

为什么在JVM中线程崩溃不会导致JVM进程崩溃呢?
电子说
描述
线程崩溃,进程一定会崩溃吗
一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,各个线程的地址空间是共享的 ,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃
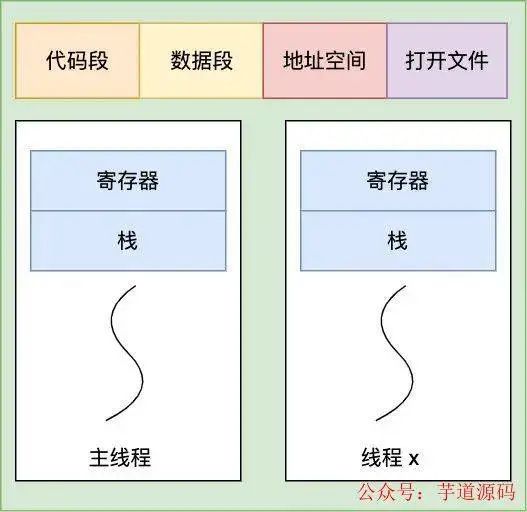
线程共享代码段,数据段,地址空间,文件
非法访问内存有以下几种情况,我们以 C 语言举例来看看
针对只读内存写入数据
#include#include int main() { char *s = "hello world";
// 向只读内存写入数据,崩溃 s[1] = 'H'; }
访问了进程没有权限访问的地址空间(比如内核空间)
#include#include int main() { int *p = (int *)0xC0000fff;
// 针对进程的内核空间写入数据,崩溃 *p = 10; }
在 32 位虚拟地址空间中,p 指向的是内核空间,显然不具有写入权限,所以上述赋值操作会导致崩溃
访问了不存在的内存,比如
#include#include int main() { int *a = NULL; *a = 1; }
以上错误都是访问内存时的错误,所以统一会报 Segment Fault 错误(即段错误),这些都会导致进程崩溃
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
进程是如何崩溃的-信号机制简介
那么线程崩溃后,进程是如何崩溃的呢,这背后的机制到底是怎样的,答案是信号 ,大家想想要干掉一个正在运行的进程是不是经常用 kill -9 pid 这样的命令,这里的 kill 其实就是给指定 pid 发送终止信号的意思,其中的 9 就是信号,其实信号有很多类型的,在 Linux 中可以通过 kill -l查看所有可用的信号
当然了发 kill 信号必须具有一定的权限,否则任意进程都可以通过发信号来终止其他进程,那显然是不合理的,实际上 kill 执行的是系统调用,将控制权转移给了内核(操作系统),由内核来给指定的进程发送信号
那么发个信号进程怎么就崩溃了呢,这背后的原理到底是怎样的?
其背后的机制如下
CPU 执行正常的进程指令
调用 kill 系统调用向进程发送信号
进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出
注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行
// 自定义信号处理函数示例 #include#include #include // 自定义信号处理函数,处理自定义逻辑后再调用 exit 退出 void sigHandler(int sig) { printf("Signal %d catched! ", sig); exit(sig); } int main(void) { signal(SIGSEGV, sigHandler); int *p = (int *)0xC0000fff; *p = 10; // 针对不属于进程的内核空间写入数据,崩溃 } // 以上结果输出: Signal 11 catched!
如代码所示 :注册信号处理函数后,当收到 SIGSEGV 信号后,先执行相关的逻辑再退出
另外当进程接收信号之后也可以不定义自己的信号处理函数,而是选择忽略信号,如下
#include#include #include int main(void) { // 忽略信号 signal(SIGSEGV, SIG_IGN); // 产生一个 SIGSEGV 信号 raise(SIGSEGV); printf("正常结束"); }
也就是说虽然给进程发送了 kill 信号,但如果进程自己定义了信号处理函数或者无视信号就有机会逃出生天,当然了 kill -9 命令例外,不管进程是否定义了信号处理函数,都会马上被干掉
说到这大家是否想起了一道经典面试题:如何让正在运行的 Java 工程的优雅停机,通过上面的介绍大家不难发现,其实是 JVM 自己定义了信号处理函数,这样当发送 kill pid 命令(默认会传 15 也就是 SIGTERM)后,JVM 就可以在信号处理函数中执行一些资源清理之后再调用 exit 退出。这种场景显然不能用 kill -9,不然一下把进程干掉了资源就来不及清除了
