

完全卷积掩码自编码器框架——ConvNeXt V2
人工智能
描述
Title: ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
单位: KAIST, FAIR(陈鑫磊, 刘壮等人), 纽约大学(谢赛宁)
Paper: https://arxiv.org/abs/2301.00808
Github: https://github.com/facebookresearch/ConvNeXt-V2
引言
受 MAE 的启发,本文在 ConvNeXt 的架构基础上延伸出了一个完全卷积掩码自编码器框架——ConvNeXt V2,同时作者设计了一个全新的全局响应归一化(Global Response Normalization, GRN)层以增强原始 ConvNeXt 模块通道间的特征竞争,从而捕获更具有判别力的通道特征。
ConvNeXt V2 最终在各种识别基准上的性能,包括 ImageNet 分类、COCO 检测和 ADE20K 分割任务上均取得了极具竞争力的结果,其中最小的模型仅 3.7M 参数可获取 76.7% top-1 准确率,而最大的模型约 650M 参数则能达到 88.9% 准确率。
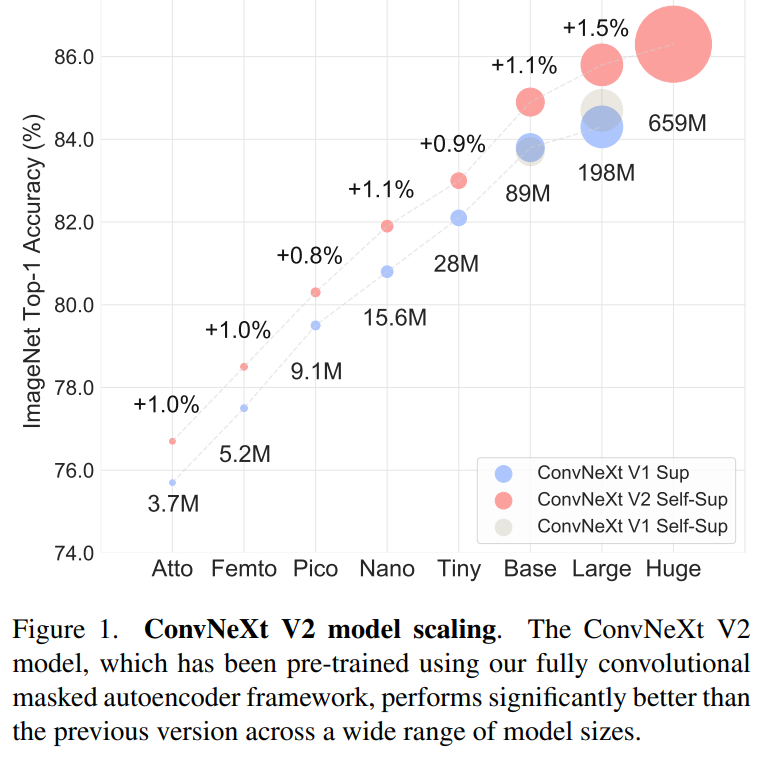
