

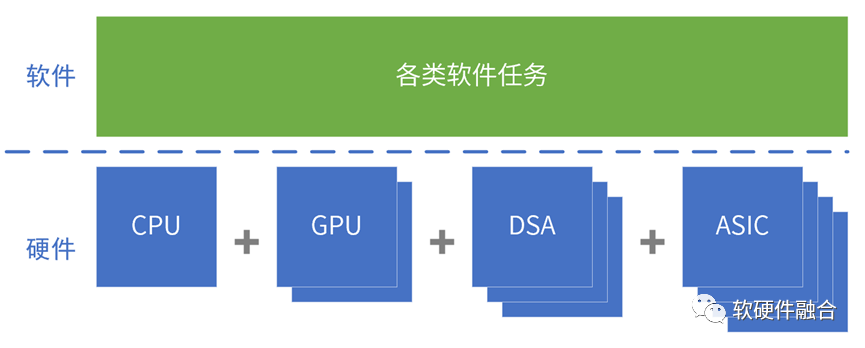
从CPU到ASIC,架构越来越碎片化
处理器/DSP
描述
去年的时候,抛砖引玉的写了一篇“硬件定义软件?还是软件定义硬件?”的文章,现在再看,发现很多考虑不全面不深刻的地方。继续抛砖,与大家深入探讨此话题。
今天这篇文章,我们主要关注如下话题:
超异构计算,为什么需要开放生态?
开放生态应该由硬件定义还是软件定义?
什么样的生态才算开放?
1 处理器类型:从CPU到ASIC
1.1 CPU指令集架构ISA
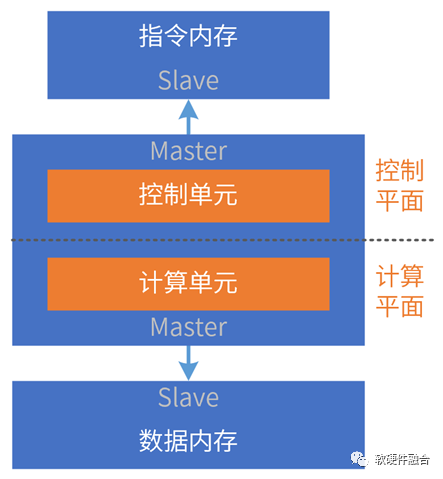
ISA(Instruction Set Architecture,指令集架构),是计算机体系结构与编程相关的部分(不包含组成和实现)。ISA定义了:指令集、数据类型、寄存器、寻址模式、内存管理、I/O模型等。
CPU图灵完备,是可自运行的处理器:CPU主动从指令内存读取指令流,然后译码后执行;指令执行会涉及到数据的载入(Load)、计算和存储(Store)。
我们可以把处理器简单地分为控制平面和计算平面两部分。
CPU是指令流驱动计算的处理引擎。
1.2 (CPU视角的)GPU架构
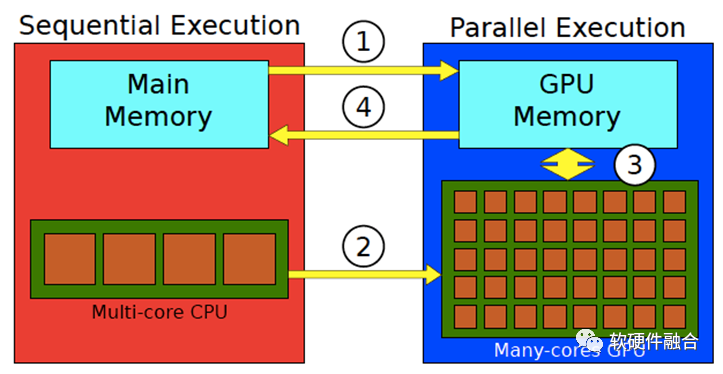
架构侧重软硬件之间的交互“接口”,而微架构侧重具体实现。因此,GPU架构通常指的是CPU视角看到的GPU“接口”。从CPU视角看GPU的处理流程:
CPU把数据准备好,并保存在CPU内存中;
将待处理的数据从CPU内存复制到GPU内存(处理①);
CPU指示GPU工作,配置并启动GPU内核(处理②);
多个GPU内核并行执行,处理准备好的数据(图中的③处理);
处理完成后,将处理结果复制回CPU内存(处理④);
CPU把GPU的结果进行后续处理。
1.3 ASIC专用处理引擎
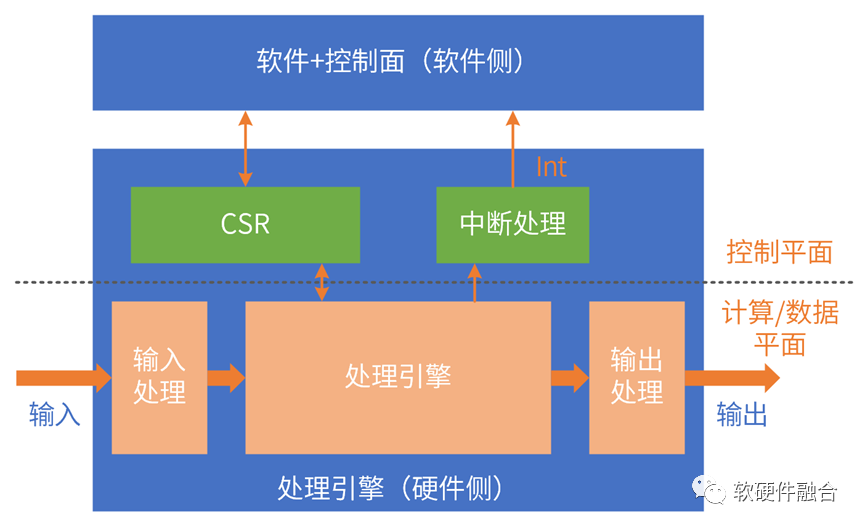
ASIC功能逻辑完全确定:通过驱动程序和CSR和可配置表项交互,以此来控制硬件运行。
