

UDP和TCP的区别
描述
UDP 和 TCP 的区别
在上一则文章中,对 TCP 的三次握手建立连接和四次挥手释放连接进行了详细地阐述,本节教程针对于 TCP 的其他内容进行讲解,首先是同处于传输层协议的UDP协议,这两者有什么区别与联系呢?
相同点那就是说:UDP 和 TCP 是 TCP/IP 体系结构运输层中的两个重要协议,下图是TCP/IP的体系结构图:
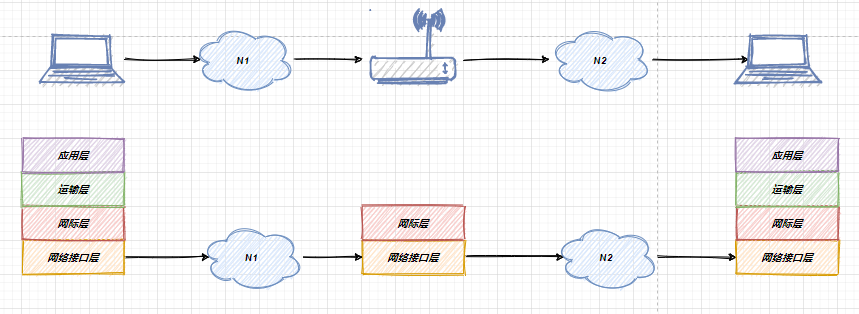
额外补充的一点就是说,在 TCP和 UDP 协议下层的IP协议,IP协议可以为各种网络应用提供服务,使用IP层协议互连不同的网络接口,下面是一个结构图:
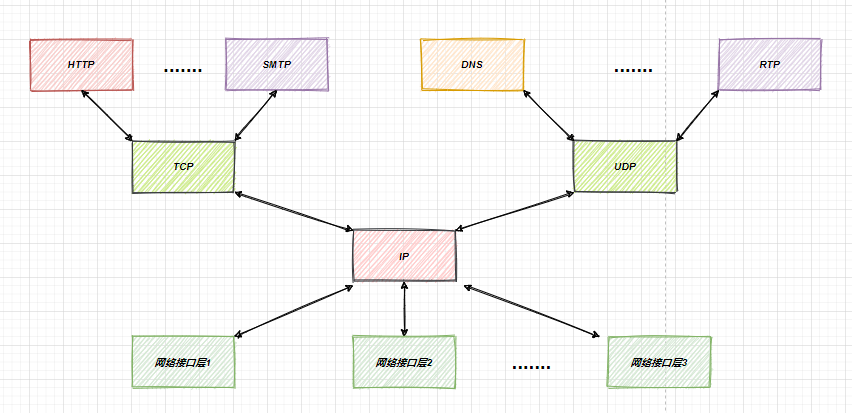
image-20210718234432031
TCP和UDP的使用频率也仅次于位于网际层的IP协议。
UDP也称之为是用户数据报协议,而TCP呢,被称之为传输控制协议,比较显著的一点区别就是说,UDP 是无连接的,而TCP 是面向连接的,下面是两种通信方式通信的一个示意图:
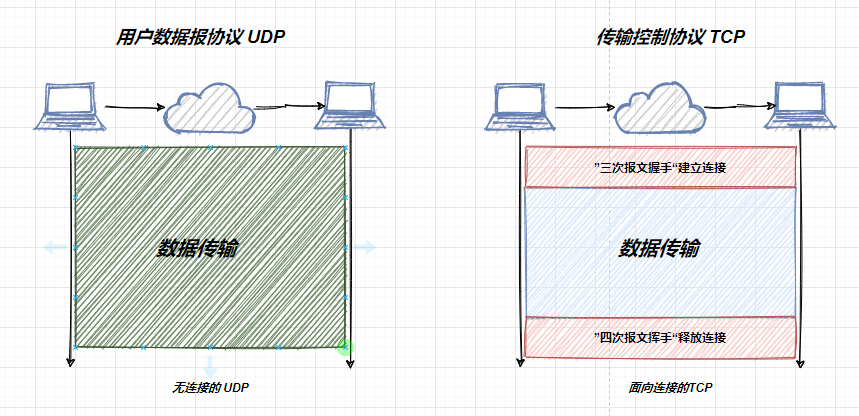
image-20210718235508609
如上图所示,对于UDP来讲,其无需建立连接就能够进行数据传输,而对于 TCP来讲,其在进行数据传输之前,需要进行“三报文握手”建立连接,然后才进行数据传输,数据传输完成之后,还需要进行“四报文挥手”释放连接。
也正是因为UDP无连接的特性,对于UDP来说,其支持 单播、多播以及广播 ,而对于TCP来说,因为三次握手建立的的连接,它有了一条可靠的信道,它也就仅仅支持 单播 ,下面是两个通信方式的示意图:
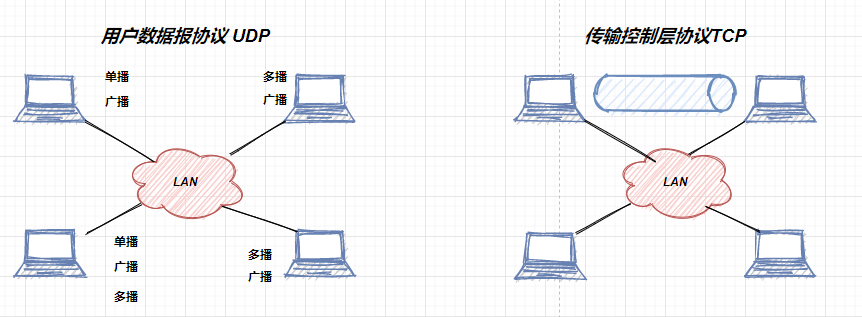
image-20210719000338512
紧接着,分析一下UDP和TCP数据传输的详细过程
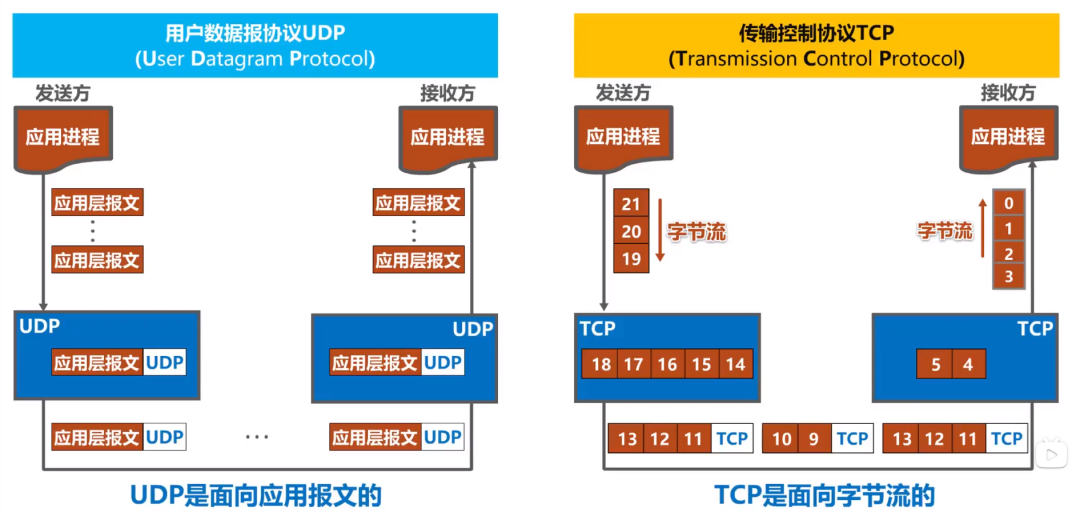
image-20210706213718285
可以看到,对于 UDP来讲,其是面向应用报文的,发送方的应用进程将应用报文交付给传输层的UDP,UDP直接给应用层报文添加一个UDP首部,使之成为UDP用户数据报,然后进行发送,接收方的UDP收到该UDP用户数据报后,去掉UDP首部,将应用层报文交付给应用进程,换言之,就是说UDP对应用进程交下来的报文既不合并也不拆分,而是保留这些报文的边界,也就是说,UDP是面向应用报文的。
