

一文速览人岗匹配领域研究进展
描述
本文主要从文本匹配、历史行为偏好建模以及混合推荐三个角度介绍了当前人岗匹配中的主要模型与方法。
引言:随着互联网产业快速发展,网络招聘已经成为一种普遍的求职服务并从中衍生出了人岗匹配(Person-Job Fit,PJF)任务。与传统仅需关注用户兴趣偏好的商品或电影推荐不同,PJF这种双边场景下的推荐双方都存在主动行为及自身偏好,如求职者有自身的目标职位,工作职位也有对求职者的能力要求。正因这种双边建模需求,PJF涌现出了各种各样与传统推荐不同的模型与方法,其中,求职者简历与职位描述之间的文本匹配和从双方历史交互行为提取偏好信息成为了大家关注的重点。本文将主要从文本匹配、历史行为偏好建模以及混合推荐方法三个角度向大家介绍当前PJF中的主要模型与方法。欢迎大家批评指正,相互交流。
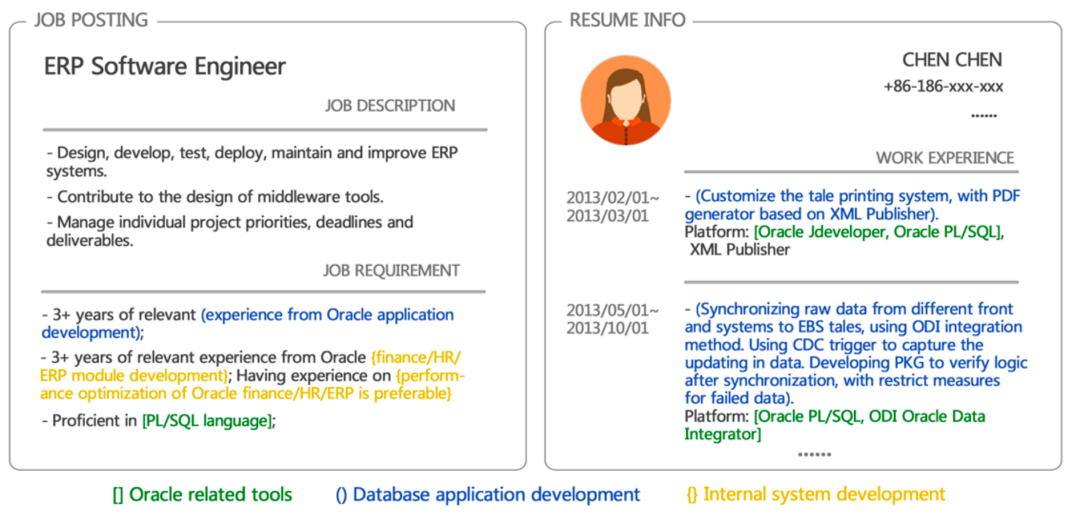
基于文本匹配的PJF
基于文本匹配的方法认为求职者与职位是否匹配主要依赖于求职者简历中的技能或工作经历与职位要求描述之间是否相对应,因此这种方法往往将PJF问题建模为一个简历与职位描述之间的文本匹配问题。早期的文本匹配方法中人们以一种无监督的方式创建文本的向量表示并计算相似度,如许多研究者使用具有TF-IDF权重的词袋,还有一些则基于Word2Vec方法。随着自然语言处理技术(NLP)的快速发展,CNN、RNN乃至Transformer等新型技术也开始应用于PJF问题并逐渐成为主流。本文选择了一小部分工作进行简单介绍。
【PJFNN】Person-Job Fit: Adapting the Right Talent for the Right Job with Joint Representation Learning (TMIS 2018)
https://dl.acm.org/doi/abs/10.1145/3234465
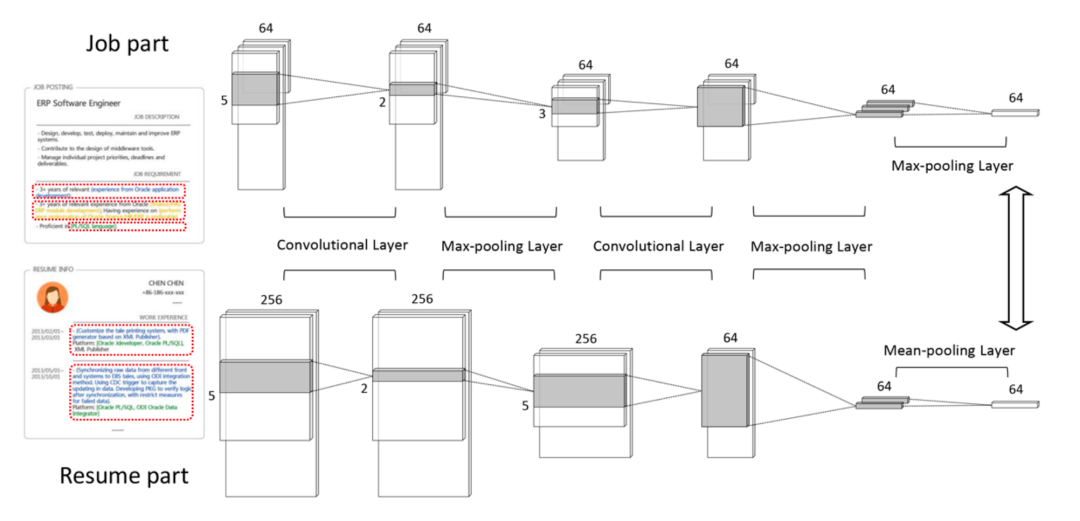