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
为什么线程崩溃不会导致 JVM 进程崩溃
现在我们再来看看开头这个问题,相信你多少会心中有数,想想看在 Java 中有哪些是常见的由于非法访问内存而产生的 Exception 或 error 呢,常见的是大家熟悉的 StackoverflowError 或者 NPE(NullPointerException),NPE 我们都了解,属于是访问了不存在的内存
但为什么栈溢出(Stackoverflow)也属于非法访问内存呢,这得简单聊一下进程的虚拟空间,也就是前面提到的共享地址空间
现代操作系统为了保护进程之间不受影响,所以使用了虚拟地址空间来隔离进程,进程的寻址都是针对虚拟地址,每个进程的虚拟空间都是一样的,而线程会共用进程的地址空间,以 32 位虚拟空间,进程的虚拟空间分布如下
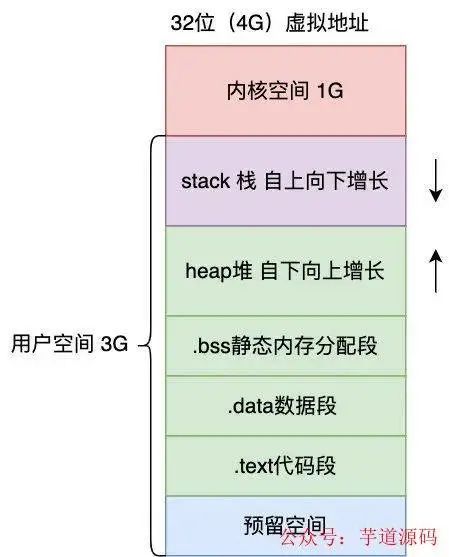
那么 stackoverflow 是怎么发生的呢,进程每调用一个函数,都会分配一个栈桢,然后在栈桢里会分配函数里定义的各种局部变量,假设现在调用了一个无限递归的函数,那就会持续分配栈帧,但 stack 的大小是有限的(Linux 中默认为 8 M,可以通过 ulimit -a 查看),如果无限递归很快栈就会分配完了,此时再调用函数试图分配超出栈的大小内存,就会发生段错误,也就是 stackoverflowError
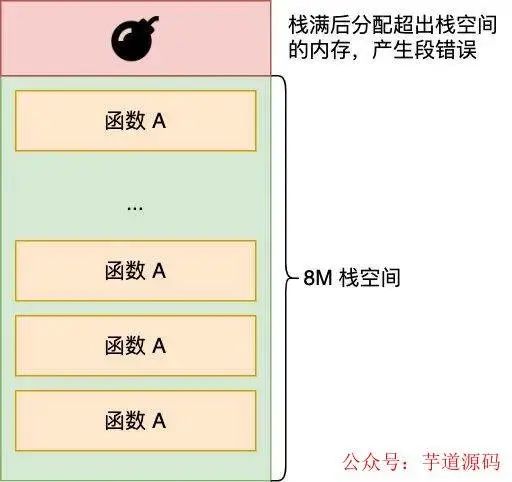
好了,现在我们知道了 StackoverflowError 怎么产生的,那问题来了,既然 StackoverflowError 或者 NPE 都属于非法访问内存, JVM 为什么不会崩溃呢,有了上一节的铺垫,相信你不难回答,其实就是因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃,怎么证明这个推测呢,我们来看下 JVM 的源码来一探究竟
openJDK 源码解析
HotSpot 虚拟机目前使用范围最广的 Java 虚拟机,据 R 大所述, Oracle JDK 与 OpenJDK 里的 JVM 都是 HotSpot VM,从源码层面说,两者基本上是同一个东西,OpenJDK 是开源的,所以我们主要研究下 Java 8 的 OpenJDK 即可,地址如下:https://github.com/AdoptOpenJDK/openjdk-jdk8u,有兴趣的可以下载来看看
我们只要研究 Linux 下的 JVM,为了便于说明,也方便大家查阅,我把其中关于信号处理的关键流程整理了下(忽略其中的次要代码)
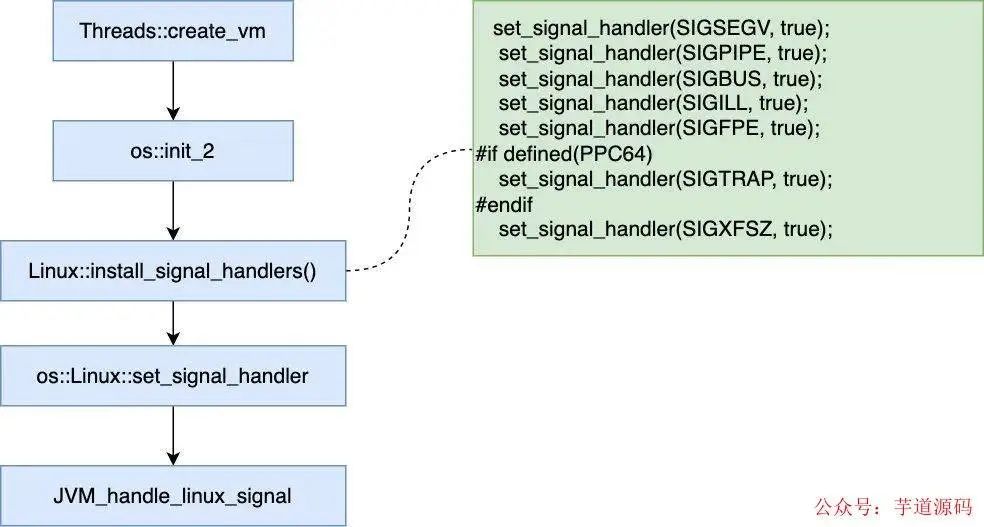
可以看到,在启动 JVM 的时候,也设置了信号处理函数,收到 SIGSEGV,SIGPIPE 等信号后最终会调用 JVM_handle_linux_signal 这个自定义信号处理函数,再来看下这个函数的主要逻辑
JVM_handle_linux_signal(int sig,
siginfo_t* info,
void* ucVoid,
int abort_if_unrecognized) {
// Must do this before SignalHandlerMark, if crash protection installed we will longjmp away
// 这段代码里会调用 siglongjmp,主要做线程恢复之用
os::check_crash_protection(sig, t);
if (info != NULL && uc != NULL && thread != NULL) {
pc = (address) os::ucontext_get_pc(uc);
// Handle ALL stack overflow variations here
if (sig == SIGSEGV) {
// Si_addr may not be valid due to a bug in the linux-ppc64 kernel (see
// comment below). Use get_stack_bang_address instead of si_addr.
