

一个TransCAD和TransModeler双平台动态交通分配DTA模型
描述
1、内容提要
本文介绍了2017年4月-2019年7月的一个TransCAD(TransDNA)和TransModeler双平台动态交通分配(DTA)模型。该项目旨在为内华达州南部地区交通委员会(RTC)开发动态交通分配工具。DTA模型涵盖RTC区域出行需求模型(TDM)的整个建模范围,包括拉斯维加斯市、北拉斯维加斯市、亨德森市、拉斯维加斯谷内未合并的克拉克县地区以及博尔德市的核心区域。
Caliper公司是构建模型的软件平台TransCAD和TransModeler的开发商,为RTC创建了两个DTA模型: 一个DTA模型在TransDNA中实现,这是一个建立在TransCAD平台上的中观DTA,利用了建立RTC TransCAD出行需求模型的大部分相同数据和地理信息。这种中观DTA为区域范围内的应用提供了快速DTA。
对于这些应用,为了更快地响应更大范围或更面向规划的决策,可能会牺牲解析度和准确性。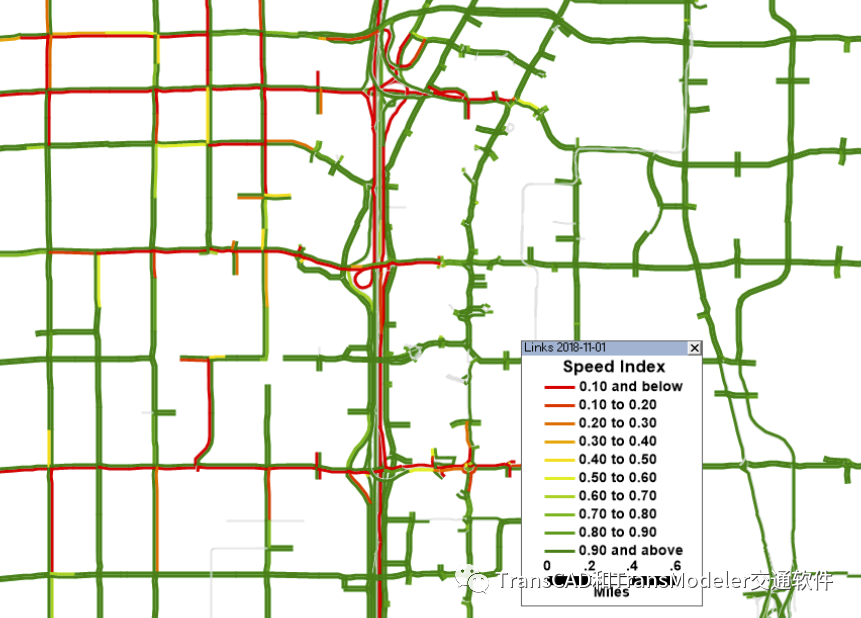
TransDNA的车速动态颜色专题 另一个DTA模型在TransModeler中实现,并使用高解析度微观交通仿真来模拟整个区域的交通流。这种微观DTA更可靠、更准确地解决了运营问题,预测了运营能力及其对拥堵模式的影响,进而预测了路径选择。
这两个DTA模型都包括RTC规划模型中的每个道路路段,但TransModeler中的微观DTA中添加了许多其他路段,以反映该地区所有信号交叉口的影响,如果没有这些影响,各种交通模型都有可能低估主干道上的出行时间和延误。针对上午高峰时段(上午6:00–上午9:00)和下午高峰时段(下午1:00–下午6:00)制定了DTA场景/方案。
