

Cache与性能优化精彩问答38条
描述
编者按:1月8日晚上,《深入理解cache训练营》讲师甄建勇和阅码场资深用户wisen围绕Cache和性能优化展开了一场线上圆桌讨论。本文是对圆桌内问题的解答整理,不一而详,供大家参考。感谢阅码场用户王建峰对于问题的整理。
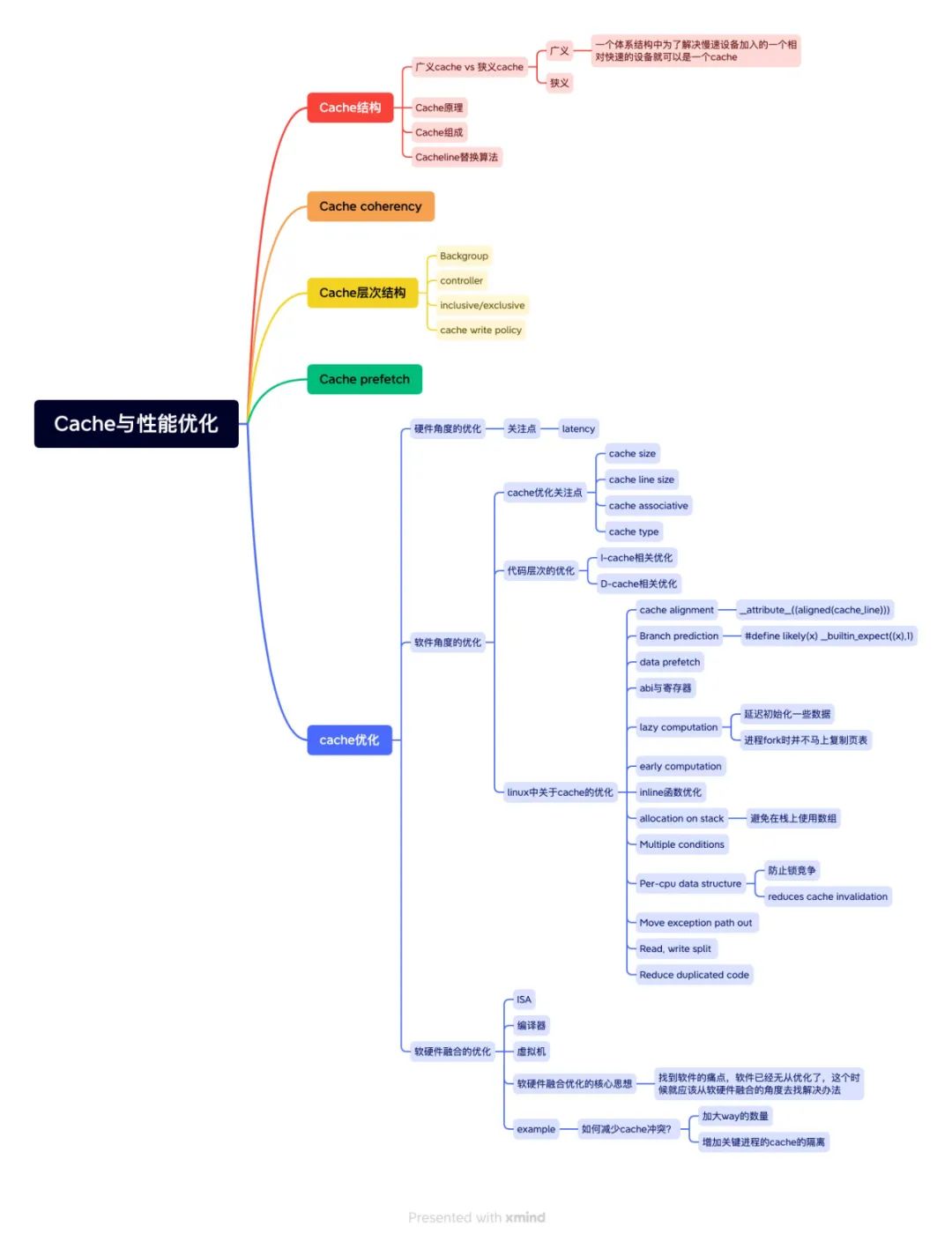
图:wisen整理的Cache和性能优化的思维导图
1、能不能举个日常生活的例子来理解什么是Cache?