address addr = ((NativeInstruction*)pc)->get_stack_bang_address(uc);
// 判断是否栈溢出了
if (addr < thread->stack_base() &&
addr >= thread->stack_base() - thread->stack_size()) {
if (thread->thread_state() == _thread_in_Java) {// 针对栈溢出 JVM 的内部处理
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::STACK_OVERFLOW);
}
}
}
}
if (sig == SIGSEGV &&
!MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr)) {
// 此处会做空指针检查
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
}
// 如果是栈溢出或者空指针最终会返回 true,不会走最后的 report_and_die,所以 JVM 不会退出
if (stub != NULL) {
// save all thread context in case we need to restore it
if (thread != NULL) thread->set_saved_exception_pc(pc);
uc->uc_mcontext.gregs[REG_PC] = (greg_t)stub;
// 返回 true 代表 JVM 进程不会退出
return true;
}
VMError err(t, sig, pc, info, ucVoid);
// 生成 hs_err_pid_xxx.log 文件并退出
err.report_and_die();
ShouldNotReachHere();
return true; // Mute compiler
}
从以上代码(注意看加粗的红线字体部分)我们可以知道以下信息
发生 stackoverflow 还有空指针错误,确实都发送了 SIGSEGV,只是虚拟机不选择退出,而是自己内部作了额外的处理,其实是恢复了线程的执行,并抛出 StackoverflowError 和 NPE,这就是为什么 JVM 不会崩溃且我们能捕获这两个错误/异常的原因
如果针对 SIGSEGV 等信号,在以上的函数中 JVM 没有做额外的处理,那么最终会走到 report_and_die 这个方法,这个方法主要做的事情是生成 hs_err_pid_xxx.log crash 文件(记录了一些堆栈信息或错误),然后退出
至此我相信大家明白了为什么发生了 StackoverflowError 和 NPE 这两个非法访问内存的错误,JVM 却没有崩溃。原因其实就是虚拟机内部定义了信号处理函数,而在信号处理函数中对这两者做了额外的处理以让 JVM 不崩溃,另一方面也可以看出如果 JVM 不对信号做额外的处理,最后会自己退出并产生 crash 文件 hs_err_pid_xxx.log(可以通过 -XX:ErrorFile=/var/log/hs_err.log 这样的方式指定),这个文件记录了虚拟机崩溃的重要原因,所以也可以说,虚拟机是否崩溃只要看它是否会产生此崩溃日志文件
总结
正常情况下,操作系统为了保证系统安全,所以针对非法内存访问会发送一个 SIGSEGV 信号,而操作系统一般会调用默认的信号处理函数(一般会让相关的进程崩溃),但如果进程觉得"罪不致死",那么它也可以选择自定义一个信号处理函数,这样的话它就可以做一些自定义的逻辑,比如记录 crash 信息等有意义的事,回过头来看为什么虚拟机会针对 StackoverflowError 和 NullPointerException 做额外处理让线程恢复呢,针对 stackoverflow 其实它采用了一种栈回溯的方法保证线程可以一直执行下去,而捕获空指针错误主要是这个错误实在太普遍了,为了这一个很常见的错误而让 JVM 崩溃那线上的 JVM 要宕机多少次,所以出于工程健壮性的考虑,与其直接让 JVM 崩溃倒不如让线程起死回生,并且将这两个错误/异常抛给用户来处理。
主线程异常会导致 JVM 退出?

有读者读完前面部分的文章后,问出了上面这个问题。
他认为如果 JVM 中的主线程异常没有被捕获,JVM 还是会崩溃,那么这个说法是否正确呢,我们做个试验看看结果是否是他说的这样
public class Test {
public static void main(String[] args) {
TestThread testThread = new TestThread();
TestThread.start();
Integer p = null;
// 这里会导致空指针异常
if (p.equals(2)) {
System.out.println("hahaha");
}
}
}
class TestThread extends Thread {
@Override
public void run() {
while (true) {
System.out.println("test");
}
}
}
试验很简单,首先启动一个线程,在这个线程里搞一个 while true 不断打印, 然后在主线程中制造一个空指针异常,不捕获,然后看是否会一直打印 test
结果是会不断打印 test,说明主线程崩溃,JVM 并没有崩溃 ,这是怎么回事, JVM 又会在什么情况下完全退出呢?
