

腾讯优图/浙大/北大提出:重新思考高效神经模型的移动模块
描述
引言
本文重新思考了 MobileNetv2 中高效的倒残差模块 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,归纳抽象了 MetaMobile Block 的一般概念。受这种现象的启发,作者设计了一种面向移动端应用的简单而高效的现代反向残差移动模块 (InvertedResidualMobileBlock,iRMB),它吸收了类似 CNN 的效率来模拟短距离依赖和类似 Transformer 的动态建模能力来学习长距离交互。所提出的高效模型 (EfficientMOdel,EMO) 在 ImageNet-1K、COCO2017 和 ADE20K 基准上获取了优异的综合性能,超过了同等算力量级下基于 CNN/Transformer 的 SOTA 模型,同时很好地权衡模型的准确性和效率。
动机
近年来,随着对存储和计算资源受限的移动应用程序需求的增加,涌现了非常多参数少、FLOPs 低的轻量级模型,例如Inceptionv3时期便提出了使用非对称卷积代替标准卷积。后来MobileNet提出了深度可分离卷积 depth-wise separable convolution 以显着减少计算量和参数,一度成为了轻量化网络的经典之作。在此基础上,MobileNetv2 提出了一种基于 Depth-Wise Convolution (DW-Conv) 的高效倒置残差块(IRB),更是成为标准的高效模块代表作之一。然而,受限于静态 CNN 的归纳偏差影响,纯 CNN 模型的准确性仍然保持较低水平,以致于后续的轻量化之路并没有涌现出真正意义上的突破性工作。
Swin
PVT
Eatformer
EAT