ASIC覆盖的场景较小,并且类型多种多样;即使同一场景,不同厂家实现依然存在差别;ASIC场景碎片化,毫无生态可言。
和GPU类似,ASIC的运行依然需要CPU的参与:
数据的输入:数据在内存准备好,CPU控制ASIC引擎的输入逻辑,把数据从内存搬到处理引擎;
ASIC的运行控制:控制CSR、可配置表项、中断等;
数据的输出:CPU控制ASIC引擎的输出逻辑,把数据从引擎搬到内存,等待后续处理。
ASIC是数据流驱动计算的处理引擎。
1.4 DSA领域专用架构
DSA是在ASIC基础上的回调,具有一定的可编程能力,覆盖场景更多,性能和ASIC同量级。
DSA经典案例:
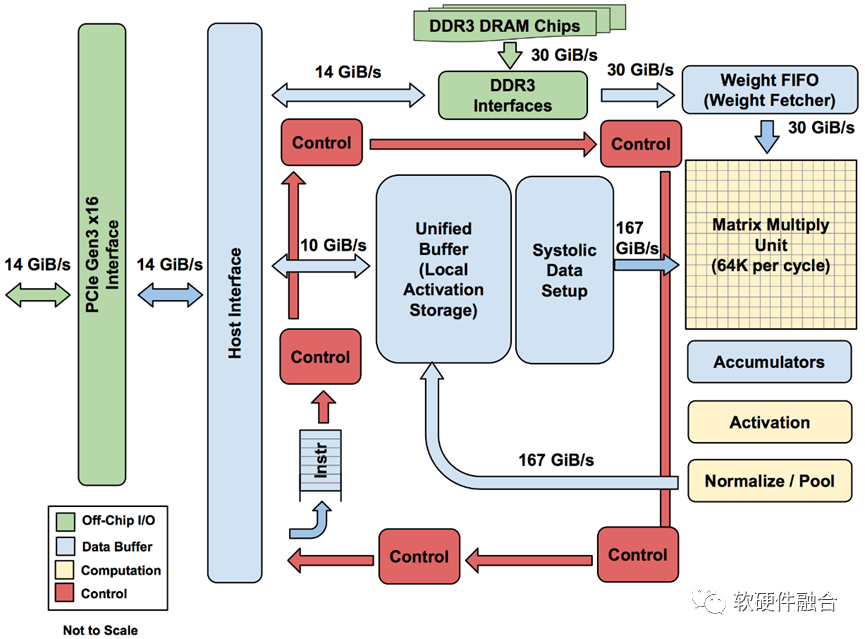
AI-DSA,如谷歌TPU;
网络DSA,如Intel Barefoot P4-DSA网络交换芯片。
1.5 小结:从CPU到ASIC,架构越来越碎片化
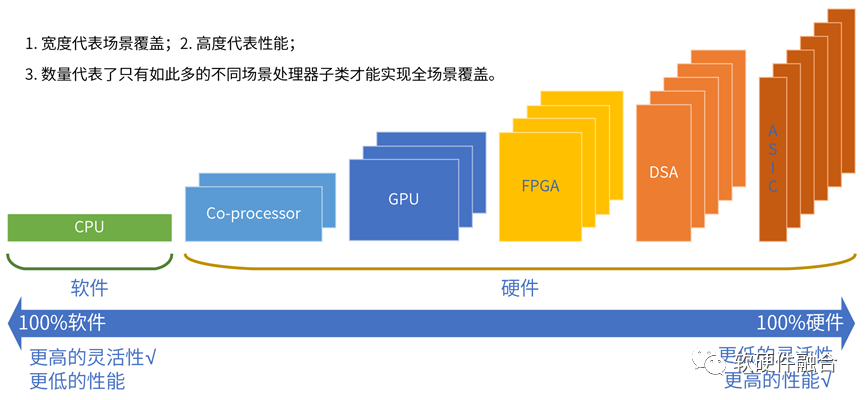
指令是软件和硬件的媒介,指令的复杂度(单位计算密度)决定了系统的软硬件解耦程度。
按照指令的复杂度,典型的处理器平台大致分为CPU、协处理器、GPU、FPGA、DSA、ASIC。
世间万物由基本粒子组成,复杂处理由基本计算组成。
指令复杂度越高,单个处理器引擎覆盖的场景就会越小,处理器引擎的形态就会越多。
从CPU到ASIC,处理器引擎越来越碎片化,构建生态越来越困难。
2 计算架构:从异构到超异构
2.1 CPU性能瓶颈,引发连锁反应
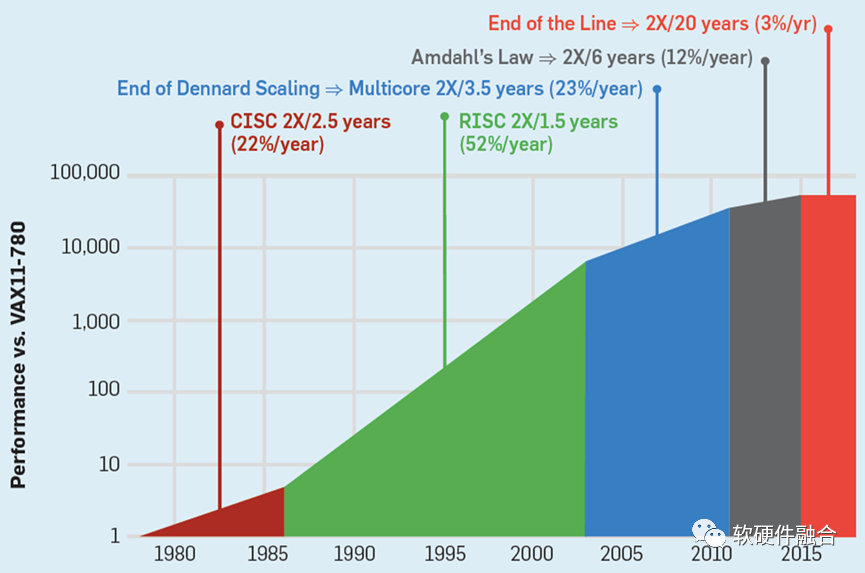
在云计算、边缘计算以及一些超级终端的复杂计算场景,对灵活性的要求远高于对性能的要求。
CPU通用灵活性好,在符合性能要求的情况下,各类复杂计算场景,CPU依然是最优选择。
对算力的需求不断增加,不得不通过各种异构加速方式进行性能优化。
实践证明,在复杂计算场景,提升性能的同时,不能损失通用灵活性(言外之意,目前很多技术方案损害了灵活性)。
2.2 异构计算存在的问题
复杂计算的挑战:系统越复杂,需要选择越灵活的处理器;性能挑战越大,需要选择越偏向定制的加速处理器。本质矛盾是:单一处理器无法兼顾性能和灵活性;即使我们拼尽全力平衡,也只“治标不治本”。