其实在 Java 中并没有所谓主线程的概念,只是我们习惯把启动的线程作为主线程而已,所有线程其实都是平等的,不管什么线程崩溃都不会影响到其它线程的执行,注意我们这里说的线程崩溃是指由于未 catch 住 JVM 抛出的虚拟机错误(VirtualMachineError)而导致的崩溃,虚拟机错误包括 InternalError,OutOfMemoryError,StackOverflowError,UnknownError 这四大子类
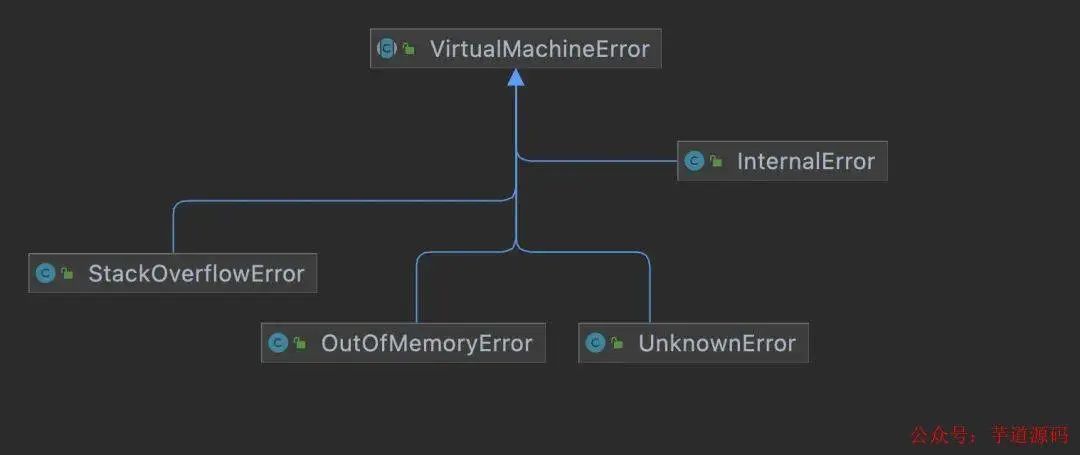
JVM 抛出这些错误其实是一种防止整个进程崩溃的自我防护机制,这些错误其实是 JVM 内部定义了信号处理函数处理后抛出的,JVM 认为这些错误"罪不致死",所以选择恢复线程再给这些线程抛错误(就算线程不 catch 这些错误也不会崩溃)的方式来避免自身崩溃,但如果线程触发了一些其他的非法访问内存的错误,JVM 则会认为这些错误很严重,从而选择退出,比如下面这种非法访问内存的错误就会被认为是致命错误,JVM 就不会向上层抛错误,而会直接选择退出
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
unsafe.putAddress(0, 0);
回过头来看,除了这些致命性错误导致的 JVM 崩溃,还有哪些情况会导致 JVM 退出呢,在 javadoc 上说得很清楚
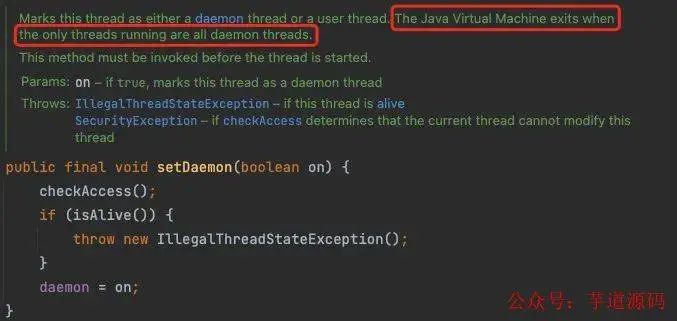
The Java Virtual Machine exits when the only threads running are all daemon threads
也就是说只有在 JVM 的所有线程都是守护线程(daemon thread)的时候才会完全退出,什么是守护线程?守护线程其实是为其他线程服务的线程,比如垃圾回收线程就是典型的守护线程,既然是为其他线程服务的,那么一旦其他线程都不存在了,守护线程也没有存在的意义了,于是 JVM 也就退出了,守护线程通常是 JVM 运行时帮我们创建好的,当然我们也可以自己设置,以开头的代码为例,在创建完 TestThread 后,调用 testThread.setDaemon(true) 方法即可将线程转为守护线程,然后再启动,这样在主线程退出后,JVM 就会退出了,大家可以试试
Java 线程模型简介
我们可以看看 Java 的线程模型,这样大家对 JVM 的线程调度也会有一个更全面的认识,我们可以先从源码角度看看,启动一个 Thread 到底在 JVM 内部发生了什么,启动源码代码在 Thread#start 方法中
public class Thread {
public synchronized void start() {
...
start0();
...
