式如下:
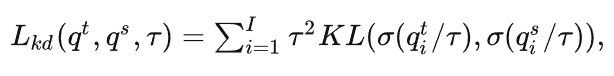

而现有工作普遍的方式都是采用固定的温度超参,一般会设定成4。
| 方法 |
FitNet (ICLR 15') |
AT (ICLR 17') |
SP (ICCV 19') |
Snapshot (CVPR 19') |
SSKD (ECCV 20') |
FRSKD (CVPR 21') |
|---|---|---|---|---|---|---|
| τ的设定 | 3 | 4 | 4 | 2 or 3 | 4 | 4 |
那么这就带来了两个问题:
1. 不同的教师学生模型在KD过程中最优超参不一定是4。如果要找到这个最佳超参,需要进行暴力搜索,会带来大量的计算,整个过程非常低效。
2. 一直保持静态固定的温度超参对学生模型来说不是最优的。基于课程学习的思想,人类在学习过程中都是由简单到困难的学习知识。那么在蒸馏的过程中,我们也会希望模型一开始蒸馏是让学生容易学习的,然后难度再增加。难度是一直动态变化的。
于是一个自然而然的想法就冒了出来:
在蒸馏任务里,能不能让网络自己学习一个适合的动态温度超参进行蒸馏,并且参考课程学习,形成一个蒸馏难度由易到难的情况?
于是我们就提出了CTKD来实现这个想法。
方法:
既然温度超参τ可以在蒸馏里决定两个分布之间的KL Divergence,进而影响模型的学习,那我们就可以通过让网络自动学习一个合适的τ来达到以上的目的。
于是以上具体问题就直接可以转化成以下的核心思想:
在蒸馏过程里,学生网络被训练去最小化KL loss的情况下,τ作为一个可学习的参数,要被训练去最大化KL loss,从而发挥对抗(Adversarial)的作用,增加训练的难度。随着训练的进行,对抗的作用要不断增加,达到课程学习的效果。
