

一文解析Zen 4 的核心架构
处理器/DSP
描述
我们在文章《万字详解AMD ZEN 4架构》中深入介绍了 Zen 4 的核心架构。而在本文中,我们将专注于我们没有设法做到的任何事情。其中一些细节可能特定于我们拥有的特定 CPU 样本,其中许多细节不会对应用程序性能产生重大影响。
Boost clock行为
AMD宣传 Ryzen 7950X 的加速时钟为 5.7 GHz。我们听说 CPU 的最大频率应该是 5.85 GHz,但我们无法达到该时钟速度。在这里,我们将展示测试数据并讨论 7950X 设计的其他方面。请记住,此处看到的行为可能是特定于样本的。
首先,我们一一检查了 7950X 的所有内核,并确定了它们提升到的时钟速度。为了测量时钟速度,我们测量了寄存器到寄存器整数加法指令的延迟。与之前的 16 核 AMD 台式机部件一样,并非所有内核都会提升到 CPU 的最大时钟。在我们的 7950X 样本上,我们看到内核 0、3 和 4 的最高时钟频率。所有这三个内核都位于第一个 CCD 上。
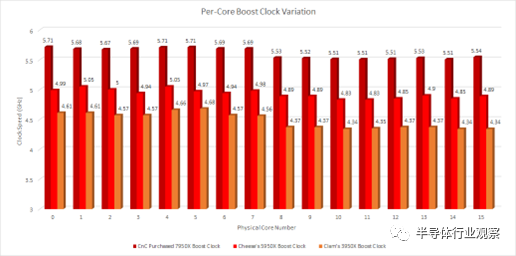
注意——没有从 0 开始轴以使时钟速度差异更明显。
第二个 CCD 上的所有内核的时钟频率都低于第一个 CCD 上的内核。它们的范围从 5.54 GHz 到 5.51 GHz,比我们在第一个 CCD 上看到的低 100-200 MHz。奇怪的是,前几代人表现出完全相同的模式。
Cheese 的 5950X 在核心 1 和 4 上达到了最高时钟。两者都位于第一个 CCD 上。我的 3950X 在核心 4 和 5 上的时钟频率最高。两者也在第一个 CCD 上。这是一个奇怪的模式。也许 AMD 只是binning一个 CCD 以达到 16 个核心部件的最大升压时钟。
我们的 Zen 4 和 Zen 3 芯片的时钟速度变化也小于我们的 Zen 2 芯片。

如果您的操作系统的调度程序没有优先安排最佳内核上的低线程任务,则 3950X 的性能可能会出现相当大的变化。Ryzen 5950X 和 7950X 在这方面要好得多。虽然时钟速度差异是可以测量的,但感受 3-4% 的性能差异要比感受 7-8% 的性能差异要困难得多。
持续时间短的Boost行为
我还想知道 Zen 4 是否会暂时达到更高的时钟速度,然后在之前测试的测量间隔内回落。该测试通常需要几秒钟来确定时钟速度,以便为任何测试的 CPU 提供合理的时间来斜坡时钟。为了查看时钟是否以非常精细的粒度变化,我使用了时钟斜坡测试,每个样本有更多的迭代。该测试使用 RDTSC 以优于毫秒的精度采集样本。增加每个样本的迭代次数可以让测试覆盖更长的持续时间以捕获快速的时钟速度变化,但不会创建一个巨大的厄运电子表格。我还在每个核心上运行了测试。结果在同一个核心上是一致的,但在不同核心上却不一致。