本文提出了一种基于卷积神经网络 (CNN) 的模型——PJFNN,PJFNN使用二分神经网络架构,对与职位要求描述以及求职者简历中的工作经历分别使用两个类似的CNN进行编码,它们之间唯一的不同是最后的pooling方法,职位要求使用Max-pooling,而求职者工作经历使用Mean-pooling。作者认为CNN最终输出的潜在表示的每个维度都可以反映专业知识的某些方面,职位的要求描述往往格式良好,不同要求项目通常独立的代表专业知识的不同方面。相比之下,求职者的每一项工作经历往往蕴含多种专业知识,因此更需要潜在表示之间的充分混合。
【APJFNN】Enhancing Person-Job Fit for Talent Recruitment: An Ability-aware Neural Network Approach (SIGIR 2018)
https://dl.acm.org/doi/abs/10.1145/3209978.3210025
与PJFNN基于CNN不同,本文中作者使用了LSTM+attention的方式进行求职者工作经历与职位要求的编码,在编码过程中两个部分的编码表示也不再相互独立,而是通过attention使得求职者工作经历与职位要求之间产生了充分的交互。整个模型的结构如下图:
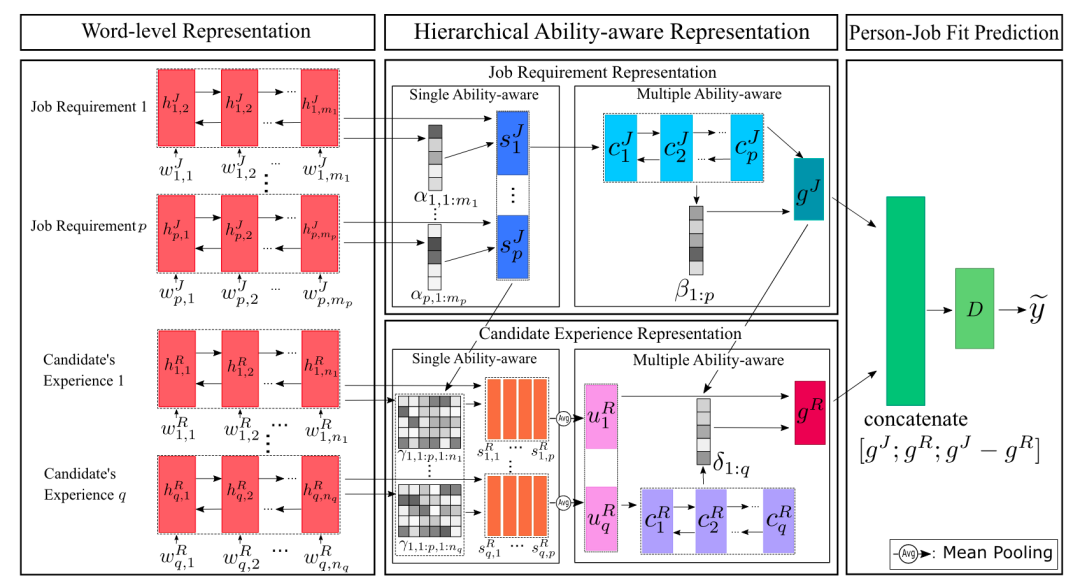
作者首先基于双向LSTM完成了单词级的表示(图中Word-level Representation),再通过两次attention完成了对职位要求的句子级表示以及全局表示(图中Job Requirement Representation),整个职位要求的编码表示过程与求职者部分独立。而对于求职者工作经历的编码则与职位要求息息相关,作者认为对于工作经历的编码过程应提取出与当前职位要求相关的信息,即工作经历中的某一项与当前职位的哪一个要求相匹配是关注的重点,因此在句子级以及全局表示的attention中都结合了职位要求表示完成(图中Candidate Experience Representation)。
【IPJF】Towards Effective and Interpretable Person-Job Fitting (CIKM 2019)
https://dl.acm.org/doi/abs/10.1145/3357384.3357949
