

Distributed Data Parallel中的分布式训练
描述
实现原理
与DataParallel不同的是,Distributed Data Parallel会开设多个进程而非线程,进程数 = GPU数,每个进程都可以独立进行训练,也就是说代码的所有部分都会被每个进程同步调用,如果你某个地方print张量,你会发现device的差异
sampler会将数据按照进程数切分,
「确保不同进程的数据不同」
每个进程独立进行前向训练
每个进程利用Ring All-Reduce进行通信,将梯度信息进行聚合
每个进程同步更新模型参数,进行新一轮训练
按进程切分
如何确保数据不同呢?不妨看看DistributedSampler的源码
# 判断数据集长度是否可以整除GPU数 # 如果不能,选择舍弃还是补全,进而决定总数 # If the dataset length is evenly divisible by # of replicas # then there is no need to drop any data, since the dataset # will be split equally. if (self.drop_last and len(self.dataset) % self.num_replicas != 0): # num_replicas = num_gpus self.num_samples = math.ceil((len(self.dataset) - self.num_replicas) /self.num_replicas) else: self.num_samples = math.ceil(len(self.dataset) / self.num_replicas) self.total_size = self.num_samples * self.num_replicas # 根据是否shuffle来创建indices if self.shuffle: # deterministically shuffle based on epoch and seed g = torch.Generator() g.manual_seed(self.seed + self.epoch) indices = torch.randperm(len(self.dataset), generator=g).tolist() else: indices = list(range(len(self.dataset))) if not self.drop_last: # add extra samples to make it evenly divisible padding_size = self.total_size - len(indices) if padding_size <= len(indices): # 不够就按indices顺序加 # e.g., indices为[0, 1, 2, 3 ...],而padding_size为4 # 加好之后的indices[..., 0, 1, 2, 3] indices += indices[:padding_size] else: indices += (indices * math.ceil(padding_size / len(indices)))[:padding_size] else: # remove tail of data to make it evenly divisible. indices = indices[:self.total_size] assert len(indices) == self.total_size # subsample # rank代表进程id indices = indices[self.rankself.num_replicas] return iter(indices)
Ring All-Reduce
那么什么是「Ring All-Reduce」呢?又为啥可以降低通信成本呢?
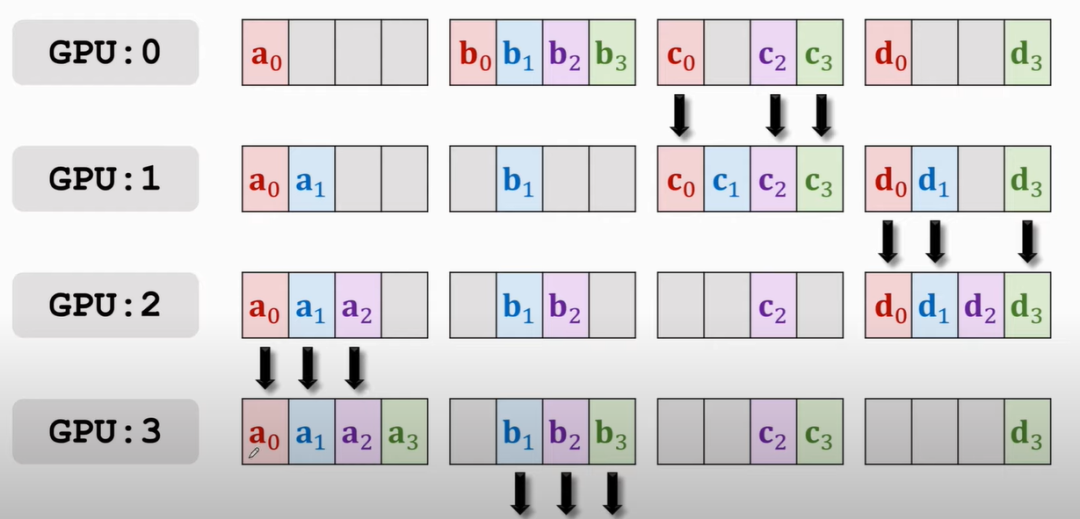
