

为什么Chimera GPNPU如此充满想象力和令人眼花缭乱呢
描述
希腊神话中,Chimera是一种巨大的喷火混血动物,由不同的动物部位组成;现在它被用来描述任何想象力丰富、难以置信或令人眼花缭乱的东西。
笔者最近从Quadric那里接触到Chimera GPNPU(通用神经处理器),真是“产品”如其名。
Quadric公司成立于2017年,最初计划基于其新创Chimera GPNPU架构提供推理边缘芯片 (针对物联网“边缘”推理应用的芯片)。
他们的第一块芯片被快速验证,一些早期用户已经在进行试验。但最近,Quadric公司决定将Chimera GPNPU授权为IP,向更广泛的客户群体展示他们的技术。
下图是利用Chimera GPNPU实现面部识别和认证的简化示意图,我们就以此作为切入点看下为什么Chimera GPNPU如此“充满想象力”和“令人眼花缭乱”。
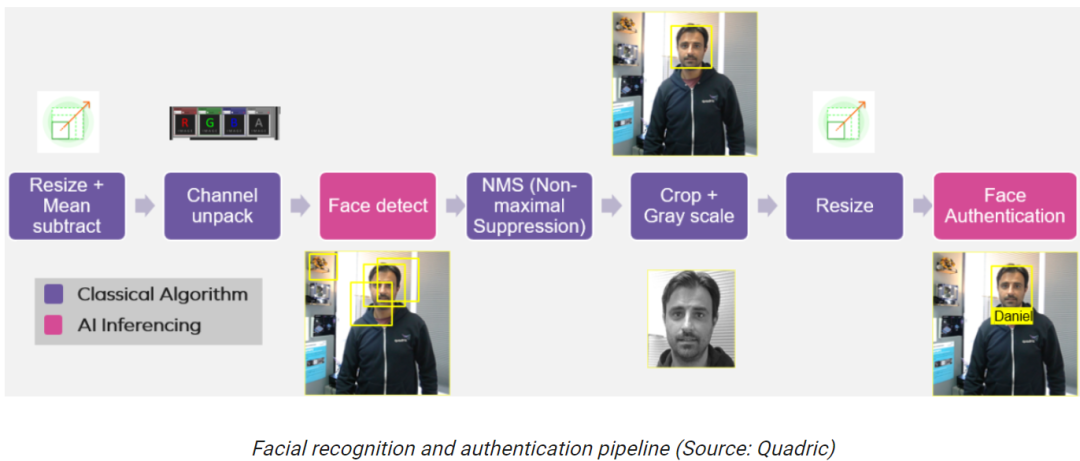
假设所有这些功能都在智能相机SoC中实现,一个摄像机/传感器为左边的第一个功能块提供视频流。这个应用很可能会用于未来几代的门铃摄像头中。
观察两个粉红色的“Face Detect”和“Face Authentication”功能块,它们是通过人工智能/机器学习(AI/ML)推理实现的。
在过去几年中,这种类型的推理发展极为迅速,从学术研究到早期部署,现在几乎成为软件开发中的一个必不可少的元素。
将推理(基于视觉、声音等形式)作为创建应用程序的构建块之一,这种想法我们可以认为是“软件2.0”。
但这实现起来并不容易,SoC传统应对软件2.0挑战的方式如下(a)所示。
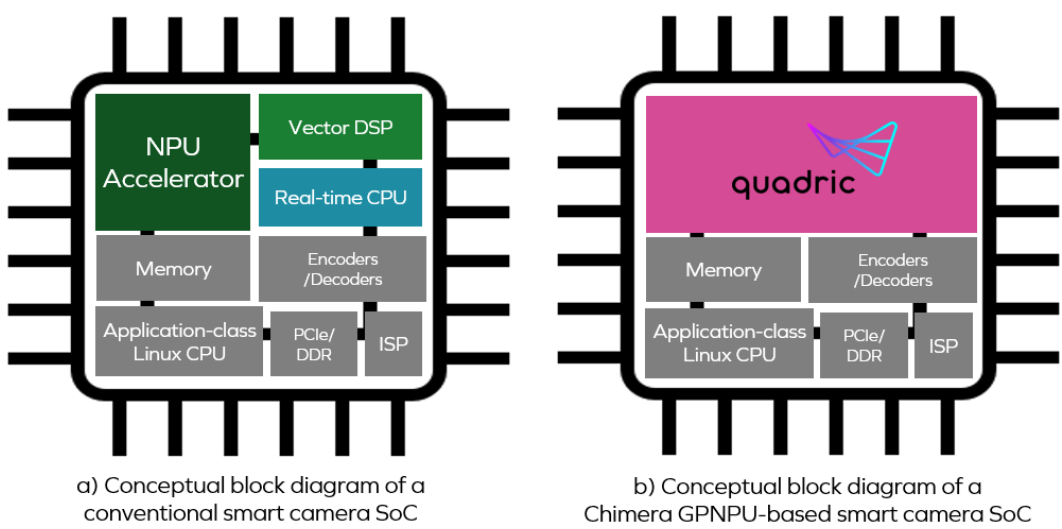
从(a)图中可以看到,神经处理器单元(NPU)、矢量数字信号处理器(DSP)和实时中央处理器(CPU)为三个独立的核心。
要实现前面的面部识别和认证流程,使用常规方法,前两个功能块(Resize和Channel unpack)相关的处理将在DSP核心上执行。
然后,DSP生成的数据将被送到NPU核心上运行神经网络“Face Detect”模型;NPU的输出再送给CPU核心,CPU将运行一个“NMS”算法来决定使用哪个算法效果最好。
然后,DSP将使用CPU识别的边界框在图像上执行更多的任务,如“Crop + Gray Scale”和“Resize”。最后,这些数据将送到NPU核心上运行“Face Authenticate”模型。