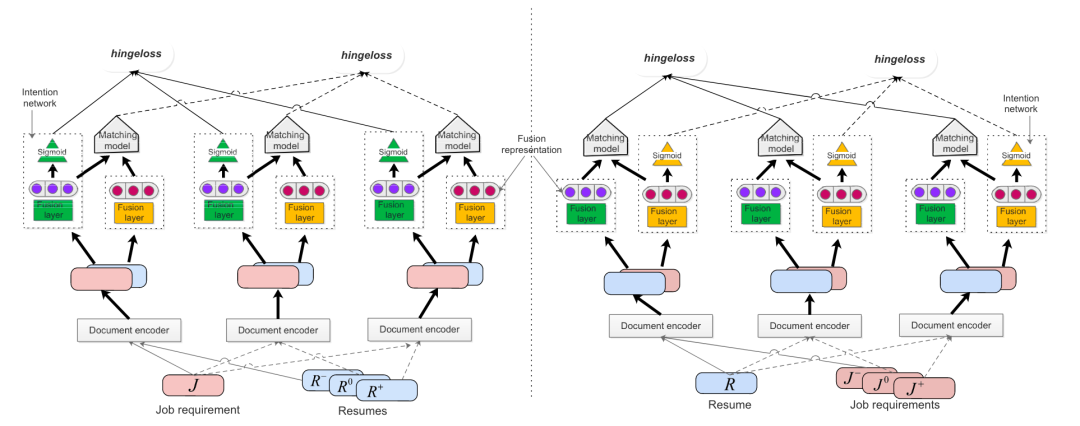
本文的亮点在于不仅仅考虑到了求职者与职位之间的双向匹配,还结合了求职者和职位双方各自的独立意图,提出了一个多任务框架。此外,作者不再将正例之外的所有目标都视为负例,而是将数据分为三种。以求职者为例,达成面试的职位为正例;求职者提出面试申请但遭到拒绝的职位为中性样本,代表单向意图;求职者没有提出面试申请的职位为负例。
【SCLPJF】Domain Adaptation for Person-Job Fit with Transferable Deep Global Match Network (EMNLP 2019)
https://aclanthology.org/D19-1487/
本文作者注意到了人岗匹配中带标签数据的稀缺问题,并希望通过领域适应(Domain Adaptation)的方法缓解这个问题。例如在招聘市场,科技领域的职位往往占比较大,数据较多,而设计相关的职位和数据较少,作者希望模型可以从具有足够标记数据的源域中获得的知识和信息来提高具有有限或很少标记数据的目标域中的预测性能。
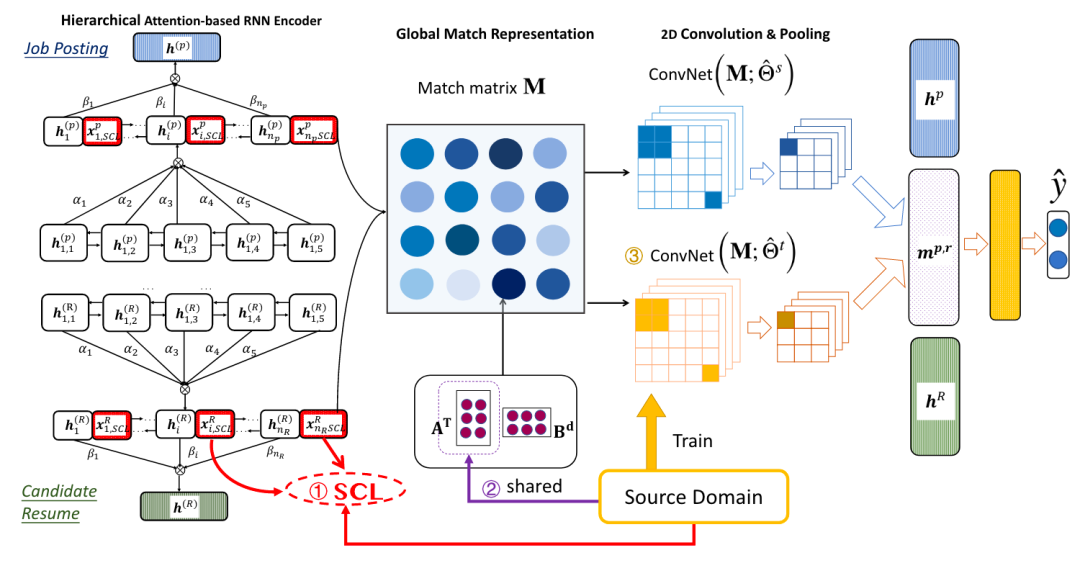
本文提出的模型主要分为Hierarchical Attention-based RNN Encoder和Global Match Representation两部分。前者基于双向GRU(BiGRU)对求职者简历和职位发布信息进行编码,并使用attention完成从单词级到句子级以及从句子级到全局表示的聚合,最终获得职位发布表示和简历表示。后者通过CNN建模职位发布与求职者简历之间的匹配信息。
为了实现模型在不同领域之间的可迁移性,作者首先使用文本领域自适应中的经典SCL算法得到相比于原始句子级表示更具可迁移性的SCL表示。其次将Global Match Representation中的匹配权重矩阵分解为两个矩阵的乘积,分别是多领域共享部分A和依托于特定领域的B;最后将卷积网络分为源域和目标域两部分实现了可迁移的匹配信息提取。
基于历史行为偏好的PJF