CPU+xPU异构计算中的xPU,决定了整个系统的性能/灵活性特征:
GPU灵活性较好,但性能效率不够极致;
DSA性能好,但灵活性差,难以适应复杂计算场景对灵活性的要求。案例:AI落地困难。
FPGA功耗和成本高,需要一些定制开发,落地案例不多。
ASIC功能完全固定,难以适应灵活多变的复杂计算场景。
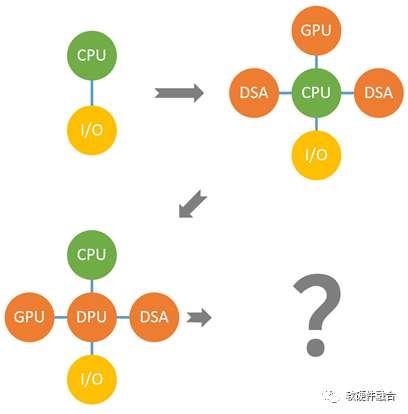
异构计算还存在计算孤岛的问题:
异构计算面向某个领域或场景,领域之间的交互困难。
服务器物理空间有限,无法多个物理加速卡,需要把这些加速方案整合;
需要强调的是:整合,不是简单的拼凑,而是要架构重构。
2.3 超异构存在的前提条件:复杂系统和超大规模
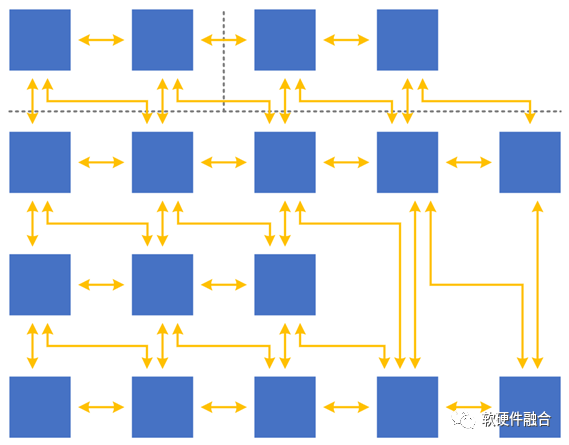
基础特征:①超大规模的计算集群;②复杂宏系统,是由分层分块的组件(系统)组成。
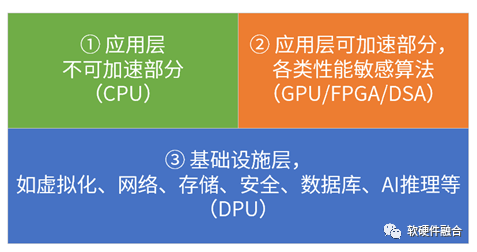
单服务器的宏系统复杂度,以及超大规模的云和边缘计算,使得“二八定律”在系统中普遍存在,因此,可以把:相对确定的任务沉淀到基础设施层,相对弹性的沉淀到弹性加速部分,其他继续放在CPU(CPU兜底)。
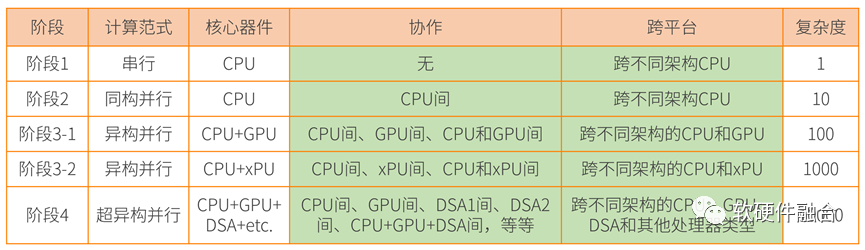
2.4 从异构并行到超异构并行
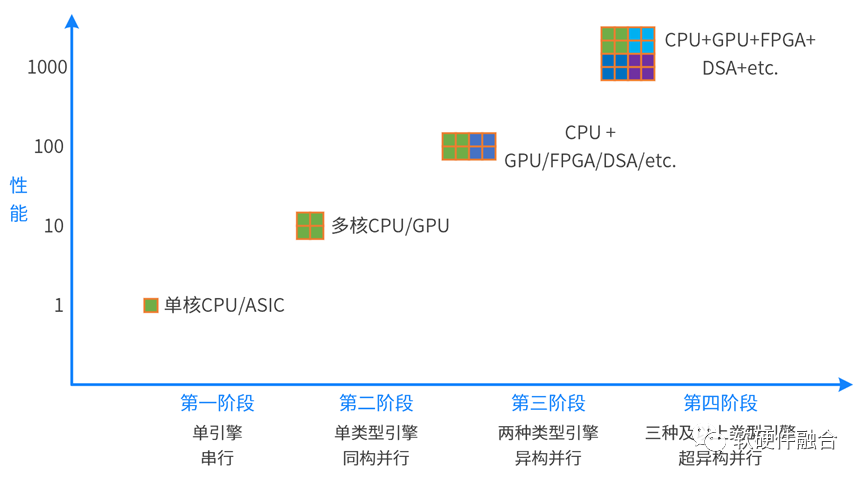
计算从单核的串行走向多核的并行;又进一步从同构并行走向异构并行。未来,计算需要进一步从异构并行走向超异构并行。
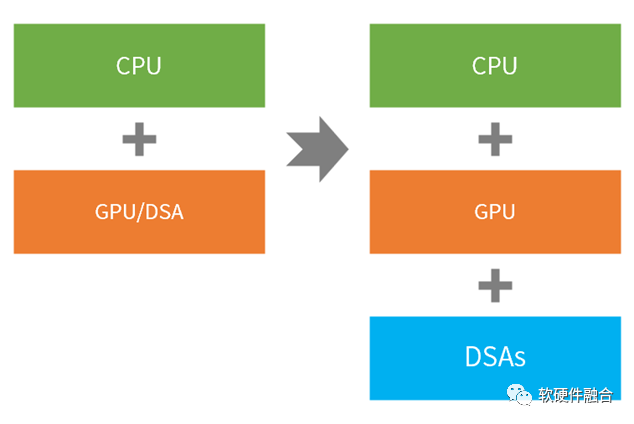
异构计算是CPU+xPU的两个层次的处理引擎类型,而超异构计算则是CPU+GPU+DSA的三个层次的处理引擎类型。
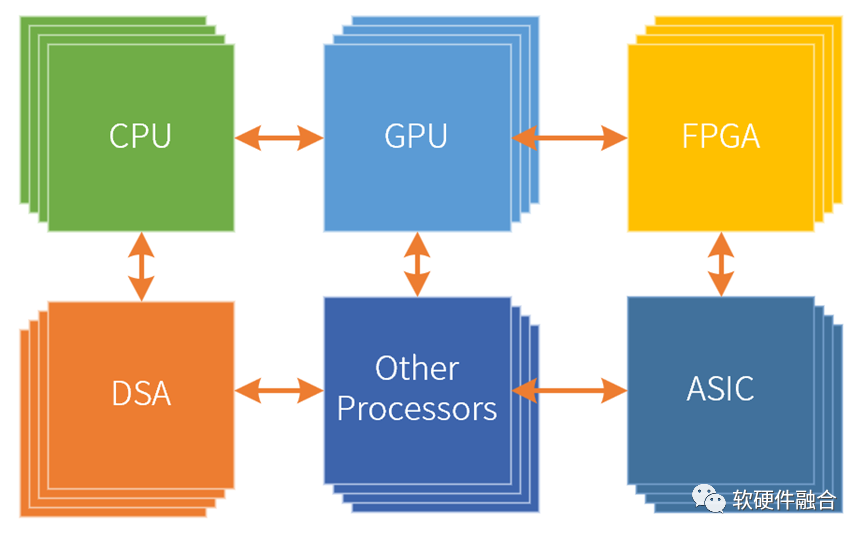
超异构计算,不是简单的集成,而是把更多的异构计算整合重构,各类型处理器间充分的、灵活的数据交互,形成统一的超异构计算宏系统。