前情回顾
ConvNeXt
先来看下经典卷积神经网络的发展史:

紧接着 ViT 的提出带火了一众基于 Transformer 的模型:
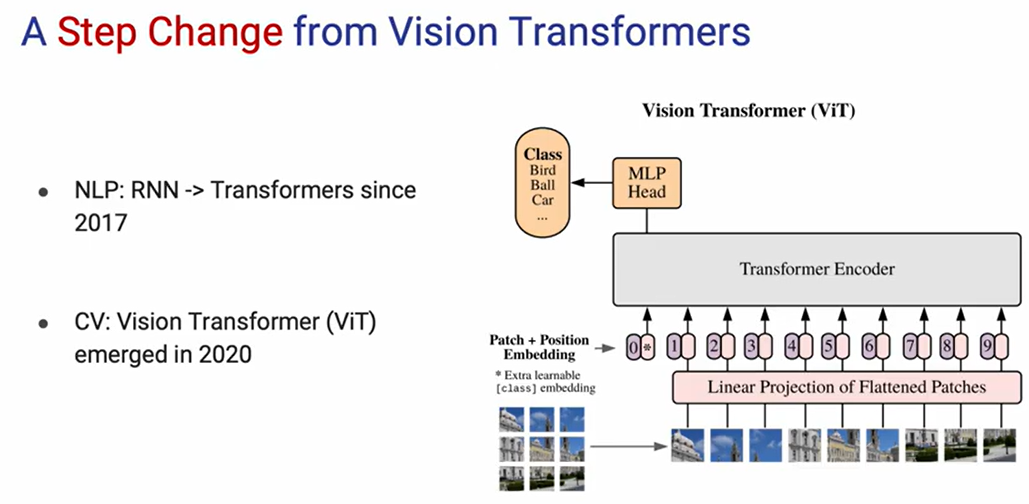
然后便是 Swin Transformer received ICCV 2021 best paper award (Marr Prize),一时间轰动华语乐坛视觉领域:
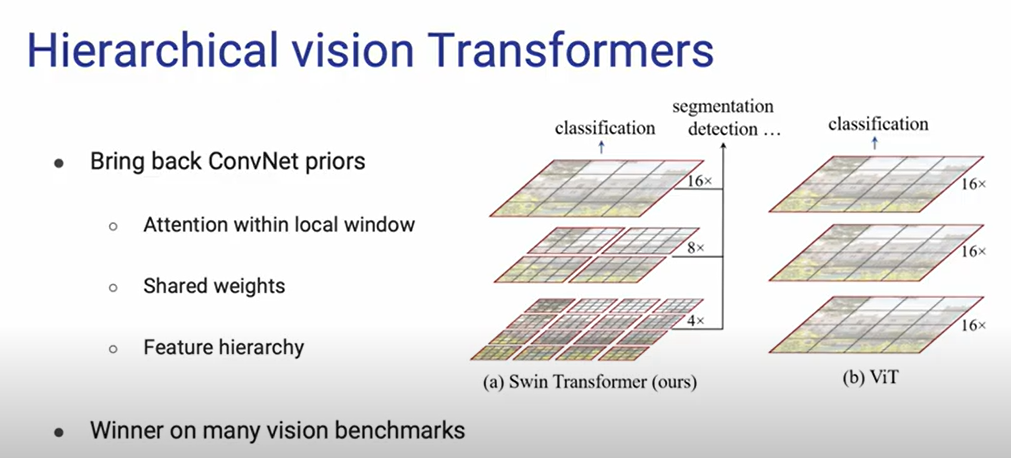
可以看出,Swin 其实是将传统 CNNs 三个重要的先验信息融入到了 Vision Transformer 的设计:
带局部窗口的注意力设计;
共享权重;
分层特征;
另一方面,我们从各大CV顶会接收的论文情况也能看出一些端倪:
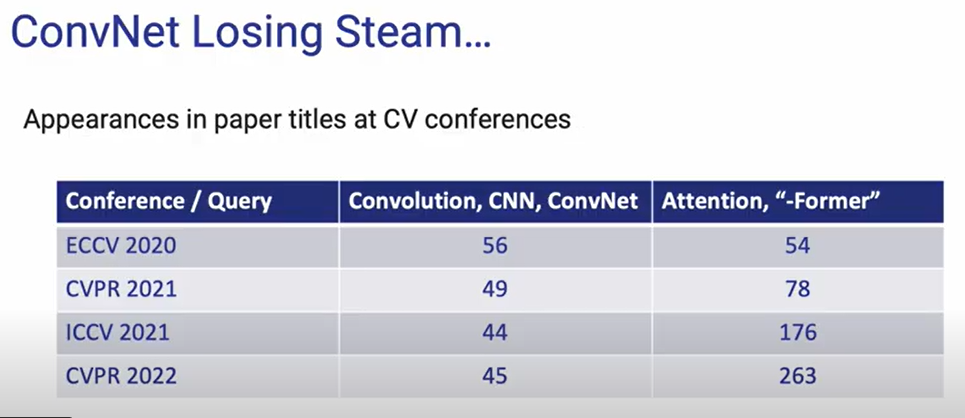
可以发现,基于各种 **Former 的模型遍地开花,而基于传统的卷积神经网络几乎没有增长。当然,除了 idea 新颖外,基于 Transformer 的模型效果也确实惊艳,例如:
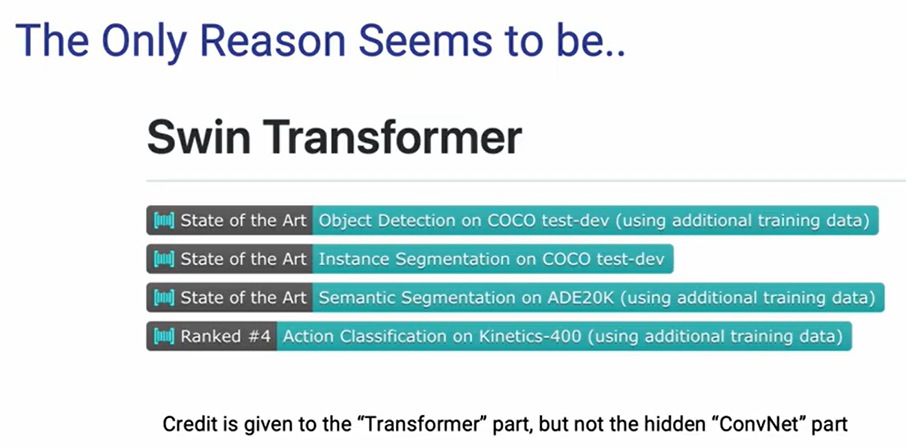
那么,这两者的本质区别在哪里呢?