首先将每块GPU上的梯度拆分成四个部分,比如,如下图(此部分原理致谢下王老师,讲的很清晰[1]:
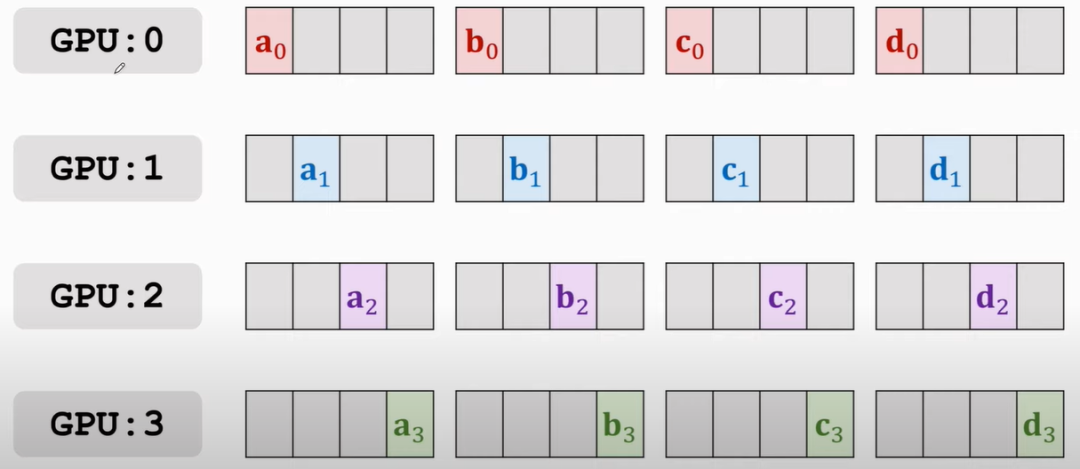
所有GPU的传播都是「同步」进行的,传播的规律有两条:
只与自己下一个位置的GPU进行通信,比如0 > 1,3 > 0
四个部分,哪块GPU上占的多,就由该块GPU往它下一个传,初始从主节点传播,即GPU0,你可以想象跟接力一样,a传b,b负责传给c
第一次传播如下:
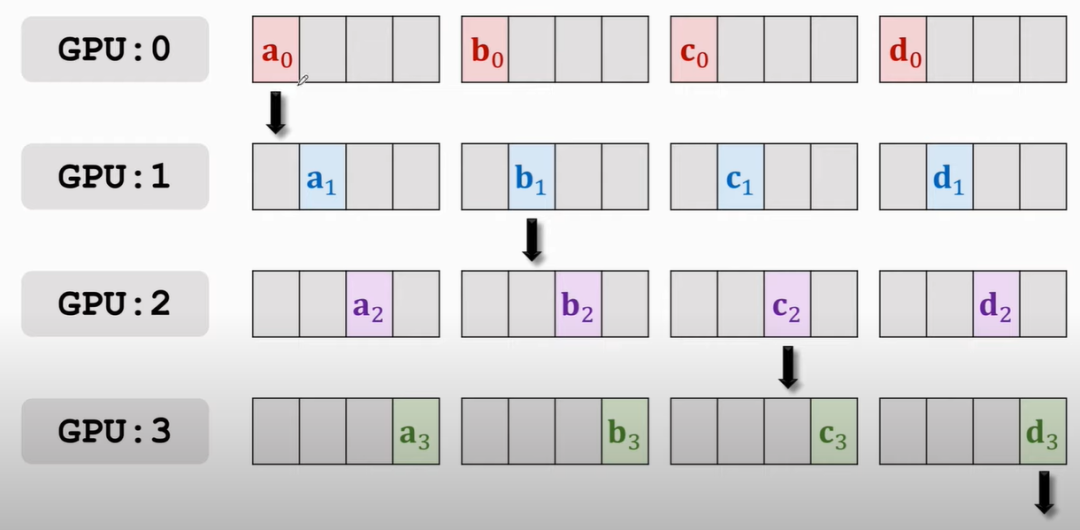
那么结果就是:
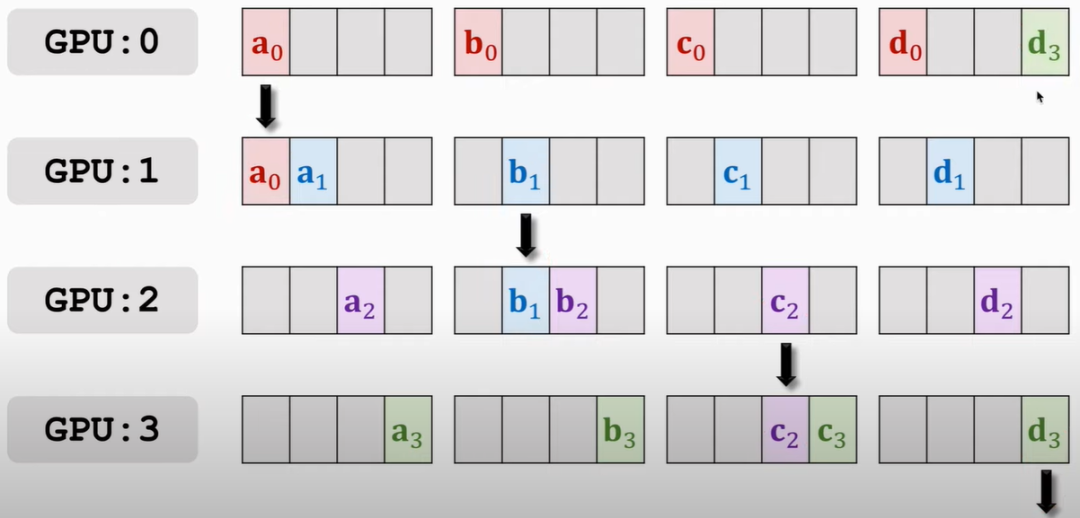
那么,按照谁多谁往下传的原则,此时应该是GPU1往GPU2传a0和a1,GPU2往GPU3传b1和b2,以此类推
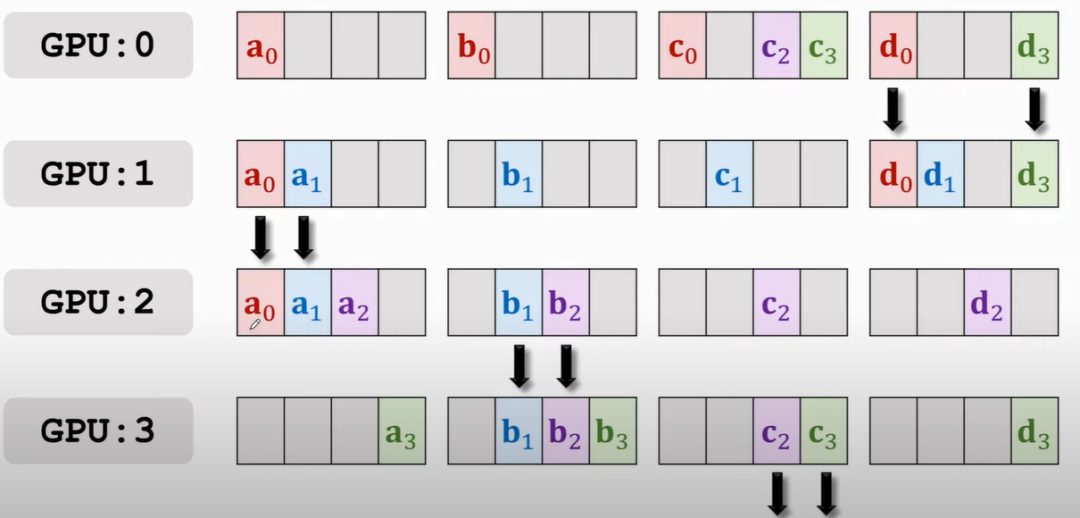
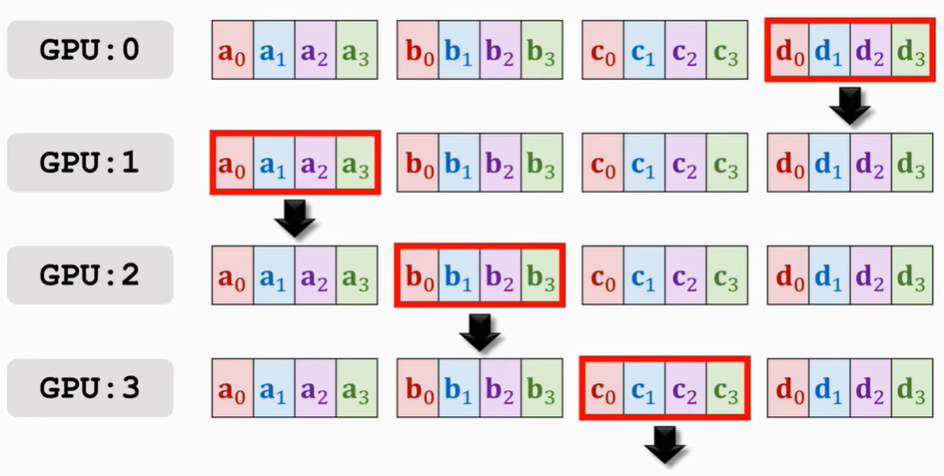
接下来再传播就会有GPU3 a的部分全有,GPU0上b的部分全有等,就再往下传
再来几遍便可以使得每块GPU上都获得了来自其他GPU的梯度啦
代码使用
基础概念
第一个是后端的选择,即数据传输协议,从下表可以看出[2],当使用CPU时可以选择gloo而GPU则可以是nccl
| 「Backend」 | 「gloo」 | 「mpi」 | 「nccl」 | |||
|---|---|---|---|---|---|---|
| Device | CPU | GPU | CPU | GPU | CPU | GPU |
| send | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| recv | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| broadcast | ✓ | ✓ | ✓ | ? | ✘ | ✓ |
| all_reduce | ✓ | ✓ | ✓ | ? | ✘ | ✓ |
| reduce | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| all_gather | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| gather | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| scatter | ✓ | ✘ | ✓ | ? | ✘ | ✘ |
| reduce_scatter | ✘ | ✘ | ✘ | ✘ | ✘ | ✓ |
| all_to_all | ✘ | ✘ | ✓ | ? | ✘ | ✓ |
| barrier | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
接下来是一些参数的解释[3]:
| Arg | Meaning |
|---|---|
| group | 一次发起的所有进程构成一个group,除非想更精细通信,创建new_group |
| world_size | 一个group中进程数目,即为GPU的数量 |
| rank | 进程id,主节点rank=0,其他的在0和world_size-1之间 |
| local_rank | 进程在本地节点/机器的id |
举个例子,假如你有两台服务器(又被称为node),每台服务器有4张GPU,那么,world_size即为8,rank=[0, 1, 2, 3, 4, 5, 6, 7], 每个服务器上的进程的local_rank为[0, 1, 2, 3]
然后是「初始化方法」的选择,有TCP和共享文件两种,一般指定rank=0为master节点
TCP显而易见是通过网络进行传输,需要指定主节点的ip(可以为主节点实际IP,或者是localhost)和空闲的端口
import torch.distributed as dist dist.init_process_group(backend, init_method='tcp://ip:port', rank=rank, world_size=world_size)