例如,我在商场购物时,把要买的东西先把它放到小推车中,最后统一结账。此时,把 自己想象成芯片中的 CPU,购物车是芯片中 Cache,柜台是芯片的输出口。再例如,我在图书馆看书,随手将喜欢看的书放到柜子里,这里某一些书我会反复看,不想看时把书放回书架上。此时,我是 CPU,书柜是 Cache,书架是下一级存储器。
2、关于 Cache和硬件设计的问题:在具体的 SOC和 CPU实现的时候,Cache占用面积给 Cache设计的限制有多大?
占用非常大的面积,大概在一半以上,而且一个好的 Cache 的设计复杂度非常高,可能比较 CPU 的 Pipeline 还要复杂。这里要考虑成本,设计复杂度,或者其他方面的考虑。你知道 L1 Cache 为什么一般是 32K 吗?如果画出曲线的话它会有一个拐点。另外一个角度是根据业务的场景,来设计 Cache Size,包括 Cache 的规格的定义。
3、像现在有很多的服务器的芯片,一上来就有 128个核,做这种 SOC设计的时候有需要特别考虑的点吗?
像这种设计的内存模型一般是 NUMA 和 UMA 的混合,考虑平衡性和灵活性。
刷 Cache时没有一致性协议保证。比如有两个 Core,其中一个 Core刷 Cache,(要保证一致性)另外个 Core也要刷。这个时候时一个 Core发中断,另一个 Core收到中断以后在去执行。有遇到过这种场景吗?
情况比较复杂,如果是一个主核和一个从核刷的话,需要这种方式来刷。如果运行虚拟机的话,只能刷自己的。
4、为什么需要 Cache Line Size对齐?
提高对 cache 的利用率,避免浪费。我们假设一个 Cache Line 的 Size 是 64 Byte,例如
•如果有 32 Byte 的数据要存入 Cache ,在 Cache Line 内部没有对齐的话(比如存放到中间的某一个区域),这时在想要向这个 Cache Line 继续存储 32 Byte 的数据时,剩余 32 Byte 的空间却无法存储这一部分数据,那么就会造成资源浪费。
•如果有 64 Byte 的数据要存入 Cache ,在 Cache Line 起始地址没有对齐的话(地址没有按照 size 的倍数对齐),实际上占用2个 Cache Line Size ,可能就会多造成一个 Cache Line 的浪费。
5、Cache指令预取和 BTB预取有什么区别吗?
BTB 根据硬件自己的算法做预测的,和 Cache 指令预取(likely 函数)相互补充,使得整体效益最大。
6、L1/L2/L3/SYSTEM/Cache相互是之间的联系是怎么样的?
它们是一个金字塔类型,一般情况越往下的 capacity 越大,速度越慢。它们之间关系的话有两种:inclusive 和 exclusive。inclusive 表示是一个包含关系; exclusive 相反的关系,例如 L1 里有的 在 L2 一定没有。
7、我们主要针对 L2/L3/Cache做的代码优化吧?
不仅仅是这些。课程在详细展开讨论。
8、System Cache一般是 DDR前面的是吧?
结论正确。这个提问方式不是特别的好,可以问 System Cache 干嘛用的呢? 一般来说 L1/L2/L3 是给 CPU 来用的,而 System 中的一些 IP ,比如 GPU 也需要缓存的话,可以使用 System Cache 。
9、单 Cache的优化方向。除 Cache Line的按场景分配,对齐,之外,在内存本身上还有什么样的优化方向?
其中一个是结合程序本身的行为进行优化,不同场景的分配算法;其中另一个方向 Cache Line 的压缩。
10、各级Cache大小如何选择,有哪些选择标准?不同大小组合对不同性能影响怎样?