不同于基于文本匹配的方法,基于历史行为偏好的模型更注重于从求职者与职位双方的交互历史记录中提取出各自的偏好信息。虽然很多模型还会根据求职者简历与职位描述生成embedding,但不再通过各种复杂的方法进行简历文本与职位描述文本之间的匹配交互。
【DPGNN】Modeling Two-Way Selection Preference for Person-Job Fit (RecSys 2022)
https://dl.acm.org/doi/abs/10.1145/3523227.3546752
本篇文章获得了ACM RecSys 2022 Best Student Paper Runner-up。
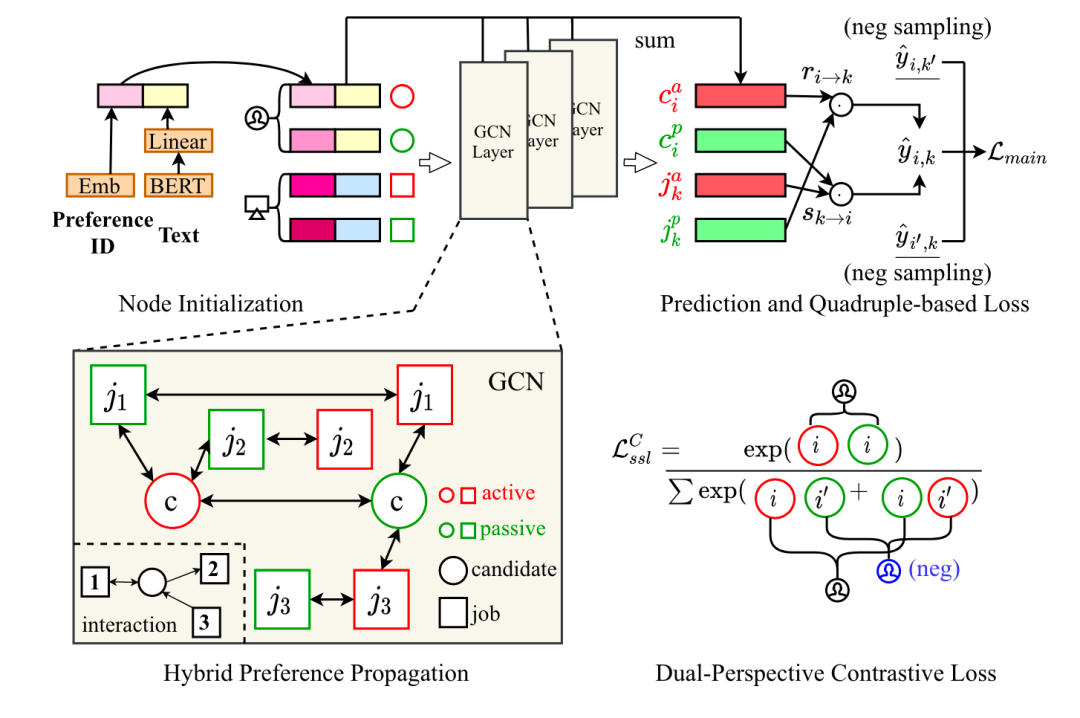
本文提出了一种有别于单向选择推荐以及整体文本匹配建模的双视角图表示学习方法DPGNN。在双视角交互图中,作者为每个求职者(或职位)建模两个不同的节点,一个捕捉自己选择职位(或求职者)的偏好,是一种主动表示,另一个是被动表示,用于与对方的偏好进行匹配。作者使用BERT对求职者简历和职位描述进行编码,结合基于ID的embedding表示对双视角交互图中的节点进行初始化,之后使用GCN进行混合偏好传播,区别于原始的GCN,DPGNN为单向偏好边和双向匹配边的信息传播赋予了不同的权重。在最终匹配预测上,DPGNN结合了两个视角的意图(求职者选择职位和职位选择求职者)。此外,作者还针对性的设计了一种四元组损失,为每一对求职者—职位正例分别采样一个负例求职者和一个负例职位。
【JRMPM】Interview Choice Reveals Your Preference on the Market: To Improve Job-Resume Matching through Proling Memories (KDD 2019)
https://dl.acm.org/doi/abs/10.1145/3292500.3330963
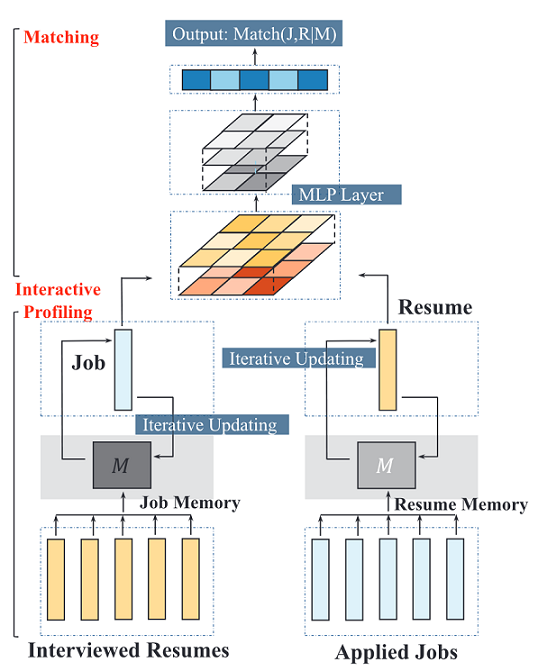
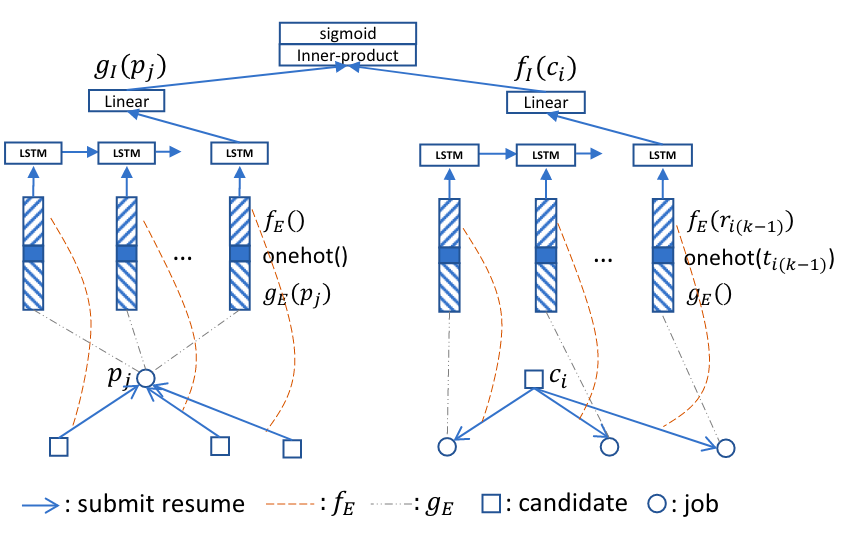