对DTA模型进行了校准,以验证该模型的出行特征(例如,出发时间的时间分布)反映了历史交通流观测数据,并验证了该模型的模拟出行时间与观测的出行时间和速度密切匹配。本文详细介绍了DTA模型开发过程中所采取的步骤和假设,简要描述了校准方法,验证结果,并说明如何使用模型。
2、模型开发
TransModeler中的动态交通分配(DTA)模型是根据以下描述的输入数据开发的。车道级道路网最初几乎完全从零开始开发,使用高分辨率航空图像作为参考。形心和形心连线从区域出行需求模型(TDM)中导入,以确保交通分析区(TAZ)中心ID的一致性。形心作为RTC区域出行需求模型中的产生出行的起点和终点。
共同的TAZ和形心,是出行需求和DTA模型之间的主要关联要素,并允许两个模型随时共用出行矩阵。随后导出了高度精确的道路网络,以创建TransDNA的线层路网,其中包括描述左转和右转湾岛长度及其车道数的字段。TransModeler数据库的开发将在本节后续部分描述。
2.1数据来源
建立DTA模型需要各种数据。至少,这些数据包括用于构建街道网络地理和几何结构的航空影像、用于模拟信号交叉口运行的信号配时数据,以及用于校准模型的短时间间隔的观测的交通流量/速度数据。通用公交提供规范(GTFS)数据可用于将公交路线信息导入模型。其他类型的数据,如详细的交通流量和出行时间观测,用于验证模型。
RTC的DTA模型是根据以下数据源开发的: 可从谷歌等网络地图服务免费获得航空影像 RTC提供的信号配时 RTC提供的流量观测数据 来自INRIX的速度数据 谷歌出行时间 GTFS数据
2.2模型设计