以上的实现可以直接利用一个非常简单的操作:利用梯度反向层GRL (Gradient Reversal Layer )来去反向可学习超参τ的梯度,就可以非常直接达到对抗的效果,同时随着训练的进行,不断增加反向梯度的权重λ,进而增加学习的难度。
CTKD的论文的结构图如下:
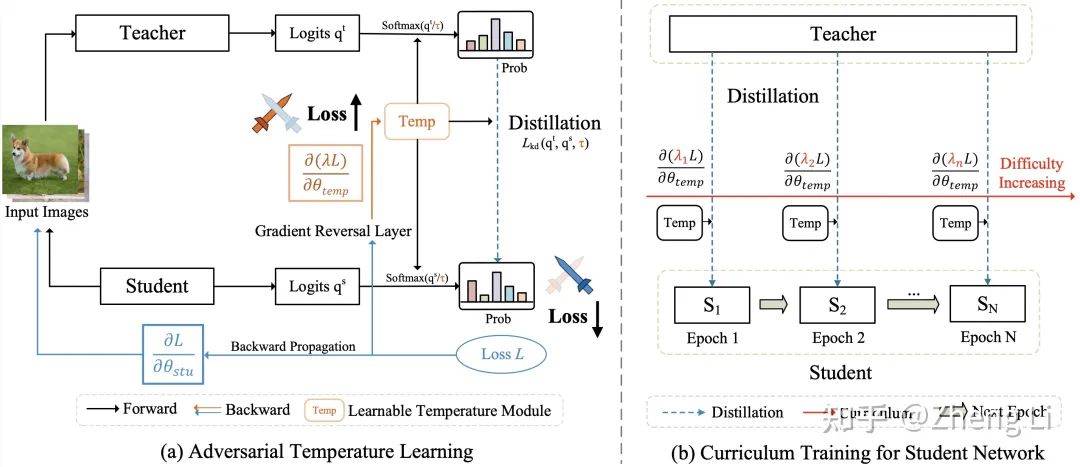
Fig.1 CTKD网络结构图
CTKD方法可以简单分为左右两个部分:
对抗温度超参τ的学习部分。
这里只包含两个小模块,一个是梯度反向层GRL,用于反向经过温度超参τ的梯度,另一个是可学习超参温度τ。
其中对于温度超参τ,有两种实现方式,第一种是全局方案 (Global Temperature),只会产生一个τ,代码实现非常简单,就一句话:
self.global_T = nn.Parameter(torch.ones(1), requires_grad=True)
第二种是实例级别方案(Instance-wise Temperature),即对每个单独的样本都产生一个τ。代码实现也很简单,就是两层conv组成的MLP。
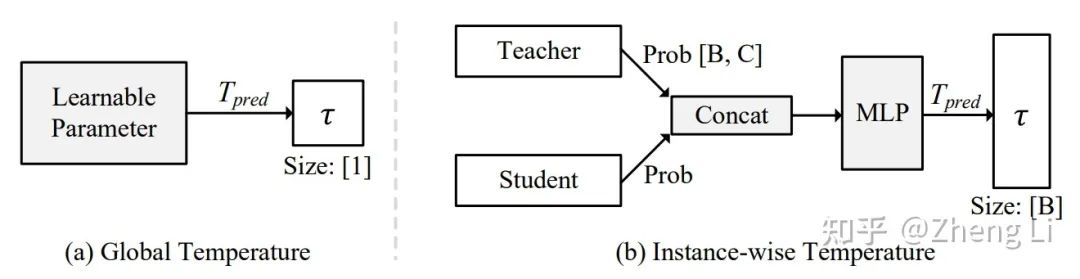
Fig.2 两种不同的可学习温度超参实现。
2. 难度逐渐增加的课程学习部分。
随着训练的进行,不断增加GRL的权重λ,达到增加学习难度的效果。
在论文的实现里,我们直接采用Cos的方式,让反向权重λ从0增加到1。
以上就是CTKD的全部实现,非常的简单有效。
CTKD总共包含两个模块,GRL和温度生成模块,都非常的轻量化,
CTKD方法可以作为即插即用的插件应用在现有的SOTA的蒸馏方法中,取得广泛的提升。
实验结果
三个数据集:CIFAR-100,ImageNet和MS-COCO。