让我们一次处理一个 CCD,因为有很多数据。根据内核的不同,我们在 700 毫秒的时间窗口内看到了略高于 5.71 GHz 的时钟。然而,结果千差万别。一些内核,如内核 0 和 2,在不到 50 毫秒的时间内提升至 5.74 GHz,然后降至 5.71 GHz。Core 2 保持 5.74 GHz 将近半秒,然后表现出不稳定的行为。
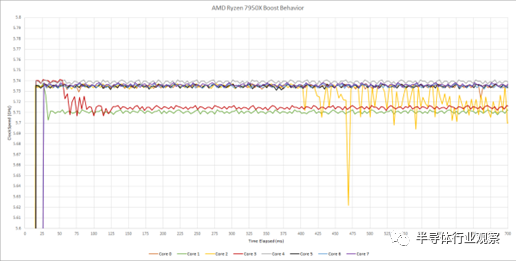
测试还使用整数加法延迟来测量时钟速度。
第二个 CCD 显示出相似的特征。然而,该 CCD 上的核心实际上开始接近 5.6 GHz。他们在很短的时间间隔内保持该速度,然后稍微降低速度。
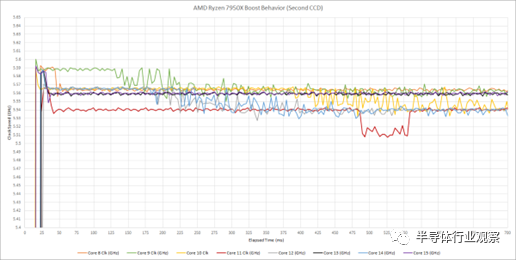
这是一个有趣的行为,尽管与大多数用户无关。短期和长期升压时钟的差异很少超过 50 MHz。如果您回到过去并运行 266 MHz Pentium II,那么 50 MHz 就很重要了。今天,50 MHz 的差异小得可笑。在 Zen 4 运行的时钟速度下,50 MHz 仅占不到 1% 的差异。该测试的最大收获是 Zen 4 在非常小的时间片内调整时钟速度,用户不应期望时钟速度非常稳定。
Not So Infinite Fabric?
与 Zen 2 和 Zen 3 一样,每个 Zen 4 核心复合体都有一个 32B/cycle
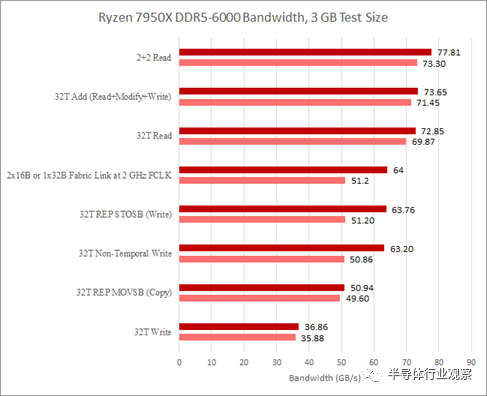
的结构读取链接和一个 16B/cycle的写入链接。在上一篇文章中,我们注意到 DDR5-6000 的写入带宽可能受到来自两个 CCD 的 16B/周期链接的限制。我们从一个 CCD 看到了类似的读取带宽限制。我们使用 3 GB 测试大小和缩放线程数运行内存带宽测试以命中所有物理内核。CCX 和 CCD 一个接一个地装满。在 3950X 上,这意味着首先在 CCD 上填充两个 CCX。从结果中,我们可以清楚地看到单个 7950X CCD 受到其与结构的 32B/cycle链接的限制。
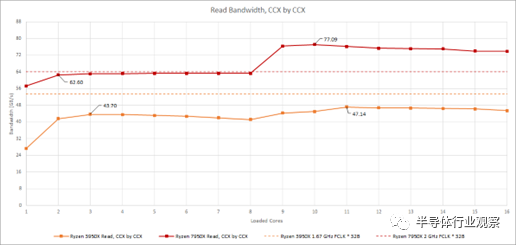
在 Zen 2 和 Zen 3 上,Infinity Fabric 互连通常可以在 DDR 时钟或 DDR 传输速率的一半下运行。因此,单个 CCD 可用的结构带宽不是问题。在匹配的时钟下,单个 32 字节/周期或 256 位链路提供与 16 字节/周期或 128 位 DDR 设置相同的理论带宽。当第二个 CCD 激活时,Zen 2 确实看到测得的内存带宽略有增加,但差异非常小。对于 Zen 4,这提出了一个有趣的问题,即快速 DDR5 是否值得用于具有单个 CCD 的设计。技嘉黑客泄露的 Genoa(Zen 4 服务器变体)处理器编程参考手册建议每个 CCD 可以有两个结构链接。根据它们的配置方式,将快速 DDR5 与单个 CCD 部件配对可能不值得,尤其是当主要目标是提高内存带宽受限应用程序的性能时。