开发DTA模型的TransModeler和构建区域TDM的TransCAD共享以TAZ ID的形式表示出行的起点和终点。这种对出行起点和终点的共用允许将TDM生成的出行矩阵用作DTA模型的输入并进行模拟。 DTA模型包括区域TDM规划模型网络中的每一条道路路段。增加了许多其他路段,以便包括所有信号灯和其他主要路口,这些路口可以从航空影像中识别出来。
除了将其用作交通影响评估的可靠交通模型外,DTA模型还有其他值得一提的重大好处。DTA模型的地理信息系统(GIS)和关系数据库平台使该模型成为一个强大的车道级交通数据存储库。具体来说,该模型可以用作数据库来存储和更新地理和几何信息。
此外,该模型还可以作为RTC地区的信号配时清单,以补充高速公路和干线运输系统(FAST)维护的工具。最后,该平台还提供了一个集成的GIS-3D建模环境,可用于可视化场景并促进公众和利益相关者参与项目评估过程。
2.3路网开发
在任何规划软件平台中,表示TDM中道路网络的地理线图层可用于在TransModeler中生成初步仿真数据库。因此,TransCAD中RTC模型的规划网络是创建DTA模型仿数据库的潜在资源。然而,TransModeler中的道路编辑和网络开发工具使得通过高分辨率航空影像图为整个大都市地区开发网络变得更具成本效益,这一过程有助于其他重要的网络开发任务,例如识别可能不在规划网络中的公共汽车和HOV车道以及信号交叉口。RTC规划区域的仿真数据库因此得以开发,并增加了额外的路段,以覆盖影像图中可识别的所有信号交叉口。
其他工具,如谷歌地球和谷歌街景,被用于确认重要的几何细节,如车道利用率和交叉口禁止转向。 TransModeler提供了对web地图服务的内置访问,这些服务允许将地图内容(如谷歌地图、谷歌卫星、OpenStreetMap和USGS地形图)自动下载到地图窗口。