}
private native void start0();
}
可以看到最终会调用 start0 这个 native 方法,我们去下载一下 openJDK(地址:https://github.com/AdoptOpenJDK/openjdk-jdk8u) 来看看这个方法对应的逻辑
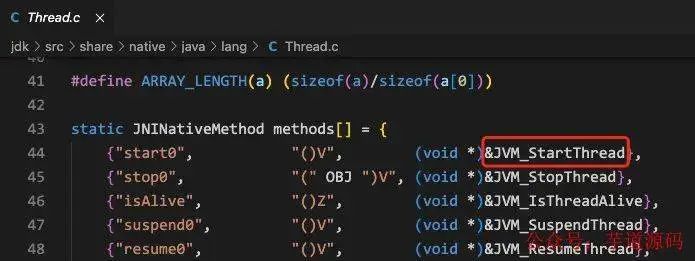
可以看到 start0 对应的是 JVM_startThread 这个方法,我们主要观察在 Linux 下的线程启动情况,一路追踪下去
// jvm.cpp
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
native_thread = new JavaThread(&thread_entry, sz);
// thread.cpp
JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz)
{
os::create_thread(this, thr_type, stack_sz);
}
// os_linux.cpp
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
}
可以看到最终是通过调用 pthread_create 来启动线程的,这个方法是一个 C 函数库实现的创建 native thread 的接口,是一个系统调用,由此可见 pthread_create 最终会创建一个 native thread,这个线程也叫内核线程 ,操作系统只能调度内核线程,于是我们知道了在 Java 中,Java 线程和内核线程是一对一的关系,Java 线程调度实际上是通过操作系统调度实现的,这种一对一的线程也叫 NPTL(Native POSIX Thread Library) 模型,如下
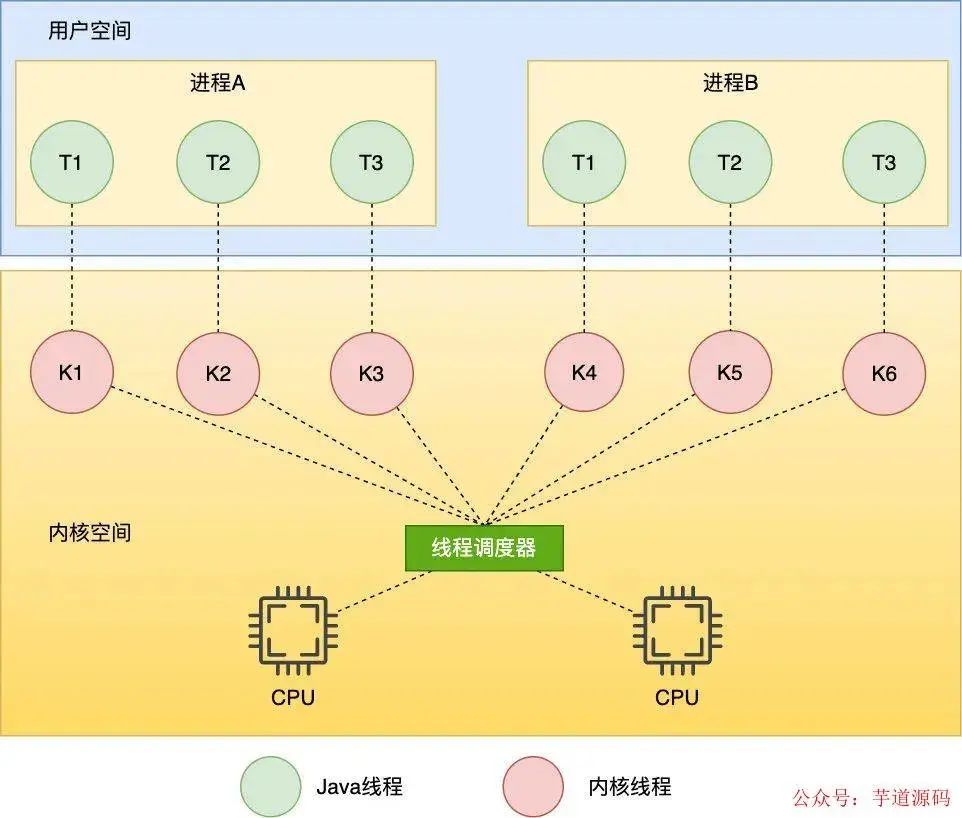
NPTL线程模型
那么这个内核线程在内核中又是怎么表示的呢, 其实在 Linux 中不管是进程还是线程都是通过一个 task_struct 的结构体来表示的, 这个结构体定义了进程需要的虚拟地址,文件描述符,寄存器,信号等资源
早期没有线程的概念,所以每次启动一个进程都需要调用 fork 创建进程,这个 fork 干的事其实就是 copy 父进程对应的 task_struct 的多数字段(pid 等除外),这在性能上显然是无法接受的。于是线程的概念被提出来了,线程除了有自己的栈和寄存器外,其他像虚拟地址,文件描述符等资源都可以共享
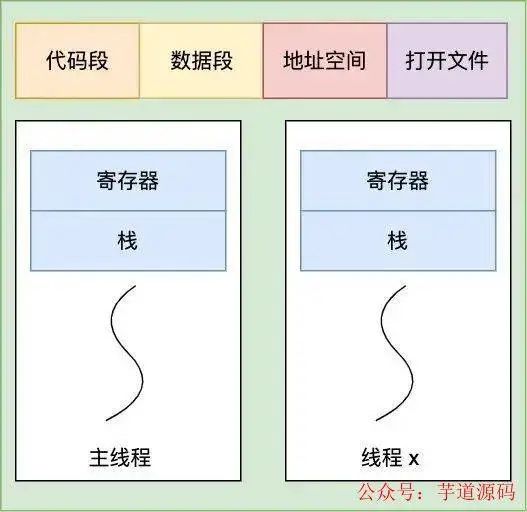
线程共享代码段,数据段,地址空间,文件等资源