共享文件的话需要手动删除上次启动时残留的文件,加上官方有一堆警告,还是建议使用TCP
dist.init_process_group(backend, init_method='file://Path', rank=rank, world_size=world_size)
launch方法
「初始化」
这里先讲用launch的方法,关于torch.multiprocessing留到后面讲
在启动后,rank和world_size都会自动被DDP写入环境中,可以提前准备好参数类,如argparse这种
args.rank = int(os.environ['RANK']) args.world_size = int(os.environ['WORLD_SIZE']) args.local_rank = int(os.environ['LOCAL_RANK'])
首先,在使用distributed包的任何其他函数之前,按照tcp方法进行初始化,需要注意的是需要手动指定一共可用的设备CUDA_VISIBLE_DEVICES
def dist_setup_launch(args):
# tell DDP available devices [NECESSARY]
os.environ['CUDA_VISIBLE_DEVICES'] = args.devices
args.rank = int(os.environ['RANK'])
args.world_size = int(os.environ['WORLD_SIZE'])
args.local_rank = int(os.environ['LOCAL_RANK'])
dist.init_process_group(args.backend,
args.init_method,
rank=args.rank,
world_size=args.world_size)
# this is optional, otherwise you may need to specify the
# device when you move something e.g., model.cuda(1)
# or model.to(args.rank)
# Setting device makes things easy: model.cuda()
torch.cuda.set_device(args.rank)
print('The Current Rank is %d | The Total Ranks are %d'
%(args.rank, args.world_size))
「DistributedSampler」
接下来创建DistributedSampler,是否pin_memory,根据你本机的内存决定。pin_memory的意思是提前在内存中申请一部分专门存放Tensor。假如说你内存比较小,就会跟虚拟内存,即硬盘进行交换,这样转义到GPU上会比内存直接到GPU耗时。
因而,如果你的内存比较大,可以设置为True;然而,如果开了导致卡顿的情况,建议关闭
from torch.utils.data import DataLoader, DistributedSampler train_sampler = DistributedSampler(train_dataset, seed=args.seed) train_dataloader = DataLoader(train_dataset, pin_memory=True, shuffle=(train_sampler is None), batch_size=args.per_gpu_train_bs, num_workers=args.num_workers, sampler=train_sampler) eval_sampler = DistributedSampler(eval_dataset, seed=args.seed) eval_dataloader = DataLoader(eval_dataset, pin_memory=True, batch_size=args.per_gpu_eval_bs, num_workers=args.num_workers, sampler=eval_sampler)
