

地址边界与地址对齐
电子说
描述
数据传输是基于地址进行的。在分析和设计微架构时,除了地址域之外,如何选择地址信号,我觉得也是值得注意的问题。
地址边界
还记得刚开始工作时,被安排维护AXI总线重排序的公共模块,当时有一个地址对齐的概念,如64Byte地址边界、128Byte或者256Byte地址边界,那会花了有一段时间才搞清楚,但也仅仅是搞清楚,也不清楚引入这一概念的原因,能解决哪些问题。
所谓地址边界,若某地址能够被一整数除净,该地址就称为整数对应的地址边界。在系统内都是以0/1的二进制,这一整数一般指的是2的幂次方,如4、8、16、64、128等等。举例来说,0x200, 0x240, 0x880等等都是64Byte地址边界;0x200,0x880是128Byte地址边界,但0x240不是128Byte地址边界。再谈谈CacheLine的概念。为提升系统访问内存的速度,通常会引入缓存Cache,也就是将Memory的内容先搬运到CPU附近。这一缓存是以块为单位的,需要访问时,则先将对应的缓存块搬运到Cache内。这一缓存块就称为CacheLine,是缓存Cahe管理的最小单位,可基于系统需求选择大小,如64Byte或128Byte,甚至是4KByte。每个CacheLine,除了存储其本身的数据之外,还需要记录其地址、是否修改等等额外信息。粒度越小,记录额外信息的资源占比越大;粒度大了,又会对数据的利用率下降;具体大小则需基于需求来确定,如对于AI/GPU计算,可考虑使用4KByte的Caheline。
地址对齐
在考虑微架构设计和软硬件接口时,访问Memory尽可能按照整块地址的访问,地址边界对齐,尤其是写操作。在一般的CPU计算机系统,采用的地址边界大小至少为64Byte,使用更大的区间,如128Byte/256Byt,在一些场景也是能够带来收益的。
数据总线利用率
系统互联总线的位宽较大,如128、256、512bit,甚至2048bit。但是,每一拍数据的地址并不是随机,而必须基于一定规则排列,参考AXI协议,如256bits的数据位宽,其地址低位必须是0-31。传输32Byte数据,若起始地址为32Byte边界对齐,1拍可以传输完成,利用率为100%,否则需要占用2拍,其利用率只有50%。
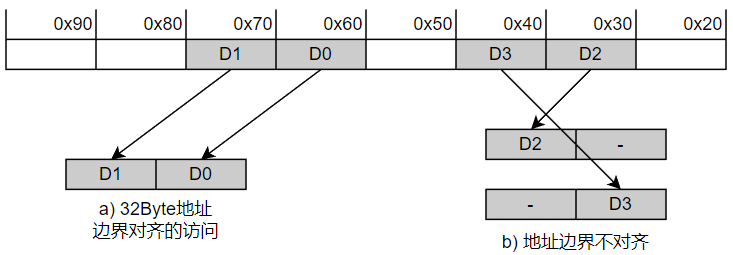
对于PCIe数据传输来说,其数据长度单位为DW,即4Byte,因此由于地址边界不对齐带来的影响比较小。
Full/Partial Write
系统存在CacheLine的定义,若访问操作为整CacheLine的写操作,则称为Full Write,否则为Partial Write。举例,CacheLine为64Byte,若访问地址低6位为0,长度为64Byte,就是Full Write;低6位不为0,或长度不为64Byte整数倍,则存在Partial操作。非地址对齐的访问操作,容易造成Partial Write,引入性能问题。
Read-modify-write
对于Cache、DDR,或者其余类似的Memory系统,存在最小操作粒度的概念。若写访问操作小于该最小操作粒度,则需要引入Read-modify-write。将对应地址的数据块读取出来,进行修改,再将数据写入对应地址,需要占用读通道的带宽。对于地址对齐的整块访问,直接写入即可。
DMA的地址选择
Host与PCIe Device之间大量数据的传输,基本都是由DMA(Direct Memory Access)完成的。简单来说,DMA就是从一个地址(源地址)读取连续的数据,再写入到另一个地址(目的地址)。硬件逻辑提供源地址、目的地址和搬运长度的软件编程接口,再被软件进行调用。复杂一些的硬件实现,还可以支持描述符、链表、搬运方式配置和其余系统属性的配置等等特性,如支持完成中断。
至于对数据搬运的地址选择,则是由调用DMA的软件进行控制的,但是也会受到上下游模块的约束,如Device侧的硬件引擎模块等等。
在考虑DMA数据流时,需基于系统层面对各模块的数据访问需求进行设计,尽可能使得DMA在Host和Device之间的数据搬运是地址边界对齐的。这一对齐包含两个方面,一是访问Device/Host的读写访问是基于地址边界对齐,二是源地址和目的地址的低位是相等的。两者其实是类似的,没有满足后者,也会引入大量的非地址对齐的操作。至于后者的地址低位,则需基于硬件实现进行考虑,考虑点就是上面描述的几点要素。
再来看看第二方面引入的逻辑复杂度,源地址和目的地址的低位相等。考虑源和目的方向使用了AMBA总线,数据位宽为512bit/64Byte,若需支持地址不对齐的场景,则需要512个64bit位宽的MUX;若仅需支持地址的低6bit相等,则完全不需要进行移位处理;若仅需支持地址的低2bit性能,硬件逻辑规模也减小为512个16bit位宽的MUX。大量的MUX逻辑也容易引入Congestion风险,需要做额外的优化处理。

结语
地址对齐的概念非常简单,但容易被忽略。对于软件人员来说,DMA就是应该支持任意地址到任意地址的数据搬运;但对硬件设计来说,可能需要付出很大的代价才能达成要求。可以考虑做一些折衷,软件做一些简单修改,使用地址对齐的数据搬运,硬件实现侧对地址对齐的操作进行尽量的优化,而对非地址对齐的做一些简化处理,不考虑性能但满足功能,达到较优的PPA。
-
CW32操作FLASH地址对齐的要求2025-12-15 159
-
购买海外虚拟IP地址可以通过以下几种方式#虚拟IP地址jf_62215197 2024-08-16
-
如何实现局部数组的地址对齐?2019-08-27 1441
-
【工程源码】NIOS II 自定义IP核的静态地址对齐和动态地址对齐2020-02-27 1636
-
探讨一下地址边界与地址对齐的概念及其选择2022-09-07 3516
-
请问MDK怎么让一个函数对齐到1K地址边界?2023-11-03 513
-
IP地址,IP地址是什么意思2010-04-03 1933
-
ATM地址,ATM地址是什么意思2010-04-06 1738
-
mac地址和ip地址是什么决定的2018-03-07 8482
-
什么叫偏移地址_偏移地址怎么计算2018-04-16 110350
-
一个跟地址对齐有关的应用异常案例2019-02-04 3301
-
工程师笔记|一个地址未对齐引起的 HardFault 异常2023-02-10 4596
-
一个地址未对齐引起的HardFault异常2023-09-18 1873
-
AXI总线:读写地址结构2023-10-31 2841
-
怎么绑定IP地址和MAC地址2024-12-01 3651
全部0条评论

快来发表一下你的评论吧 !