来自这些网络来源的航空图像被用于确定道路、交叉口和立交的几何结构。如果在图像中可以看到施工情况,或者已知或怀疑近年来发生了道路项目,则使用历史图像或其他基于网络的来源来确定模型基础年(2015年)的几何结构。 在路网开发结束时,TransModeler中的错误检查程序用于扫描数据库中常见的编码错误。
这确保了不存在缺失的车道连线、不必要的短路段或交叉口或道路几何结构错误。在模型开发和模型校准过程中,还遇到了其他编码错误并进行了纠正。
2.3.1几何细节
DTA模型中几乎包含了所有几何细节。模型开发的重点是实现交叉口形状和尺寸的高度精确表示,这在很大程度上决定了交叉口或互通式立交的运营能力。除了交叉道路的几何形状(例如,水平曲率)外,还努力准确表示转向岛长度、车道宽度、转向车道渠化、通过交叉口的车辆轨迹和其他几何元素。下图显示了RTC区域中两个地方模型的详细程度。
I-15和W. Flamingo路立交
N. Town Center Drive的一对环形交叉口
2.3.2道路功能类别
在TransModeler中确定并将适当的道路功能类别应用于路段对模型中的驾驶员行为和路径选择具有重要影响。速度限制是微观仿真模型中最重要的道路等级属性。驾驶员的期望速度,即驾驶员在没有交通信号或其他车辆影响的情况下行驶的速度,是速度限制的函数,更保守的驾驶员严格遵守速度限制,更激进的驾驶员行驶速度更快。
2015年修正的TDM模型网络中的道路等级和速度数据用于为仿真模型中的所有适用指派道路等级。对DTA模型中未包含在TDM模型中的道路功能等级进行了评估。下图显示了DTA模型中按道路类别进行颜色编码的道路网络的线图层表示。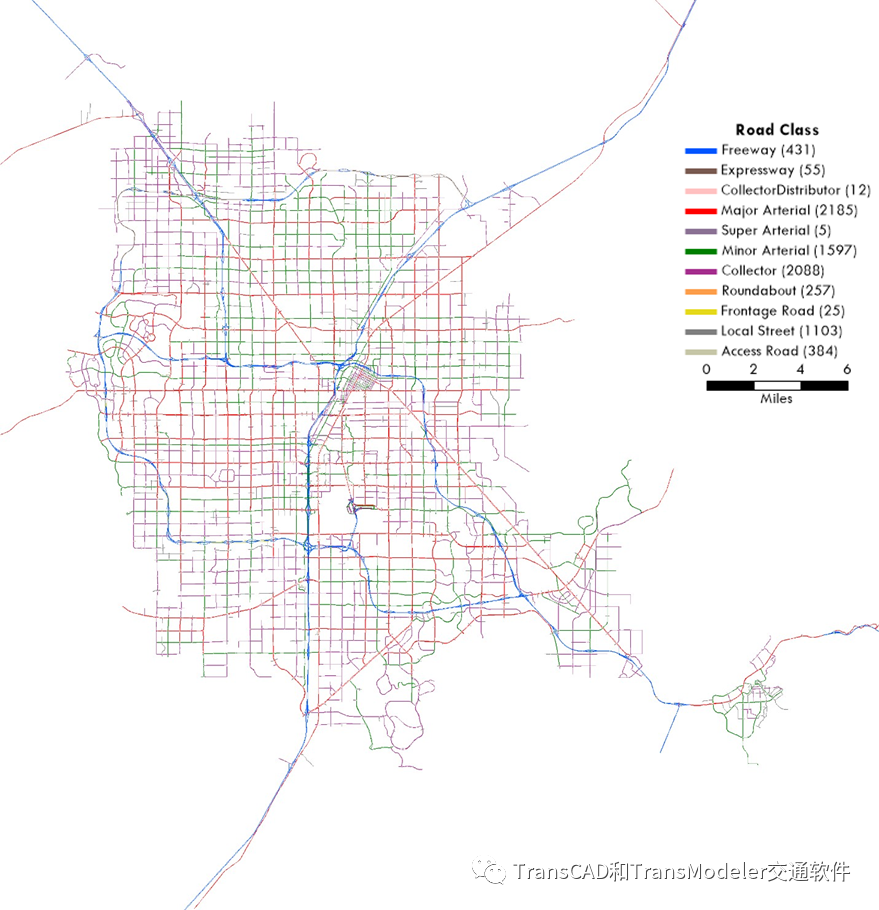
道路网络功能类别颜色编码地图
2.4交通控制输入开发