紧接着,上图的右边是TCP的数据发送流程,发送方的TCP把应用进程交付下来的数据块看作是一连串的无结构的字节流,TCP并不知道这些待传送的字节流的含义,仅仅将他们编号,并存储在自己的发送缓存中,TCP根据发送策略,从发送缓存中提取出一定数量的字节,构建TCP报文段并发送,接收方的TCP一方面从接收到的TCP报文中取出数据载荷部分并存储在接收缓存中,一方面将接收缓存中的一些字节交付给应用进程,TCP不保证所收到的数据块与发送方应用进程所发出的数据块具有对应大小的关系,但是呢,接收方应用进程收到的字节流必须和发送方应用进程发出的字节流完全一样,与此同时,接收方应用进程必须有能力识别收到的字节流,把它还原成有意义的应用层数据。也就是说,TCP是面向字节流的,这也正是TCP实现可靠传输、流量控制以及拥塞控制的基础。
紧接着,再来看另外一个对比,其示意图如下所示:
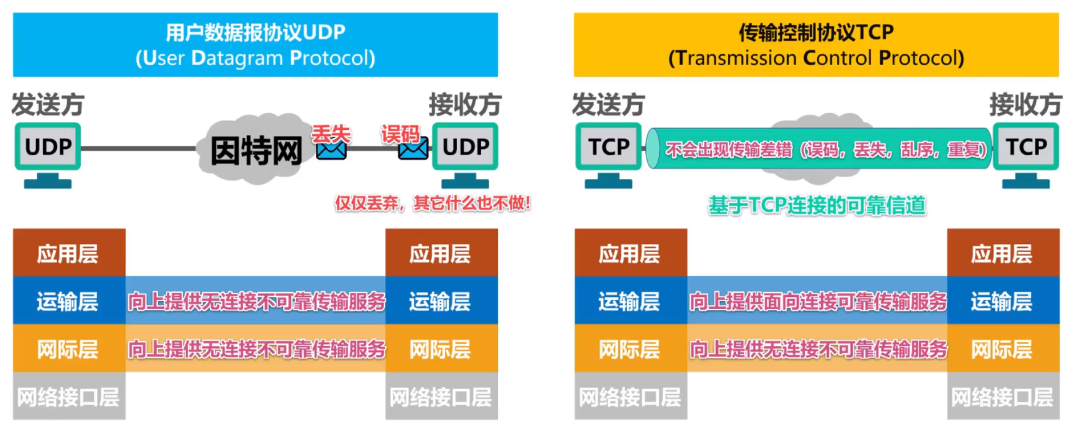
image-20210706215655559
就是说对于TCP/IP体系架构来说,网际层 向上提供无连接不可靠的传输服务 ,而对于 UDP来说,其所再运输层向上提供无连接不可靠的传输服务,这样一种机制也就造成了数据包的丢失以及误码现象,但是对于UDP传输来讲,它就仅仅是丢弃其他什么也不做;但是对于TCP传输协议来讲呢,网际层 向上提供无连接不可靠的传输服务 ,TCP所处的传输层向上提供面向连接的可靠传输服务,这也就实现了基于TCP连接的可靠信道,不会出现传输差错,误码,丢失,乱序以及重复的问题。
下面对比一下UDP和TCP报文的首部,一个UDP用户数据报由首部和数据载荷两部分组成,TCP报文段也是由首部和数据载荷部分组成,其中UDP用户数据报首部仅仅8个字节,仅仅包含源端口,目的端口,长度以及校验和。而对于TCP来讲,其首部包含的信息较多,其首部大小最小为20字节,最大为60字节。
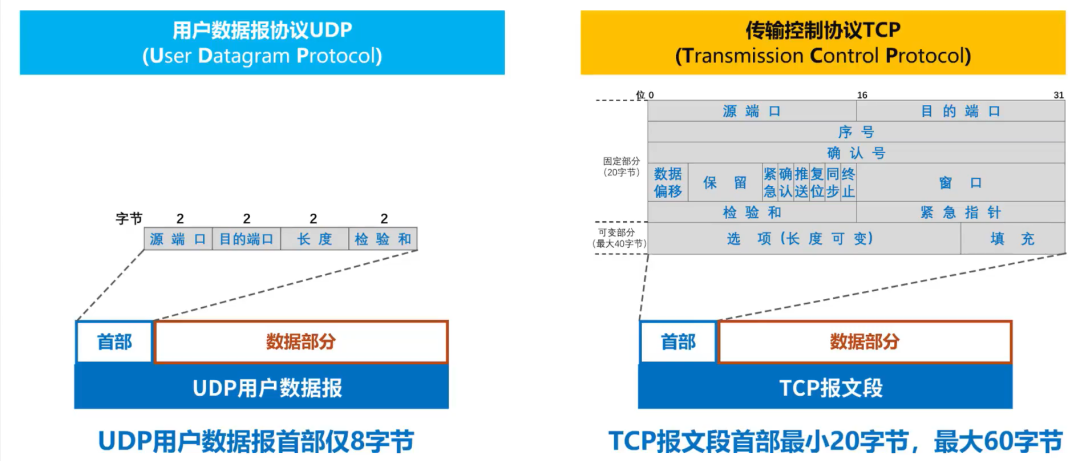
image-20210707133649551
小结
综上所述,针对于TCP和UDP来说两者的特点与区别汇总如下:
用户数据报协议UDP
- 无连接