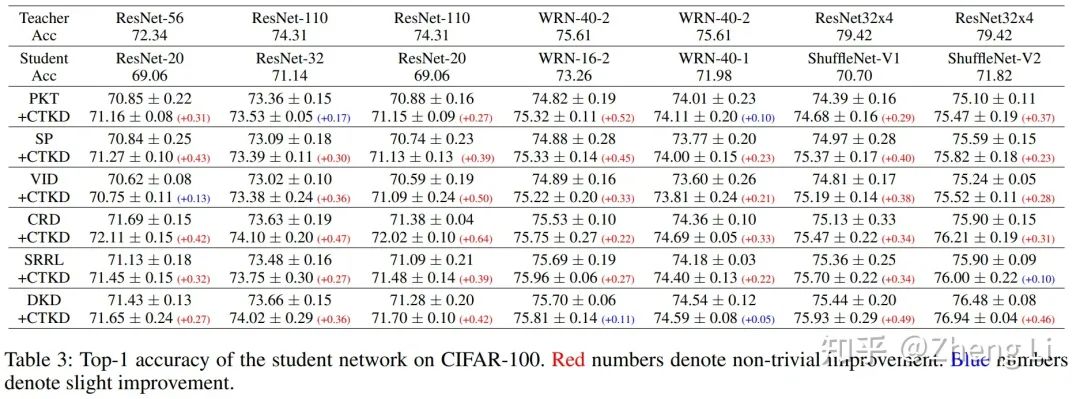
CIFAR-100上,CTKD的实验结果:

作为一个即插即用的插件,应用在已有的SOTA方法上:
在ImageNet上的实验:

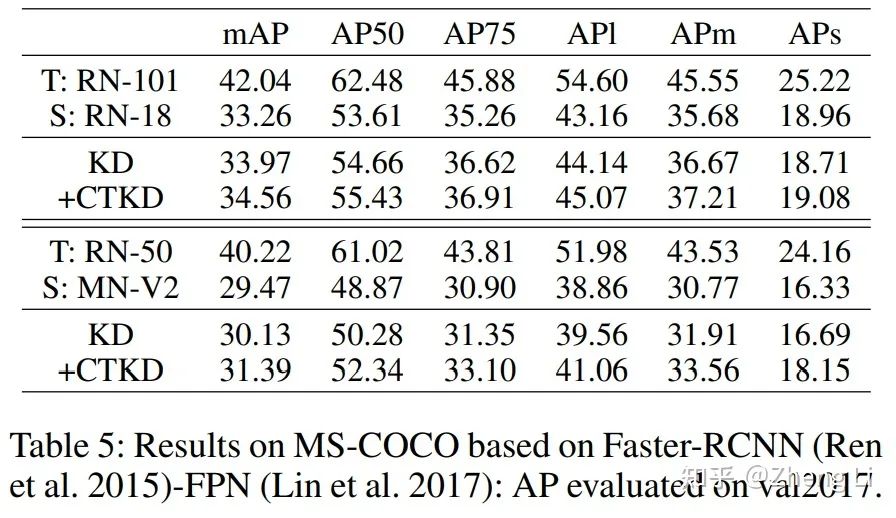
在MS-COCO的detection实验上:
温度超参的整体学习过程可视化:
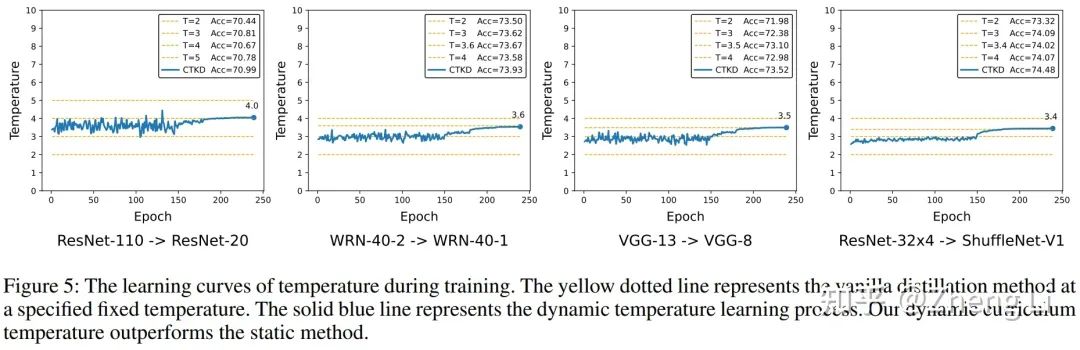
由以上图可以看到,CTKD整体的动态学习τ的过程。
将CTKD应用在多种现有的蒸馏方案上,可以取得广泛的提升效果。
审核编辑 :李倩
-
无刷直流电机反电势过零检测新方法2025-06-26 687
-
大连理工提出基于Wasserstein距离(WD)的知识蒸馏方法2025-01-21 1472
-
VLSI系统设计的最新方法2023-11-20 648
-
一种改善微波模块增益指标温度特性的新方法2023-10-25 477
-
求大佬分享按键扫描的新方法2022-01-17 883
-
分享一种中断输入和动态显示的新方法2021-06-07 2106
-
IMEC提出扇形晶圆级封装的新方法2019-08-16 5296
-
AD采集的新方法资料分享2018-03-23 1293
-
一种求解动态及不确定性优化问题的新方法2017-01-07 698
-
基于风力机输出功率序列相似度匹配的风电场分群新方法_叶超2016-12-30 629
-
一种标定陀螺仪的新方法2016-08-17 4288
-
测电阻,新方法,不加激励2015-03-26 5696
-
功率型LED热阻测量的新方法2009-10-19 6203
-
虚拟环境中软体的包围盒更新方法分析2009-08-14 892
全部0条评论

快来发表一下你的评论吧 !