2.5 Intel:超异构、XPU和oneAPI
2019年,Intel提出超异构计算相关概念;目前为止,Intel没有完全符合超异构概念的产品。
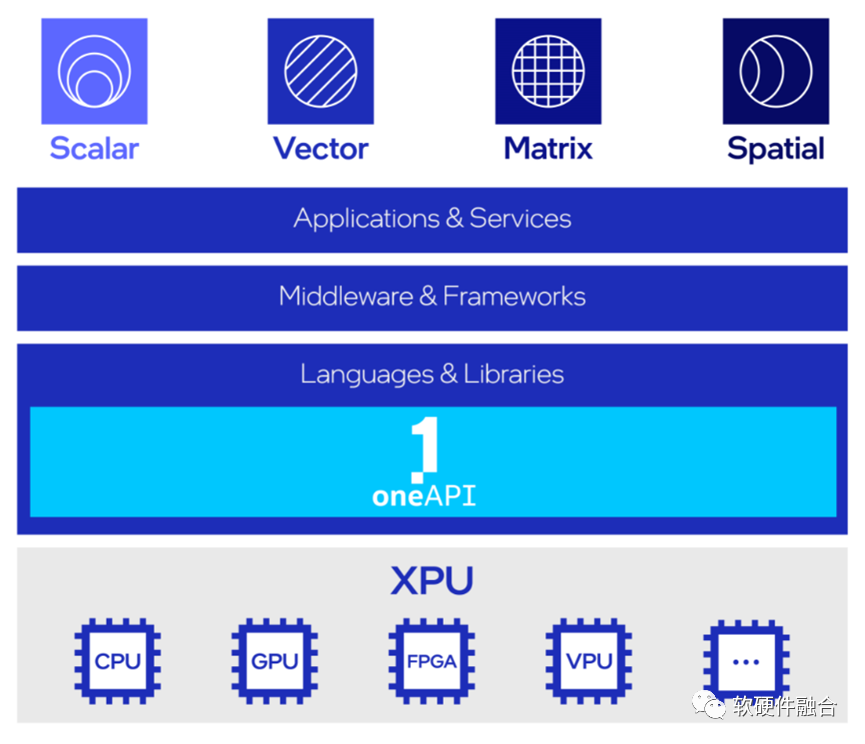
超异构计算的基础引擎是XPU,XPU是多种架构的组合,包括CPU、GPU、FPGA 和其他加速器;
oneAPI是开源的跨平台编程框架,底层是不同的XPU处理器,通过OneAPI提供一致性编程接口,使得应用跨平台复用。
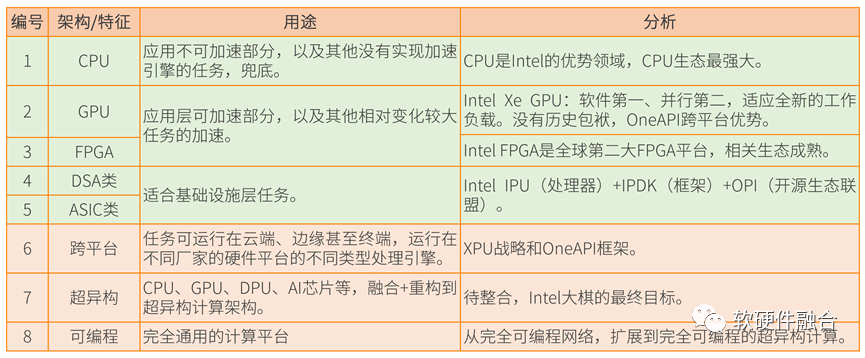
2.6 Intel超异构分析
2.7 NVIDIA自动驾驶Thor
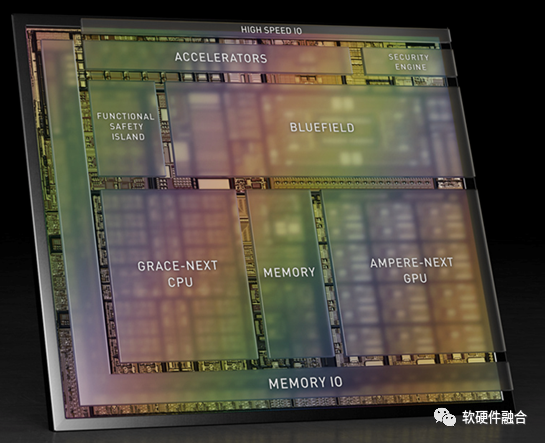
(上图为Atlan架构示意图,Atlan和Thor架构相同,性能上有差异)
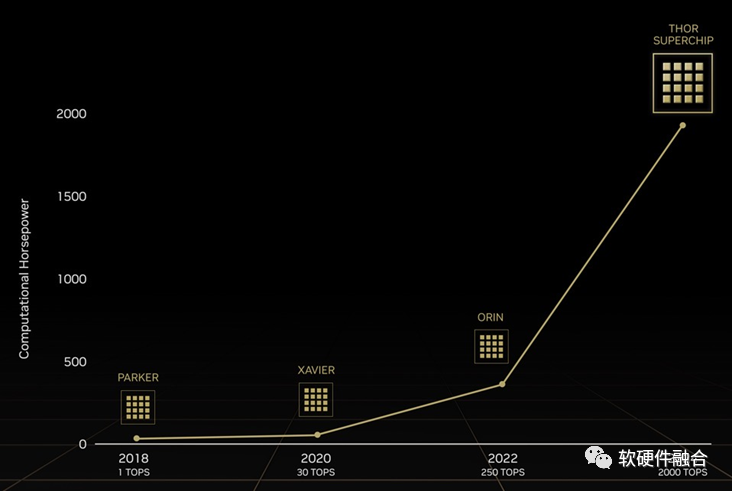
NVIDIA自动驾驶Thor芯片,由数据中心架构的CPU+GPU+DPU三部分组成,算力高达2000TFLOPS的超异构计算芯片。
Thor是把传统多个DCU(SOC)的功能融合成单个超异构处理芯片。
2.8 为什么是现在?
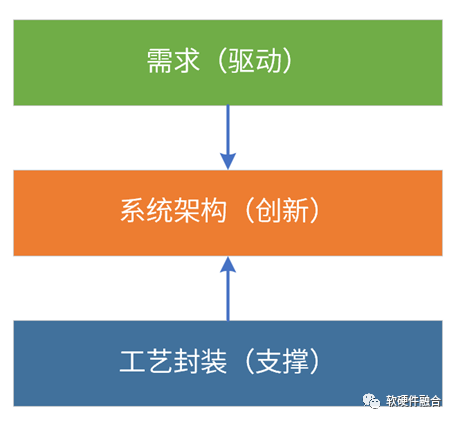
首先,是需求驱动。软件新应用层出不穷,两年一个新热点;并且,已有的热点技术仍在快速演进。元宇宙是继互联网和移动互联网之后的下一个互联网形态,要想实现元宇宙级别的体验,需将算力提升1000倍。
其次,工艺和封装支撑。工艺封装持续进步,工艺10nm以下,芯片从2D->3D->4D。Chiplet使得在单芯片层次,可以构建规模数量级提升的超大系统。系统规模越大,超异构的优势越明显。
最后,系统架构需要持续创新。通过架构创新,在单芯片层次,实现多个数量级的性能提升。挑战:异构编程很难,超异构编程更是难上加难;如何更好地驾驭超异构,是成败的关键。
2.9 小结:超异构设计和开发难度呈指数上升
软件需要跨平台复用,跨①不同架构、②不同处理器类型、③不同厂家平台、④不同位置、⑤不同设备类型。
如此复杂的超异构该如何驾驭?