「加载模型」
然后加载模型,跟DataParallel不同的是需要提前放置到cuda上,还记得上面关于设置cuda_device的语句嘛,因为设置好之后每个进程只能看见一个GPU,所以直接model.cuda(),不需要指定device
同时,我们必须给DDP提示目前是哪个rank
from torch.nn.parallel import DistributedDataParallel as DDP model = model.cuda() # tell DDP which rank model = DDP(model, find_unused_parameters=True, device_ids=[rank])
注意,当模型带有Batch Norm时:
if args.syncBN: nn.SyncBatchNorm.convert_sync_batchnorm(model).cuda()
「训练相关」
每个epoch开始训练的时候,记得用sampler的set_epoch,这样使得每个epoch打乱顺序是不一致的
关于梯度回传和参数更新,跟正常情况无异
for epoch in range(epochs): # record epochs train_dataloader.sampler.set_epoch(epoch) outputs = model(inputs) loss = loss_fct(outputs, labels) loss.backward() optimizer.step() optimizer.zero_grad()
这里有一点需要小心,这个loss是各个进程的loss之和,如果想要存储每个step平均损失,可以进行all_reduce操作,进行平均,不妨看官方的小例子来理解下:
>>> # All tensors below are of torch.int64 type. >>> # We have 2 process groups, 2 ranks. >>> tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank >>> tensor tensor([1, 2]) # Rank 0 tensor([3, 4]) # Rank 1 >>> dist.all_reduce(tensor, op=ReduceOp.SUM) >>> tensor tensor([4, 6]) # Rank 0 tensor([4, 6]) # Rank 1
@torch.no_grad() def reduce_value(value, average=True): world_size = get_world_size() if world_size < 2: # 单GPU的情况 return value dist.all_reduce(value) if average: value /= world_size return value
看到这,肯定有小伙伴要问,那这样我们是不是得先求平均损失再回传梯度啊,不用,因为,当我们回传loss后,DDP会自动对所有梯度进行平均[4],也就是说回传后我们更新的梯度和DP或者单卡同样batch训练都是一致的
loss = loss_fct(...) loss.backward() # 注意在backward后面 loss = reduce_value(loss, world_size) mean_loss = (step * mean_loss + loss.item()) / (step + 1)
还有个注意点就是学习率的变化,这个是和batch size息息相关的,如果batch扩充了几倍,也就是说step比之前少了很多,还采用同一个学习率,肯定会出问题的,这里,我们进行线性增大[5]
N = world_size lr = args.lr * N
肯定有人说,诶,你线性增大肯定不能保证梯度的variance一致了,正确的应该是正比于,关于这个的讨论不妨参考[6]
