

多线程的web目录扫描工具
电子说
1.4w人已加入
描述
项目地址
https://github.com/pmiaowu/PmWebDirScan
简介
PmWebDirScan:多线程的web目录扫描工具
免责声明
该工具仅用于安全自查检测由于传播、利用此工具所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任。作者拥有对此工具的修改和解释权。未经网络安全部门及相关部门允许,不得善自使用本工具进行任何攻击活动,不得以任何方式将其用于商业目的。注意
字典使用的御剑的字典+自己平时保存的部分字典而成使用方法
$ python3 PmWebDirScan.py --help
usage: PmWebDirScan.py [-h] [-u URL] [-f SCAN_FILE_URL] [-d DICT] [-o OUTPUT]
[-t THREAD] [--timeout TIMEOUT]
[--http_status_code HTTP_STATUS_CODE]
(QAQ)我是一个可怜兮兮不知道好不好用就给强行写出来用作扫描web目录泄露的无辜扫描器. (T^T)
optional arguments:
-h, --help show this help message and exit
-u URL, --url URL 要扫描的url
-f SCAN_FILE_URL, --scan_file_url SCAN_FILE_URL
载入要扫描的url列表txt文件(每个域名换行-文件保存至domain目录)
-d DICT, --dict DICT 提供扫描的字典位置(多个文件请使用`,`分割)
-o OUTPUT, --output OUTPUT
结果输出位置
-t THREAD, --thread THREAD
运行程序的线程数量
--timeout TIMEOUT 超时时间
--http_status_code HTTP_STATUS_CODE
代表扫描成功的http状态码
使用例子
扫描某个域名下的备份文件
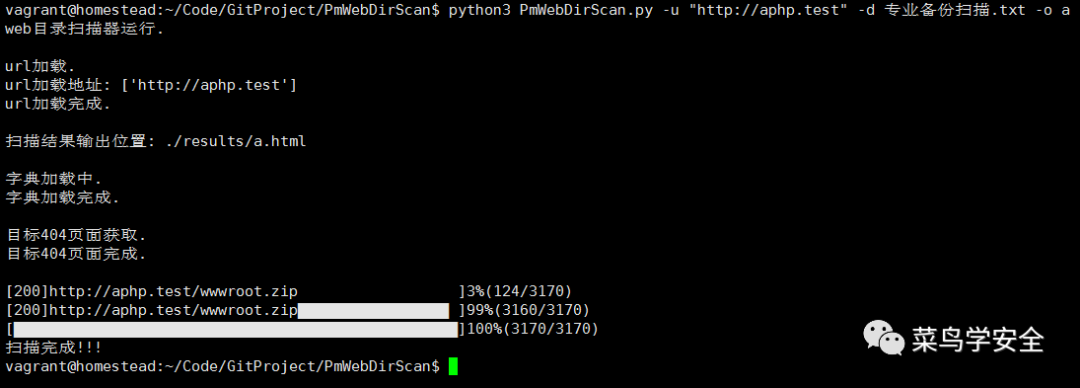
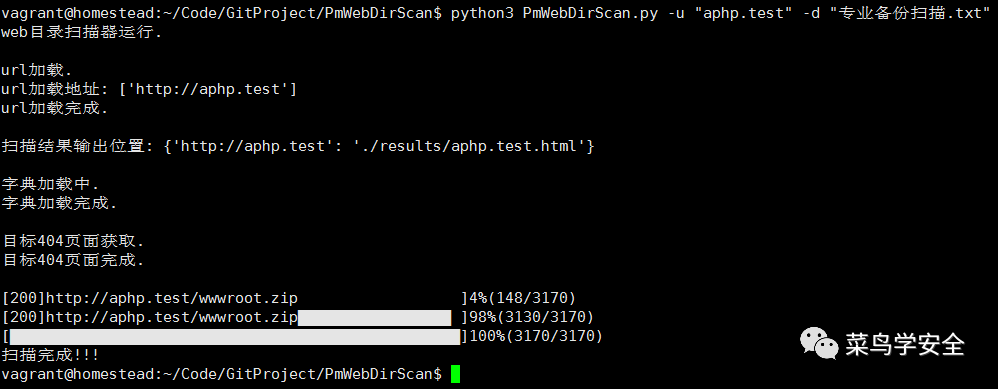
$ python3 PmWebDirScan.py -u "baidu.com" -d 专业备份扫描.txt
批量扫描某些域名的备份文件
$ python3 PmWebDirScan.py -f domain_test.txt -d 专业备份扫描.txt
排量扫描文件请放到domain目录
批量扫描某域名多个字典
$ python3 PmWebDirScan.py -u "baidu.com" -d "专业备份扫描.txt,综合目录.txt"
所有的字典都在dict目录
扫描结果保存
$ python3 PmWebDirScan.py -u "baidu.com" -d "专业备份扫描.txt,综合目录.txt" -o result_test
执行以后扫描结果将保持至./results/result_test.html
修改扫描线程
$ python3 PmWebDirScan.py -u "baidu.com" -t 100
线程默认是50
修改代表扫描成功的http状态码
$ python3 PmWebDirScan.py -u "baidu.com" --http_status_code "200,301,403"
执行以后 所有状态为 200,301,403 的请求都会认为扫描成功
修改程序超时时间
$ python3 PmWebDirScan.py -u baidu.com --timeout 5
修改以后URL发送超过5秒,将认为超时不存在 默认超时时间为2秒
运行例子
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
POC管理和漏洞扫描小工具2024-01-09 2191
-
多线程如何保证数据的同步2023-11-17 2751
-
一个有许多线程的进程,如何才能改变其中一个线程的工作目录?2023-10-17 566
-
Java多线程的用法2023-09-30 2317
-
labview AMC多线程2023-08-21 839
-
Konan:用于Web目录扫描的工具2023-06-14 4738
-
SpringBoot实现多线程2023-01-12 3123
-
Micropython STM32添加多线程功能2021-08-24 1664
-
如何利用基于字节码插桩实现的多线程调试工具2020-07-06 1123
-
多线程好还是单线程好?单线程和多线程的区别 优缺点分析2017-12-08 83618
-
MFC--多线程程序设计2016-09-01 678
全部0条评论

快来发表一下你的评论吧 !
