

革命性的小芯片 GPU 设计时代开启
处理器/DSP
描述
在过去的几年里,技术创新和计算机芯片的发展明显放缓,特别是与我们过去 20 年左右的习惯相比,这尤其适用于变得更大、更复杂、更浪费且生产成本极高的高端图形处理器。
最近,就连饱受争议的英伟达老板黄仁勋也再次扣动了扳机,宣布著名的摩尔定律“死了”。让我们提醒您,摩尔定律指的是戈登摩尔(英特尔的技术先驱和联合创始人)早期的预测,即现代微芯片上的晶体管数量每两年翻一番。当然,这可以显着提高性能、提高能源效率并降低生产成本。
而AMD RDNA3的发布,似乎昭示着新时代的开始?
由于单片设计中的现代高端图形处理器一代又一代地变得越来越复杂和昂贵,AMD 决定为其 RDNA3 图形处理器采用全新的革命性小芯片设计。他们最新的图形处理器 Navi 31 基于小芯片设计,这意味着我们没有一个大的单片芯片,而是几个较小的芯片的组合,然后一起形成一个整体,从而实现了我们在图形处理器中看到的所有功能。

这是否听起来很熟悉?因为这正是AMD 多年来一直在其 Ryzen 和 Epic 处理器中使用的技术。正是因为采用了小芯片设计,他们取得了巨大成功。然而,GPU 是一种略有不同的产品,很难指望主处理器中 chiplet 设计的所有优势会像那样转移到图形芯片的世界。
但让我们也提一下具体的产品。AMD 的图形处理器 Navi 31,是历史上第一个小芯片 GPU,该产品是两款最新显卡——Radeon RX 7900 XTX 和 Radeon RX 7900 XT 的基础。XTX是旗舰机型,拥有更多的shader处理器,更高的内存带宽,更多的显存,而XT则是有些弱化的版本。
GCD + MCD = 小芯片 GPU
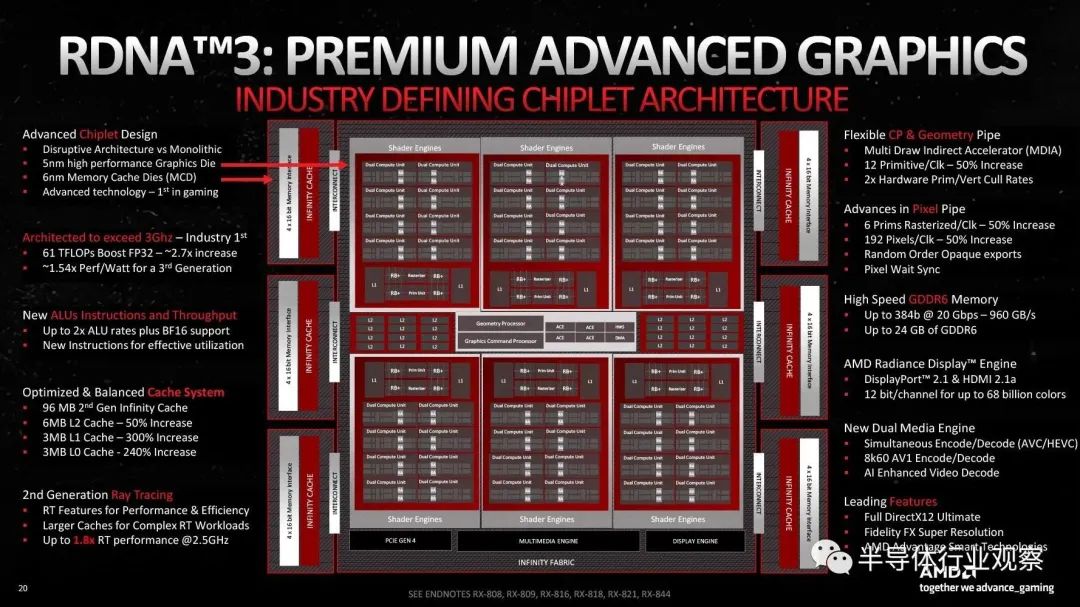
图形处理器 Navi 31 由令人印象深刻的 580 亿个晶体管组成,小芯片架构包括一个 GCD(图形计算芯片)内核和多达 6 个 MCD(内存缓存芯片)内核。
300 平方毫米的 GCD 核心包含着色器处理器、ROP 单元和现代 GPU 的所有其他组件,采用台积电更先进的 5 纳米工艺制造。另一方面,较小的 MCD 小芯片尺寸仅为 37 平方毫米,包含内存控制器和 Infinity 缓存,并使用 6 纳米工艺制造。
也就是说,AMD 已经确定着色器处理器和其他单元从使用最现代的生产工艺中获益更多,而内存控制器和缓存则不需要使用最新的工艺。从这个意义上说,小芯片架构的使用降低了成本,因为使用尺寸更小的更小芯片,一个晶圆上的缺陷芯片数量要少得多。
然而,图形处理器的小芯片方法的关键问题肯定是延迟的增加。图形处理器对增加的延迟极为敏感。著名的 Infinity Fabric 总线与 AMD 的图形芯片主处理器是不可能的,因为它太慢了。
AMD 使用全新的 Infinity Link 总线(即 Infinity Fanout Links 系统)连接 GDC 和 MCD 部件,从而在 GCD 和 MCD 小芯片部件之间实现 5.3 TB/s 的带宽。这种超级先进的互连系统无疑是小芯片 GPU 设计的关键决定因素。此外,AMD 计划通过更高的运行时钟来消除延迟增加的问题。
Navi 31:重新设计的 CU 和更好的光线追踪
说到时钟速度,Navi 31 是多年来第一款针对着色器处理器(即 ROP 和纹理单元以及芯片的其他部分)具有不同时钟速率的图形处理器。着色器处理器的工作时钟略低于芯片的其余部分。
目前最强版本的Navi 31图形芯片(RX 7900 XTX)的GCD代码共有96个CU(计算单元)单元,同样数量的光线追踪单元,6144个着色器处理器和192个ROP单元。与其前身 Navi 21 相比,AMD 对 Navi 31 图形处理器中的计算单元 (CU) 进行了重大重新设计和改进。AMD 表示,Navi 31 芯片中的 CU 在相同的运行时钟下将 IPC 提高了 17.4%。
此外,关键的创新是现在 FP32 单元可以同时执行两个操作,AMD 称之为 Dual Issue SIMD。这些处理器可以在每个数据路径中处理两条指令,与 RDNA 2 图形处理器相比,理论上至少可以达到两倍的指令速率。
然而,这只是理论上的可能性。作为这种设计的结果,在实践中实际可以看到多少加速将在很大程度上取决于驱动程序中的编译器。
RDNA 3 CU 单元的新颖之处当然是独立的 AI 加速器(总共 192 个,每个 CU 单元 2 个),用于加速矩阵乘法等操作。现在的第二代光线追踪单元也得到了改进。
Navi 31 GCD 的光线追踪单元支持额外的指令,光线追踪得到改进和优化,并根据场景进行分类。与 RDNA 2 架构相比,AMD 承诺每个 CU 的性能提升高达 50%。
最后,当我们谈到 Navi 31 中的 GCD 时,与 RDNA 2 图形芯片相比,L0、L1 和 L2 缓存内存的数量有了显着增加。
Radiance 显示引擎 :165 Hz 时 8k!
如果我们回到小芯片 MCD,我们可以说 AMD 在使用 320 或 384 位总线方面增加了内存带宽,尽管仍然使用 GDDR6 内存。有趣的是,L3 缓存或 Infitnity 缓存的数量小于 RDNA 2 Navi 21 图形处理器的数量,以降低能耗。另一方面,与 RDNA 2 芯片的 1.2 TB/s 相比,Infinity 缓存现在的速度是 2.5 TB/s 的两倍。