「evaluate相关」
接下来,细心的同学肯定好奇了,如果验证集也切分了,metric怎么计算呢?此时就需要咱们把每个进程得到的预测情况集合起来,t就是一个我们需要gather的张量,最后将每个进程中的t按照第一维度拼接,先看官方小例子来理解all_gather
>>> # All tensors below are of torch.int64 dtype. >>> # We have 2 process groups, 2 ranks. >>> tensor_list = [torch.zeros(2, dtype=torch.int64) for _ in range(2)] >>> tensor_list [tensor([0, 0]), tensor([0, 0])] # Rank 0 and 1 >>> tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank >>> tensor tensor([1, 2]) # Rank 0 tensor([3, 4]) # Rank 1 >>> dist.all_gather(tensor_list, tensor) >>> tensor_list [tensor([1, 2]), tensor([3, 4])] # Rank 0 [tensor([1, 2]), tensor([3, 4])] # Rank 1
def sync_across_gpus(t, world_size): gather_t_tensor = [torch.zeros_like(t) for _ in range(world_size)] dist.all_gather(gather_t_tensor, t) return torch.cat(gather_t_tensor, dim=0)
可以简单参考我前面提供的源码的evaluate部分,我们首先将预测和标签比对,把结果为bool的张量存储下来,最终gather求和取平均。
这里还有个有趣的地方,tensor默认的类型可能是int,bool型的res拼接后自动转为0和1了,另外bool型的张量是不支持gather的
def eval(...) results = torch.tensor([]).cuda() for step, (inputs, labels) in enumerate(dataloader): outputs = model(inputs) res = (outputs.argmax(-1) == labels) results = torch.cat([results, res], dim=0) results = sync_across_gpus(results, world_size) mean_acc = (results.sum() / len(results)).item() return mean_acc
「模型保存与加载」
模型保存,参考部分官方教程[7],我们只需要在主进程保存模型即可,注意,这里是被DDP包裹后的,DDP并没有state_dict,这里barrier的目的是为了让其他进程等待主进程保存模型,以防不同步
def save_checkpoint(rank, model, path): if is_main_process(rank): # All processes should see same parameters as they all # start from same random parameters and gradients are # synchronized in backward passes. # Therefore, saving it in one process is sufficient. torch.save(model.module.state_dict(), path) # Use a barrier() to keep process 1 waiting for process 0 dist.barrier()
