

基于长度感知注意机制的长度可控摘要模型
描述
以往的长度可控摘要模型大多在解码阶段控制长度,而编码阶段对指定的摘要长度不敏感。这样模型倾向于生成和训练数据一样长的摘要。在这篇论文中,作者提出了一种长度感知注意机制(LAAM,length-aware attention mechanism)来适应基于期望长度的编码。
本文的方法是在由原始训练数据构建的摘要长度平衡数据集上训练 LAAM,然后像往常一样进行微调。结果表明,这种方法可以有效地生成具有所需长度的高质量摘要,甚至是原始训练集中从未见过的短长度摘要。

论文题目:Length Control in Abstractive Summarization by Pretraining Information Selection
收录会议:
ACL 2022
论文链接:
https://aclanthology.org/2022.acl-long.474.pdf
代码链接:
https://github.com/yizhuliu/lengthcontrol
背景
摘要任务目的是改写原文,在简明流畅的摘要中再现原文的语义和主题。为了在不同的移动设备或空间有限的网站上显示摘要,我们必须生成不同长度的摘要。
长度可控的摘要是一个多目标优化问题,包括:
在期望的长度内生成完整的摘要
以及根据期望的长度选择适当的信息
相关方法
现有的基于编解码器模型的长度可控摘要可分为两类:
解码时的早停
编码前的信息选择
解码过程中的早停方法关注何时输出 eos(end of sequence),也就是摘要的结束标志。有人设计了专门的方法。这个专门方法是通过在测试期间将期望长度的位置上的所有候选单词分配 −∞ 的分数来生成 eos。这个方法可以应用于任何 seq2seq 模型。然而,这些方法只是简单地为解码器增加了长度要求,而忽略了从源文档编码内容或信息选择也必须适应不同长度要求的问题。
基于信息选择的方法分为两阶段。一个突出的例子是 LPAS,在第一阶段,从源文档中提取最重要的 l 个标记作为所需长度的原型摘要,并在第二阶段通过双编码器对源文档和原型摘要进行编码。一方面,这种两阶段方法会在中间结果中引入噪声。另一方面,这些方法的第二阶段没有第一手的长度信息,这削弱了长度控制。
本文方法
在本文中,作者提出了LAAM(长度感知注意机制),它扩展了 Transformer seq2seq 模型,具有根据长度约束在上下文中选择信息的能力。
LAAM 重新 normalize 编码器和解码器之间的注意力,以增强指定长度范围内具有更高注意力分数的 token,帮助从源文档中选择长度感知信息。随着解码进行,增强 token 的数量将会逐步减少,直到 eos 获得最高的注意力分数,这有助于在指定长度上停止解码过程。
LAAM 可以被认为是上一节两类方法的混合版本。
同时作者观察到,在现有训练集中,不同长度的摘要数量有很大差异。为了平衡摘要在不同长度范围内的分布,本文提出了一种启发式方法:首先定义摘要长度范围,然后从原文中直接抽取不同长度的摘要,根据特定指标控制抽取摘要的相关度,从而创建长度平衡数据集(LBD,length-balanced dataset)。
在本文方法中,先从原始的摘要数据集创建一个 LBD。之后,在 LBD 上预训练LAAM,以增强 LAAM 在长度约束下的文本选择能力。最后,将预训练后的 LAAM 在原始数据集上微调,以学习将所选文本改写为不同长度的摘要。
当前训练数据集中没有短摘要,微调后的模型没有见过短摘要,所以如果用它生成短摘要的话算是 zero-shot。得益于 LDB 的预训练,本文的方法可以解决zero-shot情况下的长度控制问题。
本文的主要贡献:
提出了LAAM(长度感知注意机制)来生成具有所需长度的高质量摘要。
设计了一种启发式方法,从原始数据集中创建一个LBD(长度平衡数据集)。在 LBD 上对 LAAM 进行预训练后,LAAM 效果能有提升,并且可以有效解决 zero-shot 情况下的短摘要生成问题。
LAAM
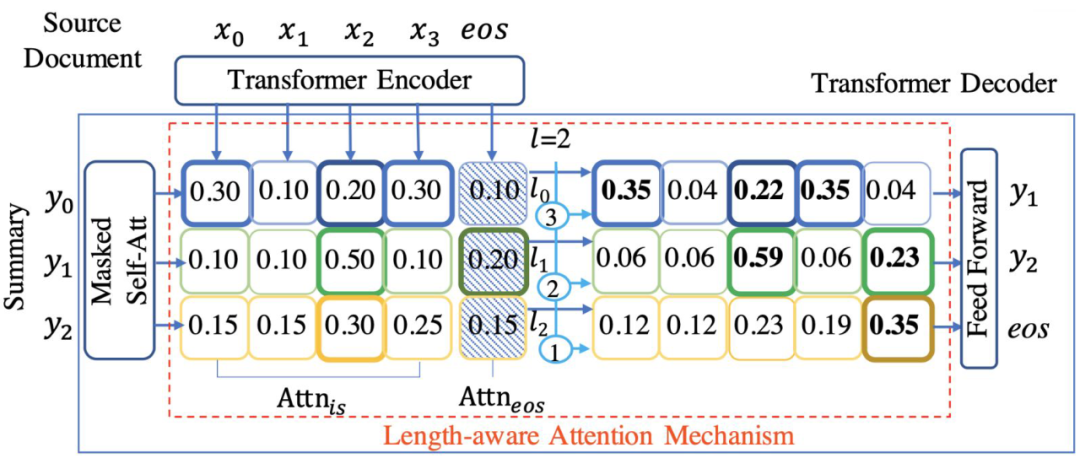
上图是 Transformer 解码器。
左上方为源文档输入:,作为注意力的 Key。
最左侧为模型当前输出:,作为注意力的 Query,两者点乘得到注意力矩阵。 注意力矩阵分为两部分, 负责文本信息选择, 负责结束标志选择
注意力矩阵的第一行加粗了 Top3,第二行加粗了 Top2,第三行加粗了 Top1,对加粗的进行提权,本文通过这种方式向模型传递句子剩余预测长度信息。
也会进行提权,并且越接近指定长度,提权幅度越大,模型也就更容易预测出 eos。
提权后要进行一次归一化,不然和不为 1。
这就是本文提出的 LAAM 模型。
总结
本文方案的整体流程是:
用原始训练集生成 LBD(长度平衡数据集)
在 LBD 上预训练 LAAM 模型
在原始训练集上微调 LAAM 模型
审核编辑 :李倩
-
现代长度测量方法综述2009-03-18 991
-
基于旋转编码器的长度测量系统设计2010-01-11 1689
-
天线的长度计算方法2008-03-12 16390
-
IC包装内部的长度计算 (pin delay)2009-09-06 4145
-
最大单段长度/五类线是什么意思2010-03-26 2083
-
基于数据包长度的网络隐蔽通道2012-02-23 877
-
基于RBF网络预测模型优化压缩视频长度王晓东2017-03-17 854
-
发送队列长度功率控制2018-03-20 1154
-
基于多层CNN和注意力机制的文本摘要模型2021-04-07 1226
-
关于热缩管的出厂长度和恢复长度2022-05-26 3018
-
电缆长度计算规则 预留长度怎么计算?2022-09-07 28605
-
如果变频器到电机的电缆长度超出变频器的标准电缆长度,对系统有什么影响?2023-11-06 4672
-
如何利用实时示波器测量线缆长度2024-05-27 4108
-
hdmi线缆长度根据什么决定选择2024-06-06 7192
-
关于伺服电缆长度问题的详解2025-11-01 1683
全部0条评论

快来发表一下你的评论吧 !