随着 Transformer 在 CV 领域的崛起,一时间涌现了许多性能性能超群的网络,如 Swin transformer、PVT、Eatformer、EAT等。得益于其动态建模和不受归纳偏置的影响,这些方法都取得了相对 CNN 的显着改进。然而,受多头自注意(MHSA)参数和计算量的二次方限制,基于 Transformer 的模型往往具有大量资源消耗,因此也一直被吐槽落地很鸡肋。
针对 Transformer 的这个弊端,当然也提出了一些解决方案:
设计具有线性复杂性的变体,如FAVOR+和Reformer等;
降低查询/值特征的空间分辨率,如Next-vit、PVT、Cvt等;
重新排列通道比率来降低 MHSA 的复杂性,如Delight;
不过这种小修小改还是难成气候,以致于后续也出现了许多结合轻量级 CNN 设计高效的混合模型,并在准确性、参数和 FLOPs 方面获得比基于 CNN 的模型更好的性能,例如Mobilevit、MobileViTv2和Mobilevitv3等。然而,这些方法通常也会引入复杂的结构,或者更甚者直接采用多个混合的模块如Edgenext和Edgevits,这其实是不利于优化的。
总而言之,目前没有任何基于 Transformer 或混合的高效块像基于 CNN 的 IRB 那样流行。因此,受此启发,作者重新考虑了 MobileNetv2 中的 Inverted Residual Block 和 Transformer 中的 MHSA/FFN 模块,归纳抽象出一个通用的 Meta Mobile Block,它采用参数扩展比 λ 和高效算子 F 来实例化不同的模块,即 IRB、MHSA 和前馈网络 (FFN)。
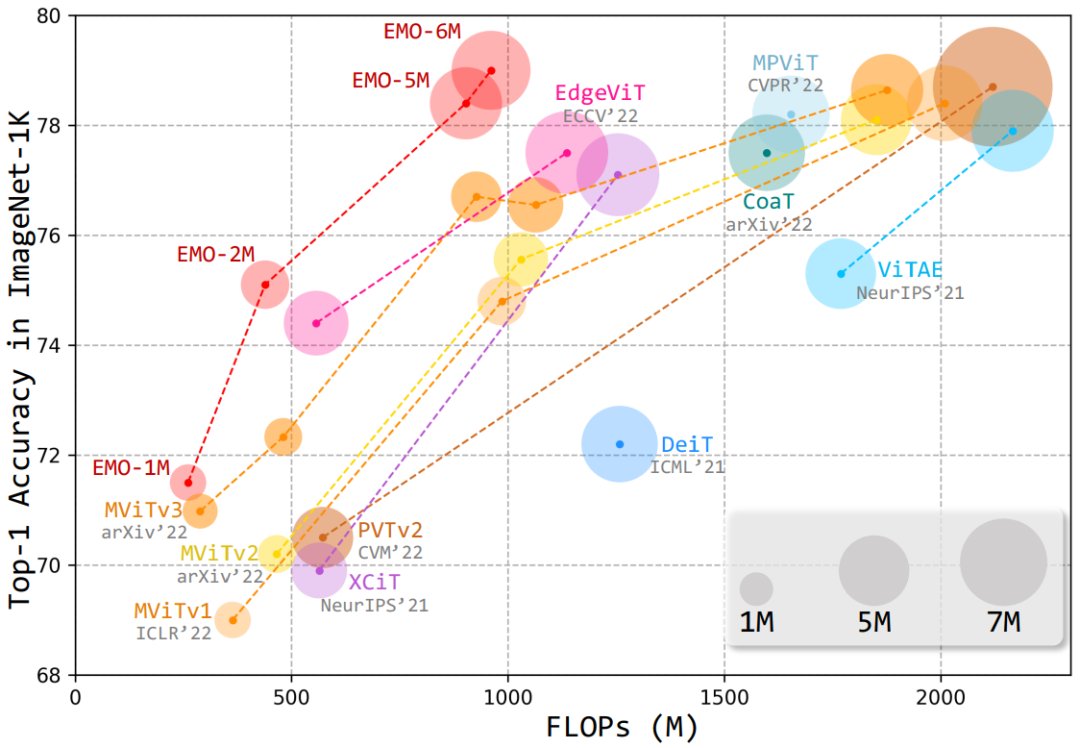
