

STL的概述
描述
STL 概述
C++ STL 是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现多种流行和常用的算法,关于 STL 呢,下面通过一个系统框图来对其进行一个总结:
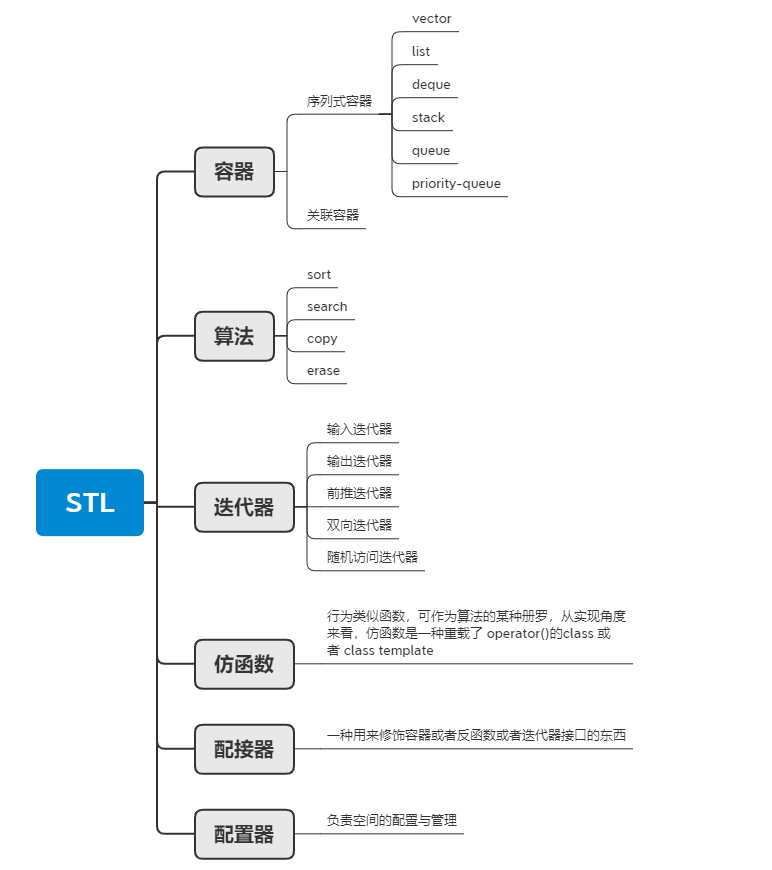
image-20210812170610134
可以看到,其主要包含 6 大方面,分别是:
- 容器:一个容器就是一些特定类型对象的集合。STL容器分为两大类:序列式容器和关联式容器
- 序列式容器:为程序员提供了控制元素存储和访问顺序的能力。这种顺序不依赖于元素的值,而是与元素加入容器时的位置相对应。
- 关联式容器:关联容器中的元素是按照关键字来保存和访问的。关联式容器支持高效的关键字查找和访问,STL有两个主要的关联式容器:map 和 set。
- 算法:STL 通过函数模板提供了很多作用于容器的通用算法,例如查找、插入、删除、排序等,这些算法均需要引入头文件,所有的
STL算法都作用在由迭代器所标识出来的区间上,可以分为两类: - 质变算法:运算过程中会更改区间内 迭代器所指向的内容,如分割,删除
- 非质变算法:运算过程中不会改变区间内迭代器所指向的内容,如匹配,计数等算法
- 迭代器:迭代器提供对一个容器中的对象的访问方法,并且定义了容器中的对象的范围。迭代器就如同一个指针。事实上,C++的指针也是一种迭代器。
- 仿函数:仿函数在 C++ 标准中采用的名称是函数对象。仿函数主要用于 STL 中的算法中,虽然函数指针也可以做为算法的参数,但是函数指针不能满足 STL 对于抽象的要求
- 配接器:配接器又被称之为是适配器,通俗来讲,适配器就是以序列式容器为底层数据结构,进一步封装了的为适应场景应用的容器。STL中提供了三种适配器,分别为: stack , queue ,priority_queue
- 配置器:以 STL 运用的角度而言,空间配置器是最不需要介绍的,它总是藏在一切组件的背后,默默工作。整个 STL 的操作对象都存放在容器之中,而容器需要配置空间以放置资料,这就是空间配置器的作用。
在对 STL 标准库做了一个总体的概述之后,进一步详细地对每个部分进行叙述。
容器
在一份资料中看到,容器是这样被形容的:
容器,置物之所也
对于容器来说,又分为序列式容器和关联式容器,这里先从序列式容器开始说起
序列式容器
序列式容器:其中的元素都可序,但是未必有序。C++语言本身提供了一种序列式容器array,STL另外提供了 vector,list,deque,stack,queue,priority-queue等序列容器。其中stack、queue只是由deque改头换面而成,技术上称为一种配接器。
下面将对几种序列式容器进行阐述:
vector
vector 是一个拥有扩展功能的数组,我们可以创建任何类型的 vector
比如说,我们可以通过如下的方式创建一个二一维数组:
vector A1 {1,2,3,4,5};
对于一维数组的初始化,也可以采用如下的方式进行:
vector A1(10); /* 带参数构造,10个数据都是 0 */
vector A2(10,1); /* 带参数构造,10个数据全是 1 */
除了上述这种给出数据的初始化方式以外,也可以通过同类型来进行初始化,比如下面这样:
vector A3(12,1);
vector A4(A3); /* 通过 A3 来初始化 A4 */
也可以通过创建一个存储 vector元素的 vector的形式来创建一个二维数组:
vector> Matrix {{1,2,3},{4,5,6},{7,8,9}};
也可以通过如下的方式来初始化二维数组:
vectorint>> Matrix(N,vector<int>(M,-1));
上述代码的意思就是说,创建了一个 N*M 的矩阵,并且用 -1 填充所有位置上的值。
在创建了一个vector之后,又该如何访问内部的数据成员呢?有如下几种方式:
vector<int> A1 = {1,2,3,4,5};
vector<int>::iterator k1 = A1.begin();
cout << *k1 << endl;
cout << *(k1 + 1) << endl;
vector<int>::iterator k2 = A1.end(); /* 返回最后一个元素的下一个地址 */
cout << *(k2 - 1) << endl;
cout << A1.at(0) << endl;
上述代码经过运行之后,输出的结果如下所示:
1
2
5
1
紧接着,就是关于元素的插入,删除,插入删除可以使用下面方法:
A1.pop_back(); /* 删除最后一个元素 */
A1.push_back(); /* 在末尾添加一个元素 */
当然,也可以在特定位置插入元素,如下所示:
vector A1 = {1,2,3,4,5};
vector::iterator k = A1.begin();
A1.insert(k + 1, 9);
插入元素之后,A1里的元素变为:
1,9,2,3,4,5
在叙述 vector的开头,就说了vector是一个具有扩展功能的数组,也就是说 vector的容量是可以扩充的,如下就有一个例子:
最后,来叙述一些 vector的遍历方式:
for (int i = 0; i < A.size(); i++)
{
cout << A1[i] << endl
}
上述这种方式是和C语言中普通数组的遍历方式一样的,在C++ 中除了这种遍历方式,还有其余的方式,比如:
for (vector<int>::iterator k = A1.begin(); k != A1.end(); k++)
{
cout << *k << endl;
}
除此之外,还有一种稍微简便一点的方式,用 auto 来推导迭代:
for (auto iter = A1.begin(); iter != A1.end(); iter++)
{
cout << *iter << endl;
}
除此之外,还有更为简洁的,如下所示:
for (auto i : A1)
{
cout << i << endl;
}
list
对比于 vector的连续线性空间,list显得复杂许多,他的好处是每次插入或者删除一个元素,就配置或者释放一个元素空间。因此list对于空间的运用有着绝对的精准,一点也不浪费。而且对于任何位置的元素插入或者元素移除,list永远是常数时间。下图展示了 list双向链表容器是如何存储元素的:

image-20210815154103144
在使用 list 的时候,需要包含下面两行代码:
#include
using namespace std;
根据不同的使用场景,有如下几种方式创建 list 容器:
list<int> values; /* 空的 list 容器 */
list<int> values(10); /* 创建一个包含 n 个元素的 list 容器 */
list<int> values(10,5); /* 创建了一个包含 10 个元素且值都为 5 的容器 */
list<int> values2(values);
可以看到上述的初始化的方法和vector一样,都是有这么几种方式,同样的,和vector一样,list也提供了push_back,pop_back方法,而且由于是双链表的原因,也可以从头部插入或者删除数据:push_front,pop_front
#include
using namespace std;
int main(int argc, char **argv)
{
list<int> mylist;
mylist.push_back(33);
mylist.push_back(22);
mylist.push_front(11);
for (auto n: mylist)
{
cout << n << endl;
}
mylist.front() -= mylist.back();
mylist.insert(mylist.begin(),0);
cout << "^^^^^^^^^^^^^^^^^^^^^^^^^" << endl;
for (auto n : mylist)
{
cout << n << endl;
}
cout << "========================" << endl;
mylist.erase(--mylist.end());
for (auto n : mylist)
{
cout << n << endl;
}
}
上述代码最终的输出结果如下所示:
11
33
22
^^^^^^^^^^^^^^^^^^^^^^^^^
0
-11
33
22
========================
0
-11
33
对比结果,和代码就可以清除地知道具体地作用,在这里需要注意地就是:mylist.begin()和 mylist.end()返回的分别是:返回容器中第一个元素的双向迭代器,返回指向容器中最后一个元素所在位置的下一个位置的双向迭代器。
上述所叙述的基本是 list相对比与 vector相同的部分,那么两者不同的部分呢,由于 list 数据结构的特殊,也提供了一些 vector 没有的操作,比如说:
- splice: 将某个连续范围的元素从一个 list 迁移到另一个(或者同一个)list 的某个节点
- remove: 删除list中指定值的元素,和 erase 不同,这里是根据值而不是位置去删除。
- merge: 合并两个有序链表并使之有序。
- sort: 针对 list 的特定排序算法,默认的算法库中的sort需要随机访问迭代器,list并不能提供
先从 splice说起,对于splice来说,其主要有如下三种原型:
void splice(iterator position, list &x);
void splice(iterator position, list &x, iterator it);
void splice(iterator position, list &x, iterator first, iterator last);
下面分别就这三种原型进行叙述:
#include
using namespace std;
int main(int argc, char** argv)
{
list<int> mylist1, mylist2;
list<int>::iterator it;
for (int i = 0; i <= 4; i++)
mylist1.push_back(i);
for (int i = 0; i <= 3; i++)
mylist2.push_back(i*10);