3 开放架构和生态的现状
3.1 开放架构和生态综述
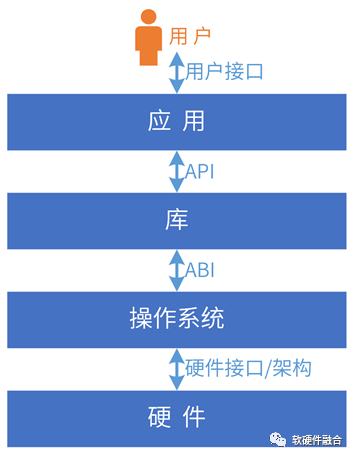
系统必然是在某个层次开放:
用户接口:应用程序必须提供UI供用户使用。
开发库:指提供函数的代码,开发者可以从自己的代码中调用这些函数来处理常见任务,如CUDA库等。
操作系统:提供系统调用接口。
硬件需要提供硬件接口/架构,给系统软件调用,如I/O接口、CPU架构、GPU架构等。
互操作性:不同的系统、模块一起协同工作并共享信息的能力。系统堆栈的相邻两层,遵循配对的接口协议进行交互;如果接口不匹配,就需要有接口转换层。
开放接口/架构及生态:基于互操作性,形成标准的开放的接口/架构;大家遵循此接口/架构开发产品和服务,从而形成开放生态。
3.2 RISC-V:开放CPU架构
x86架构主要应用在PC和数据中心领域,ARM架构主要应用在移动领域,目前也在向PC和服务器领域拓展。
为了给芯片提供低成本CPU,加州大学伯克利分校开发了RISC-V, RISC-V已成为行业标准的开放ISA。
理论上可通过静态编译、动态翻译等方式,实现跨不同CPU架构运行。但都存在损耗及稳定性等问题,需要很多移植方面的工作。
一个平台上的程序难以在其他平台上运行(静态),运行时跨平台(动态)更是难上加难。
理想情况,如果形成RISC-V的开放生态,没有了跨平台的损耗和风险,大家可以把精力专注于CPU微架构及上层软件的创新。
RISC-V的优势:
免费。指令集架构免费获取,不需要授权,没有商业上掣肘。
开放性。任何厂家就可以设计自己的RISC-v CPU,大家共建一套开放的生态,共荣共生。
简洁高效。没有历史包袱,ISA更高效。
标准化。最关键的价值。如果RISC-v变成主流架构,就没有了跨平台等成本或代价。
3.3 GPU架构生态
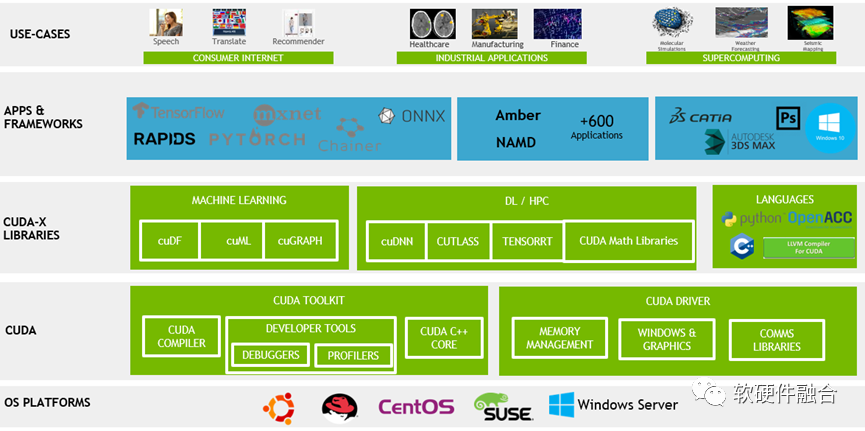
目前,GPU还没有像CPU RISC-V一样,有标准化的、开源的ISA架构。
CUDA是NVIDIA GPU的开发框架,向前兼容。
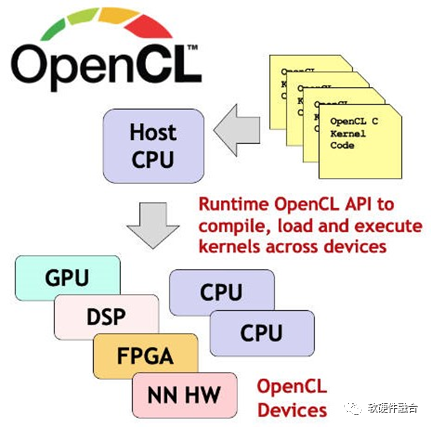
OpenCL是完全开放的异构开发框架,可以跨CPU、GPU、FPGA等处理引擎。
3.4 DSA,混战
①DSA领域多种多样,即使同一领域,②不同厂家的DSA架构仍不相同,甚至③同一厂家不同代产品的架构也不相同。
最典型的AI-DSA场景,目前就处在各种DSA架构混战的阶段。
要想构建DSA的生态:
软件定义,不需要开发应用,兼容已有软件生态;
少量编程(许多DSA编程,类似静态配置脚本),门槛较低的标准的领域编程语言;
开放架构,防止架构过多导致的市场碎片化。
DSA架构一般来说分为静态和动态两部分:
静态部分。类配置脚本,通过编译器映射到具体的DSA引擎,编程实现DSA引擎的具体功能。