基于此,本文提出了一种简单高效的模块——反向残差移动块(iRMB),通过堆叠不同层级的 iRMB,进而设计了一个面向移动端的轻量化网络模型——EMO,它能够以相对较低的参数和 FLOPs 超越了基于 CNN/Transformer 的 SOTA 模型,如下图所示:
方法
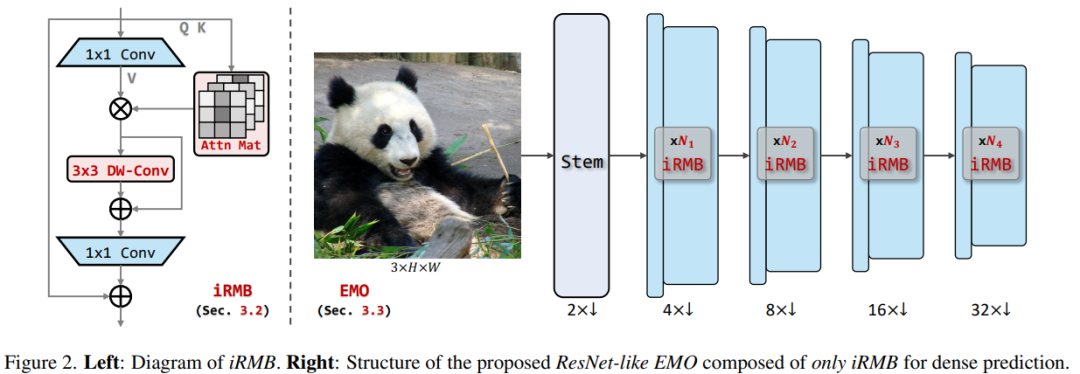
EMO
上图是整体框架图,左边是 iRMB 模块的示例图。下面让我们进一步拆解下这个网络结构图。
Meta Mobile Block
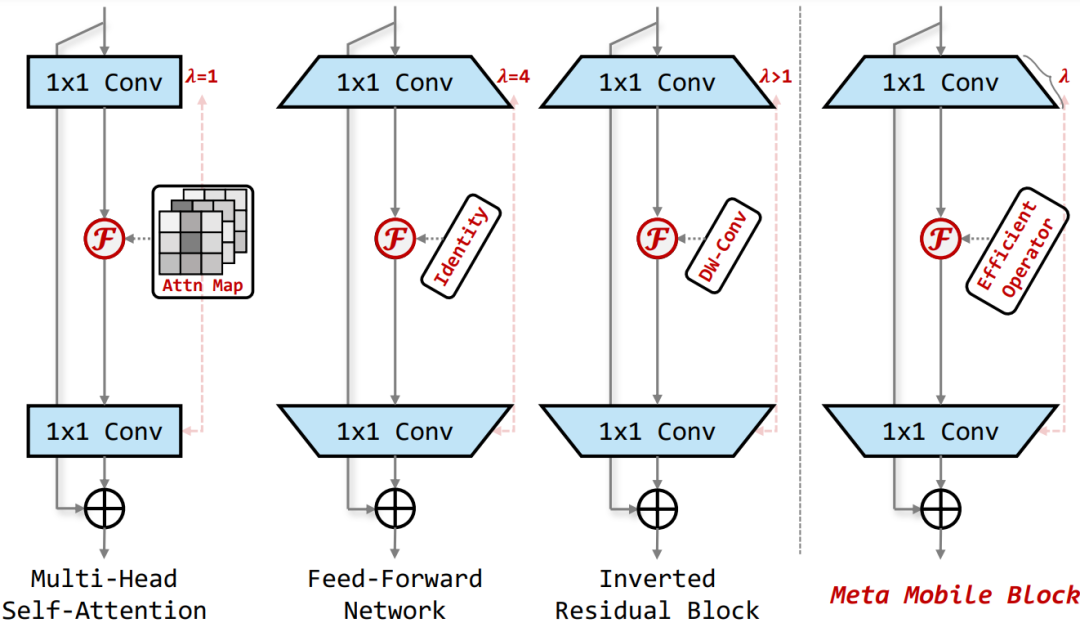
Meta Mobile Block
如上所述,通过对 MobileNetv2 中的 Inverted Residual Block 以及 Transformer 中的核心 MHSA 和 FFN 模块进行抽象,作者提出了一种统一的 Meta Mobile (M2) Block 对上述结构进行统一的表示,通过采用参数扩展率 λ 和高效算子 F 来实例化不同的模块。
Inverted Residual Mobile Block
基于归纳的 M2 块,本文设计了一个反向残差移动块 (iRMB),它吸收了 CNN 架构的效率来建模局部特征和 Transformer 架构动态建模的能力来学习长距离交互。
具体实现中,iRMB 中的 F 被建模为级联的 MHSA 和卷积运算,公式可以抽象为 。这里需要考虑的问题主要有两个:
通常大于中间维度将是输入维度的倍数,导致参数和计算的二次增加。
MHSA 的 FLOPs 与总图像像素的二次方成正比。
具体的参数比对大家可以简单看下这个表格:
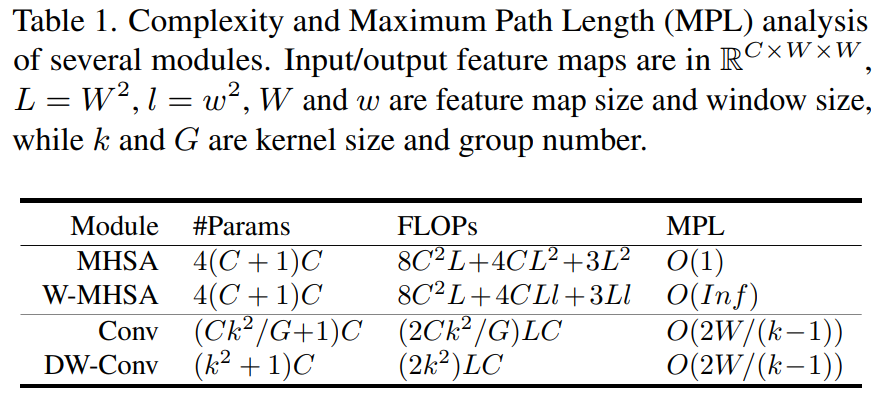