在 Ryzen 3950X 上,每个 CCD 的较窄写入链路意味着单个 CCD 写入带宽限制可能会在人为测试下出现。但是,在写入时,两个 CCD 加在一起几乎可以使 DDR4 设置饱和。正如我们 Zen 4 报道的第 2 部分所述,7950X 的写入带宽似乎受到从 CCD 到 Infinity Fabric 互连的 16 字节/周期链接的限制。如果我们用非时间写入重复上面的测试,我们可以清楚地看到当单个 CCD 处于活动状态时类似的带宽限制。
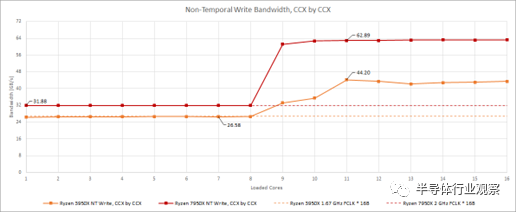
奇怪的是,这两个测试以及两个被测试的 CPU 都表明我们可以通过不加载所有内核来实现更高的带宽。
更少的线程,更多的带宽?
当我们测试内存带宽时,每个线程都有自己的数组,所有线程的总数据加起来就是测试大小。该策略可防止内存控制器机会性地组合来自不同线程的访问。然后,我们生成与硬件线程一样多的软件线程。带宽如何随着线程数的增加而扩展是一个有趣的话题,但我并不总是有时间和精力来解决这个问题。正如您在上面看到的,这个案例非常值得一试。

以 2000 MHz FCLK 运行。内存带宽兔子洞有多深?
通过进一步测试,我获得了最高的内存带宽和四个线程,固定到每个 CCD 的两个内核。进一步调查显示 3950X 有类似的行为。我还检查了 CCX 到 Infinity Fabric 请求的性能计数器、内存带宽和 L3 命中率,以确保写入组合或缓存恶作剧没有发挥作用。
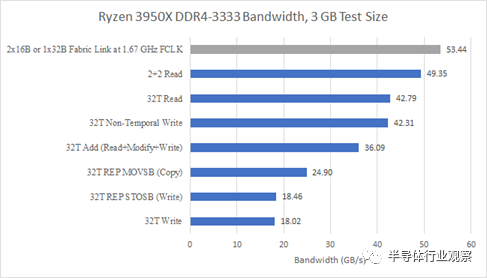
32B/周期结构链路带宽等于可用的 DDR4 带宽
对此行为的一种解释是 32 线程工作负载对内存控制器的要求比 4 线程工作负载更苛刻。如果使访问模式更加分散,那么公开更多的并行性并不是一件好事。内存控制器将更难尝试安排访问以最大化页面命中率,同时又不会停止任何访问足够长的时间以使某些队列备份。
我们还可以根据内存控制器如何有效地利用理论带宽来查看相同的数据。显然,越高越好,即使我们从未期望达到理论带宽。页未命中、读写周转和刷新将导致内存总线周期丢失,并且没有办法避免这种情况。
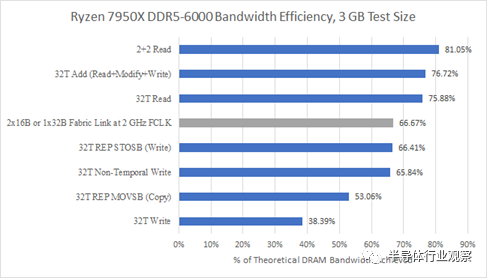
每个 CCD 有两个线程,带宽效率相当不错。81%的理论一点都不差。AMD 较旧的 DDR4 控制器在利用可用带宽方面仍然更好:
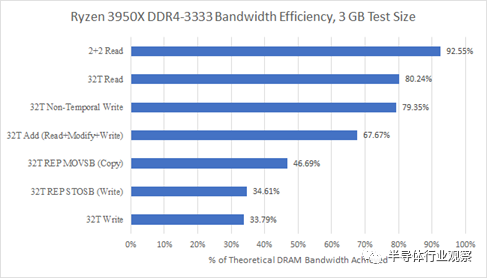
但这并不能说明全部。如果我们看看其他访问模式,Zen 4 在最大可实现带宽之外的领域也取得了进步。Zen 2 不知道如何在 REP STOSB 情况下避免读取所有权访问,但 Zen 4 知道。Zen 4 的 DDR5 控制器还可以更好地处理读取-修改-写入访问模式,这可能表明它在混合读取和写入时受到的损失较小。通过纯 AVX 写入和加载所有线程,Zen 4 还实现了更好的带宽效率。从绝对意义上讲,Zen 4 的 DDR5 控制器还提供比旧款 DDR4 控制器高得多的带宽。
FCLK效应?