动态部分。DSA的动态部分通常不是编程实现,而是跟已有软件进行适配;相当于是把软件的数据平面/计算平面卸载到硬件,控制平面依然在软件;符合软件定义的思路。
3.5 DSA/ASIC集成平台:NVIDIA DPU
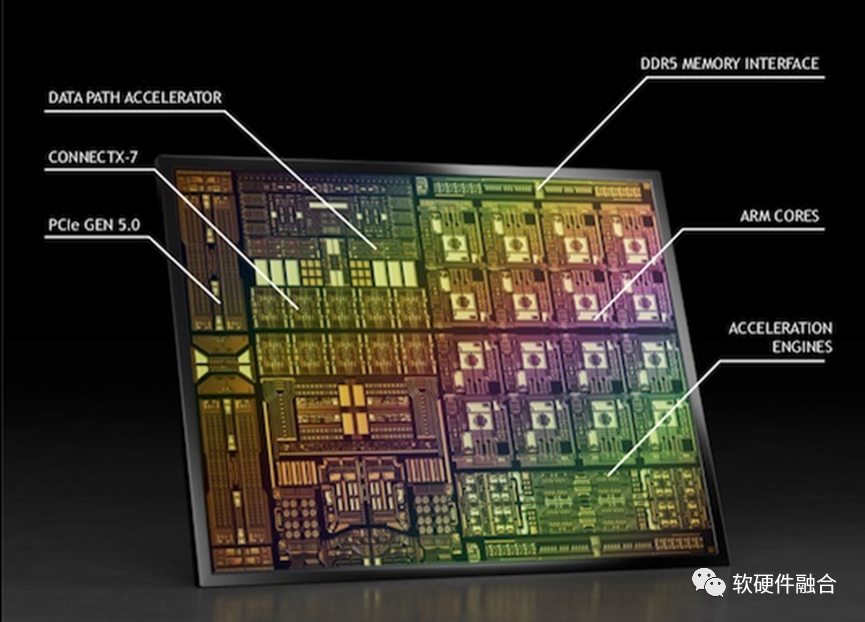
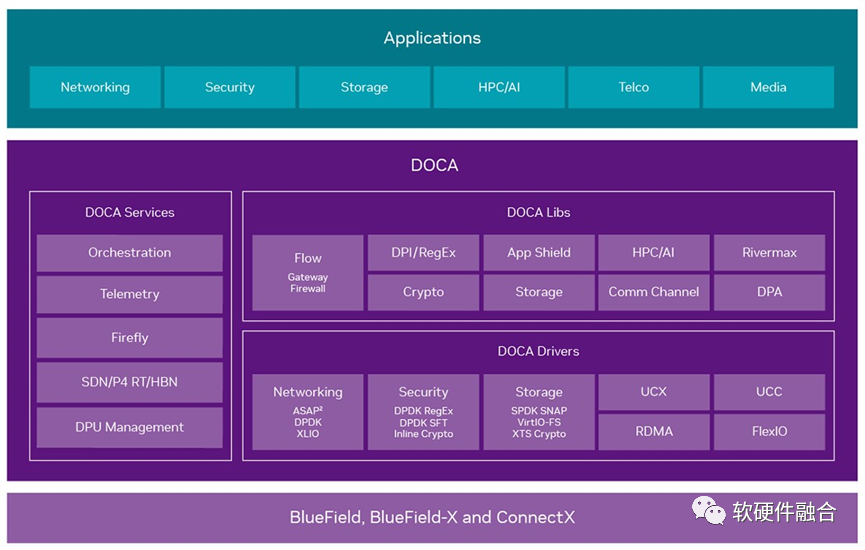
DPU集成虚拟化、网络、存储、安全等DSA/ASIC引擎,DOCA框架:库文件、运行时和服务、驱动程序组成。
DPU/DOCA是非开源/开放的封闭架构、平台和生态。
3.6 DSA/ASIC集成平台:Intel IPU
和NVIDIA DPU类似,Intel IPU集成虚拟化、网络、存储、安全等DSA/ASIC引擎。
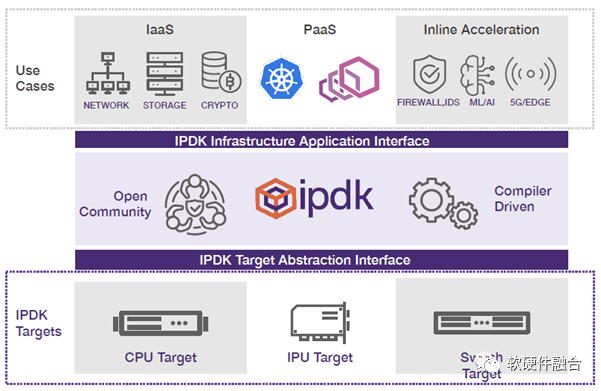
IPDK是开源的基础设施编程框架,可运行在CPU、IPU、DPU或交换机。

Intel和Linux基金会的OPI项目:为基于 DPU/IPU 类技术的下一代架构和框架,培育一个标准的开放生态系统。
Intel IPU/IPDK/OPI是开源/开放的架构、平台和生态。
3.7 硬件使能:Hardware Enablement
随着数据中心演变成虚拟机、裸金属机和容器的组合,OpenStack社区扩大成新的OpenInfra社区。
旨在推进开放基础设施领域技术发展,包括:公共云、私有云、混合云,以及AI/ML、CI/CD、容器、边缘计算等。
Ubuntu硬件使能版本:为了更好地支持最新的硬件,会经常更新内核版本,不太适合企业用户。
OpenInfra硬件使能:软件组件需要在云和边缘环境使能硬件,包括GPU、DPU、FPGA等。
在硬件加速/软件卸载的语境下,硬件使能可以理解成:
软件要支持硬件加速,“硬件加速原生”;
如果存在硬件加速的资源,则采用硬件加速模式;
如果不存在硬件加速的资源,则继续采用传统的软件运行模式。
4 硬件定义软件,还是软件定义硬件?
4.1 系统的控制平面和计算平面
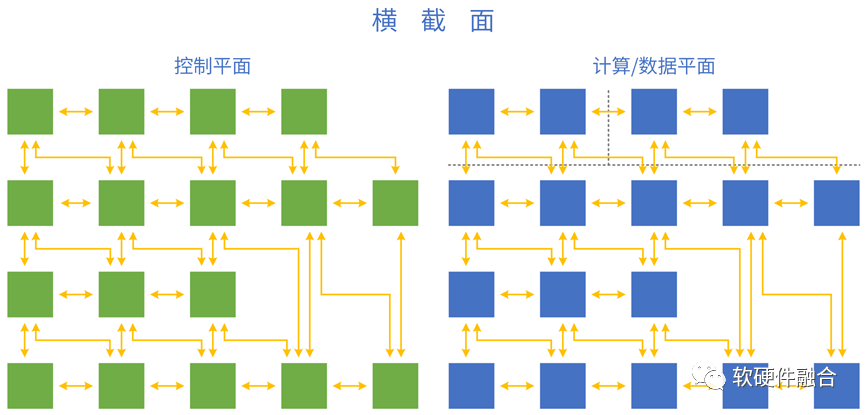
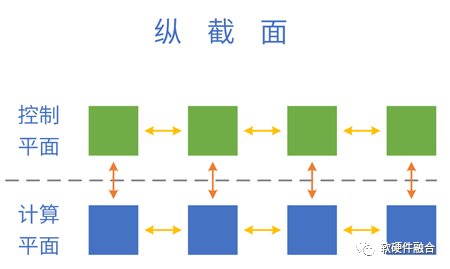
把分层分块的系统,映射到软硬件具体实现:控制平面运行在CPU,计算/数据平面运行在CPU、GPU、DSA等处理引擎。
4.2 泛义的软硬件接口
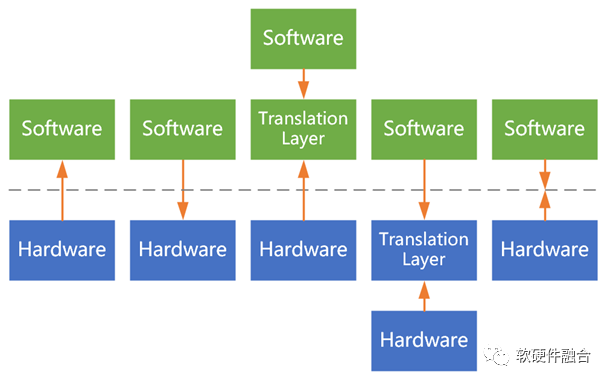
泛义的接口:
块和块之间、层和层之间的接口;
软件和软件之间、硬件和硬件之间、软硬件之间的接口。
软件和硬件之间的接口:
硬件定义接口,软件适配;
软件定义接口,硬件适配;
硬件/软件定义接口,软件接口适配层;
硬件/软件定义接口,接口适配层卸载;
软件硬件设计遵循标准接口(要求:标准、高效、开源、迭代)。
4.3 什么是硬件/软件定义?