交通信号对地面道路的交通运行至关重要,DTA模型对交通信号配时的详细表示足够准确,以支持具有高度运营敏感性的假设情景评估。该模型可以支持公交信号优先、列车优先和各种其他交通信号配时策略的分析。 FAST提供信号配时数据,包括匝道信号配时数据。RTC工作人员还协助提供了许多信号配时电子表格中没有的相位分配的额外数据(例如,相位1服务于EBL转向)。
在研究区域内的1437个信号交叉口中,1414个为FAST信号,1060个为导入的可用信号配时数据。剩余377个信号的信号配时是根据预计的2015年高峰时段转向需求、该区域的通用信号配时参数和工程判断进行估计的。在整个网络中,假设了感应信号操作,并应用了简单的检测器几何结构,包括停车呼叫和延时检测。
研究区域内有68个匝道信号。获得了其中38个地点的时间参数,并对其余地点进行了假设。在没有可用数据的匝道信号,假设交通响应操作在一天中最常见的时间(6:00 AM–9:00 AM和3:00 PM–6:00 PM)运行,RTC向我们提供了典型的占用率和费率。队列检测器也被假定为可运行,如果超过队列占用率,则假定匝道流量统计被关闭。
下图提供了匝道信号位置示意图,图2-5提供了模型中信号交叉口位置示意图。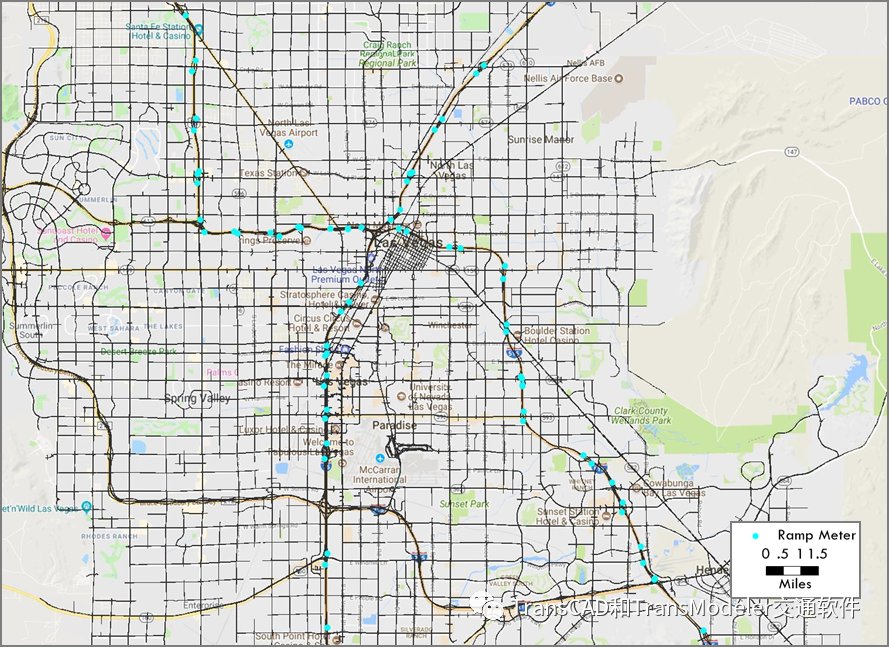
DTA模型中的匝道信号分布图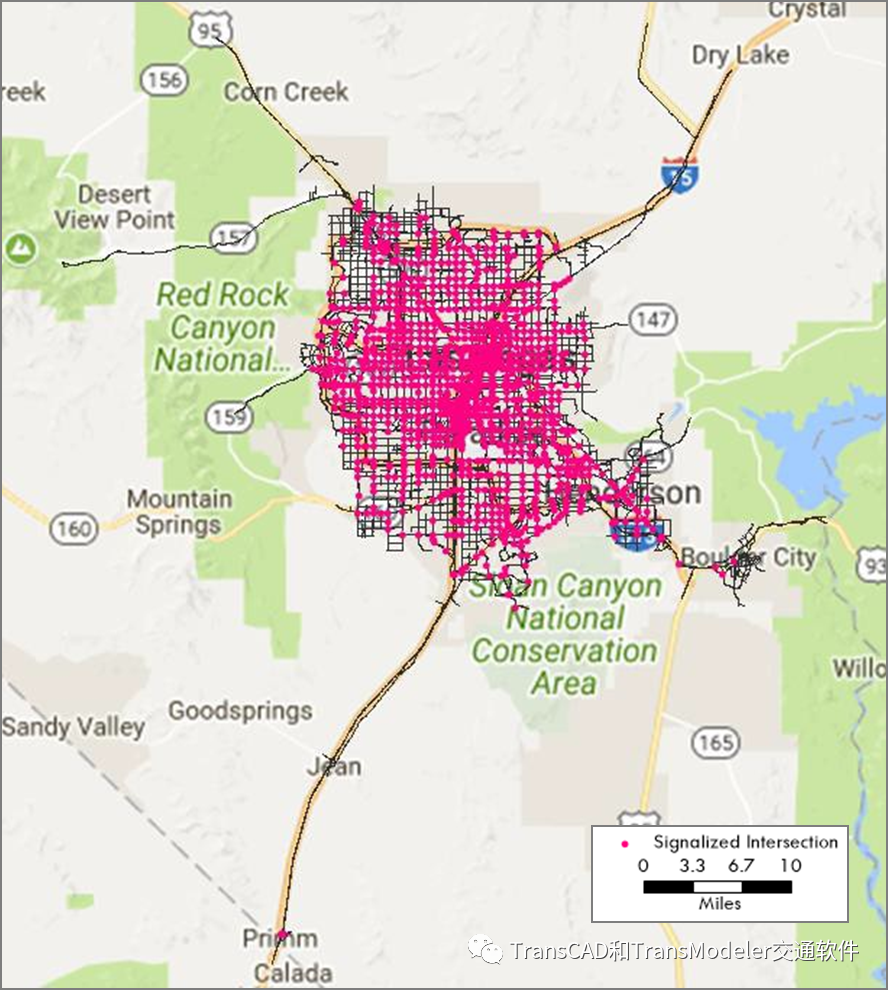
DTA模型中的信号交叉口位置图
2.5流量观测数据
整个研究区域的交通流量数据来自五个来源: (1)内华达州交通部(NDOT)短期15分钟流量 (2)快车道流量 (3)ATR流量 (4)内华达州南部交通研究(SNTS)对三个地点的15分钟间隔流量(包括I-15、 I-215和Summerlin Parkway) (5)FAST探测器数据(流量和速度),15分钟间隔 仿真数据库是一个地理关系数据库,存储了道路网络的地理和几何结构,其中包括了这些流量数据,我们的校准分析侧重于这些数据以及下面讨论的速度数据。