本文中作者提出了一种结合历史偏好的匹配网络(JRMPM),关键思想是从职位或求职者历史交互目标的文本信息中提取潜在偏好。具体来说,作者提出了一种基于记忆模块的偏好更新机制,以职位的偏好为例,JRMPM模型通过一个记忆矩阵M记录职位的句子级潜在偏好,并根据时间顺序,一步步根据职位历史交互求职者的简历信息更新记忆矩阵M。同理,对于求职者来说则是根据其历史交互职位的描述信息更新记忆矩阵。最终,通过Max-pooling将求职者与职位的句子级偏好记忆矩阵转换为全局偏好向量并输入MLP得到匹配预测结果。
【DPJF-MBS】Beyond Matching: Modeling Two-Sided Multi-Behavioral Sequences for Dynamic Person-Job Fit (DASFAA 2021)
https://link.springer.com/chapter/10.1007/978-3-030-73197-7_24
本文中,作者将关注点落到了求职者和招聘职位双方在实现匹配之前产生的丰富的辅助行为,如点击、申请、聊天等,不同于在PJF问题中非常稀疏的匹配行为,这些辅助行为往往更为密集且蕴含丰富的偏好信息。
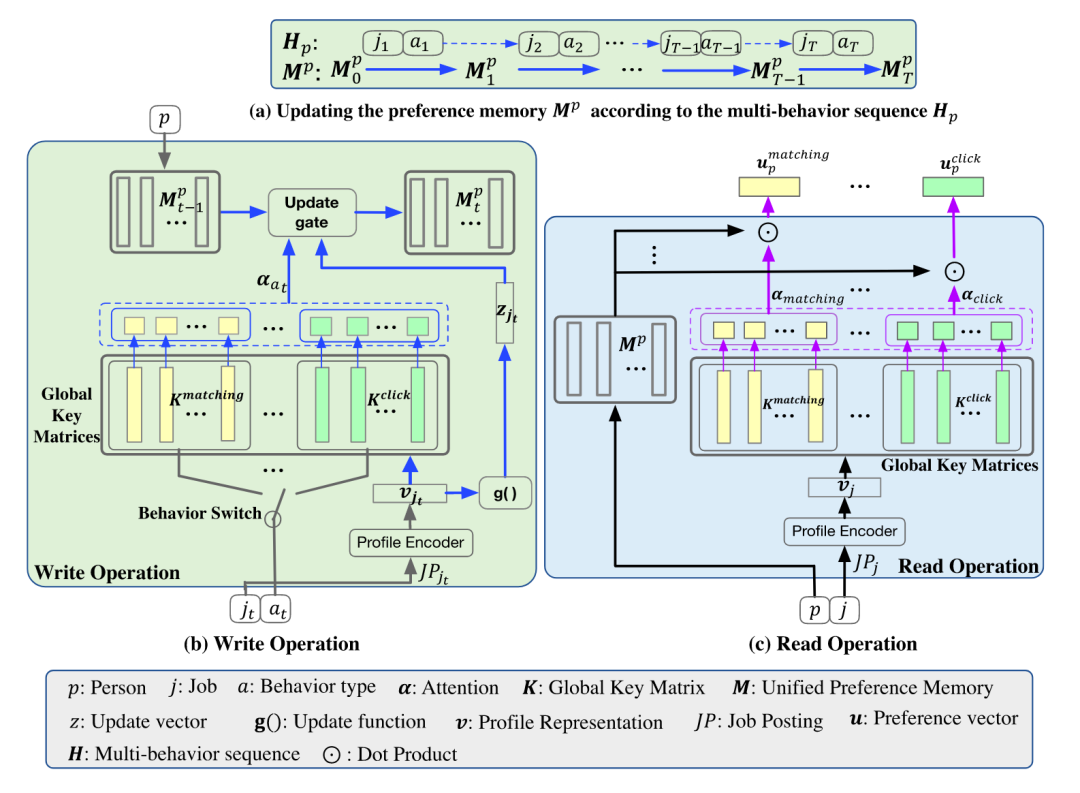
整个模型(DPJF-MBS)分为两个部分,Write Operation根据时间顺序将多种行为信息更新于记忆矩阵M中,Read Operation则从记忆矩阵中读出不同行为的偏好信息。具体来说,模型包含多个用户共享的全局键矩阵{, , , , },在Write Operation过程中,将当前行为对应的全局键矩阵当作key计算attention权重用于更新偏好记忆矩阵M,在Read Operation过程中也将根据不同的全局键矩阵计算不同的行为偏好权重,并根据权重聚合记忆矩阵M生成多个行为偏好向量。此外,作者还敏锐的注意到了多种行为之间的级联关系,例如在达成匹配的前提是经历过点击、申请等前置行为,因此最终的匹配预测是一个级联过程,对于匹配的判断需要前置行为的输出作为输入。
混合推荐方法