- 支持一对一,一对多,多对一和多对多交互通信
- 对应用层交付的报文直接打包
- 尽最大努力交付,也就是不可靠;不使用流量控制和拥塞控制
- 首部开销小,仅 8 字节
传输控制层协议TCP
- 面向连接
- 每一条
TCP连接只能有两个端点,只能是一对一通信 - 面向字节流
- 可靠传输,使用流量控制和拥塞控制
- 首部最小20字节,最大60字节
TCP 的流量控制
滑动窗口的引出
在上一则文章叙述 TCP三次握手和四次挥手的那个过程中,我们知道对于TCP的通信来讲,是每发送一个数据,都要进行一次确认应答。当上一个数据包收到应答了,再发送下一个数据包,这样一个通信的流程是如下所示的:
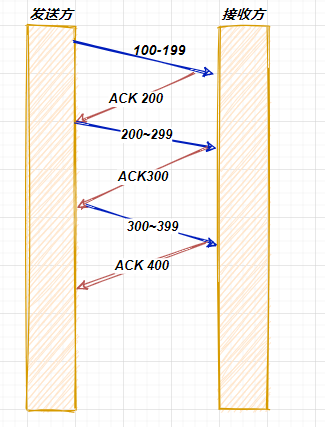
image-20210711105416703
通过上述这个示意图也可以看出,如果说每次发送一个数据包应答一次再发送下一个数据包,这样的效率也过于低下了,这时候也就引入了滑动窗口的概念。那有了窗口,就可以指定窗口的大小了,窗口大小也就是指无需要等待应答,而可以继续发送数据的最大值,比如说如果当前的窗口是 3 的话,那么发送方就可以连续发送三个TCP段,而且如上图所示如果其中的一个ACK丢失了,那么可以通过下一个确认应答进行确认,比方说,如果ACK 600丢失了,那么ACK 700的确认应答就可以替代ACK 600的确认应答。
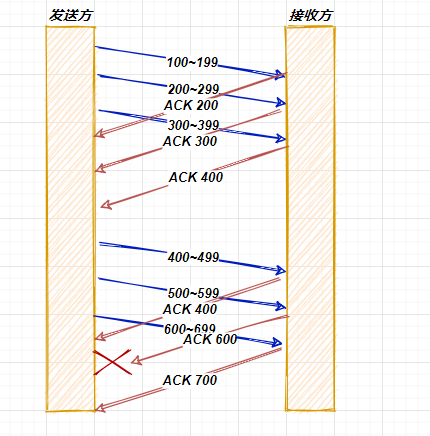
image-20210711233912755
流量控制
根据上述引出的滑动窗口机制,我们知道,因为此机制的原因,我们能够使得传输速率更快了,但是如果发送方的发送速率过快,那么接收方就可能来不及处理,这就会造成数据的丢失,而即将叙述的流量控制,就是让 发送方的发送速率不要太快,要让接收方能够来得及接收 ,而利用滑动窗口机制可以很方便地在 TCP 连接上实现对发送方的流量控制。
在介绍流量控制是如何实现的之前,先来分别看看发送方和接收方的滑动窗口,首先来介绍发送方的 窗口 ,那对于发送方来讲,这个窗口有多大呢?这是取决于接收方能够处理多大的数据,也就是说在发送数据之前,接受方会给发送方报一个 窗口大小 ,这个窗口大小也就是 Advertised window ,具体是什么意思呢?看如下示意图:
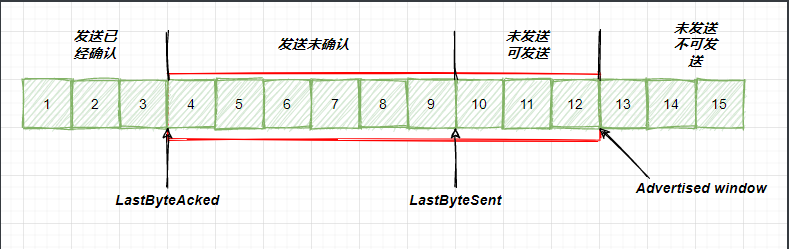
image-20210727010803750
- LastByteAcked: 第一部分和第二部分的分界线
- LastByteSent: 第二部分和第三部分的分界线
通过示意图也可以看出来,对于Advertised window来说,这个窗口的大小应该等于 第二部分+第三部分 。
对于接收端来讲,它的缓存里面记录的内容要简单一些,示意图如下所示:
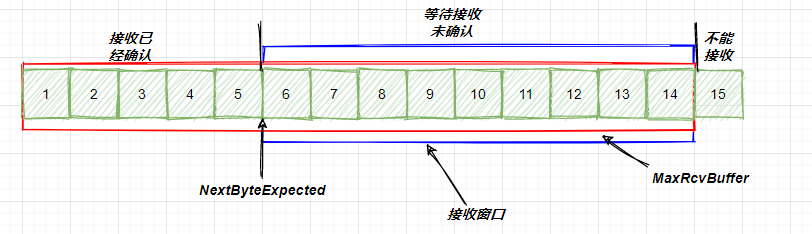
image-20210712002717332
其中,MaxRcvBuffer也正如其字面意思,就是最大缓存的量,对于接收方的窗口大小也就如蓝色方框所示,说到这里呢,也就引入了一个问题,就是说:接收窗口和发送窗口的大小是相等的么?
答案是 并不是完全相等,接收窗口的大小是约等于发送窗口的大小的 。
原因在于滑动窗口不是一成不变的,比如说,当接收方的应用进程读取数据比较快的时候,这样的话接收窗口就会很快空出来,但是要把这一消息告诉发送方,需要经过网络传输,那么这样依赖就会出现不一致的情况,所以说,是约等于的。
发送方和接收方的窗口就基本这些内容,接下来是关于流量控制的内容:
先假设窗口不变,也就是9,当 4 的确认来的时候,窗口会向右移动一个,整个时候,13这个序号的包也可以发送了。
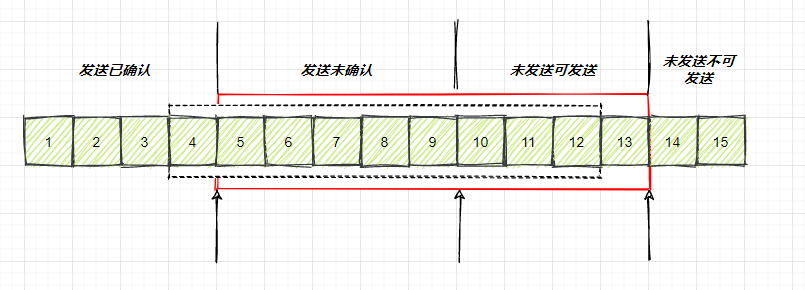
image-20210726001856097
如果说这个时候,发送方发送的过快,会将第三部分的10、11、12、13全部发送完毕,之后就停止发送了,未发送可发送部分为0
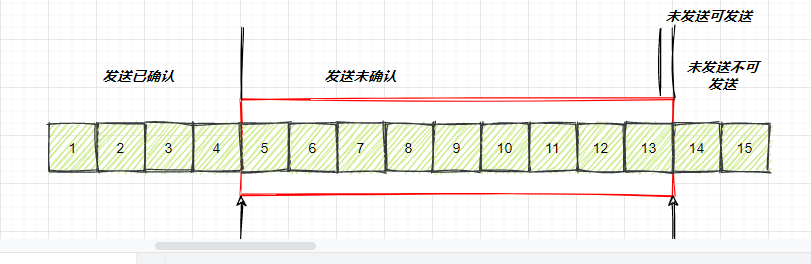
image-20210726002732414
这个时候,只有当包 5 的确认到达的时候,在客户端相当于窗口再滑动了一格,这个时候,第 14 个包才可以发送。
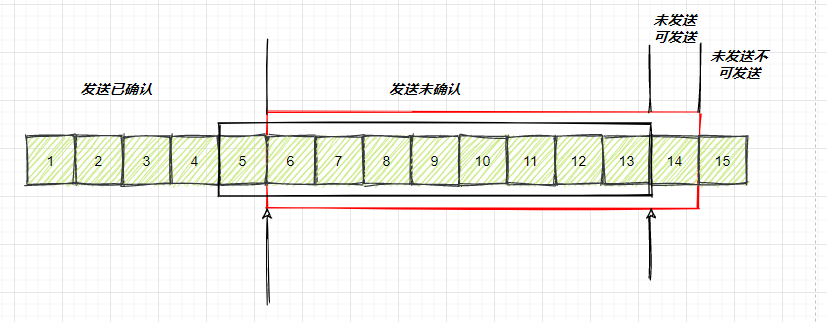
image-20210726003909427
如果接收方处理的太慢了,那么就可以通过确认信息来调整窗口的大小,现在假设一种比较极端的情况,就是说接收端一直不处理数据,那么当数据包6的确认到达之后,窗口大小就不能是 9了,就需要缩小一个变为8,下方是发送方在收到一个6的确认包之后,窗口的变化情况,可以看到此时窗口的变化方式并不是向右移动一格,而是窗口的左边向由缩进一格,窗口的整体大小并没有发生变化。