首先,Transformer 模型由于缺乏固有的归纳偏置属性,这也意味着在小数据量的情况下它是很难“硬train一发”,因此大部分 Vision Transformer 模型训练的时候都会加入一堆 DataAug 和 Training Tricks,如果我们将这些 Tricks 应用到原始的 ResNet 上也能获得不错的性能增益:

好了,让我们看下 ConvNeXt 的设计思路是怎么样的:

整体设计遵循由粗粒度到细粒度的原则,可以看到,通过最终一步步的实验论证,ConvNeXt 的精度也随即提升,最终获得了完全可以媲美 Vision Transformer 的结果:
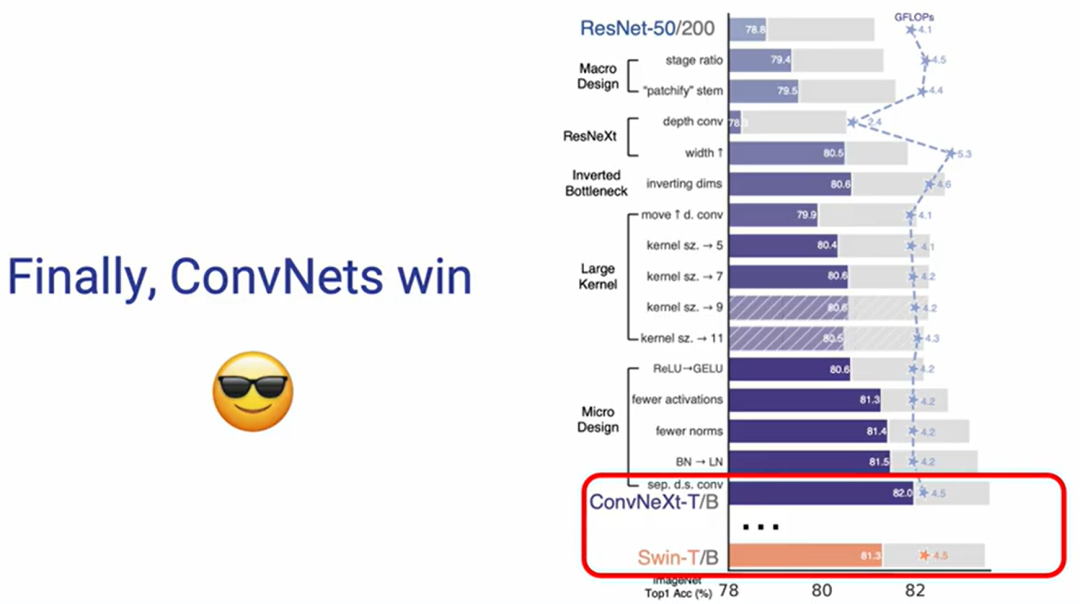
下面展示的是不同模块之间的结构对比图:
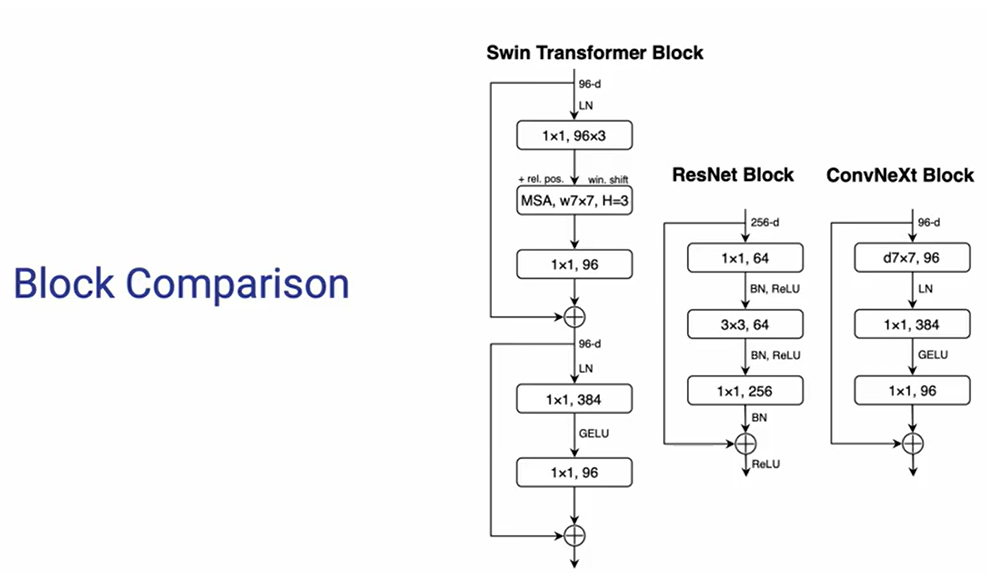
总的来说,ConvNeXt 是一个基于纯 ConvNets 的网络结构设计,其通过借鉴 Vision Transformer 的一些优化技巧,在 ResNet 的基础上一步步扎实的进行实验论证,最终获得了一个极具实际应用价值的网络结构模型,最终实现了优于 Swin Transformers 的性能,同时保持了标准 ConvNets 的简单性和效率,非常值得大家伙借鉴。
MAE
MAE 想必大家伙都认识了,毕竟CV界盛传的一句经典谚语——“凯明出品,必属精品”!自编码器一开始是应用在 NLP 领域,例如 BERT 模型便是被提出应用在句子的不同部分屏蔽单词,并尝试通过预测要填充到空白处的单词来重建完整的句子。因此自然而然的一个想法便是是否可以将这一想法嫁接到计算机视觉领域。
作为CV界的头号种子选手,老何当然是不负众望,凭借着多年来异常敏锐的嗅觉,不费吹灰之力便提出了一种使用自编码器对计算机视觉模型进行自监督预训练的新方法:
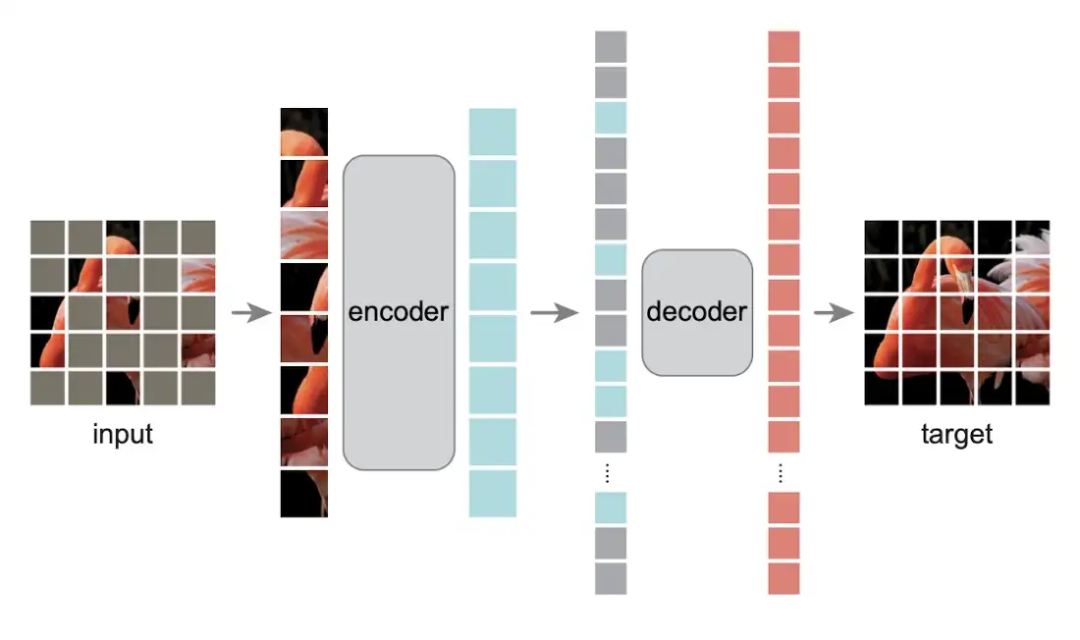
在 MAE 中,作者提倡使用非常高的遮挡率,例如 75%,这能带来两个好处:
训练速度提升3倍,因为模型仅需处理更少(unmasked)的图像块;
强迫模型学习出泛化能力,提高特征提取的能力;
此处,这是一个非对称的编解码器,这意味着其应用了一个相当轻量的解码器,而编码器的输出便是输入图像块的潜在向量表示。而 MAE 的关键步骤之一便是利用解码器重建初始图像,其中每个掩码标记都是一个共享的学习向量,表示存在缺失的补丁。解码器则接收潜在表示以及掩码标记作为输入,并输出每个补丁的像素值,包括掩码。根据此信息,可以将原始图像拼凑在一起,以根据用作输入的掩码图像形成完整图像的预测版本。
一旦重建了目标图像,我们只需测量它与原始输入图像的差异并将其用作损失执行反向传播即可。最终,当模型训练完成后,解码器将会被丢弃掉,只保留编码器部分,以供下游任务使用。