不幸的是,快速车道流量无法用于校准,因为没有按车道区分交通量。
相互冲突的流量也会被丢弃,因为它们会对校准过程产生不利影响。 例如,在I-515 NB沿线的这个位置,我们有四个流量观测位置,总PM高峰期(2:00 PM–6:00 PM)的交通量如下所示。
东向西方向,19390–2047+4446 =21809。然而,橙色的数字只有17407。其他相邻计数与19390计数一致,因此我们使用零权重对流量17407进行加权。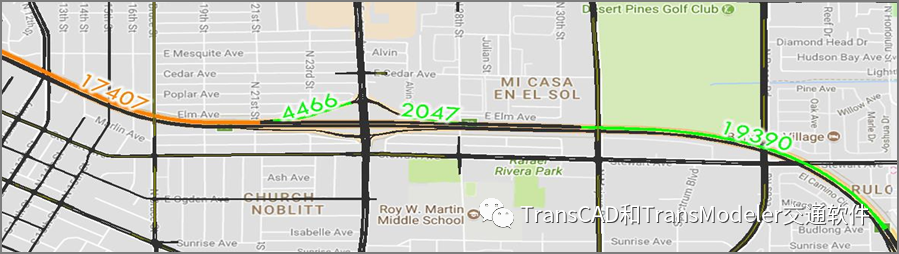
权重为0的流量观测断面例子 总的来说,AM期间有效流量观测点为939个,PM期间有效数为954个,分布在整个区域。下图说明了整个网络中流量观测点的位置。流量观测与模型中的路段(片段)相关联。图中呈现了整个网络中观测点大致均匀分布。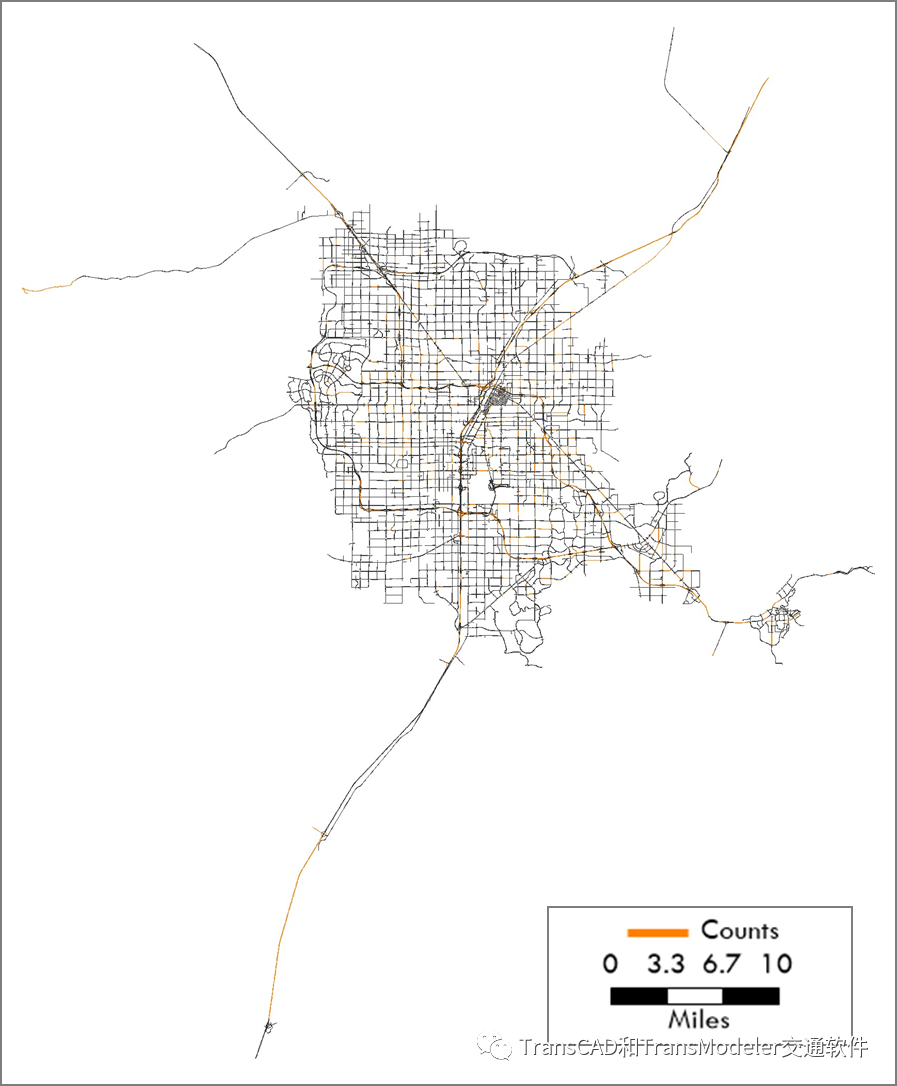
流量观测断面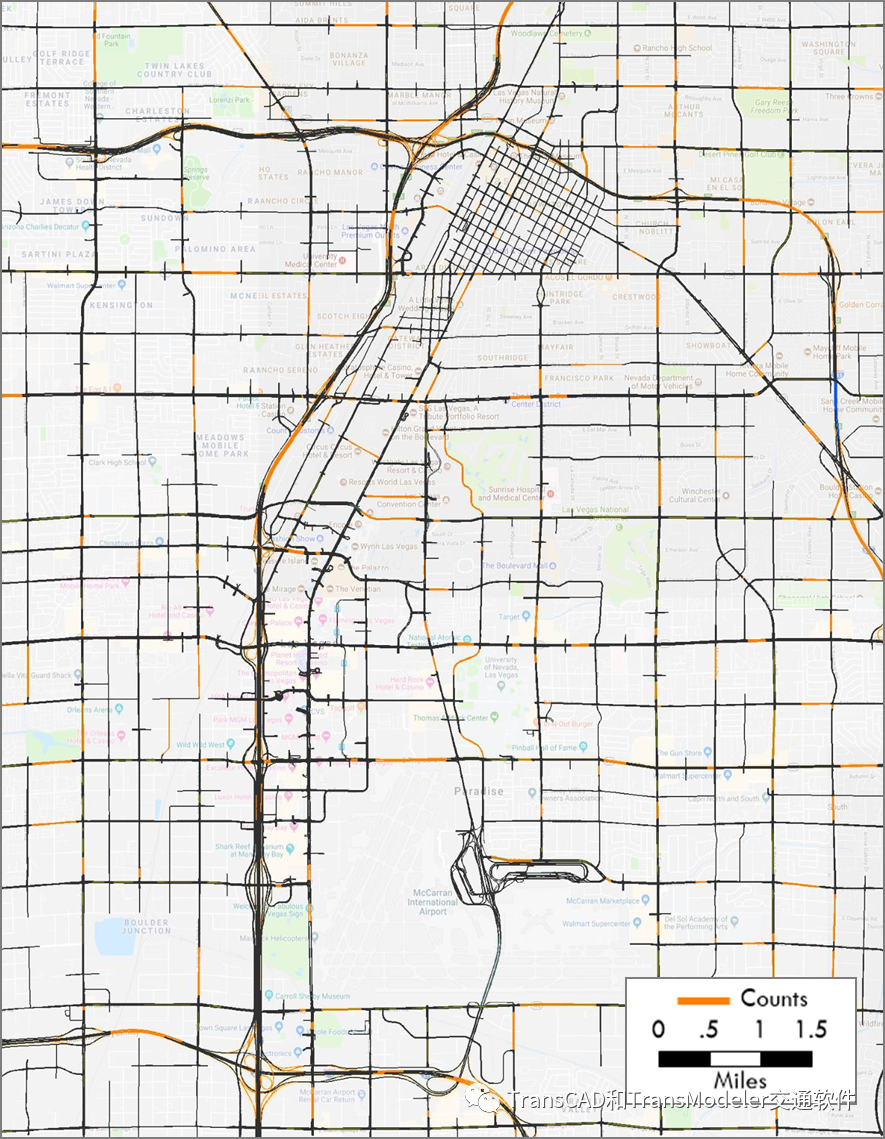
Strip和空港附近的流量观测断面
2.6速度数据
速度数据对于了解网络中瓶颈的位置至关重要。INRIX是一家全球软件即服务(SaaS)和数据即服务(DaaS)公司,提供移动电话、联网车辆、卡车和配备GPS设备的车队车辆的道路速度数据。获取2016年3月1日至2016年5月31日之间的周三INRIX速度数据,并将其平均值用于校准过程。
2.7出行时间数据
为了验证该模型,我们使用Google的Directions API(应用程序编程接口)获得了示例出行时间数据,这是通过Google地图平台提供的各种web服务之一。