例如 PPA 、PPAC 、PPACY。
11、以 VIPT为例,Cache访问时候 Index到底是怎么从虚拟地址里取出来的,Tag又是取了物理地址的那部分?
地址到达 Cache 之前,假设是 VIPT ,Index 查找直接跨过 MMU 到达 L1 Cache ,Index 直接从虚拟地址取出对应的位就可以了。Tag 的话看 Cache 的组织,几路组相连,知道 Cache Size 就能知道 Tag 大小。实际上这个地方,在实际的 Cache 中还要考虑 MMU,考虑虚拟机,考虑不同的进程。
12、如何提升 Cache命中率,有哪些方式方法?
如图片归纳的方法。如果用一句话总结的话,局部性越好一般(Cache命中率)越高的。局部性是指时间的局部性和空间的局部性,就是说 CPU 越是频繁的访问相同的物理地址,Cache 的命中率是越高的。
13、请问下做 Cache性能优化的常用手段有哪些啊。Perf采集?
如图片归纳的方法。Perf 采集时其中的一部分。我们的逻辑时这样,我们做 Cache 性能优化,(前提是)要先了解它,当我们了解之后,甚至是非常熟悉和通透之后,很多优化的算法思路就会涌现出来。
14、exclusive有什么好处与代价?
如果从上层看它的等价的 Cache Size 是变大的,因为是互斥的嘛。例如你有两个桶,雨水从屋子上留下来,这两个桶是重叠呢还是不重叠呢? 此时桶就是 Cache,雨水就是流入的数据,exclusive 不重叠会让局部变大一些。
15、请问 ARM64架构下,如何理解 Cache refill和 Cache allocate的异同?谢谢
Cache allocate 策略是什么样子的,怎么去走 refill 策略。这里做法有很多,比如是直接去拿,还是等一等,如果等的话要等多久。课程在详细展开讨论。
这个压缩是平台硬件设计的行为还是软件算法?
软硬件结合设计。
17、VIPT也有 Cache的重名问题。这个一般要怎么解决啊?
ASID
18、Cache设计时遇到什么严重问题?
两个比较严重的问题,其中一个时物理地址和虚拟地址发生错乱,一个物理地址对应到两个虚拟地址,或者一个虚拟地址对应到两个物理地址;另外一个时同一块数据存放到两个不同的 Cache Line 里面。课程在详细展开讨论。
19、请问关于 Cache压缩之类的配置是看 Cache的 datasheet还是 armarchtrm?
armarchtrm
20、为什么要避免在栈上用数组?
有两个原因,第一个是在栈里面分配数组,数组分配的初始化,对 Cache 是一个操作。然后再多进程切换时,栈的数组(在Cache中)还会被刷掉。所以对于比较大的数组,用全局变量分配比较好。如果在栈上分配的话,在初始化的时候(Cache)被冲刷。
21、老师课程会讲 innersharebale/outershareable/pou/poc吗?
会。课程中深入讨论。
22、课程会讲 CPU/GPU/NPU架构方面的内容吗?
会。讲师个人经历过多年的 CPU/GPU/NPU 的架构设计。课程中深入讨论。
23、请问同一个 SoC/L1/L2/L3/Cache的组织方式相同么?会不会 L1用 vipt,L2用 pipt?
其中 PIVT 很少见之外,其他三种都会用。有很多 L2 用 PIPT。课程中深入讨论。
L1主要负责速度, L2主要负责广度
正确。
24、inclusive与 exclusive在 Cache一致性维护上有什么区别?
inclusive 与 exclusive 在设计的时候,它们的要求是不一样的,硬件行为是不一样的。
25、L1中的数据在 L2中的位置是固定的么?
不固定。
26、CPU访问 Cache和访问 DDR在 Power上的消耗比例?
1000倍量级。
27、有啥工具可以分析不同 NUMA节点核的 Cache invalidate的延迟吗?
芯片规格说明书里一般会提供。
28、编译器优化会做自动的 Cacheline对齐吗?