于是针对线程,我们就可以指定在创建 task_struct 时,采用共享 而不是复制字段的方式。其实不管是创建进程(fork)还是创建线程(pthread_create)最终都会通过调用 clone() 的形式来创建 task_struct,只不过 pthread_create 在调用 clone 时,指定了如下几个共享参数
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
画外音 :CLONE_VM 共享页表,CLONE_FS 共享文件系统信息,CLONE_FILES 共享文件句柄,CLONE_SIGHAND 共享信号
通过共享而不是复制资源的形式极大地加快了线程的创建,另外线程的调度开销也会更小,比如在(同一进程内)线程间切换的时候由于共享了虚拟地址空间,TLB 不会被刷新从而导致内存访问低效的问题
提到这相信你已经明白了教科书上的一句话:进程是资源分配的最小单元,而线程是程序执行和调度的最小单位。在 Linux 中进程分配资源后,线程通过共享资源的方式来被调度得以提升线程的执行效率
由此可见,在 Linux 中所有的进程/线程都是用的 task_struct,它们之间其实是平等的 ,那怎么表示这些线程属于同一个进程的概念呢,毕竟线程之间也是要通信的,一组线程以及它们所共同引用的一组资源就是一个进程。, 它们还必须被视为一个整体。
task_struct 中引入了线程组的概念,如果线程都是由同一个进程(即我们说的主线程)产生的, 那么它们的 tgid(线程组id) 是一样的,如果是主线程,则 pid = tgid,如果是主线程创建的线程,则这些线程的 tgid 会与主线程的 tgid 一致,
那么在 LInux 中进程,进程内的线程之间是如何通信或者管理的呢,其实 NPTL 是一种实现了 POSIX Thread 的标准 ,所以我们只需要看 POSIX Thread 的标准即可,以下列出了 POSIX Thread 的主要标准:
查看进程列表的时候, 相关的一组 task_struct 应当被展现为列表中的一个节点(即进程内如果有多个线程,展示进程列表 ps -ef 时只会展示主线程,如果要查看线程的话可以用 ps -T)
发送给这个进程的信号(对应 kill 系统调用), 将被对应的这一组 task_struct 所共享, 并且被其中的任意一个”线程”处理
发送给某个线程的信号(对应 pthread_kill), 将只被对应的一个 task_struct 接收, 并且由它自己来处理
当进程被停止或继续时(对应 SIGSTOP/SIGCONT 信号), 对应的这一组 task_struct 状态将改变
当进程收到一个致命信号(比如由于段错误收到 SIGSEGV 信号), 对应的这一组 task_struct 将全部退出
画外音 : POSIX 即可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),是一种接口规范,如果系统都遵循这个标准,可以做到源码级的迁移,这就类似 Java 中的针对接口编程