因此,作者很自然的考虑结合 W-MHSA 和 DW-Conv 并结合残差机制设计了一种新的模块。此外,通过这种级联方式可以提高感受野的扩展率,同时有效的将模型的 MPL 降低到 。
为了评估 iRMB 性能,作者将 λ 设置为 4 并替换 DeiT 和 PVT 中标准的 Transformer 结构。如下述表格所述,我们可以发现 iRMB 可以在相同的训练设置下以更少的参数和计算提高性能。
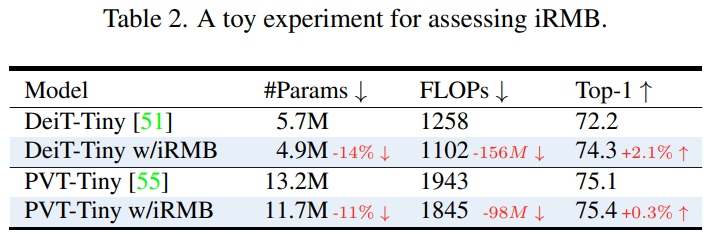
EMO
为了更好的衡量移动端轻量化模型的性能,作者定义了以下4个标准:
可用性。即不使用复杂运算符的简单实现,易于针对应用程序进行优化。
简约性。即使用尽可能少的核心模块以降低模型复杂度。
有效性。即良好的分类和密集预测性能。
高效性。即更少的参数和计算精度权衡。
下面的表格总结了本文方法与其它几个主流的轻量化模型区别:
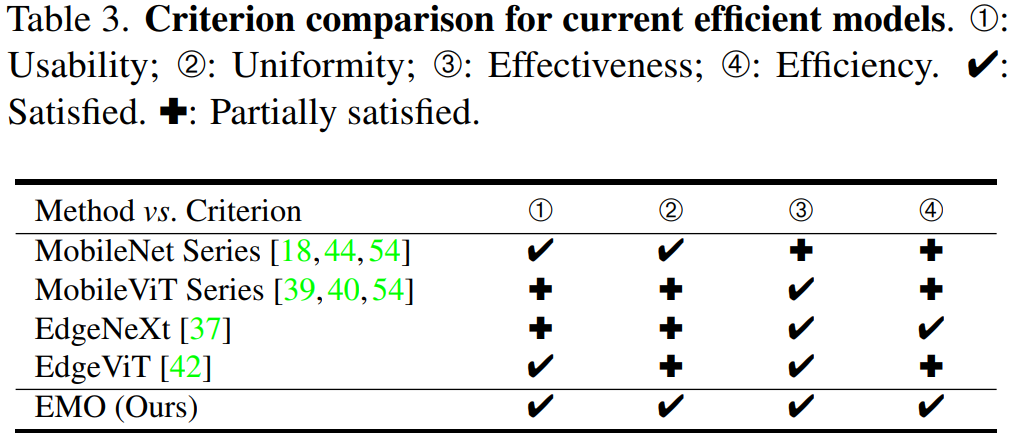
可以观察到以下几点现象:
基于 CNN 的 MobileNet 系列的性能现在看起来略低,而且其参数略高于同行;
近期刚提出的 MobileViT 系列虽然取得了更优异的性能,但它们的 FLOPs 较高,效率方面欠佳;
EdgeNeXt 和 EdgeViT 的主要问题是设计不够优雅,模块较为复杂;
基于上述标准,作者设计了一个由多个 iRMB 模块堆叠而成的类似于 ResNet 的高效模型——EMO,主要体现在以下几个优势:
1)对于整体框架,EMO 仅由 iRMB 组成,没有多样化的模块,这在设计思想上可称得上大道至简;
2)对于特定模块,iRMB 仅由标准卷积和多头自注意力组成,没有其他复杂的运算符。此外,受益于 DW-Conv,iRMB 还可以通过步长适应下采样操作,并且不需要任何位置嵌入来向 MHSA 引入位置偏差;