向编译器里加一些编译选项。
29、有哪些专门测试 Cache性能测试的 benchmark吗?
非常多。
30、Snoop啥时候工作呢?
是一个 Standby 的机制,一直在工作。
31、Cache怎么仿真?
仅在 Cache 的设计阶段。
32、什么情况下会将 Cache invalid之后,然后 flush到 DDR中?
Cache Line 一般放置处理的数据,flush 为了将 Cache 腾空
33、什么情况下会将 Cache invalid之后,然后 flush到 DDR中?例如数据从外设(用DMA)搬进来,这时候数据在 DDR中,此时 CPU想要不过 Cache直接读 DDR中的数据。
直接设置 non-cached 的地址去读写就可以了。这种情况是申请的时候是带 cache 的地址空间,然后直接就用的话,访问数据是带 cache 的。
34、busrtmemaccess导致同一个 Cacheline多次连续 miss,一般 pmu会重复计算吗?
看 pmu 的 spec。
35、监听式和目录式一致性维护有什么区别?
完全两套不同的机制。监听式是一个广播的机制,适合核比较小的情况。目录式完全相反。
36、CPU内存和外设共享,外设写到 DDR中,然后 CPU读。之前遇到个这样的问题,有两个Cache,在一个 Cache中可能因为预取一些数据。那么在另外一个 Cache中做无效,那么在原来 Cache已经预取的那一部分数据没有办法做处理,这样 CPU就读不到外设搬到 DDR上新的数据。因为 Cache预取的缘故,在另外 Cache中做无效是没有用的这种情况,怎么处理呢?
原来 Cache 读的时候,将预取功能 disable 掉。但是预取不能一直关掉,只有代码在危险区的时候,才关掉。
37、什么场景要用到 RSB?
动态指令修改。
38、DSB的原理是什么?
原理很简单,实际上在硬件上结构里面,它是有先后顺序的。只不过在为了某种性能的考虑,允许它乱序。但是有些特殊的指令,比如你提到 Barrier 指令,出现这类指令的时候,决定这条指令的完成。CPU 内部 Pipeline 里面,核里面,是有一定的顺序的。所有的指令都有一个提交态,我们会知道单条指令的取指、译码、执行,写回是谁给他的呢? 实际上是 Cache 给它的。Cache 是谁给他的呢? 实际上是下面的 DDR 给它的。所以实际上这里是一个非常大的环,看起来这个指令在 CPU Core 里面,一级一级来,最终这个指令才能提交。硬件上要保证它的顺序,通过它的 FIFO。FIFO 里面你怎么 POP 出来,POP 出来之后,怎么释放,要等它的下一级。
审核编辑 :李倩
-
NVIDIA 知乎精彩问答甄选 | 探索 AI 如何推动工作流升级相关精彩问答2023-12-14 1177
-
NVIDIA 知乎精彩问答甄选 | 查看关于 NVIDIA Omniverse 的相关精彩问答2023-12-01 1481
-
NVIDIA 知乎精彩问答甄选 | 分享 NVIDIA 助力医学研究的相关精彩问答2023-11-24 1565
-
NVIDIA 知乎精彩问答甄选 | 分享 NVIDIA 在艺术创作方面的精彩问答2023-10-13 1368
-
NVIDIA 知乎精彩问答甄选 | 了解更多关于 NVIDIA BlueField DPU 相关精彩问答2023-09-20 1451
-
NVIDIA 知乎精彩问答甄选 | 查看 NVIDIA Jetson 相关精彩问答2023-09-14 1498
-
NVIDIA 知乎精彩问答甄选 | 发掘 NVIDIA 医疗行业相关精彩问答2023-09-06 1432
-
NVIDIA 知乎精彩问答甄选 | 查看 NVIDIA Omniverse 相关精彩问答2023-08-01 1410
-
电源设计精彩问答!2021-09-13 1580
-
电机知识精彩问答盘点2021-01-21 885
-
linux一句话精彩问答2013-04-21 2479
-
电源设计精彩问答2010-07-05 475
全部0条评论

快来发表一下你的评论吧 !