这样就能很好地满足进程退出线程也退出,或者线程间通信等要求了
NPTL 模型的缺点
NPTL 是一种非常高效的模型,研究表明 NPTL 能够成功地在 IA-32 平台上在两秒内生成 100,000 个线程,而 2.6 之前未采用 NPTL 的内核则需耗费 15 分钟左右,看起来 NPTL 确实很好地满足了我们的需求,但针对内核线程来调度其实还是有以下问题
不管是进程还是线程,每次阻塞、切换都需要陷入系统调用(system call),系统调用开销其实挺大的,包括上下文切换(寄存器切换),特权模式切换等,而且还得先让 CPU 跑操作系统的调度程序,然后再由调度程序决定该跑哪一个进程(线程)
不管是进程还是线程,都属于抢占式调度(高优先级线进程优先被调度),由于抢占式调度执行顺序无法确定的特点,使用线程时需要非常小心地处理同步问题
线程虽然更轻量级,但这只是相对于进程而言,实际上使用线程所消耗的资源依然很大,比如在 linux 上,一个线程默认的栈大小是1M,创建几万个线程就吃不消了
协程
NPTL 模型其实已经足够优秀了,上述问题本质上其实还是因为线程还是太“重”所致,那能否再在线程上抽出一个更轻量级的执行单元(可被 CPU 调度和分派的基本单位)呢,答案是肯定的,在线程之上我们可以再抽象出一个协程(coroutine)的概念,就像进程是由线程来调度的,同样线程也可以细化成一个个的协程来调度
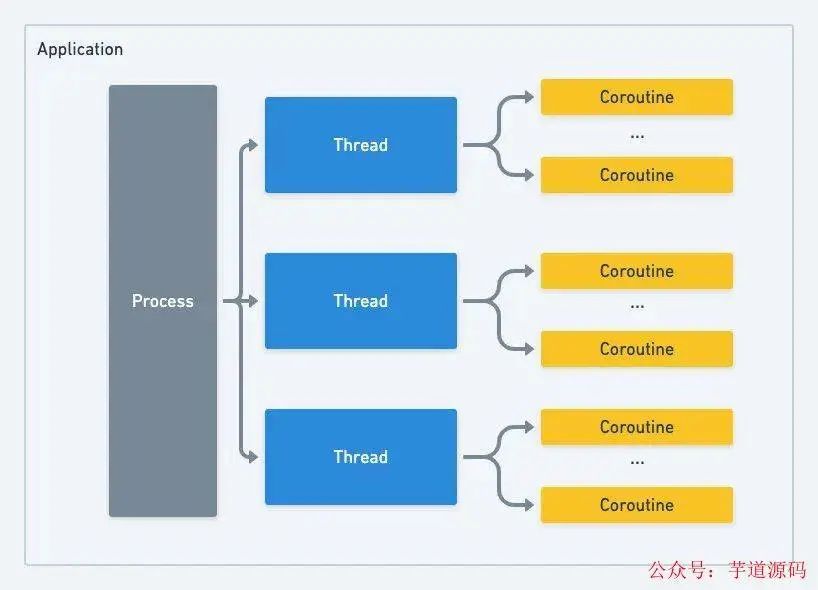
针对以上问题,协程都做了非常好的处理
协程的调度处于用户态,也就没有了系统调用这些开销
协程不属于抢占式调度,而是协作式调度,如何调度,在什么时间让出执行权给其它协程是由用户自己决定的,这样的话同步的问题也基本不存在,可以认为协程是无锁的,所以性能很高
我们可以认为线程的执行是由一个个协程组成的,协程是更轻量的存在,内存使用大约只有线程的十分之一甚至是几十分之一,它是使用栈内存按需使用的,所以创建百万级的协程是非常轻松的事
协程是怎么做到上述这些的呢
协程(coroutine)可以分为两个角度来看,一个是 routine 即执行单元,一个是 co 即 cooperative 协作,也就是说线程可以依次顺序执行各个协程,但协程与线程不同之处在于,如果某个协程(假设为 A)内碰到了 IO 等阻塞事件,可以主动让出自己的调度权,即挂起(suspend),转而执行其他协程,等 IO 事件准备好了,再来调度协程 A
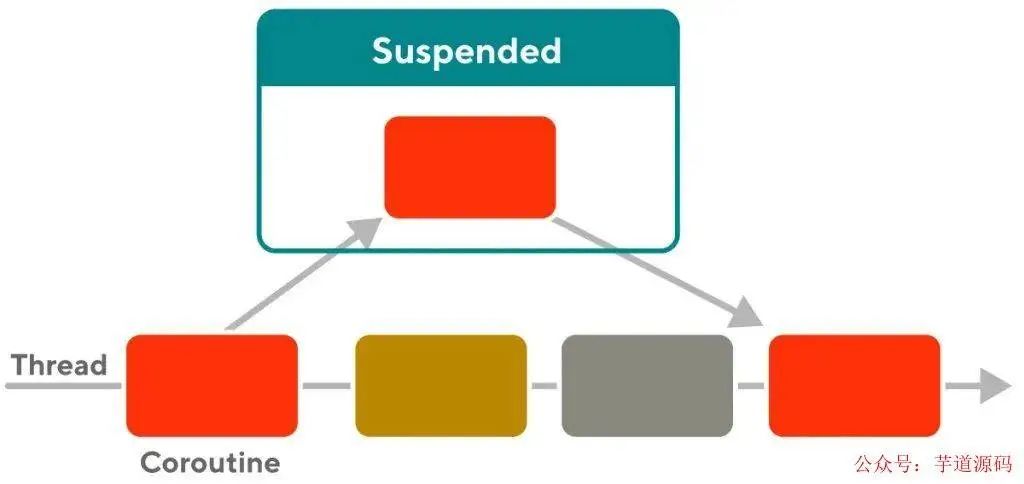
这就好比我在看电视的时候碰到广告,那我可以先去倒杯水,等广告播完了再回来继续看电视。而如果是函数,那你必须看完广告再去倒水,显然协程的效率更高。那么协程之间是怎么协作的呢,我们可以在两个协程之间碰到 IO 等阻塞事件时随时将自己挂起(yield),然后唤醒(resume)对方以让对方执行,想象一下如果协程中有挺多 IO 等阻塞事件时,那这种协作调度是非常方便的