我们还使用较低的 1.6 GHz Infinity Fabric 时钟或 FCLK 进行了测试。结果进一步证明写入带宽受 Infinity Fabric 带宽限制。具体来说,我们看到写入带宽急剧减少。如果我们受到每周期两个 16 字节 CCD 到 IO 芯片链接的限制,这种减少与我们期望看到的带宽损失非常吻合。
读取带宽显然不受 Infinity Fabric 带宽的限制。我们在 FCLK 的每个周期远远超过 32 个字节。此外,带宽的下降并不对应于 FCLK 的下降。具体来说,20% 的 FCLK 降低只会使最大读取带宽降低 5.8%。然而,有趣的是,我们在较低的 FCLK 下读取带宽出现了可测量的下降。
集成显卡
AMD 的桌面 Zen 4 平台 Raphael 是最近内存中第一个集成 GPU 的高性能 AMD 平台。在前几代产品中,AMD 的产品线是分裂的。桌面芯片提供了最高性能的 CPU 配置,比移动芯片具有更多的缓存、更多的内核和更高的时钟。另一方面,“APU”提供了一个相对强大的集成 GPU,能够进行轻度游戏。他们还继续使用单片芯片来节省电力,即使他们的台式机同行转而使用小芯片设置以以合理的成本提供更多的核心数。
但是 Zen 4 的 IO die 转向了 TSMC 6 nm 工艺,与之前 IO die 使用的 GlobalFoundries 12nm 工艺相比,它提供了很大的密度提升。IO 接口通常不能随着工艺节点的缩小而很好地扩展,但以前的 IO die的芯片照片显示,IO 控制器逻辑和支持 SRAM 占用了大量区域。这些块可能确实可以通过缩小芯片来很好地扩展,从而为 AMD 提供添加小型 iGPU 的空间。
Raphael 的集成 GPU 没有 AMD APU 的性能雄心,并且似乎打算在没有可用的专用 GPU 时驱动显示器。它采用 AMD 的现代 RDNA2 图形架构,但仅使用一个 WGP 以尽可能小的配置实现它。由于我们一直在谈论内存和结构带宽,让我们从带宽测试开始。毕竟,Raphael iGPU 确实为我们提供了一种额外的方式来使用 DDR5 控制器。
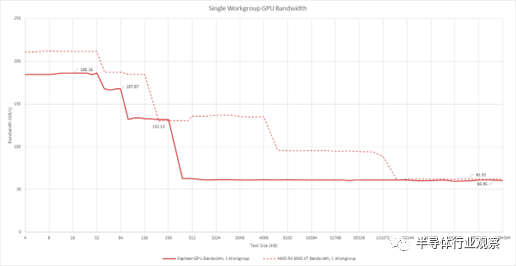
不幸的是,测试带宽并没有告诉我们任何可能的结构限制。我们从 DRAM 大小的区域获得超过 60 GB/s 的速度。来自另一个 RDNA2 实施的数据表明,无论如何,单个 WGP 不能从 DRAM 中提取超过 60 GB/s 的数据。如果 iGPU 具有 32 字节/周期的结构链接,则 2 GHz 结构时钟将提供 64 GB/s 的带宽。这足以养活一个 WGP。
