

使用VS2022对GPU进行CUDA编程
描述
在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),两者优势互补。
CUDA作为GPU的编程模型,提供了对其他编程语言的支持,例如常用的C/C++,Python等。
下面在windows系统下,使用VS2022对GPU进行CUDA编程。
开始之前你需要准备的硬件是:一块GPU显卡。并假设你已经提前安装了VS2022,而且具备一定的软件编程经验。
安装CUDA
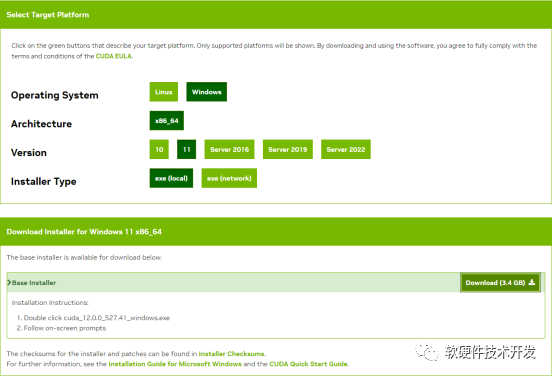
首先进行CUDA编程模型的安装,根据自己的系统情况到CUDA官网下载安装包。下载完成后进行安装,过程很简单。
安装完成后,“win+R”输入cmd打开终端后输入:nvcc -V,检验安装是否成功。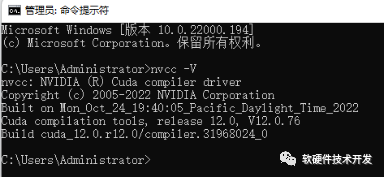
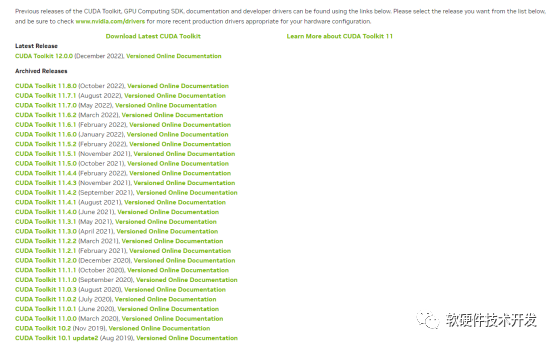
若需要下载以前的版本,你还可以点击查看你需要下载的CUDA版本: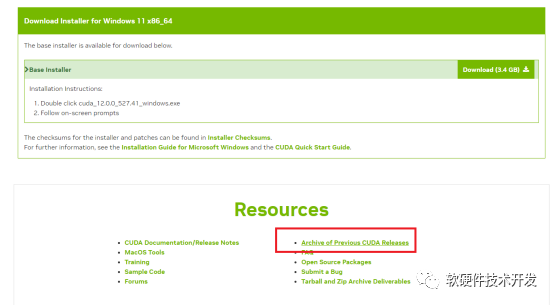
创建VS2022项目
CUDA安装完成后,打开VS2022创建新项目,选择CUDA runtime。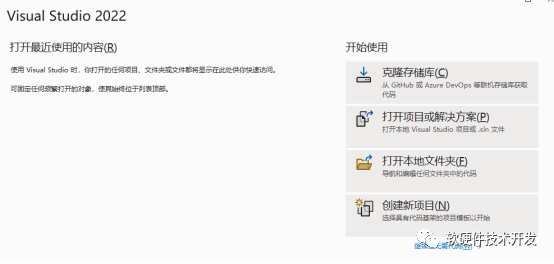
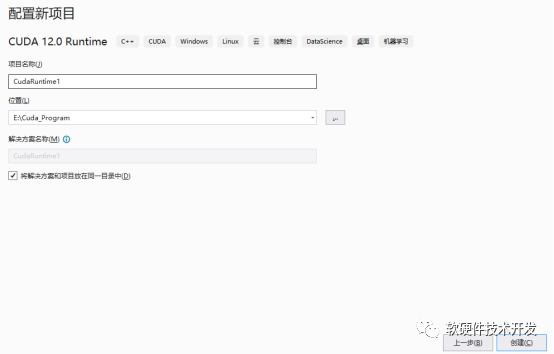
新建完成后有一个简单的例程,直接进行调试即可看到下面的结果:
在CUDA中,用host指代CPU及其内存,用device指代GPU及其内存。
CUDA程序既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。
同时,host与device之间可以进行数据拷贝。
在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数,不能成为类成员函数。
注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
__device__:在device上执行,仅可以从device中调用,不可以和__global__同时用。
__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。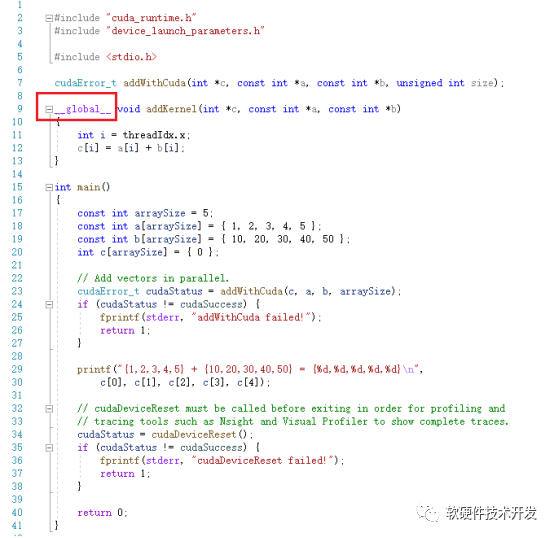