用上述方法实现后,我们可能会发现没有达到想要的吞吐率。如何找出性能瓶颈在哪里?另外,三个核心之间交换数据产生了多少功耗?
真正的潜在问题是,拥有三个独立的处理器核心会使整个设计过程变得繁琐。
例如,硬件设计人员必须决定要为每个核心分配多少内存,以及在功能块之间需要多大的缓冲区。同时,软件开发人员需要决定如何在内核之间划分算法。这很痛苦,因为程序员不愿意花大量时间考虑所运行目标平台的硬件细节。
另一个问题是ML模型正在迅速发展,谁都不知道未来几年会有怎样的ML模型。
所有这些问题都会导致ML部署无法尽可能快地加速,因为针对这种类型的常规目标平台进行开发,对于编程、调试和性能调优等方面来说,都是一件非常痛苦的事情。
再回到Chimera GPNPU,它由前面图(b)部分的粉色区域表示。
GPNPU将DSP、CPU和NPU的属性结合在单个核心中,作为一个传统的CPU/DSP的组合,它可以运行C/ C++代码,具有完整的32位标量+向量指令集架构(ISA),同时可以用作一个NN图处理器,运行8位推理优化的ML代码。这种方法通过在同一个引擎上运行两种类型的代码,独特地解决了信号传输的挑战。
我们可以认为Chimera GPNPU是经典的冯·诺依曼RISC机和收缩阵列/2D矩阵架构的混合体。
Chimera GPNPU的一个关键优势是它能够适应不断发展和日益复杂的ML网络。现在东西变得越来越复杂,需要在NN的体系结构中做更多的条件控制流,可以是CNN, RNN, DNN等等。
传统的NPU通常是硬连接的加速器,不能条件执行。例如有一个专用加速器,用户不能在第14层的某个地方停下来检查条件或中间结果,然后分支判断并做各种面向控制流的事情。
在这些情况下,必须在NPU和CPU之间来回移动数据,这将对性能和功耗产生冲击。而使用一个Chimera GPNPU,我们可以在NN和控制代码之间在时钟基础上来回切换。
这里还有很多需要讨论,比如Chimera GPNPU在执行卷积层(这是CNN的核心)方面的出色表现,以及它们的TOPS(每秒万亿次操作)评分,都令笔者非常兴奋。这里不再详细阐述,有需要的读者可以咨询Quadric公司。
最后,笔者想快速概述一下Quadric软件开发工具包(SDK),如下所示。
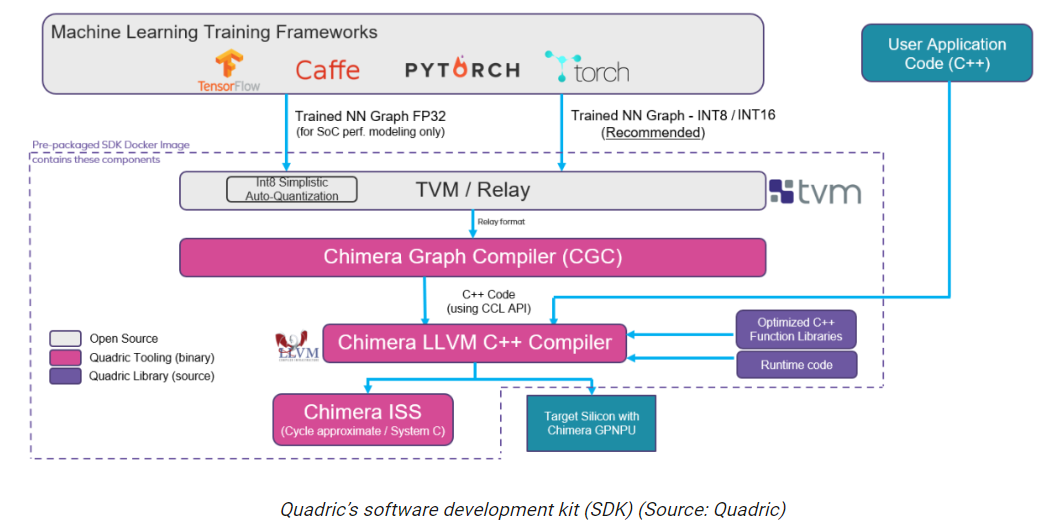