it = mylist1.begin();
it++;
mylist1.splice(it,mylist2);
for (auto n : mylist1)
cout << n << endl;
}
代码输出结果为:
1
10
20
30
2
3
4
这里需要注意的是:此处的 it由于是指向的mylist1,经过splice后,此迭代器依然存在于 mylist1中,所以没有失效。
#include
using namespace std;
int main(int argc, char** argv)
{
list<int> mylist1, mylist2;
list<int>::iterator it;
for (int i = 0; i <= 4; i++)
mylist1.push_back(i);
for (int i = 0; i <= 3; i++)
mylist2.push_back(i*10);
it = mylist1.begin();
it++;
mylist1.splice(it,mylist2);
for (auto n : mylist1)
cout << n << endl;
cout << "^^^^^^^^^^^^^^^^^^^^^" << endl;
mylist2.splice(mylist2.begin(), mylist1, it);
/* mylist1: 1, 10, 20, 30, 3, 4
* mylist2: 2
* it 现在就无效了
*/
cout << "====================" << endl;
it = mylist1.begin(); /* 现在 it 指向的是 1 */
advance(it, 3); /* 现在 it 就指向的是 30 */
mylist1.splice(mylist.begin(), mylist1, it, mylist.end());
/* 经过上述这么操作之后 */
/* mylist1 就变成了:30 3 4 1 10 20 */
}
上述注释对 splice三种原型进行了常数,结合注释也能够清楚地知道具体地功能。
除了splice以外,还有remove函数以及 merge 和sort也是区别于vector的,所涉及的代码如下所示:
#include
using namespace std;
int main(int argc, char** argv)
{
list mylist;
mylist.push_back('A');
mylist.push_back('B');
mylist.push_back('C');
mylist.remove("B");
mylist.sort();
for (auto n : mylist)
cout << n << endl;
return 0;
}
最终输出的结果为:
int main(int argc, char** argv)
{
list mylist;
mylist.push_back("one");
mylist.push_back("two");
mylist.push_back("three");
mylist.remove("two");
mylist.sort();
for (auto n : mylist)
cout << n << endl;
return 0;
}
关于 merge,使用起来也很简单,它的作用是将两个有序序列进行合并,注意,必须是有序序列,并且,两种序列的排序方式是一致的,也就是说,要么都是升序,要么都是降序。下面是关于 merge的使用例子:
#include
int main(){
// declaring the lists
// initially sorted, use sort() if unsorted
std::list<int> list1 = { 10, 20, 30 };
std::list<int> list2 = { 40, 50, 60 };
// merge operation
list2.merge(list1);
std::cout << "List: ";
for (auto it = list2.begin(); it != list2.end(); ++it)
std::cout << *it << " ";
return 0;
}
代码输出的结果是:10,20,30,40,50,60
deque
vector 是单向开口的连续线性空间,deque 则是一种双向开口的连续线性空间。所谓双向开口,意思是可以在头尾两端分别做元素的插入和删除工作,deque 和 vector 的差异在于:
- deque 允许常数时间内对起头端进行元素的插入或移除操作
- deque 没有所谓的容量(capacity)概念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。
关于deque要指出的一点是,它的迭代并不是普通的指针,其复杂度要大的多,因此除非必要,应该尽可能使用 vector 而非 deque。对 deque 进行排序操作,为了提高效率,可以先将 deque 完整复制到一个 vector 中,将 vector 排序后(利用 STL sort),再复制回 deque。
下面是关于 deque的一个例子:
std::deque<int> mydeque;
// set some initial values:
for (int i=1; i<6; i++) mydeque.push_back(i); // 1 2 3 4 5
std::deque<int>::iterator it = mydeque.begin();
++it;
it = mydeque.insert (it,10);
mydeque.erase(--mydeque.end());
for(auto n: mydeque) std::cout << n << " "; // 1 10 2 3 4
适配器
在本文的最开头给出了适配器的概念,再来回顾一下,就是:适配器就是以序列式容器为底层数据结构,进一步封装了的为适应场景应用的容器。STL中提供了三种适配器,分别为: stack , queue ,priority_queue
stack
Stack (堆栈) 是一个容器类的改编,为程序员提供了堆栈的全部功能,也就是说实现了一个先进后出 (FILO)的数据结构,其示意图如下所示:

image-20210815225740108
它主要支持如下操作:
- empty: 判断 栈是否为空
- size: 取得栈的大小
- top: 取得栈顶的元素
- push:入栈操作
- pop: 出栈操作
stack 的所有元素都必须满足先进后出的机制,只有stack顶的元素,才有机会被外界取用,以此stack不提供迭代器,关于它的简单的使用例子如下所示:
#includequeue
queue 是一种先进先出(FIFO)的数据结构,允许从最底部加入元素,同时取得最顶部元素。STL以 deque 作为缺省情况下的 queue 底部结构,下面queue的示意图:
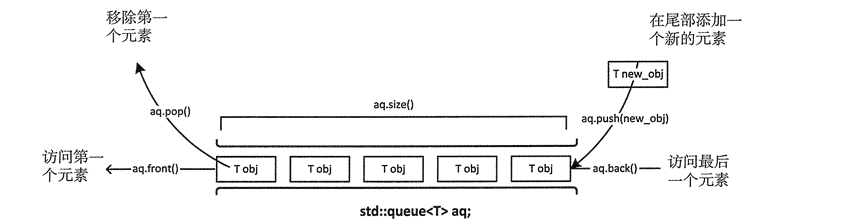
image-20210815230959996
代码如下所示:
std::queue<int> myqueue;
for (int i=0; i<5; ++i) myqueue.push(i);
std::cout << "Popping out elements...";
while (!myqueue.empty())
{
std::cout << ' ' << myqueue.front();
myqueue.pop();
}
std::cout << '\\n';
// Popping out elements... 0 1 2 3 4
return 0;
priority queue
优先队列(priority queue)允许用户以任何次序将任何元素推入容器内,但取出时一定是从优先权最高的元素开始取。优先队列具有权值观念,其内的元素并非依照被推入的次序排列,而是自动依照元素的权值排列,权值最高者排在最前面。
优先队列完全以底部容器为根据,加上 heap 处理规则,具有修改某物接口,形成另一种风貌的性质,因此是配接器。优先队列中的所有元素,进出都有一定的规则,只有queue顶部的元素(权值最高者),才有机会被外界取用。因此并不提供遍历功能,也不提供迭代器。
优先队列的构造函数和其他序列式容器的略有不同,因为需要指定底层容器的类型和优先级比较的仿函数。C++11 中一共有5大种构造函数,下面列出其中一种:
template <class InputIterator>
priority_queue (InputIterator first, InputIterator last,
const Compare& comp, const Container& ctnr);
下面是具体的构造示例:
int myints[]= {10,60,50,20};
std::priority_queue<int> first;
std::priority_queue<int> second (myints,myints+4);
std::priority_queue<int, std::vector<int>, std::greater<int>> third (myints,myints+4);
小结
本次就是关于C++中的序列式容器做了一个总结,当然 C++ 中的容器不止这些,还有其余内容,这次就写到这里啦,下次继续。
-
STL内容介绍2023-11-13 2499
-
使用STL函数控制传送带2023-10-12 1445
-
C++之STL算法(二)2023-07-18 3469
-
C++之STL库中的容器2023-02-21 2619
-
X-CUBE-STL与ARM的STL的区别是什么?2022-12-02 628
-
stl-thumb STL缩略图生成器2022-05-30 5559
-
S7-STL中文编程手册2021-04-23 1446
-
STL130N6F7 MOS管现货2018-11-12 984
-
基于STL曲面网格重建算法2017-12-25 1411
-
数据结构与STL2015-12-22 998
-
STL算法在GIS中的应用2011-06-28 853
-
STEP7 STL语句表编程使用手册2011-03-10 4174
-
C++ STL的概念及举例2010-08-30 1739
-
effective stl中文版下载pdf2008-08-25 3230
全部0条评论

快来发表一下你的评论吧 !