结合文本匹配与历史行为偏好建模的PJF方法也是研究者们的研究热点,这些方法往往是将从双方文本中提取的显式偏好与从历史行为中获得的隐式偏好相结合完成推荐。下面笔者选择了一部分工作进行介绍。
【PJFFF】Learning Effective Representations for Person-Job Fit by Feature Fusion (CIKM 2020)
https://dl.acm.org/doi/abs/10.1145/3340531.3412717
本文中提出了一种结合特征融合、文本匹配以及历史行为偏好建模的PJF模型,整个模型分为两个部分,一部分以求职者简历和职位描述中的显式信息为输入,另一部分建模双方的历史行为序列,建模隐式偏好特征。
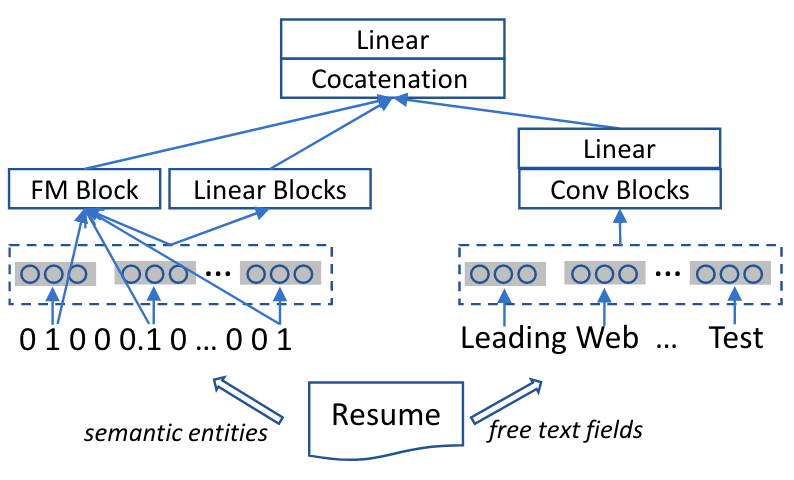
在简历或职位描述中除了技能描述、职位要求等文本信息外,还有一些可以通过NLP技术提取出的语义实体,如年龄、性格、大学等等,本文作者将这些实体也作为显式信息输入,通过DeepFM模型完成建模,对于文本信息则使用CNN得到向量表示,最终两种显示特征concat作为第一部分的输出。
模型第二部分则通过两个LSTM对求职者和职位的历史行为进行建模,用于提取双方的隐式特征,模型输入是第一部分获得的显式特征与匹配结果onehot向量的拼接。最终的预测过程中首先将双方的显式特征与隐式特征拼接,之后通过内积得到匹配得分。
【PJFCANN】Person-job fit estimation from candidate profile and related recruitment history with Co-Attention Neural Networks (Neurocomputing 2022)
https://www.sciencedirect.com/science/article/pii/S0925231222007299
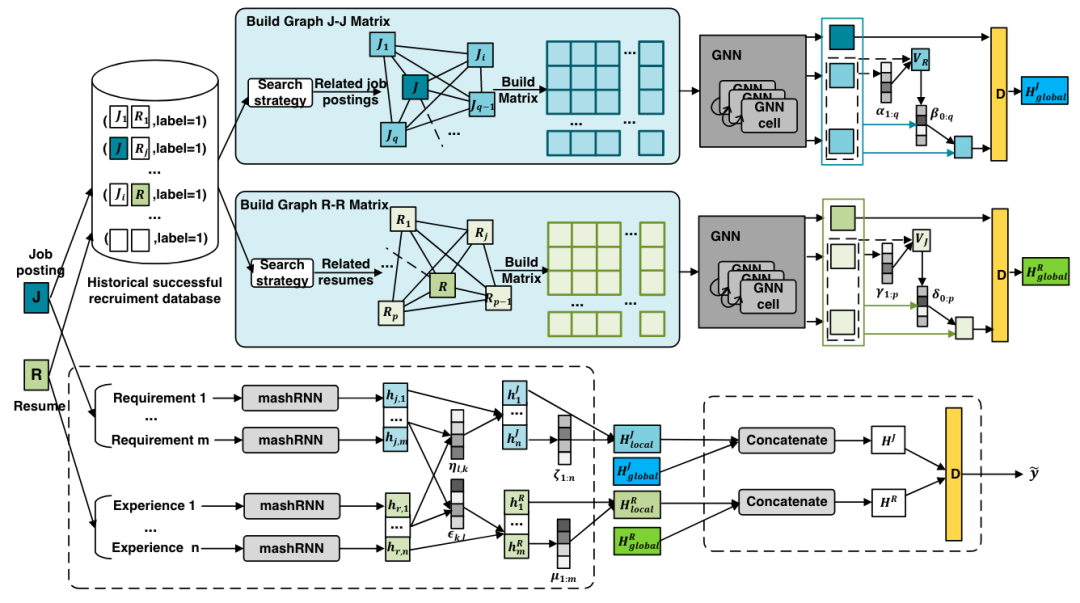