本文方法
动机
上面我们提到过,ConvNeXt 架构是对传统的 ConvNet 进行的一次现代化改造,作者证明了纯卷积模型也可以成为像 Vision Transformer 一样的可扩展架构。然而,探索神经网络架构设计空间的最常用方法仍然是通过在 ImageNet 上对监督学习性能进行基准测试。
近年来,自监督学习也是非常热门,相比之下,自监督学习不需要任何人工创建的标签。顾名思义,模型学会自我监督。在计算机视觉中,对这种自监督进行建模的最常见方法是对图像进行不同裁剪或对其应用不同的增强,并将修改后的输入传递给模型。即使图像包含相同的视觉信息但看起来不一样,我们让模型学习这些图像仍然包含相同的视觉信息,即相同的对象。这导致模型为相同的对象学习相似的潜在表示(输出向量)。特别地,MAE 的提出成功地将掩码语言建模成功带到了视觉领域,并迅速成为视觉表示学习的流行方法。然而,自监督学习中的一种常见做法是使用为监督学习设计的预定架构,并假设模型架构是固定的。例如,MAE 是基于 ViT 开发的。
既然 ConvNeXt 和 MAE 有这么大的优势,那么简单将 MAE 的思想套在 ConvNeXt 上会有什么问题呢?首先,正如上述所说,MAE 有一个特定的编解码器设计,是专门针对 Transformer 的序列处理能力进行了优化,这使得计算量大的编码器可以专注于可见的补丁,从而降低预训练成本。此设计可能与使用密集滑动窗口的标准 ConvNet 不兼容。此外,如果不考虑体系结构和训练目标之间的关系,则很大可能获取不到最佳性能。事实上,相关研究表明,使用基于掩码的自监督学习训练 ConvNets 是比较困难的,并且 Transformers 和 ConvNets 本质上提取到的特征本身就没有良好的兼容性。
因此,本文的重点便是探讨如何在同一框架下共同设计网络架构和掩码自编码器,目的是使基于掩码的自监督学习对 ConvNeXt 模型有效,并获得与使用 Transformer 相当的性能。
具体地,在设计 MAE 时,作者将 mask 输入视为一组稀疏补丁,同时使用稀疏卷积仅处理可见部分,这点跟原始的 MAE 保持一致。这个想法的灵感来自于在处理大规模 3D 点云时所采用的稀疏卷积一致。在实践中,我们可以用稀疏卷积实现 ConvNeXt,在微调时,权重被转换回标准的密集层,不需要特殊处理。为了进一步提高预训练效率,作者应用了单个 ConvNeXt 块替换了原始的基于 Transformer 的解码器,使整个设计完全卷积化。最后,作者对 ConvNeXt 的不同训练配置进行特征空间分析。当直接在掩码输入上训练 ConvNeXt 时,会发现 MLP 层的潜在特征崩溃问题。为了解决这个问题,本文额外设计了一个全新的 Global Response Normalization 层来鼓励通道间的特征竞争。