系统是由软件和硬件组成,也必然是软硬件协同的。从软硬件的相互关系和影响,阐述软件定义和硬件定义。
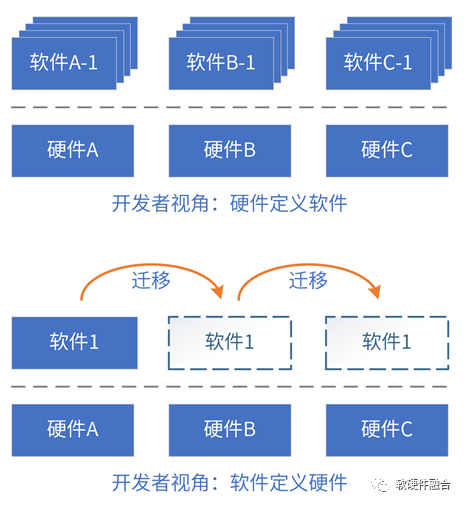
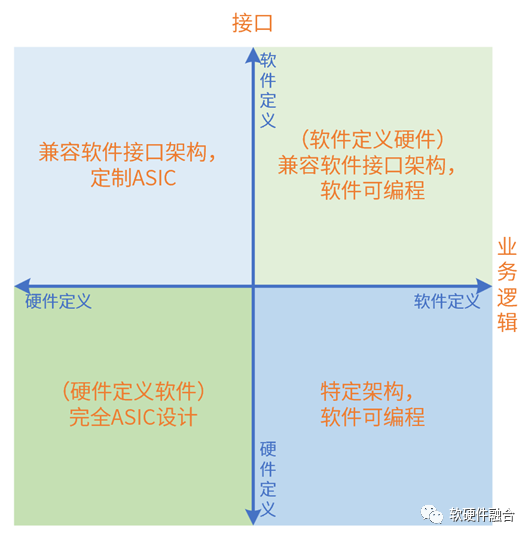
评价标准:系统的业务逻辑由谁决定;软件和硬件的交互接口(架构)由谁决定。
“硬件定义软件”定义为:系统的业务逻辑以硬件实现为主,软件实现为辅;软件依赖于硬件提供的接口构建。
“软件定义硬件”定义为:当一个系统的业务逻辑以软件实现为主,硬件实现为辅;或者硬件引擎是软件可编程的,硬件引擎按照软件编程的逻辑执行操作;硬件依赖于软件提供的接口构建。
4.4 硬件/软件定义的依据:系统复杂度
硬件定义软件,还是软件定义硬件,跟系统复杂度是休戚相关的。
系统复杂度较小,迭代较慢。可以快速设计优化的系统软硬件划分,先硬件开发,然后开始系统层和应用层的软件开发。
量变引起质变,随着系统复杂度上升,系统迭代快,直接实现一个完全优化的设计难度很大。系统实现变成了演进式:
前期系统不够稳定,算法和业务逻辑在快速迭代,需要快速实现想法。这样,基于CPU的软件实现就比较合适;
随着系统发展,算法和业务逻辑逐渐稳定,后续逐步优化到GPU、DSA等硬件加速来持续优化性能。
硬件定义还是软件定义?本质上是系统定义。系统的复杂度过高,实现难以一次到位,于是系统的实现,变成了持续优化和迭代的过程。
4.5 硬件/软件定义的本质:归纳和演绎
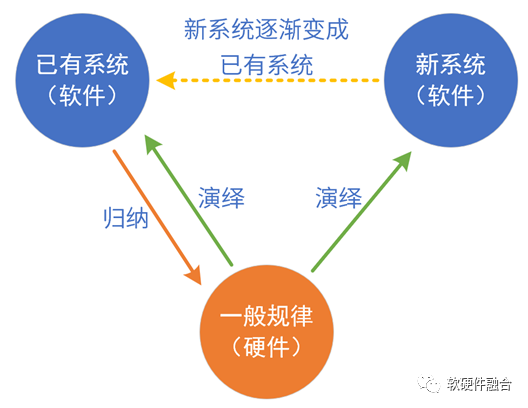
硬件/软件定义的本质,是通过归纳和演绎实现系统及系统的发展。从长期和发展的视角看,系统是由软硬件共同定义的。我们以典型的处理引擎实现进行分析:
CPU:把所有领域归纳出共性(最基本的指令),这个共性“放之四海皆准”。也即是说,相对其他平台,“CPU不需要再归纳”,只需要持续演绎新的领域和场景。软件定义:CPU已经是成熟的软件平台,可以基于CPU快速实现系统原型,当系统的算法和业务逻辑稳定后,可通过硬件加速进行性能优化。
GPU:把很多个领域归纳出共性,然后硬件实现共性,软件实现个性。GPU平台实现后,可以持续演绎新的领域新的场景。GPU是足够通用、成熟的并行计算开发平台。
DSA:把某个领域多个场景的业务逻辑进行归纳:硬件实现共性部分,软件实现个性部分。DSA平台实现后,可以在此领域演绎新的场景。
ASIC:具体场景的算法和业务逻辑直接变成硬件,软件只是基本的控制作用。直接映射,谈不上归纳和演绎。
5 总结:软硬件共同定义,超异构开放生态
5.1 软件原生支持硬件加速
软件原生支持硬件加速:
软件架构调整,控制面和计算/数据面分开;
控制面和计算/数据面接口标准化;
硬件加速资源的发现能力,自适应选择软件计算/数据面或硬件计算/数据面。
数据的输入,可以来源于软件,也可以来源于硬件;
数据的输出,可以去向软件,也可以去向硬件。
5.2 完全可编程
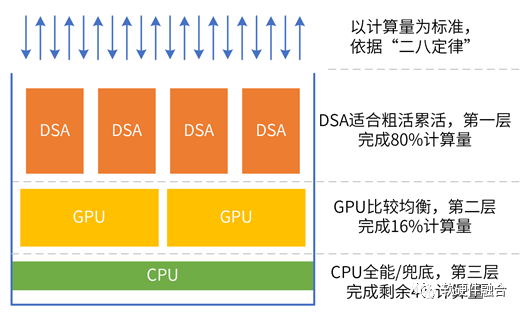
完全可编程,不是CPU可编程,而是在极致优化性能基础之上的可编程。完全可编程是分层的可编程体系:
基础设施层可编程。基础设施层Workload不经常变化,可以采用DSA架构。
弹性应用可编程。支持主流GPU编程方式,可以把常见应用通过DSA,实现更高效率的加速。
应用可编程。应用不确定性最大,仍然运行在CPU。同时,CPU负责兜底,所有其他不适合加速或没有加速引擎的任务都在CPU运行。
实现完全可编程的同时,性能数量级的提升:
从整个系统看,绝大部分是DSA加速的,因此系统的性能效率接近于DSA;
Chiplet+超异构,系统规模数量级提升,系统性能数量级提升;
从用户角度,应用运行在CPU,用户体验到的是100%的CPU可编程。
5.3 开放接口和架构