带宽测试还表明我们正在处理非常小的缓存配置。之前,我们查看了几款 iGPU,注意到 AMD Renoir 的 iGPU 使用相对较大的 1 MB L2 缓存,以补偿与 CPU 共享带宽相对较低的 DDR4 总线。Raphael 的 iGPU 甚至没有与低端显卡竞争的愿望,L2 大小降至 256 KB。有趣的是,AMD 还将 L1 缓存大小降至 64 KB。到目前为止,我们看到的所有 RDNA(2) 实现都使用了 128 KB L1 缓存。但看起来 RDNA2 的 L1 可以配置为该大小的一半。与离散的 RDNA2 GPU 不同,Raphael 的 iGPU 没有 Infinity Cache。L2 未命中直接进入内存。
我们可以通过延迟测试来确认缓存设置细节。最近,我们发现我们的简单延迟测试实现正在影响 AMD 在 GCN 和 RDNA GPU 上的标量数据路径。查看编译后的程序集表明生成了 s_load_dword 指令,因为编译器意识到加载的值在波前是统一的。
s_load_dword 访问标量缓存而不是向量缓存,并且这些缓存在 GCN 和 RDNA 上是分开的。应用 hack 来阻止编译器确定加载的值是否统一会导致 global_load_dword 指令和更高的测量延迟。在最近的 Nvidia 和 Intel 架构上,这种 hack 没有效果,因为即使整个 wavefront 或 warp 正在加载相同的值,也会使用相同的缓存。这使 GPU 基准测试变得复杂,因为展望未来,我们必须为现代 AMD GPU 提供两组延迟结果。让我们从标量端的延迟开始。
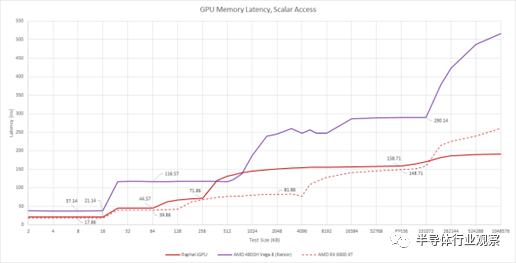
我们看到确认 Raphael 的 iGPU 有一个 64 KB L1,由一个 256 KB L2 支持。它的时钟似乎略低于桌面 RDNA2,导致更高的 L1 标量和共享 L1 延迟。然而,Raphael 的微型 L2 比 6900 XT 的延迟更好。与其桌面对应物一样,Raphael 的 iGPU 享有比Renoir 使用的旧 GCN 架构更低的标量加载延迟。然而,Renoir 有一个更大的 L2 缓存,以帮助 iGPU 免受内存带宽瓶颈的影响。
Raphael 的 iGPU 也享有比Renoir 更好的 DRAM 访问延迟。此处测试的 Ryzen 4800H 确实存在更高的内存延迟,在 1 GB 测试大小下达到 84.7 ns,而 7950X 为 73.35 ns。然而,这个相对较小的差距并不能解释 GPU 端 DRAM 延迟的巨大差异。超过 L2 容量后延迟的跳跃表明测试正在溢出 GCN 的 TLB 级别。在 128 MB 之后,我们可能会看到完全 TLB misses。
Raphael 的 iGPU 上的 DRAM 访问延迟也与桌面 RDNA2 的访问延迟相当。Desktop RDNA2 的 DRAM 访问延迟超过 250 ns,而 Raphael 的 iGPU 可以在 191 ns 多一点的时间内访问 DRAM。该优势可能是因为 iGPU 非常小,这意味着它在通往 DRAM 的途中不必经过非常复杂的互连和大型缓存。iGPU 也位于 IO 裸片上,IO 裸片也有内存控制器。
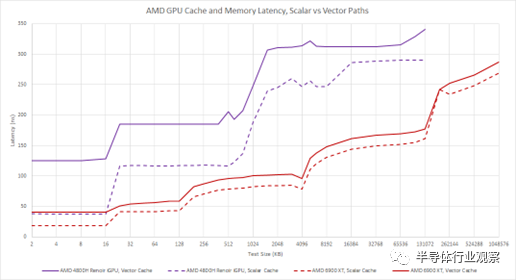