FCMAE
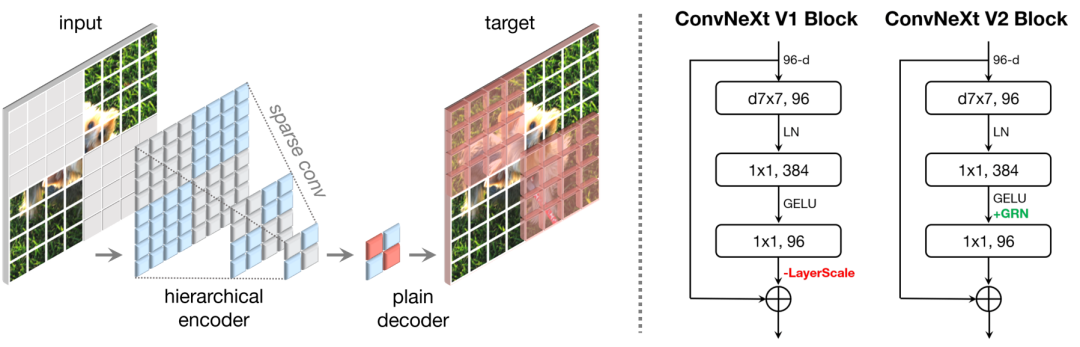
FCMAE Framework
上图左半部分展示了一种全卷积掩码自编码器 (FCMAE)。它是由一个基于稀疏卷积的 ConvNeXt 编码器和一个轻量级的 ConvNeXt 块解码器组成。整体来看,这是一个非对称的编解码器。其中编码器仅处理可见像素,解码器则使用编码像素和掩码标记重建图像,损失仅在 mask 区域上计算,与 MAE 保持一致。大家可以明显的看出本文方法在概念上很简单,并且以纯卷积的方式运行。学习信号是通过以高屏蔽率随机屏蔽原始输入视觉效果并让模型在给定剩余上下文的情况下预测缺失部分来生成的。下面让我们拆解下整个网络结构具体看看作者作出了什么改进和优化。
Masking
首先,本文使用 mask ratio 为 0.6 的随机 mask 策略,相对之下 MAE 是建议使用 0.75。由于卷积模型具有分层设计,其特征会在不同阶段被下采样,因此掩码在最后阶段生成并递归上采样到最精细的分辨率。为了在实践中实现这一点,作者从原始输入图像中随机删除 60% 的 32 × 32 patch,同时使用最少的数据增强,仅包括随机调整大小的裁剪策略。
Encoder design
ConvNeXt V2 顾名思义是使用 ConvNeXt 模型作为编码器。使 mask 图像建模有效的一个挑战是防止模型学习允许它从 mask 区域复制和粘贴信息的快捷方式。这在基于 Transformer 的模型中相对容易防止,它可以将可见补丁作为编码器的唯一输入。然而,使用 ConvNets 其实是比较难实现这一点,因为必须保留 2D 图像结构。一种最简单的解决方案是在输入端引入可学习的掩码标记,如 BEiT 和 Simmim,但这些方法降低了预训练的效率并导致训练和测试时间不一致,因为在测试时没有掩码标记。特别是当遮挡率过高时问题便会尤其凸显。
为了解决这个问题,本文借鉴在 3D 任务中学习稀疏点云的道理,将 mask 图表示为一个二维的稀疏像素阵列。因此,一种自然而然的想法便是引入稀疏卷积,以促进 MAE 的预训练。在具体的代码实现中,我们可以将标准卷积层转换为稀疏卷积,这使得模型可以仅对可见数据点进行操作,而在 fine-tune 阶段,完全可以转换为标准卷积,而无需额外处理。作为替代方案,也可以在密集卷积运算之前和之后应用 binary masking operation。此操作在数值上与稀疏卷积等价,但理论上计算量更大些,不过在 TPU 等 AI 加速器上更友好。
Decoder design