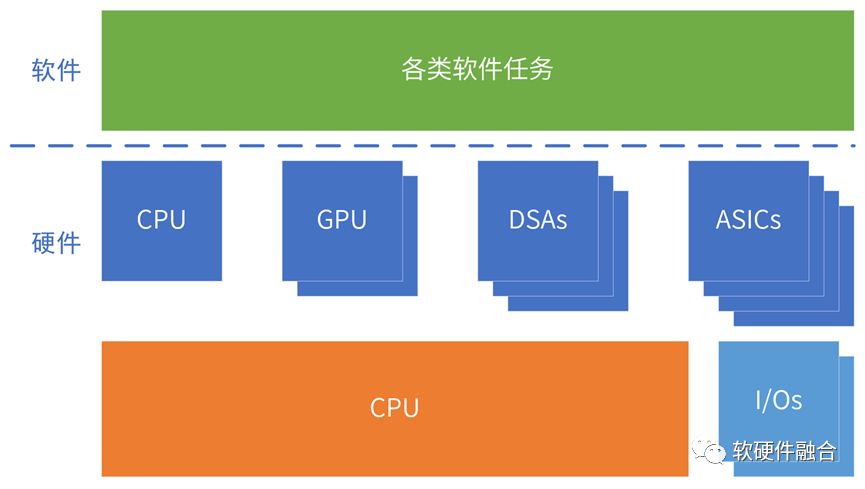
ASIC/DSA覆盖的领域/场景较小,芯片对场景的覆盖(相比CPU、GPU)越来越碎片化。
构建生态越来越困难。需要从硬件定义,逐步转向软件定义。
超异构计算,包括CPU、GPU,也包括多种DSA、ASIC类型的处理器。
异构的引擎架构越来越多,必须构建高效的、标准的、开放的接口和架构体系,才能构建一致性的宏架构(多种架构组合)平台,才能避免场景覆盖的碎片化。
5.4 计算需要跨不同类型处理器
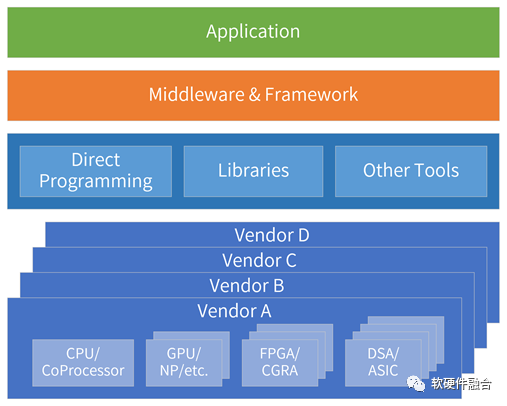
超异构包含CPU、GPU、FPGA、DSA等不同类型的处理器,计算任务需要跨不同类型的处理器运行。
oneAPI是Intel开源的跨平台编程框架,通过oneAPI提供一致性编程接口,使得应用可以跨不同类型处理器运行。
更广泛的,不仅仅是跨不同类型的处理器,还要能跨不同厂家的芯片平台。
5.5 超异构开放生态
要想提升算力利用率,就需要把一个个孤岛的计算资源,整合成统一的资源池。
需要通过跨平台融合,实现计算资源池化:
维度一:跨同类型处理器架构。如软件可以跨x86、ARM和RISC-v CPU运行。
维度二:跨不同类型处理器架构。软件需要跨CPU、GPU、FPGA和DSA等处理器运行。
维度三:跨不同的芯片平台。如软件可以在Intel、NVIDIA等不同公司的芯片上运行。
维度四:跨云网边端不同的位置。计算可以根据各种因素的变化,自适应的运行在云网边端最合适的位置。
维度五:跨不同的云网边服务供应商、不同的终端用户、不同的终端设备类型。
超异构时代,必须要形成开放的生态,才能让计算资源形成一个整体,才能满足元宇宙等应用场景对算力数量级提升的要求。
5.6 软硬件共同定义:超异构开放生态
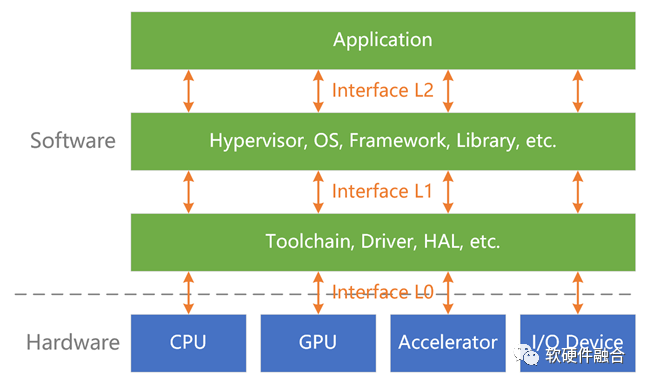
首先,是超异构计算架构。CPU+GPU+FPGA+DSA等多种架构处理引擎组成的超异构计算;实现既要又要:接近CPU的灵活性,接近ASIC的性能效率,以及多个数量级提升的性能。
其次,要平台化&可编程。两个一切:软件定义一切,硬件加速一切;两个完全:完全可软件编程的硬件加速平台,完全由软件编程决定业务逻辑;一个通用:足够的通用性,满足多场景、多用户的需求,满足业务的长期演进。
最后,要标准&开放。架构/接口标准、开放,持续演进;拥抱开源开放的生态;支持云原生、云网边端融合;用户无(硬件、框架等)平台依赖。
编辑:黄飞
-
IC datasheet为什么越来越薄了?2024-03-06 4912
-
嵌入式会越来越卷吗?2024-03-18 9073
-
为什么原厂越来越需要一套自己的 Studio2026-02-05 1154
-
在当今的社会噪音越来越影响人的正常生活了2011-12-16 2708
-
新人报道,祝论坛越来越旺2012-04-02 1650
-
蓝牙技术越来越鸡肋2012-09-16 2489
-
为什么红外热像仪越来越受欢迎2014-09-12 3294
-
为什么说射频测试中便携式仪器越来越重要?2019-08-12 2246
-
在仿真电路中的INL为什么越来越差?有人知道问题大概在哪里吗2021-06-24 2067
-
MCU和MPU之间的区别变得越来越模糊2021-11-01 1414
-
从FPGA到ASIC,异曲同工还是南辕北辙?2023-03-28 2007
-
随着互联网、信息技术的发展 安防行业“碎片化”问题越来越突出2019-05-07 1301
-
设计全定制ASIC以占用尽可能多的硅面积变得越来越具有挑战性2019-08-13 2832
-
后摩尔时代:芯片不是越来越凉,而是越来越烫2025-07-12 2909
-
FPGA技术为什么越来越牛,这是有原因的2025-08-22 5472
全部0条评论

快来发表一下你的评论吧 !