3)对于网络的变体设置,作者采用逐渐增加的扩展率和通道数,详细配置如下表所示。
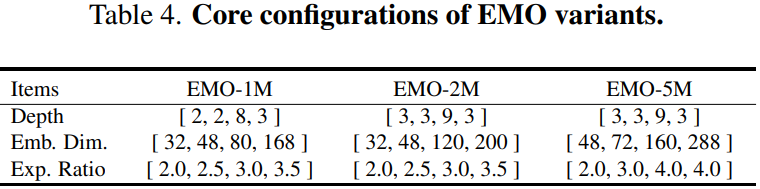
由于 MHSA 更适合为更深层的语义特征建模,因此 EMO 仅在第3和第4个stage采用它。为了进一步提高 EMO 的稳定性和效率,作者还在第1和第2个stage引入 BN 和 SiLU 的组合,而在第3和第4个stage替换成 LN 和 GeLU 的组合,这也是大部分 CNN 和 Transformer 模型的优先配置。
实验
参数比对
先来看下 EMO 和其他轻量化网络的相关超参比对:
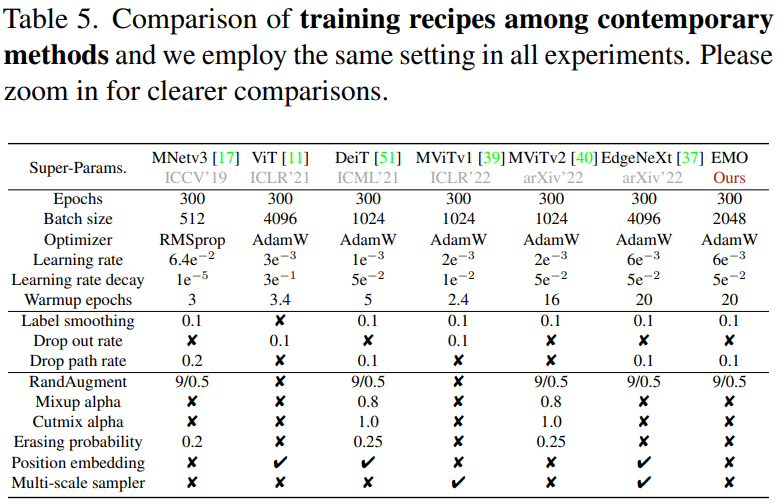
可以看到,EMO 并没有使用大量的强 DataAug 和 Tricks,这也充分体现了其模块设计的有效性。
性能指标
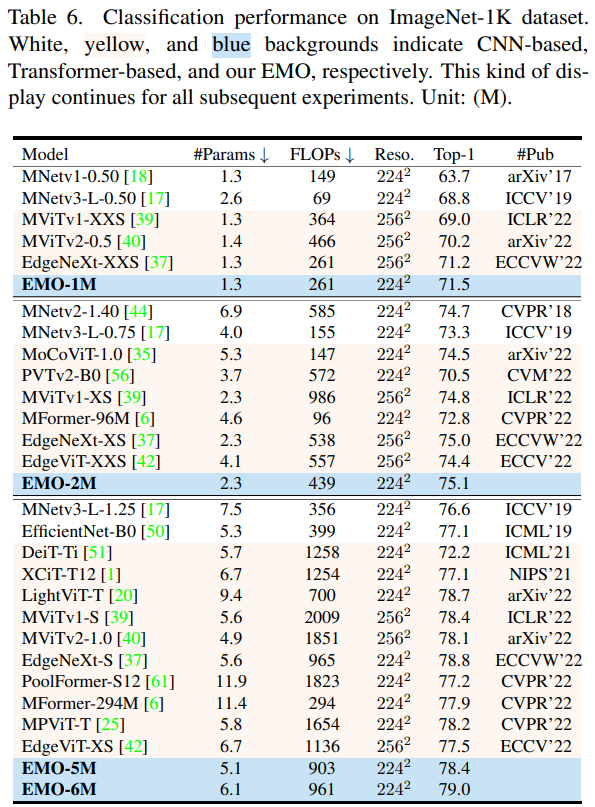
图像分类
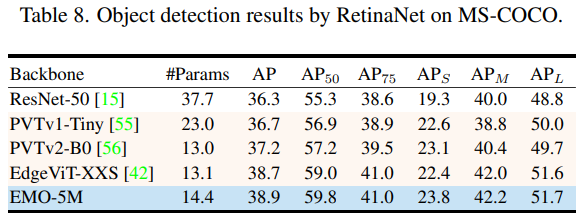
目标检测
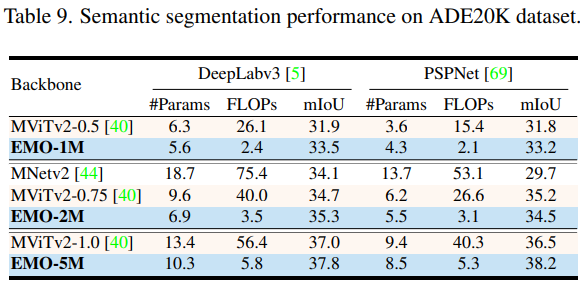
语义分割
整体来看,EMO 在图像分类、目标检测和语义分割 CV 三大基础任务都表现强劲,可以以较少的计算量和参数量取得更加有竞争力的结果。
可视化效果

Qualitative comparisons with MobileNetv2 on two main downstream tasks
从上面的可视化结果可以明显的观察到,本文提出的方法在分割的细节上表现更优异。

Attention Visualizations by Grad-CAM