本文将文本匹配与从历史交互记录中提取的关系图相结合。文本匹配部分通过mashRNN实现了单词级编码,之后通过co-attention完成了简历与职位描述间的匹配交互与句子级编码,最终基于另一个简单的attention获得文本的本地(local)编码向量。此外,作者根据历史交互记录建立了职位—职位和求职者—求职者之间的关系图,以职位与职位之间的关系图为例,假设我们需要预测的job—resume对为 (J, R),若另一职位 J' 与当前简历 R 也产生过交互则在 J 与 J' 之间建立一条边,这条边的权重通过两个职位描述信息的相似度得到。获得两个关系图后通过GNN得到图中各个节点的表示,并基于attention机制获得职位和求职者简历的全局(global)表示。最终的匹配预测同样基于MLP实现。
其他
除了上述几类方法外,还有很多其他方法,例如基于特征工程的传统机器学习方法,基于单边偏好建模的职位推荐,灵活运用用户搜索历史或其他辅助数据的方法等。
The Influence of Feature Selection on Job Clustering for an E-recruitment Recommender System (2020):基于特征选择与提取。
A Session-based Job Recommendation System Combining Area Knowledge and Interest Graph Neural Networks (2020):加入领域知识增强的单边序列推荐。
Using autoencoders for session‑based job recommendations (2020):基于autoencoder的单边序列推荐。
Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network (2020):为了缓解PJF任务中交互数据稀疏且嘈杂的问题,作者提出了一种基于稀疏交互数据的新型多视图协同教学网络,结合基于文本匹配的模型和基于关系的模型,两个部分采用协同教学机制来减少噪声对训练数据的影响。核心思想是让两个组件通过选择更可靠的训练实例来相互帮助。
Leveraging Search History for Improving Person-Job Fit (2022):不再局限于求职者与职位之间的历史匹配记录,而是结合了求职者的搜索历史信息进行偏好建模。