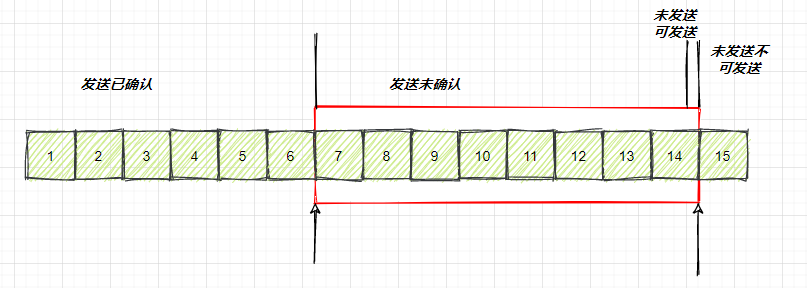
image-20210726004657587
如果说接收端一直不处理数据,那么随着确认的包越来越多,窗口也就越来越小,直到为0,下方是接收方窗口的变化情况:
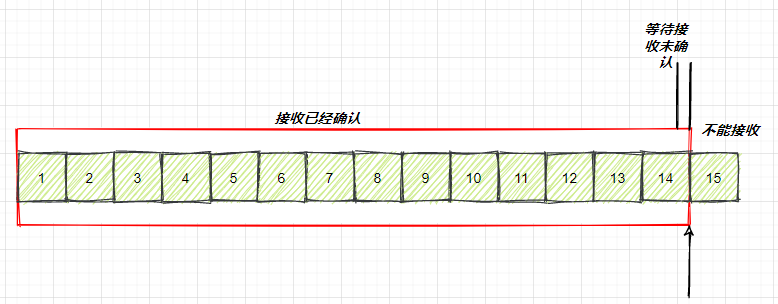
image-20210726004911416
与上图接收方对应的发送窗口的情况如下如所示,当 14 的确认到达发送端的时候,发送端的窗口也调整为0,停止发送。
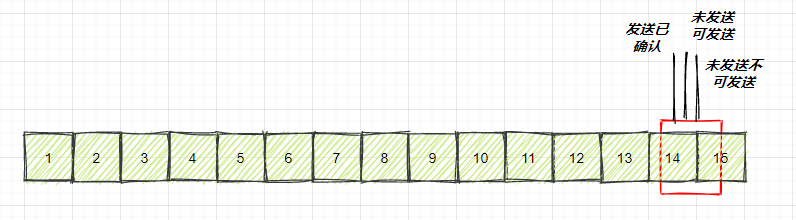
image-20210726005438132
如果到这种情况的话,发送方会定时发送窗口探测数据包,看是否有机会调整窗口的大小。当接收方比较慢的时候,,要防止低能窗口综合征,别空出一个字节来就赶快告诉发送方,然后马上又填满了,可以当窗口太小的时候,不更新窗口,直到达到一定大小,或者缓冲区一半为空,才更新窗口。
上述就是TCP中的流量控制。
TCP 拥塞控制
在某段时间,如果对网络中某一资源的需求超过了该资源所能够提供的可用部分,网络性能就要变坏,这种情况就叫做 拥塞 。
在计算机网络中的链路容量(即带宽)、交换结点中的缓存和处理机等,都是网络的资源
如果出现拥塞而不进行控制,整个网络的吞吐量将随着输入负荷的增大而下降。
下图是理想拥塞控制,实际的拥塞控制,和无拥塞控制的一个曲线图,曲线如下所示:
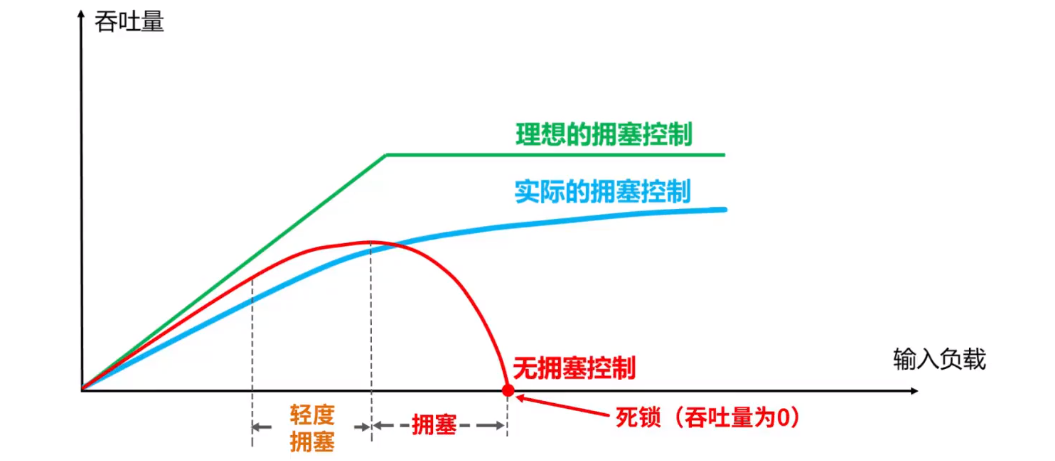
image-20210726233128809
TCP 的拥塞控制算法主要涉及到四个,分别是:
- 慢开始算法
- 拥塞避免算法
- 快重传算法
- 快恢复算法
在讲解这四种拥塞控制算法之前,先假定如下条件:
- 数据是单方向传送的,而另一个方向只传送确认
- 接收方总有足够大的缓存空间,因而发送方发送的窗口的大小由网络的拥塞程度来决定
- 以最大报文段 MSS 的个数作为讨论问题的单位,而不是以字节为单位
也就是说现在发送方和接收方两者之间的通信是这样子的,具体过程如下图所示:
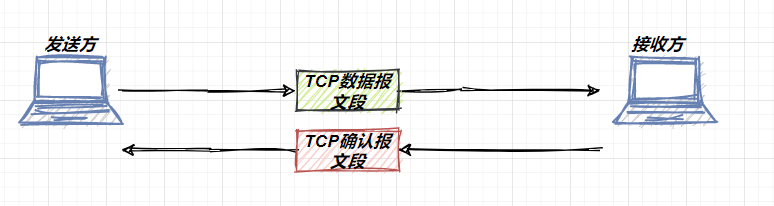