当我们使用矢量加载路径时,AMD 会遭受很多额外的延迟。AMD 可能在优化标量高速缓存的延迟方面付出了很多努力,并期望延迟敏感的操作发生在那里。矢量路径针对带宽而非延迟进行了更多优化,并且延迟惩罚在 GCN 上尤为明显。RDNA2 是一个显着的改进。不幸的是,我们没有在 Raphael 上测试向量缓存延迟,但这里可以预览 GCN 和 RDNA2 之间的区别:
虽然 iGPU 通常比它们的独立表亲更小并且可以访问更少的内存带宽,但它们确实享受与主机 CPU 更快的通信。在某些情况下,通过将相同的物理内存映射到 CPU 和 GPU 的页表,数据可以在 CPU 和 GPU 之间移动而无需实际复制。在这里,我们正在测试如果需要复制会发生什么。
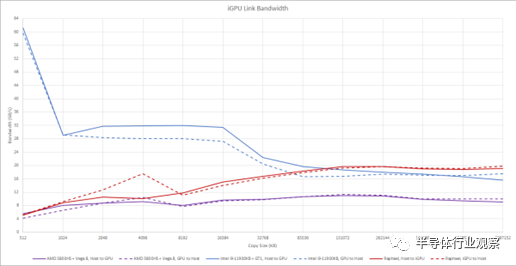
英特尔在 CPU 和 GPU 之间共享一个 L3 缓存,允许在 GPU 和主机之间进行非常快速的复制。AMD 没有这个,但 AMD iGPU 仍然受益于共享 DDR 总线。DDR4 或 DDR5 可能无法提供 GDDR 设置的带宽,但通过 DDR 总线复制数据仍然比通过 PCIe 更快。在英特尔的 L3 缓存无济于事的较大副本大小下,Raphael 更高带宽的 DDR5 设置开始发挥作用,并让 Raphael iGPU 超越 Tiger Lake。
Raphael 的 iGPU 是一个非常有趣的外观,它是一个非常小的 RDNA2 实现。它展示了 RDNA2 如何通过减少 L1 缓存大小来缩小到非常小的设置,同时保留较大 RDNA2 实现的低延迟缓存行为。
编辑:黄飞
-
AMD将推出Zen5架构CPU,效能比Zen4快40%2024-08-08 1921
-
AMD Ryzen Zen 4c架构规格介绍2023-12-25 1643
-
Zen4架构处理器将升级到5nm制程2020-12-22 3174
-
AMD Zen4架构:采用5nm工艺,核心数有望再增加2020-11-11 2541
-
AMD推出Ryzen 5000系列Zen 3架构处理器,可自主适配主板芯片组2020-10-10 2058
-
AMD回顾Zen架构历史,Zen4架构可能会是在2021年推出2020-07-23 6608
-
曝Zen 3架构IPC性能将比Zen 2提升10~15%2020-04-07 4215
-
AMD Zen 3微架构将在CES 2020上发布2020-01-04 5419
-
ARM新锐Cortex_A7核心架构解析2017-09-28 2649
-
AMD谈新一代Zen处理器:更高的IPC,更强超频能力2017-09-07 3799
-
AMD公布Zen架构详情曝光:全新CPU真身是这样的八核心2016-08-24 3367
-
AMD Zen处理器基本架构首度曝光:32核心2016-07-22 2613
全部0条评论

快来发表一下你的评论吧 !
