

Merlin HugeCTR v4.3 发布说明
描述
NVIDIA Merlin HugeCTR(以下简称 HugeCTR)是 GPU 加速的推荐框架,旨在在多个 GPU 和节点之间分配训练并估计点击率(Click-through rate)。作为一个开源框架,HugeCTR 能够优化 NVIDIA GPU 上的大规模推荐。近期,HugeCTR 发布了 v4.3 版本,让我们一同了解一下此次更新的详细内容!
新增内容
HugeCTR 第三代 Embedding 更新:
-
第三代 Embedding 功能优化:自从在 v3.7 中引入新一代 HugeCTR Embedding 以来,进行了一些更新和优化,包括代码重构以提高可用性。此版本的增强功能如下:
-
EmbeddingPlanner 类替换为 EmbeddingCollectionConfig 类。有关 API 的示例,请参阅 test/embedding_collection_test 目录。
-
优化了一些 API ,以支持训练过程中模型导入和导出。这些方法是 Model.embedding_dump(path: str, table_names: list[str]) 和 Model.embedding_load(path: str, list[str])。路径参数是文件系统中的一个目录,您可以将模型权重存储到该目录或从中加载权重。table_names 参数是 Embedding 表名的列表。
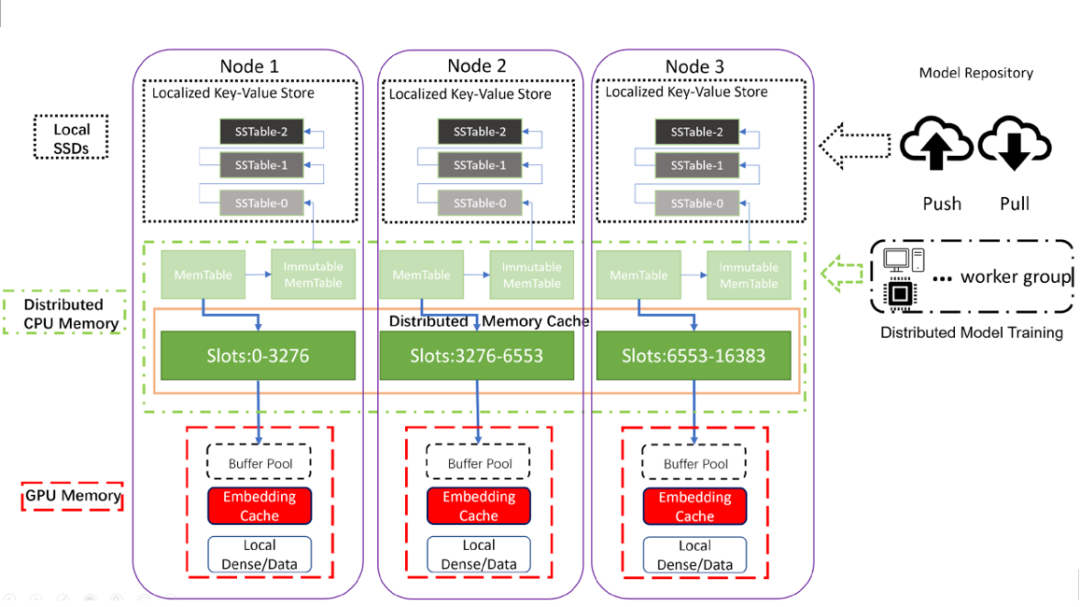
图 1:HugeCTR 分层参数服务器(HPS)架构
HugeCTR 分层参数服务器(HPS)更新:
-
RedisClusterBackend 现在支持 TLS/SSL 通信。相关示例代码,请参阅分层参数服务器演示笔记本。该笔记本更新了分步说明,向您展示如何设置 HPS 以使用带(和不带)加密的 Redis。同时, 易失性数据库参数 文档对 enable_tls、tls_ca_certificate、tls_client_certificate、tls_client_key 和 tls_server_name_identification 等参数进行了更新。
-
对 Embedding 缓存添加了静态表支持。当 Embedding 表可以完全放在 GPU 内存中时,静态表是合适的。在这种情况下,静态表比 Embedding 缓存查找快三倍以上。当然,静态表将不支持 Embedding 的更新。
-
用于 TensorFlow 与 TensorFlow-TensorRT 集成的 HPS 插件 (TF-TRT):有关示例代码请参阅部署 SavedModel 笔记本
-
Redis 或 Kafka 使用的更改:更新了用 RedisClusterBackend 和用 Kafka 参数流部署模型的方式。使用了 HPS 分区选择算法的第三方库以提高性能。新算法可以为易失性数据库生成不同的分区分配。
-
新易失性数据库类型:此版本将 multi_process_hash_map 的 db_type 值添加到分层参数服务器。此数据库类型支持使用共享内存和 /dev/shm 设备文件跨进程的共享 Embedding。运行 HPS 的多个进程可以读取和写入同一个哈希映射。
-
HPS Redis 后端的优化:在此版本中,分层参数服务器可以并行打开多个连接到每个 Redis 节点。此增强功能使 HPS 能够利用 Redis 服务器 I/O 模块中的重叠处理优化。此外,HPS 现在可以利用 Redis 散列标签来共同定位 Embedding 值和元数据。此增强功能可以减少对 Redis 节点的访问次数以及完成事务所需的每个节点往返通信的次数。
-
向 ONNX 模型转换器添加了多任务模型支持:此版本向 ONNX 转换器添加了对多任务模型的支持。此版本还包括对 preprocess_census.py 脚本的更新。
-
删除了对一些库的依赖。