加载的时候别忘了map_location,我们一开始会保存模型至主进程,这样就会导致cuda:0显存被占据,我们需要将模型remap到其他设备
def load_checkpoint(rank, model, path):
# remap the model from cuda:0 to other devices
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
model.module.load_state_dict(
torch.load(path, map_location=map_location)
)
进程销毁
运行结束后记得销毁进程:
def cleanup(): dist.destroy_process_group() cleanup()
如何启动
在终端输入下列命令【单机多卡】
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS main.py (--arg1 --arg2 --arg3 and all other arguments of your training script)
目前torch 1.10以后更推荐用run
torch.distributed.launch -> torch.distributed.run / torchrun
多机多卡是这样的:
# 第一个节点启动 python -m torch.distributed.launch --nproc_per_node=NUM_GPUS --nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234 main.py # 第二个节点启动 python -m torch.distributed.launch --nproc_per_node=NUM_GPUS --nnodes=2 --node_rank=1 --master_addr="192.168.1.1" --master_port=1234 main.py
mp方法
第二个方法就是利用torch的多线程包
import torch.multiprocessing as mp # rank mp会自动填入 def main(rank, arg1, ...): pass if __name__ == '__main__': mp.spawn(main, nprocs=TOTAL_GPUS, args=(arg1, ...))
这种运行的时候就跟正常的python文件一致:
python main.py
优缺点
「优点」:相比于DP而言,不需要反复创建和销毁线程;Ring-AllReduce算法提高通信效率;模型同步方便
「缺点」:操作起来可能有些复杂,一般可满足需求的可先试试看DataParallel。
审核编辑:刘清
-
分布式软件系统2009-07-22 5441
-
分布式RAM中怎么异步读取2019-04-16 2171
-
分布式RAM综合问题2019-06-25 2538
-
【木棉花】:简单的分布式任务调度2021-09-03 1891
-
【木棉花】JS分布式能力——学习笔记2021-09-04 1345
-
HarmonyOS教程—分布式运动健康应用(智能穿戴端)2021-09-06 3126
-
如何高效完成HarmonyOS分布式应用测试?2021-12-13 2399
-
分布式电源的相关资料推荐2021-12-29 928
-
分布式系统硬件资源池原理和接入实践2023-12-06 614
-
鸿蒙原生应用开发——分布式数据对象2023-12-08 575
-
什么是CDDI (Copper Distributed Da2010-02-22 881
-
GL Studio的分布式虚拟训练系统关键技术2011-03-22 982
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 4089
-
基于PyTorch的模型并行分布式训练Megatron解析2023-10-23 5961
-
HarmonyOS开发实例:【分布式数据服务】2024-04-18 1687
全部0条评论

快来发表一下你的评论吧 !