为了更好地说明本文方法的有效性,作者进一步采用 Grad-CAM 方法突出显示不同模型的相关区域。如上图所示,基于 CNN 的 ResNet 倾向于关注特定对象,而基于 Transformer 的 MPViT 更关注全局特征。相比之下,EMO 可以更准确地关注显着物体,同时保持感知全局区域的能力。这在一定程度上也解释了为什么 EMO 在各类任务中能获得更好的结果。
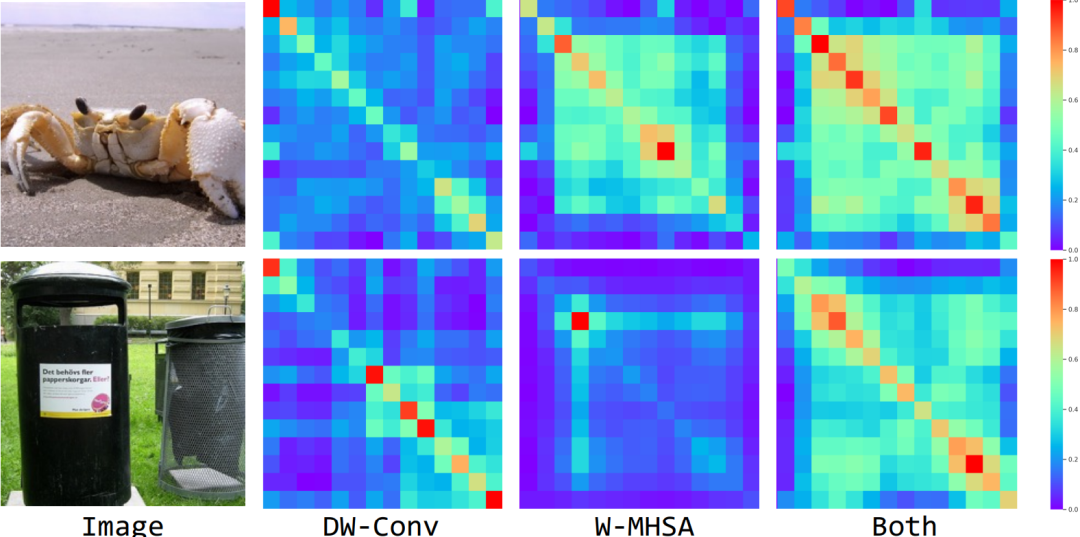
Feature Similarity Visualizations
上面我们提到过,通过级联 Convolution 和 MHSA 操作可以有效提高感受野的扩展速度。为了验证此设计的有效性,这里将第3个Stage中具有不同组成的对角线像素的相似性进行可视化,即可视化 DW-Conv 和 EW-MHSA 以及同时结合两个模块。

可以看出,无论从定量或定性的实验结果看来,当仅使用 DW-Conv 时,特征往往具有短距离相关性,而 EW-MHSA 带来更多的长距离相关性。相比之下,当同时采用这两者时,网络具有更大感受野的模块,即更好的建模远距离的上下文信息。
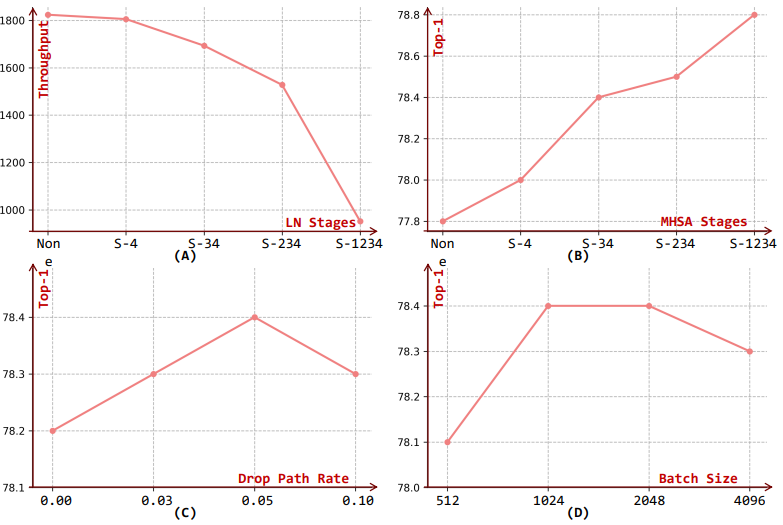
Ablation studies on ImageNet-1K with EMO-5M
最后展示的是本文的消融实验,整体来说实验部分还是挺充实的,感兴趣的小伙伴去看下原文,时间有限,今天我们就分析到这里。
结论
本文探讨了面向移动端的高效架构设计,通过重新思考 MobileNetv2 中高效的 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,作者引入了一个称为 Meta Mobile Block 的通用概念,进而推导出一个简单而高效的现代 iRMB 模块。