Layer 以及优化器的更新以及新的模型支持:
-
增加了对动态 Embedding 表 (DET) 的 SGD、Momentum SGD、Nesterov Momentum、AdaGrad、RMS-Prop、Adam 和 FTRL 优化器的支持。示例代码请参考目录中的test_embedding_table_optimizer.cpp 文件 test/utest/embedding_collection/ 目录。
-
添加了对稠密网络 FTRL 优化器的支持。
-
支持了 BERT 和其变体:包括对 MultiHeadAttention 层并为序列掩码层。有关详细信息,请参阅 samples/bst 目录。
-
Deep & Cross Network Layer 版本 2 支持:有关概念信息,请参阅 https://arxiv.org/abs/2008.13535。多交叉层文档也已更新。
-
MLP Layer 更新:添加了一个带有 hugectr.Layer_t.MLP 类的 MLP 层。该层非常灵活,可以更轻松地使用一组融合的全连接层并启用相关优化。对于 MLPLayer 中的每个融合全连接层,输出维度、偏差和激活函数都是可调的。MLPLayer 支持 FP32、FP16 和 TF32 数据类型。有关示例请参阅 dlrm 目录中的 dgx_a100_mlp.py 以了解如何使用该层。
Sparse Operation Kit(SOK) 的更新:
-
DeepRec 中 Sparse Operation Kit 的增强功能:此版本包括对 Sparse Operation Kit 的更新,以提高 DeepRec 中 Embedding 变量查找操作的性能。lookup_sparse() 函数的 API 已更改以删除热度参数。lookup_sparse() 函数得到优化,可以动态计算非零元素的数量。有关详细信息,请参阅 sparse_operation_kit 目录 。
-
Sparse Operation Kit 可从 PyPi 安装:1.1.4 版的 SOK 可从 PyPi 安装了。
HugeCTR I/O 模块更新:
-
支持了在离线推理中从远端文件系统(HDFS, S3 等)中读取推理数据:HugeCTR 除了训练时读取外,现在还支持离线推理时通过 DataSourceParams API 从远程文件系统如 HDFS 和 S3 读取数据。HugeCTR Training and Inference with Remote File System Example 已更新以展示这个新功能。
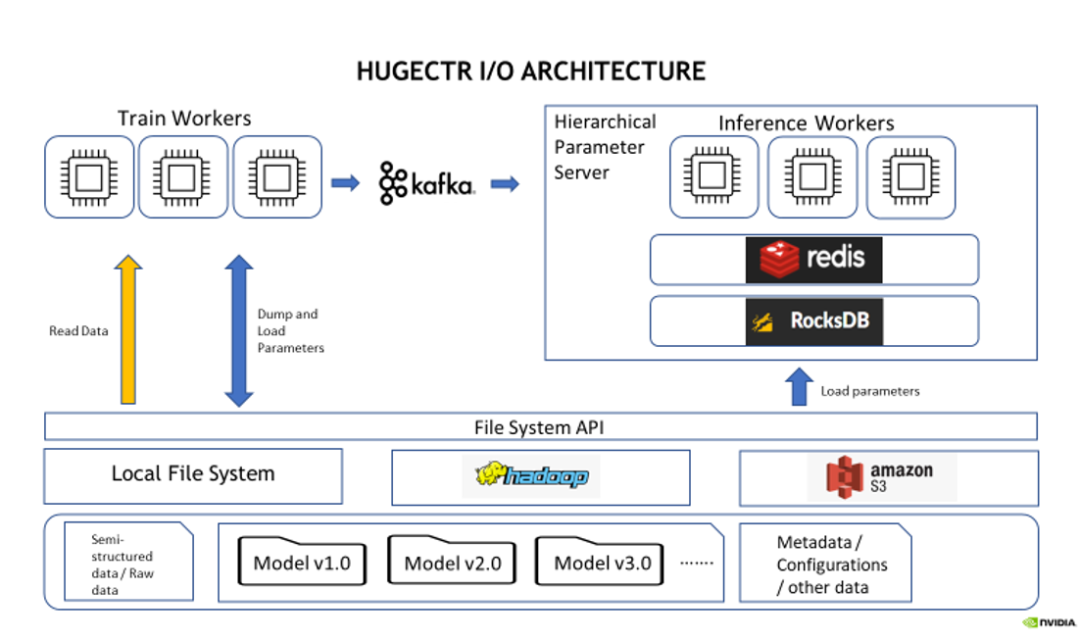
图 2:HugeCTR I/O 模块功能架构
文档和示例更新:
-
为了帮助用户配置 Jupyter Notebook 的运行环境,新增了运行示例笔记本 。
-
提高了数据预处理脚本的易用性。
-
MLP 层的文档更新了。
-
新增了 2022 年的 HugeCTR 相关演讲和博客:HugeCTR 演讲和博客 。
修复的问题
-
修复了 MultiProcessHashMapBackend 在使用基于 JSON 文件的配置时阻止配置共享内存大小的错误。
-
在调用某些 HugeCTR API 之前具有 NUMA 绑定的原始 CUDA 设备现在可以正确恢复。
-
修复了使用宏 DEBUG 安装 HugeCTR 时偶尔出现的 Embedding CUDA 内核启动失败的问题。
-
修复了与 TensorFlow v2.1.0 及更高版本相关的 SOK 构建错误。
-
修复了与 CUDA 12 相关的编译错误。
已知问题
以下是目前 HugeCTR 存在的已知问题,我们将在之后的版本中尽快修复:
-