同 MAE 一致,ConvNeXt V2 也采用轻量级的解码器设计。其次,作者还考虑了更复杂的解码器,例如分层解码器如 FPN 和 U-Net 或 ViT 和 MAE,不过最终的实验表明更简单的单个 ConvNeXt 块解码器效果其实就很不错了,而且还可以显著减少预训练时间,本文将将解码器的维度设置为 512。
Reconstruction target
这里目标重构的方式同 MAE 类似,也是采用 MSE 来衡量损失,目标是原始输入的 patch-wise 归一化图像,并且损失仅应用于 mask 过后的 patch。在具体的训练步骤中,作者基于 ImageNet-1K 数据集进行了 800 轮 epochs 的预训练并额外微调了 100 轮 epochs。
Global Response Normalization
如上所述,当直接在 mask 输入上训练 ConvNeXt 时,会导致特征崩溃的问题。为此,作者引入了一种全新的全局响应归一化层,以结合 ConvNeXt 架构使 FCMAE 预训练更加有效,下面让我们介绍下具体细节。
Feature collapse
为了更深入地了解学习行为,我们首先在特征空间中进行定性分析。具体的,可以将 FCMAE 预训练的 ConvNeXt-Base 模型的激活可视化,由此可以观察到一个有趣的“特征崩溃”现象:即存在许多饱和的特征图,并且激活在通道之间变得很多余。如下图所示,这些特征图可以通过可视化 ConvNeXt 块中的维度扩展 MLP 层中观察到:

Feature cosine distance analysis
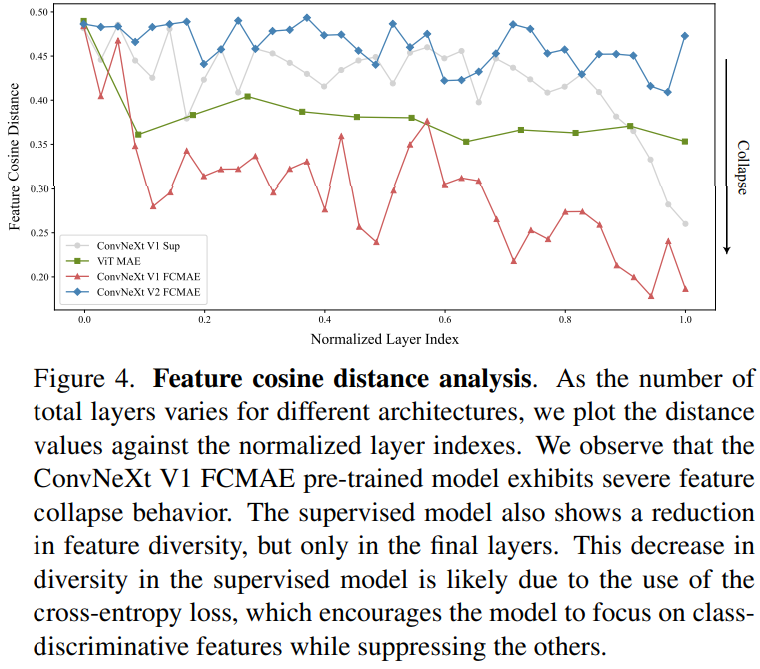
上图展示了定量分析结果。为了执行此分析,本文随机选择 ImageNet-1K 验证集中不同类别的 1,000 张图像,并从不同模型的每一层提取高维特征,包括 FCMAE 模型、ConvNeXt 监督模型和 MAE 预训练 ViT 模型。随后作者计算了每个图像的每层距离,并对所有图像像素值求平均。从给出的结果图可以看出,FCMAE 预训练的 ConvNeXt 模型表现出明显的特征崩溃趋势,这与我们从之前的激活可视化中观察到的结果一致。这促使作者进一步考虑在学习过程中使特征多样化并防止特征崩溃的方法。
Approach
在这项工作中,全局响应归一化的引入主要旨在增加通道的对比度和选择性。具体地,给定一个输入特征 ,所提出的 GRN 单元包括三个步骤:
全局特征聚合;
特征归一化;
特征校准;
下面给出伪代码示例:

通过将 GRN 层整合到原始的 ConvNeXt 块中,我们可以得到下面的结构:
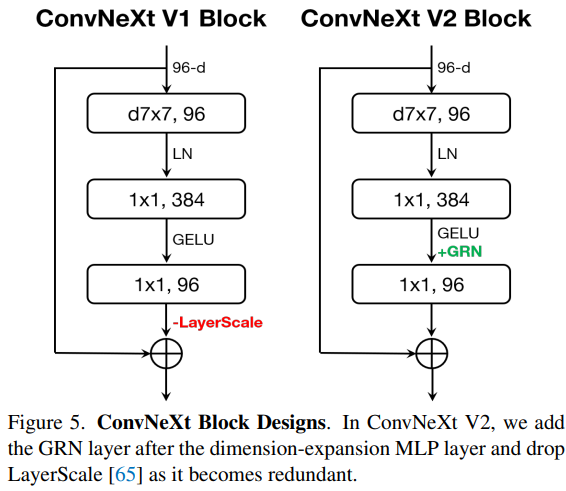