使用的Directions API许可证限制了每天可以提交的查询数。我们选择了分布在整个网络中的59个TAZ的形心,确保每个大区(K-District)至少选择两个TAZ。59个原始TAZ形心的位置如下图所示。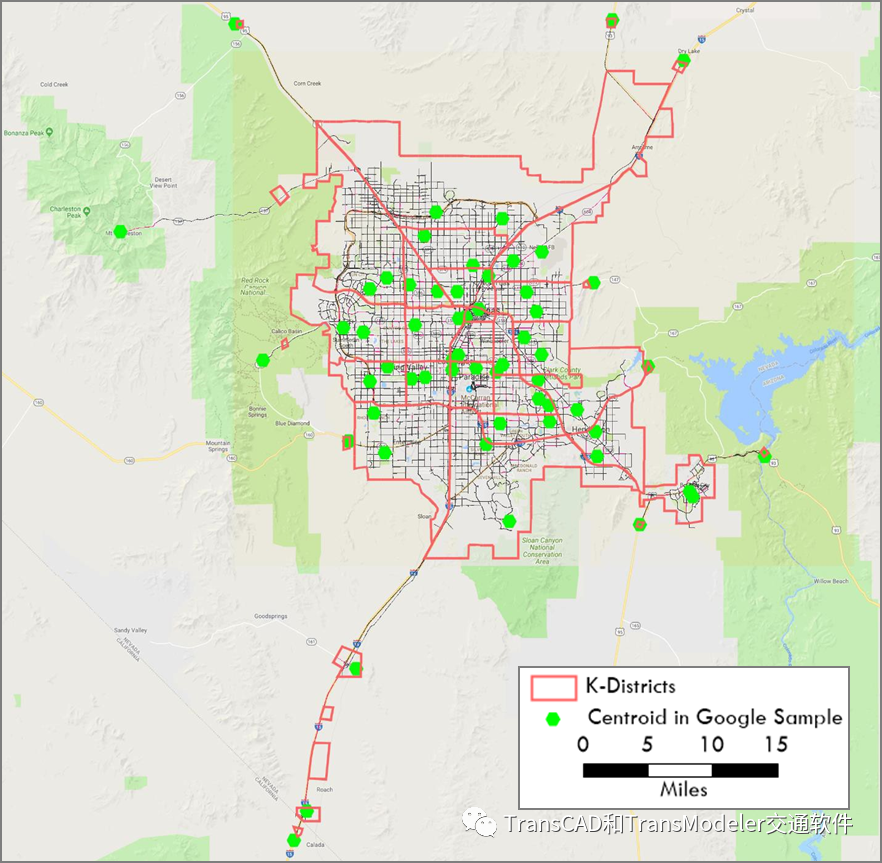
谷歌出行时间抽样的TAZ形心分布 然后,我们在AM和PM模型期间每半小时查询一次出行时间,其中59个形心作为起点,1658个形心作为终点(97822个OD对)。
因此,查询了97822个OD对的8个出发时间:7:00 AM、7:30 AM、8:00AM、8:30 AM、2:00 PM、2:30 PM、3:00 PM、3:30PM、4:00 PM、4:30 PM、5:00 PM和5:30 PM。
由于无法查询过往的数据,我们查询了一个典型的春天的日期,2019年4月10日,星期三。 我们还查询了2019年7月17日(星期三)的一些数据(7:30AM、8:00 AM、4:00 PM、4:30 PM、5:00 PM、5:30PM),以查看全年出行时间是否波动。
我们发现,出行距离在68-75%的时间内保持完全相同,这表明谷歌在这两个月内可能采用了相同的路径。当出行距离相同时,4月和7月的出行时间非常相似,如下图中的散点图所示。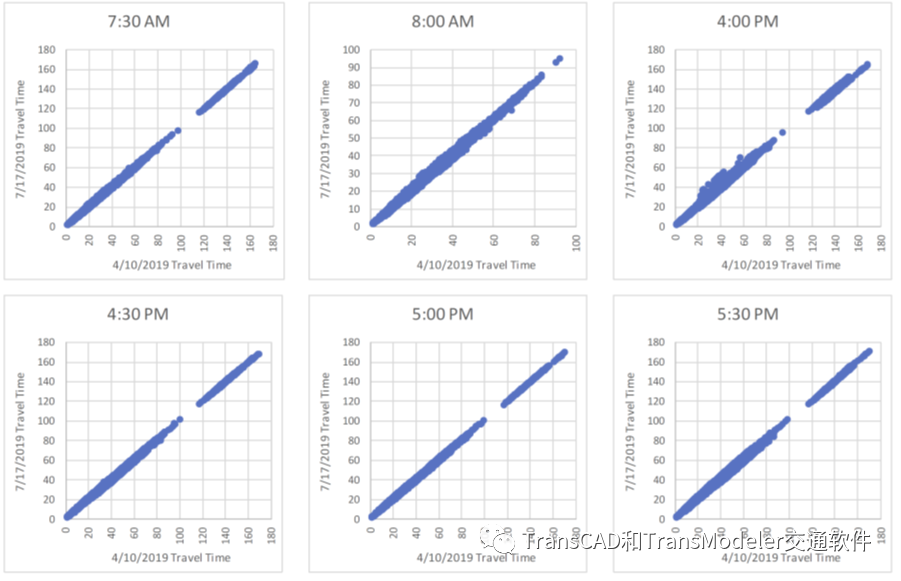
谷歌相同出行距离下不同日期出行时间散点图 即使在出行距离不同,出行时间仍然非常相似,只有少数出行时间明显不同。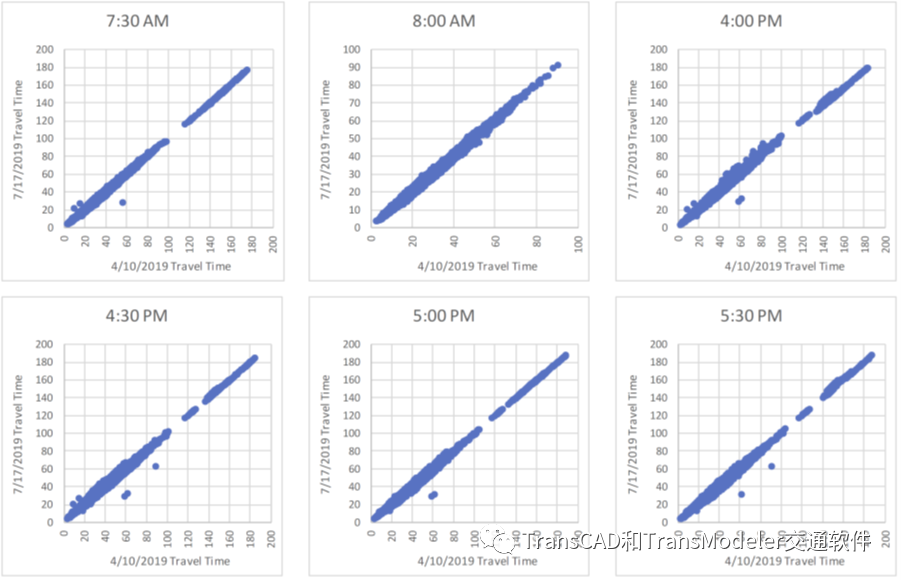
谷歌不同出行距离下不同日期出行时间散点图 谷歌出行时间的样本被缩小到内部之间(I-I)OD对,根据谷歌和模型,这些OD对的整个路径都将穿过模型内的路段。