如果客户端代码调用 RMM rmm::set_current_device_resource() 方法或 rmm::set_current_device_resource() 方法,HugeCTR 可能会出现运行时错误。该错误是由于 HugeCTR 中的 Parquet 数据读取器也调用了 rmm::set_current_device_resource(),因此该设备对同一进程中的其他库可见。参考 GitHub 问题 #356 以获取更多信息。作为解决方法,如果您知道 rmm::set_current_device_resource() 被 HugeCTR 以外的客户端代码调用,您可以将环境变量 HCTR_RMM_SETTABLE 设置为 0 以防止 HugeCTR 设置自定义 RMM 设备资源。但要小心,因为该设置会降低 Parquet 读取的性能。
-
HugeCTR 使用 NCCL 在队列之间共享数据,并且 NCCL 可能需要共享系统内存用于 IPC 和固定(页面锁定)系统内存资源。如果您在容器内使用 NCCL,请在启动容器时通过指定参数 -shm-size=1g -ulimit memlock=-1 来增加这些资源。
-
即使目标 Kafka 代理没有响应,KafkaProducers 启动也会成功。为避免与来自 Kafka 的流模型更新相关的数据丢失,您必须确保足够数量的 Kafka 代理正在运行、正常运行,并且可以从运行 HugeCTR 的节点访问。
-
文件列表中的数据文件数量应大于或等于数据读取器工作人员的数量。否则,不同的 worker 会映射到同一个文件,并且数据加载不会按预期进行。
-
暂时不支持使用正则化器的联合损失训练。
-
暂时不支持将 Adam 优化器状态导出到 AWS S3。
HugeCTR v4.3 发布说明,已更新至 GitHub 和文档:
GitHub:
https://github.com/NVIDIA-Merlin/HugeCTR
文档:
https://nvidia-merlin.github.io/HugeCTR/master/hugectr_user_guide.html
从 2023 年一月起,HugeCTR 的版本号将从数字版本(v.4.4)变更为年历版本(v23.01)。
原文标题:Merlin HugeCTR v4.3 发布说明
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 英伟达
-
请问lyrat mini和lyrat v4.3开发板声音输出底噪很大是什么原因?2024-06-28 354
-
【软件更新】Gecko SDK v4.3版现已可用,全面优化IoT无线协议开发2023-06-19 2134
-
UM-B-041: User 手册 DA1458x-DA1468x Production Line Tool 软件 and HW v4.32023-03-13 542
-
lyrat v4.3想实现通过两个mic录音,录音文件很嘈杂怎么解决?2023-03-10 587
-
idf的版本release/V4.3是不是用不了master版本的例程?2023-02-17 501
-
Merlin HugeCTR第三代 Embedding 功能优化2022-10-20 2109
-
Merlin HugeCTRV 3.8/3.9版本新增内容2022-08-24 1339
-
Merlin HugeCTR v3.6和v3.7版本新增内容介绍2022-06-17 1927
-
如何使用NVIDIA Merlin推荐系统框架实现嵌入优化2022-04-02 2814
-
GPU加速的推荐程序框架Merlin HugeCTR2022-03-20 3176
-
Merlin HugeCTR V3.4.1版本新增内容介绍2022-03-10 2073
-
中兴ZXD2400 V4.3电源模块电路图分享2021-12-29 14290
-
Benchlink V4.3中的错误?2019-05-06 1128
-
WH-500800编程器软件V4.32013-10-19 14111
全部0条评论

快来发表一下你的评论吧 !