image-20210726235358470
发送方向接收方发送一个 TCP 数据报文段,而接收方收到整个报文段之后,就向发送方回一个TCP确认报文段
也就是说,发送方维护一个叫做拥塞窗口cwnd的状态变量,其值取决于网络的拥塞程度,并且动态变化。
- 拥塞窗口cwnd的维护原则:只要网络没有出现拥塞,拥塞窗口的值就增大一些;但是只要网络中出现拥塞,拥塞窗口就减小一些。
- 判断出现网络拥塞的依据:没有按时收到应当达到的确认报文(也就是发生了超时重传)。
发送方将拥塞窗口作为发送窗口,也就是 swnd = cwdn
维护一个慢开始门限ssthresh状态变量:
- 当 cwnd < ssthresh 时,开始使用慢开始算法
- 当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法
- 当 cwnd = ssthresh 时,既可以使用慢开始算法,也可以使用拥塞避免算法
慢开始和拥塞避免算法
为了更改的阐述慢开始算法,我们给出下面这样一个折线图,其中折线图的横坐标表示的是传输轮次,而一个传输轮次指的是发送方给接收方发送数据报文段之后,接收方给发送方回相应的确认报文段,一个传输轮次所经历的时间,其实就是往返时间,纵坐标是拥塞窗口,这是一个动态变化的值。
在 TCP 双方建立逻辑连接关系时,拥塞窗口的值被设置为1 ,另外还需要设置慢开始门限的初始值为16,在执行慢开始算法时,发送方每收到一个接收方发来的确认报文段时,就将拥塞窗口值+1,然后再开始下一轮次的传输,当拥塞窗口值增加到慢开始门限值时,就改为执行拥塞避免算法。

image-20210727001131965
上述的折线图该如何解释呢?就是说,如果最开始,发送方的拥塞窗口值为1,发送方发送一个TCP 报文段至接收方,接收方收到之后,发送TCP确认报文段至发送方,当发送方收到这个确认报文段之后,就将拥塞窗口的值加1,因为在这里,拥塞窗口的值就等于发送窗口的值,所以,此时发送窗口的值为 2,那么发送方就能够发送两个报文段到接收方,当发送方收到这两个报文段的确认报文段后,就将拥塞窗口设置为 4,此时发送方就能发送4个TCP报文段至接收方,按照这样一种原理,图中数据包每增加一个轮次,拥塞窗口的值就呈现指数增长,直至增加到慢开始门限值,也就是 16,此时改为拥塞避免算法。