Navi 31 还带来了显着改进的 GPU 部分,负责图像显示和多媒体。首先,新的 Radiance Display Engine 全面支持 DisplayPort 2.1,它可以通过单根电缆以 165 Hz 的 8k 分辨率或 480 Hz 的 4k 分辨率显示图像。每个通道还可以使用 12 位彩色显示。与仍“仅”支持 DP 1.4 的最新 Nvidia 卡相比,这是一个很大的优势。
此外,Navi 31 还可以通过两个独立的编码器/解码器对 AV1 编码和解码进行硬件加速,从而可以同时对两个视频流进行转码或以每秒两倍的帧数进行转码。
AMD 通过 Navi 31 图形芯片打破僵局,为图形处理器世界带来了真正革命性的小芯片 GPU 设计。这将在未来证明有多成功还有待观察。潜力当然是巨大的。在现代 GPU 中堆叠乐高积木的原理和小芯片的模块化听起来确实很有未来感。然而,主要目标应该是在图形处理器的小芯片设计中组合多个 GCD,这应该会在未来将我们引入一个物理芯片上的多 GPU 配置时代。
编辑:黄飞
-
国产FPGA低成本替代革命性Quantum架构助您摆脱芯片缺货2021-08-04 5453
-
革命性LED驱动方案2013-07-19 3334
-
恩智浦发布革命性简单易用的LPC800.pdf2016-09-19 1467
-
革命性的笔HeatVanish,写出来的字加热就会消失2016-12-17 3191
-
Eduscope显示屏革命性产品2018-11-22 2574
-
什么是革命性MU-MIMO算法?2019-08-15 3140
-
电子病历需要革命性技术创新2012-12-03 2038
-
安森美半导体和AfterMaster Audio Labs 将推出革命性的音频芯片2015-05-05 2230
-
揭晓革命性图形处理加速技术GPU Turbo2018-06-08 9601
-
华为麦芒7将发布,搭载麒麟710芯片,且支持革命性的GPU Turbo技术2018-09-11 2667
-
华为是5G革命性技术的先锋2019-04-22 966
-
英特尔计划推出一款革命性的模拟芯片2019-11-06 907
-
革命性的VR全景技术2020-03-15 2903
-
GTC2022大会黄仁勋:GPU使AI发生革命性的转变2022-03-23 2127
-
爱立信推出革命性OSS/BSS产品组合2025-06-24 16113
全部0条评论

快来发表一下你的评论吧 !