归根结底,一切都是由软件驱动的。使用TensorFlow、PyTorch、Caffe等框架生成的经过训练的神经网络图/模型被送入Apache TVM(一个用于CPU、GPU和ML加速器的开源机器学习编译器框架),生成一个Relay输出(Relay是TVM框架的高级中间表示)。
中继表示的转换和优化由Chimera CGC执行,它将转换和优化后的神经网络输出为C++代码。Chimera LLVM C++ Compiler将这些代码与开发人员的C++应用程序代码合并,所有这些输出为一个可执行文件,运行在目标硅/SoC中的Chimera GPNPU上。
注意,Quadric SDK是作为预打包的Docker映像交付的,用户可以下载并在自己的系统上运行。Quadric很快将把这个SDK托管在Amazon Web Services (AWS)上,从而允许用户通过他们的Web浏览器访问它。
让笔者特别感兴趣的是,Quadric的工作人员正在开发一个图形用户界面(GUI),它可以让开发人员拖放包含CPU/DSP代码和NPU模型的管道构建块,将它们拼接在一起,并将所有内容编译成一个ChimeraGPNPU image。这种无代码开发方法将使大量开发人员能够创建含有Chimera GPNPU的芯片。
审核编辑:刘清
-
展会直击:无人机眼花缭乱,芯片卡位低空经济大爆发2025-05-25 8421
-
别被忽悠了!细看眼花缭乱的液晶显示器参数2011-02-23 2741
-
下一代家用电器的更多想象力2019-07-29 1486
-
机器人盘点,那些最有想象力的机器人,你觉得哪个最实用?2017-06-08 2247
-
AI想象力以及如何推理构建计划2017-09-22 646
-
未来VR到底将为人类创造了一个怎样的世界,都需要我们的想象力2018-02-06 7181
-
紧凑型市场眼花缭乱,思域与卡罗拉哪个更好?2018-07-20 7240
-
眼花缭乱的HDR,中国自主标准能否找到出路?2021-07-01 13508
-
连续四年参展进博会,蔡司携尖端科技挑战想象力的极限2021-10-28 983
-
为下一代家用电器注入更多想象力2022-11-01 811
-
什么是元宇宙 元宇宙的发展现状 开启元宇宙寻找想象力的边界2023-06-30 2826
-
开启元宇宙,寻找想象力的边界2023-07-18 10004
全部0条评论

快来发表一下你的评论吧 !