何为拥塞避免算法呢,也就是说当前来讲,每个传输轮次结束之后,拥塞窗口的值改为线性加1,而不是像慢开始算法那样拥塞窗口的值呈现指数增长,比如说此时发送方能够发送15~30号的数据报文段,当发送方收到 15 ~30 号的数据确认报文段,将拥塞窗口值加1增大到17,依据此原理,发送方和接收方又进行了几个轮次的数据传输,达到如下所示的一个折线图:
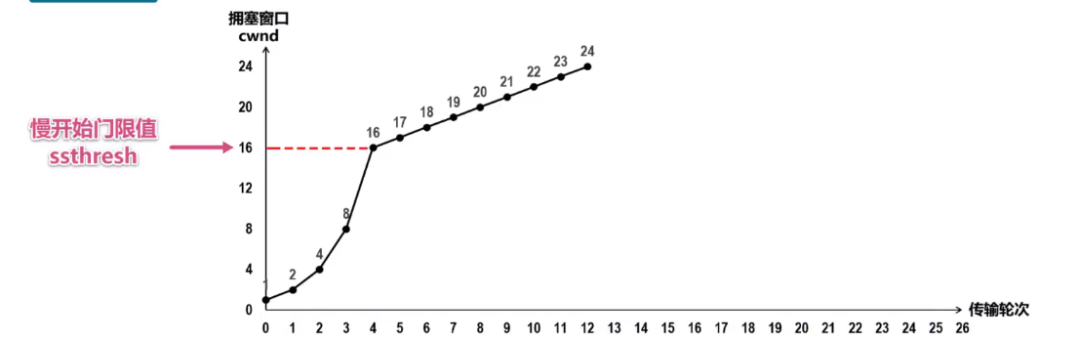
image-20210727002623522
如果说此时,在拥塞窗口值达到 24 的时候,发送方又向接收方发送了一串数据包,假设这串报文段在传输过程中,丢失了几个,这必然会造成发送方对这些丢失报文段的超时重传,发送方依据此判断网络很可能出现了拥塞,那么这个时候就需要做如下的工作:将慢开始门限值更新为发生拥塞时拥塞窗口值的一半,然后将拥塞窗口值调整为1 ,重新执行慢开始算法,当拥塞窗口达到慢开始门限值的时候,就执行拥塞避免算法,具体过程如图所示:
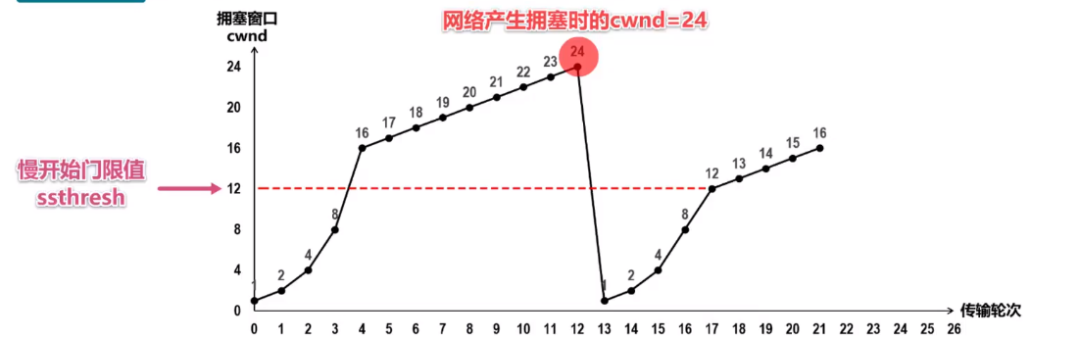
image-20210727003147211
最后,对这一整个过程进行标注,标注之后的折线图如图所示:
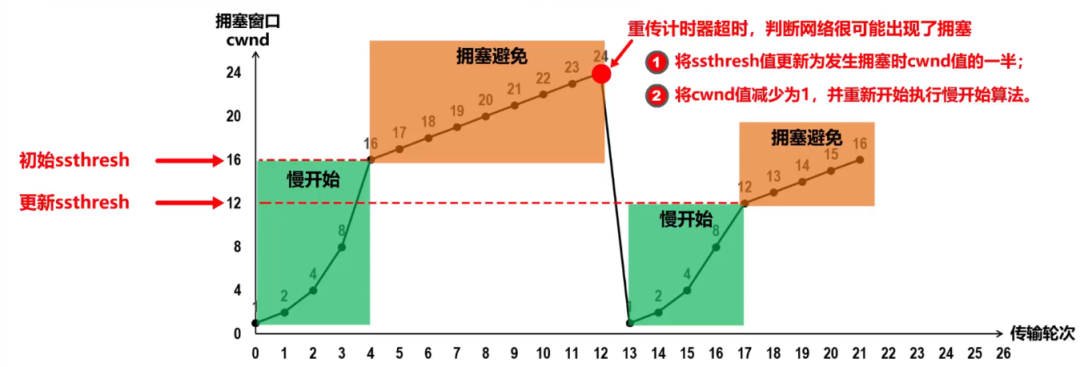
image-20210727003439349
快重传算法
有些时候,个别报文段会在网络中丢失,但是实际网络中并没有发生拥塞,这也将导致发送方超时重传,并且误认为是发生了拥塞,这个时候,发送方将拥塞窗口设置为最小值1,并且错误地启动了慢开始算法,因而降低了传输效率。
而采用快重传算法可以让发送方尽可能早地知道发生了个别报文段的丢失,也就是说快重传也就是让发送方尽快进行重传,而不是等待超时重传计时器超时再重传。
具体是怎么样呢?就是说接收方不要等待自己发送数据时才进行捎带确认,而是要立即发送确认;即使是收到了失序的报文段也要立即发出对已经收到报文段的重复确认,发送方一旦收到 3 个连续的重复确认,就将相应的报文段立即重传,而不是等待该报文段超时重传计时器超时再重传。
具体的过程是怎么样的呢,看如下所示的示意图:
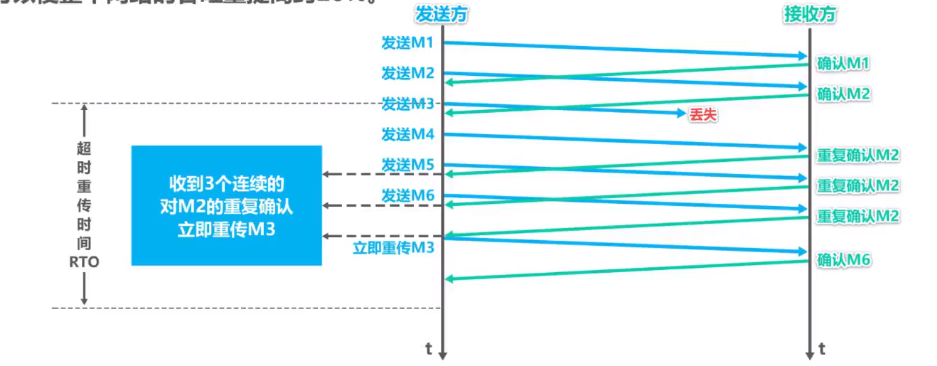
image-20210727004738434