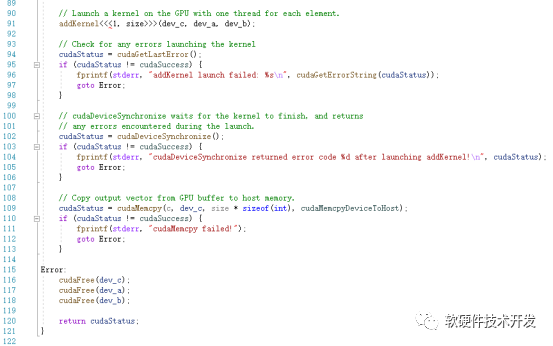
该例程虽然简单,也反映了典型的CUDA程序流程:
分配host内存,并进行数据初始化;
分配device内存,并从host将数据拷贝到device上;
在device上调用CUDA的核函数(kernel)完成进行并行计算;
将device上的运算结果拷贝到host上;
释放device和host上分配的内存。
其中,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<
审核编辑:刘清
-
在K520上能使用两个GPU进行CUDA作业吗2018-09-26 3202
-
CUDA编程教程2019-03-05 6000
-
linux安装GPU显卡驱动、CUDA和cuDNN库2019-07-09 3790
-
GPU加速的L0范数图像平滑(L0 Smooth)【CUDA】2020-07-08 3052
-
计算机组成原理 — GPU 图形处理器 精选资料分享2021-07-23 1822
-
VS2022破解vMicro2022-01-10 3566
-
GPU高性能运算之CUDA2010-08-16 885
-
CUDA学习笔记第一篇:一个基本的CUDA C程序2020-12-14 2055
-
CUDA简介: CUDA编程模型概述2022-04-20 4370
-
国产GPU绕不开的CUDA生态2022-11-29 6159
-
使用CUDA进行编程的要求有哪些2023-01-08 3694
-
GPU平台生态,英伟达CUDA和AMD ROCm对比分析2023-05-18 4203
-
介绍CUDA编程模型及CUDA线程体系2023-05-19 3400
-
在Python中借助NVIDIA CUDA Tile简化GPU编程2025-12-13 1729
-
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程2026-02-10 834
全部0条评论

快来发表一下你的评论吧 !
