

京东:基于多类目MoE模型的电商搜索引擎
描述
商品搜索引擎是电商平台满足用户购物需求的一个重要系统,它根据用户输入的搜索词,返回个性化的排序列表。商品一般会被归为某一大类下某个小类目,例如电子产品,在电子产品这个大类目下面还有更细粒度的类目(冰箱或者电视)。这种体系用于构造查询类别的层次结构。在不同的查询类别中,价格和品牌知名度等特征的分布差异很大。在CTR(点击率)/CVR(转化率)预估问题中,特征重要性在不同类目间也是不一样的。本文主要介绍专家混合模型(MoE)在京东搜索精排中的应用,以及结合实际场景对MoE模型进行的一系列改进。
Part1. 背景介绍
越来越多的人转向电子商务来满足他们的购物需求,这给搜索排名带来了新的挑战。电子商务搜索排名的一个关键输入是产品类别标签,店主通常被要求用特定的类别来标记他们的产品,以方便搜索索引。从这些产品类别中,可以构造查询类别的概念,通常是通过聚合在查询下正确检索到的最频繁出现的产品类别。目前大多数电子商务排名系统都没有为每个查询类别部署专用模型的工程资源,即使是主要的查询类别也是如此。但是作为人工编目员,自然的策略是首先确定查询最可能属于的类别,然后检索该类别中的项目。不同类别的特性对于产品排名的重要性可能不同。直观地说,根据用户购买反馈判断,不同类别的单独排名策略应该能够提高整体产品搜索相关性。
京东电商平台有一套完整的以树形结构组织的多层级类目结构。下图是一个两层级类目结构的示意图,不同的Top-Categories 之间,用户的购物行为会有比较明显的差异,例如:当用户搜索食品相关商品时,可能选择销量高的;而当搜索服饰相关商品时,可能会更关注风格、品牌等信息。相反同一个Top-Categories下的Sub-Categories之间,用户的购物行为一般比较接近。
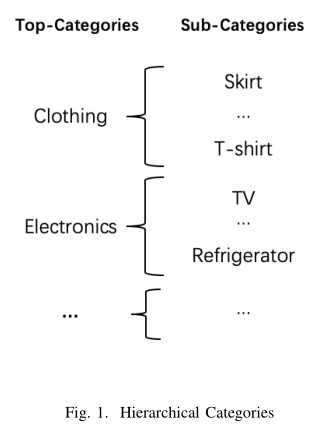
此外,对于一些小类目的商品,在训练集样本量上和大类目相比差距悬殊,在模型训练过程中会被大类目商品的样本所影响和主导。针对类目差异和小类目学习这两个问题,本文提出了一种多类目MoE(Mixture of Experts)模型。
Part2. 多类目MoE模型
MoE模型
MoE 主要包括两个核心部分:门网络(gating network)和专家网络(expert network)。门网络的输出作为对应的专家网络的权重,用于对专家网络的输出进行加权求和。MoE 模型的输出可以写成下面的公式:
其中,N表示专家网络的个数,G表示门网络,Q表示专家网络。
Top-K gating MoE模型
模型会根据门网络的输出,选择最大的K个权重所对应的专家网络进行激活,然后只对选中的K个专家网络的输出进行加权求和。计算公式如下:
在Top_k MoE模型中,如果一个专家网络对应的权重值不在最高的K个集合里,那么经过softmax函数之后权重会变为0。从而在模型训练中这些专家网络不会被激活,能降低模型的计算复杂度。
多类目MoE的模型
针对上述提到的类目差异和小类目学习两个问题,本文在Top_K MoE 的基础上加入了两种改进方法,提出了多类目MoE的模型结构,如下图:
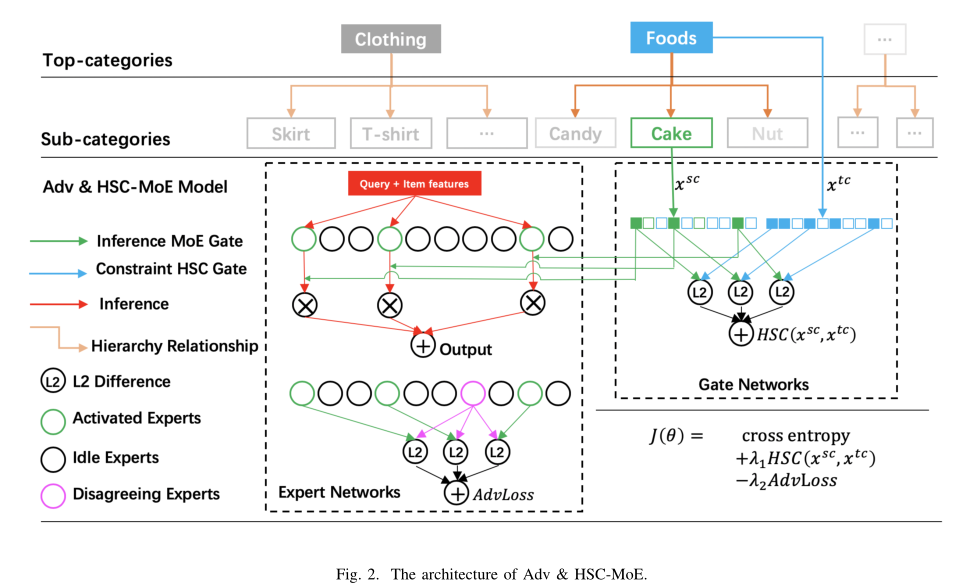
(1)Hierarchical Soft Constraint(HSC)网络
针对小类目样本学习问题,本文的改进是增加一个与MoE门网络结构相同的HSC门网络(图种蓝色部分)。HSC门网络的输入是Top-Category,输出与MoE的门网络结构维度一致,代表了不同专家网络对于Top-Category 的重要程度。同时将激活的专家网络对应的权重和HSC门网络对应的权重的L2距离作为模型训练的一个损失项,加入到模型的训练过程中。
具体来说,图2中的Top-Category和Sub-Category具有层次关系,Top-Category是父节点,Sub-Category是子节点。为了进一步强调不同门网络的功能,我们分别将它们称之为inference MoE gate(绿色部分)和constraint HSC gate(蓝色部分)。
a. Inference MoE Gate
将Sub-Category的嵌入向量,输入inference gate,其输出代表专家的权重。定义inference gate函数如下:
其中,是一个 q×N的可训练的权重矩阵,q表示embedding的维度,N表示expert的个数。
为了节省计算,只在中保留前K个值,并将其余值设置为−∞。然后应用softmax函数从前K个中得到如下的概率分布:
,如果
,如果<
由于有K个大于0的值,为了节省计算,只激活这些对应的专家。模型的计算复杂度取决于单个专家的网络和K的取值。
b. Inference MoE Gate
在模型中,constraint gate和inference gate具有相同的结构。用表示constraint gate,表示inference gate,constraint gate的输入特征记为,是Top-Category的嵌入向量,定义inference gate和constraint gate之间的分层软约束(HSC)如下:
通过上述HSC网络,可以让相同Top-Category下的所有Sub-Category所激活的专家网络尽量的接近。尤其对于样本量少的小类目,可以利用到相同Top-category下的其他类目信息,能一定程度上解决小样本学习难的问题。
(2)Adversarial Regularization
第二个改进是Adversarial Regularization。在Top_K门网络结构中,对于每条样本,专家网络都会分为激活的专家网络和没有激活的专家网络。Adversarial Regularization的目的是在训练过程中让不同专家网络尽量区别开,避免专家网络的预测结果相同。即鼓励激活的专家网络和没有被激活的专家网络给出的预测结果差异较大。Adversarial Regularization计算公式如下:
其中, 表示激活的专家网络集合, 表示没有被激活的专家网络集合。
增加了HSC网络和Adversarial Regularization之后,模型的损失函数如下所示:
Part3. 实验结论
作者在Amazon和In-house两个数据集上分别评估了所提出模型的效果。表格中的Adv-MoE和HSC-MoE分别表示只有Adversarial Regularization和HSC loss的两个模型,Adv&HSC-MoE表示作者提出的最终多类目模型。