此外,作者发现,当应用 GRN 时,LayerScale 其实是没有必要的,因此在此版本中将其删掉。使用这种新的模块设计,我们可以创建具有不同效率和容量的各种模型,分别适用于不同的应用场景。
Impact of GRN
从图 3 中的可视化和图 4 中的余弦距离分析,我们可以观察到 ConvNeXt V2 有效地缓解了特征崩溃问题。其中余弦距离值一直很高,这表明跨层机制保持了特征的多样性。这种行为类似于 MAE 预训练的 ViT 模型。总体而言,这表明在类似的掩码图像预训练框架下,ConvNeXt V2 的学习行为可以类似于 ViT。
此外,当配备 GRN 时,FCMAE 预训练模型可以显着优于 300 个 epoch 的监督模型。GRN 通过增强特征多样性来提高表示质量,这在原始的 ConvNeXt 模型中是不存在的,但已被证明对于基于掩码的预训练至关重要。值得一提的是,这种改进是在不增加额外参数开销或增加 FLOPS 的情况下实现的。

Relation to feature normalization methods
如上表所示,作者将 GRN 与三个广泛使用的归一化层进行了比较,即局部响应归一化(LRN)、批量归一化(BN)和层归一化(LN)。从结果可以观察到只有 GRN 可以显着优于 baseline,这是由于:
LRN 缺乏全局上下文,因为它只对比附近领域的通道;
BN 沿批处理轴在空间上归一化,这不适用于 mask 输入;
LN 则通过全局均值和方差标准化隐含地鼓励特征竞争,但效果显然不如 GRN。
Relation to feature gating methods
另一种增强神经元间竞争的方法是使用动态特征门控方法,例如 SE 和 CBAM,一个注重通道,一种注重空间。这两个模块都可以增加单个通道的对比度,类似于 GRN 所做的。不过 GRN 显然更简单、更高效,因为它不需要额外的参数层(例如 FC 层)。
The role of GRN in pre-training/fine-tuning
最后我们可以看下 GRN 在预训练和微调中的重要性。从表格最后一栏可以看到,无论我们是从微调中删除 GRN,还是仅在微调时添加新初始化的 GRN,都可以观察到模型性能显着下降,这表明在预训练和微调中使用 GRN 层是非常有必要的。
实验
参数设置
Pre-training setting
End-to-end IN-1K fine-tuning setting for Atto (A), Femto (F), Pico (P) and Nano (N) models
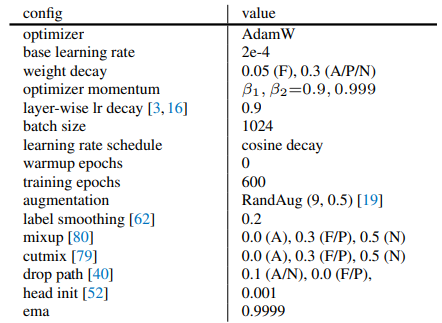
End-to-end IN-1K fine-tuning setting for Tiny model
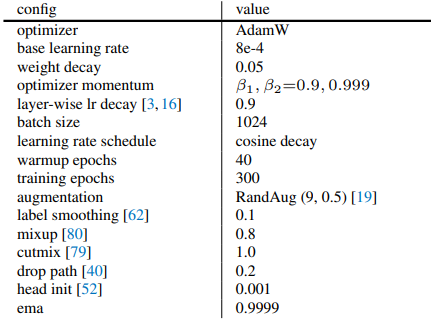