Job Recommendation Based on Extracted Skill Embeddings (2022):从求职者简历与职位要求描述中提取技能短语,使用Word2Vec编码后计算相似度。
小结
本文从文本匹配、历史行为偏好建模以及混合推荐方法三个角度向大家介绍了当前人岗匹配中的主要模型与方法,可以看到,单纯基于文本匹配的人岗匹配方法在最新的研究中较少出现,随着BERT等系列大规模预训练语言模型的快速涌现,文本匹配任务也不再局限于简单的监督训练,最近的很多PJF工作中都将BERT作为一个基线且表现出不俗的性能,因此结合对历史行为偏好的建模是当前人岗匹配研究的主要方向。但同时人岗匹配的实际场景使得交互数据非常稀疏,如何解决数据稀疏也是当前的一大研究热点。
审核编辑 :李倩
-
新型铜互连方法—电化学机械抛光技术研究进展2009-10-06 7374
-
室内颗粒物的来源、健康效应及分布运动研究进展2010-03-18 3594
-
薄膜锂电池的研究进展2011-03-11 3092
-
太赫兹量子级联激光器等THz源的工作原理及其研究进展2019-05-28 2560
-
一维光子晶体研究进展2009-03-11 1043
-
声频定向扬声器的研究进展2010-01-08 896
-
锂离子电池合金负极材料的研究进展2009-10-28 4908
-
CMOS_Gilbert混频器的设计及研究进展2015-12-21 920
-
移动互联网QoS机制的研究进展述评2016-01-04 781
-
物联网隐私保护研究进展2016-03-24 704
-
共振式无线电能传输技术的研究进展与应用综述2017-01-05 1125
-
软件测试技术的研究进展刘继华2017-03-14 1165
-
无人车领域的主要研究进展分析2018-10-28 9682
-
AI指数报告 看几大国AI领域的研究进展和趋势大比拼2019-03-01 1027
-
农业机械自动导航技术研究进展2021-03-16 1273
全部0条评论

快来发表一下你的评论吧 !