通过上图可以看到,在发送M2时,并没有等待M1的确认报文段到达之后再发送,而是在确认报文段到达之前就将 M2 的报文段发送出去了,发送 M3 的时候,数据报发生了丢失,在发送 M4 的时候,接收方收到之后,会继续回传报文段 M2 的确认,一直到发送 M6 的时候,都是回传的M2的确认包,而此时对于M2的确认包的接收已经累计3个了,就立即重传M3报文段,这样也就不会造成对 M3 报文段的超时重传,也就不会将拥塞窗口调整为 1 ,也就能够大大提升网络的传输效率。
快恢复算法
发送方一旦收到3个重复确认,就知道现在只是丢失了个别的报文段。于是不启动慢开始算法,而执行快恢复算法;发送方将慢开始门限值和拥塞窗口值调整为当前窗口的一半;开始执行拥塞避免算法。
小结
综上所述,我们综合前面所叙述的慢开始和拥塞避免算法,以及快重传和快恢复算法举一个例子,例子如下所示:
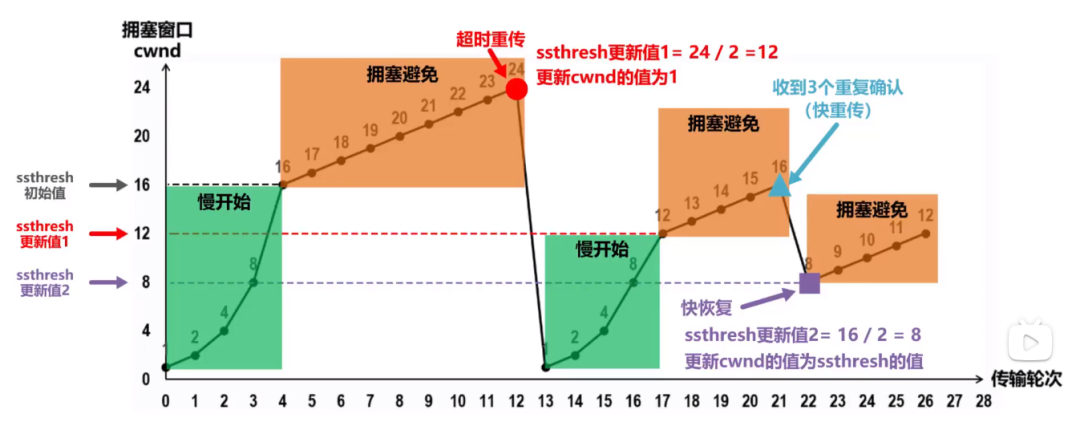
image-20210727010118107
这个图结合上述的理论能很好的进行解释,这里就不在进行阐述了。
总结
至此,关于计算机网络中 TCP 部分的阐述到此也就结束了,结合前面一则的 TCP 教程阅读更佳哦~
-
udp是什么意思 简述TCP与UDP的区别和联系2024-02-02 3090
-
UDP与TCP的主要区别 UDP能否像TCP一样实现可靠传输?2024-01-22 1869
-
TCP与UDP的基本区别2023-11-13 6323
-
TCP和UDP的区别2023-11-09 8460
-
udp是什么协议 TCP与UDP的区别2023-06-26 12840
-
UDP和TCP的区别2023-05-29 2335
-
UDP一定比TCP更快吗?什么情况下用UDP会更慢?2023-04-03 2785
-
TCP和UDP协议的区别2022-11-03 1394
-
一文详解udp与tcp的区别(UDT原理分析)2022-09-22 3985
-
TCP和UDP的原理以及区别2022-08-08 2071
-
TCP协议和UDP协议的区别有哪些2021-08-06 3024
-
多线程和多进程的区别2021-07-19 1482
-
udp和tcp的区别在哪里2017-12-08 9261
-
TCP和UDP的区别分析2017-09-18 801
全部0条评论

快来发表一下你的评论吧 !