End-to-end IN-1K fine-tuning setting for Base (B), Large (L), and Huge (H) models
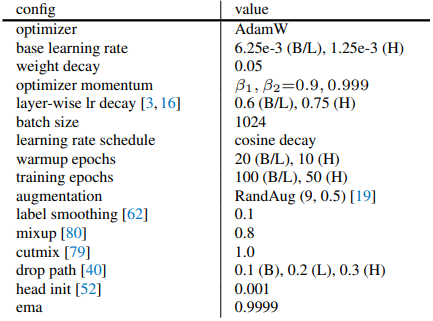
End-to-end IN-22K intermediate fine-tuning settings
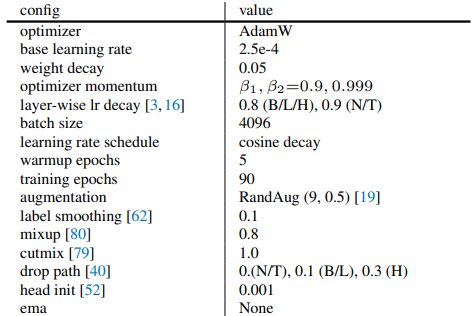
End-to-end IN-1K fine-tuning settings (after IN-22K intermediate fine-tuning)
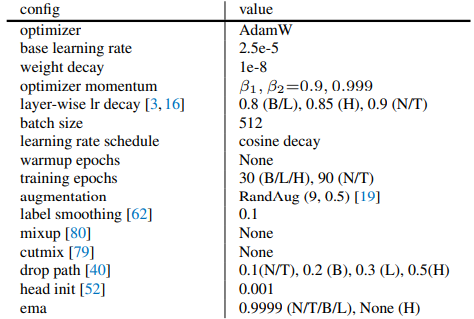
协同设计
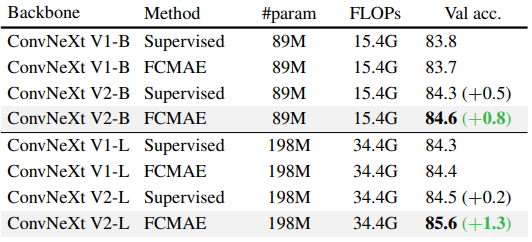
可以发现,在不修改模型架构的情况下使用 FCMAE 框架对表示学习质量的影响有限。同样,新的 GRN 层对监督设置下的性能影响很小。然而,如果我们将两者结合起来使用可以令微调性能显着提高。
与 SOTA 方法对比
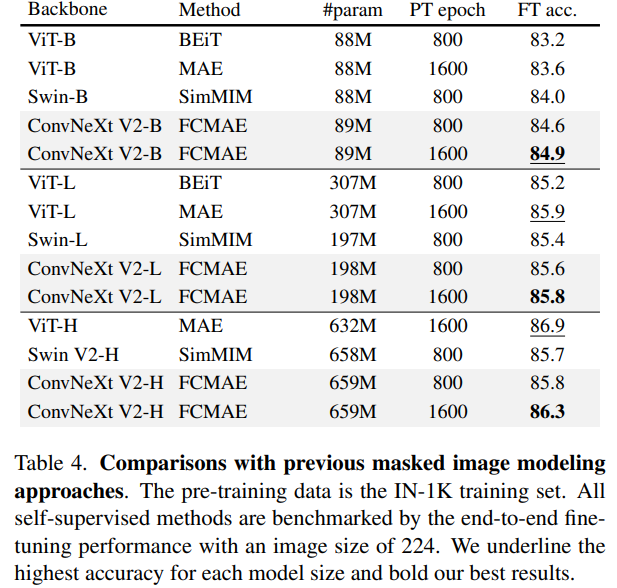
总结
在本文中,我们介绍了一个名为 ConvNeXt V2 的新 ConvNet 模型系列,一种更适合自监督学习而设计的新型网络架构。通过使用全卷积掩码自编码器预训练,可以显著提高纯 ConvNets 在各种下游任务中的性能,包括 ImageNet 分类、COCO 目标检测和 ADE20K 分割。
编辑:黄飞
-
自编码器的原理和类型2024-07-09 3961
-
李飞飞团队新作SiamMAE:孪生掩码自编码器,刷榜视觉自监督方法!2023-06-12 1358
-
堆叠降噪自动编码器(SDAE)2023-01-11 7999
-
自编码器神经网络应用及实验综述2021-06-07 1132
-
晶圆表面的二维主成分分析卷积自编码器2021-04-29 1091
-
基于深度神经网络模型的二维主成分卷积自编码器2021-04-22 1451
-
一种基于变分自编码器的人脸图像修复方法2021-04-21 1168
-
自编码器基础理论与实现方法、应用综述2021-03-31 1227
-
基于稀疏自编码器的属性网络嵌入算法SAANE2021-03-27 1149
-
基于变分自编码器的异常小区检测2020-12-03 1688
-
自编码器介绍2019-06-11 5544
-
卷积Turbo码编码器及CPLD的实现工程中的关键问题2019-05-30 1411
-
是什么让变分自编码器成为如此成功的多媒体生成工具呢?2018-04-19 14521
全部0条评论

快来发表一下你的评论吧 !