具体地,该模块包含两个核心组件,即 DW-Conv 和 EW-MHSA,这两个组件可以充分利用 CNN 的效率来建模短距离依赖同时结合 Transformer 的动态建模能力来学习长距离交互。最后,通过以不同的规模堆叠 iRMB 模块搭建了一个高效的类 ResNet 架构——EMO,最终在 ImageNet-1K、COCO2017 和 ADE20K 三个基准测试的大量实验证明了 EMO 优于其它基于 CNN 或 Transformer 的 SoTA 方法。
审核编辑 :李倩
-
脉冲神经元模型的硬件实现2025-10-24 335
-
腾讯元宝升级:深度思考模型“腾讯混元T1”全量上线2025-02-20 1580
-
腾讯AI助手“腾讯元宝”重大更新:支持深度思考功能2025-02-18 2286
-
怎么对神经网络重新训练2024-07-11 1617
-
如何使用TensorFlow将神经网络模型部署到移动或嵌入式设备上2023-08-02 867
-
一种基于高效采样算法的时序图神经网络系统介绍2022-09-28 2927
-
卷积神经网络模型发展及应用2022-08-02 13393
-
用腾讯优图AI视觉模组做一个驾驶疲劳监测仪2019-08-16 2741
-
谷歌发表论文EfficientNet 重新思考CNN模型缩放2019-06-03 7520
-
首届“腾讯云+社区”开发者大会 腾讯优图实验室总监吴永坚出席论坛2019-03-01 2208
-
腾讯优图吴永坚:计算机视觉在产业中的应用实践和前沿思考2019-01-02 5590
-
基于英特尔低功耗VPU,腾讯优图推出人工智能硬件2018-11-20 791
-
腾讯优图:列MegaFace海量人脸识别测试榜首2017-04-10 1584
全部0条评论

快来发表一下你的评论吧 !