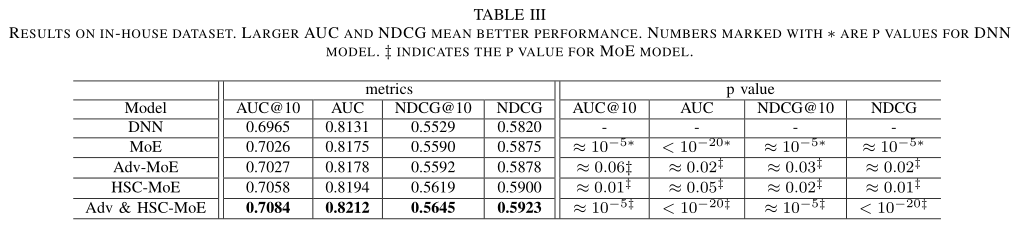
作者首先在In-house数据集上测试了模型的整体效果、类目差异的效果以及在小样本类目上的提升效果。表3给出了各个模型在AUC和NDCG两个指标上结果。与DNN模型相比,本文提出的Adv&HSC-MoE模型在AUC指标上实现了0.96%的增益(NDCG为0.99%),具有较好的泛化性能。
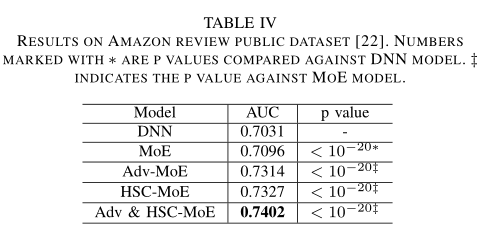
同时,作者也在amazon数据集上做了实验,下表显示改进后的Adv-MoE、HSC-MoE和Adv& HSC-MoE结果与In-house一致,验证了对抗正则化和分层软约束技术的一般适用性。
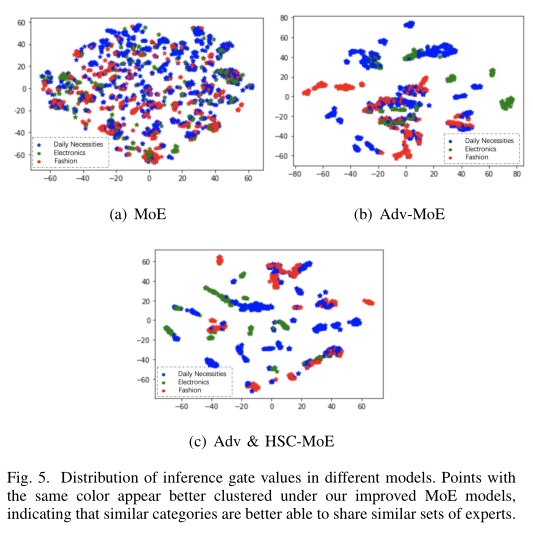
MoE模型门网络的输出代表了各个专家网络的权重,作者同样测试了不同类目下门网络的输出结果,以评估模型对于类目差异的学习效果。本文将门网络的输出结果使用T-SNE降维展示出来,以便观察不同类目的聚类效果。图5中蓝色表示日用百货类目,绿色表示电器类目,红色表示流行服饰类目。结果显示,本文的方法聚类效果更好,这表明对于相似的类目,本文提出的模型更倾向于选择相似的专家网络,差异大的类目,更倾向于选择不同的专家网络。
Part4. 总结
本文提出的对抗性正则化和层次软约束技术是在产品搜索中开发类别感知排名模型的有效方法。它在行业规模的数据集上取得了显著的改进,主要体现在以下几个方面:(1)同一Top-Categories下的Sub-Categories可以共享相似的专家,从而克服了有限训练数据下的参数稀疏性;(2)对抗性正则化鼓励专家“独立思考”,从不同角度处理每个问题。
审核编辑 :李倩
-
[分享]最强山寨版搜索引擎震惊世界-熊熊搜索2008-11-22 3376
-
参加搜索引擎营销SEM培训的好处?2011-04-11 3399
-
详解搜索引擎中的投票机制2019-04-11 2491
-
基于网格技术的并行搜索引擎2009-03-30 939
-
分布式多搜索引擎系统的研究与实现2009-06-09 610
-
教育网BBS搜索引擎设计与实现2009-06-17 1161
-
主题搜索引擎的研究2010-07-05 1062
-
网络搜索引擎,网络搜索引擎的工作原理2010-03-26 1750
-
基于JAVA技术的搜索引擎的研究与实现2012-05-07 1890
-
垂直搜索引擎是什么_垂直搜索引擎有哪些2018-01-04 8867
-
介绍五个具有高级功能的搜索引擎2018-04-04 8276
-
人工智能时代的到来,搜索引擎将会是什么样子呢?2019-03-20 2643
-
苹果自研的搜索引擎干的过谷歌吗?2020-12-22 2756
-
基于蜕变测试的用户搜索引擎性能分析2021-05-25 965
-
NAS下搭建linux命令搜索引擎教程2023-02-24 2023
全部0条评论

快来发表一下你的评论吧 !