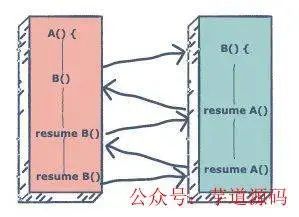 两个协程之间的“协作”
两个协程之间的“协作”
不像函数必须执行完才能返回,协程可以在执行流中的任意位置 由用户决定挂起和唤醒,无疑协程是更方便的
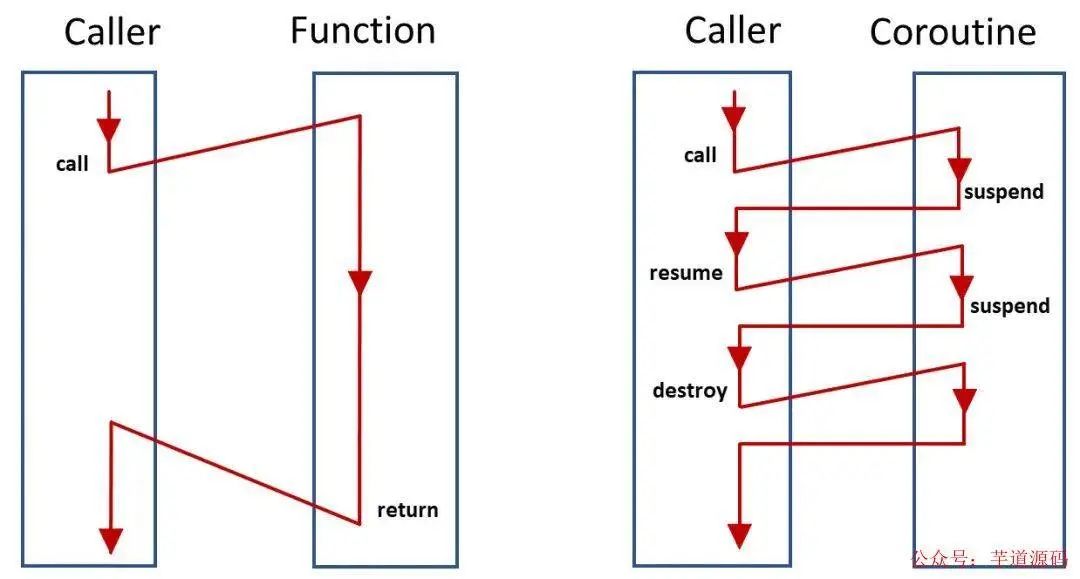
函数与协程的区别
更重要的一点是不像线程的挂起和唤醒等调度必须通过系统调用来让内核调度器来调度,协程的挂起和唤醒完全是由用户决定的 ,而且这个调度是在用户态,几乎没有开销!
前面我们一直提到一般我们在协程中碰到 IO 等阻塞事件时才会挂起并唤醒其他协程,所以可知协程非常适合 IO 密集型的应用 ,如果是计算密集型其实用线程反而更加合适
为什么 Go 语言这么最近这么火,一个很重要的原因就是因为因为它天生支持协程,可以轻而易举地创建成千上万个协程,而如果是创建线程的话,创建几百个估计就够呛了,不过比较遗憾的是 Java 原生并不支持协程,只能通过一些第三方库如 Quasar 来实现,2018 年 OpenJDK 官方创建了一个 loom 项目来推进协程的官方支持工作
总结
从进程,到线程再到协程,可知我们一直在想办法让执行单元变得更轻量级,一开始只有进程的概念,但是进程的创建在 Linux 下需要调用 fork 全部复制一遍资源,虽然后来引入了写时复制的概念,但进程的创建开销依然很大,于是提出了更轻量级的线程,在 Linux 中线程与进程其实都是用 task_struct 表示的,只是线程采用了共享资源的方式来创建,极大了提升了 task_struct 的创建与调度效率,但人们发现,线程的阻塞,唤醒都要通过系统调用陷入内核态才能被调度程度调度,如果线程频繁切换,开销无疑是很大的,于是人们提出了协程的概念,协程是根据栈内存按需求分配的,所需开销是线程的几十分之一,非常的轻量,而且调度是在用户态,并且它是协作式调度,可以很方便的挂起恢复其他协程的执行,在此期间,线程是不会被挂起的,所以无论是创建还是调度开销都很小,目前 Java 官方还不支持,不过支持协程应该是大势所趋,未来我们可以期待一下。
审核编辑:刘清
-
eclipse设置jvm内存大小2023-12-06 3407
-
jvm的dump太大了怎么分析2023-12-05 4277
-
OOM会导致JVM虚拟机退出吗2023-09-30 1572
-
看看基于JDK中自带JVM工具的用法2022-11-16 1435
-
如何解决JVM解释器导致应用崩溃的bug2021-08-27 3391
-
如何解决JVM中一个极小概率发生的bug2021-08-23 4388
-
Jvm的整体结构和特点2021-01-05 2038
-
Jvm工作原理学习笔记2018-04-03 926
全部0条评论

快来发表一下你的评论吧 !