考虑到这一点,在各自的15分钟出发间隔内,88%的AM仿真OD对和87%的PM仿真OD对具有相应的Google出行时间可供比较。所得散点图见第4节模型验证。
2.8 GTFS数据
为了代表2015年的公交服务,并导入了公交服务ID4_merged_35727228,该公交服务从2015年2月份22日运行到2015年11月7日。这导致212条公交线路被添加到网络中,如下图所示。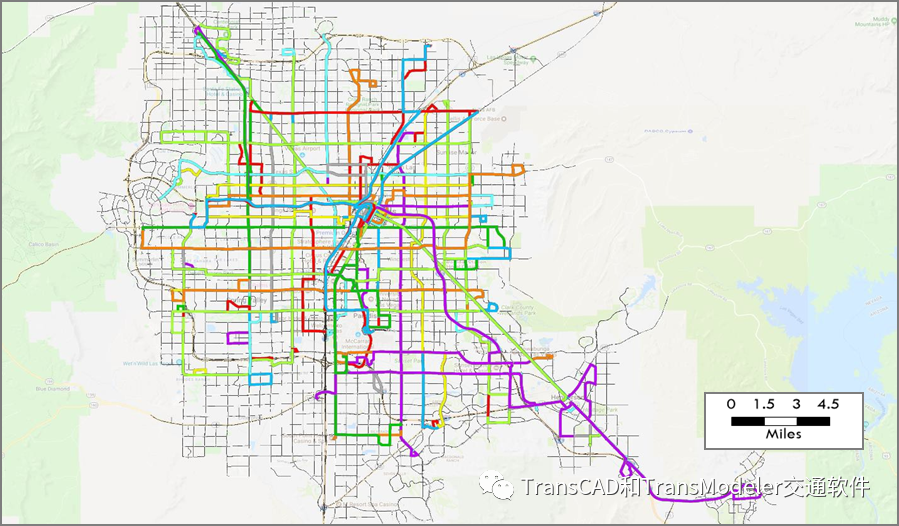
GTFS数据导入的公交线路
2.9 TransDNA模型开发
对于TransDNA中的中观DTA,从TransModeler中为DTA开发的仿真网络中导出了一个线图层,如第2.3节所述。因此,线图层包含TransCAD规划模型中的所有路段,但添加了支持仿真和DTA所需的相同路段和形心连线细节。换句话说,对TransModeler网络所做的所有几何增强都反映在TransDNA线图层中。
这些增强功能包括在线图层中添加字段,以表示左、右转向岛的存在、转向岛车道的数量和转向岛长度。这些字段是TransDNA的重要输入,在这些字段中,当车道配置发生变化时,无需拆分路段,就可以合理地捕捉到转向岛对交通流的影响。
将交叉口几何图形表示为线图层属性还具有最小化网络中路段数量的优点,从而实现了低运行时间的仿真。更多的路段会增加运行时间,因为它们会降低最短路径计算的速度,随着经过的节点数量的增加,最短路径的计算需要更长的时间,并且在DTA过程中会执行多次,以便随着拥堵模式的演变更新路径选择。
3、模型校准
TransModeler DTA模型的校准和验证旨在实现:(1)DTA模型及其基础交通流模型能够反映2015年状况,包括区域交通模式和瓶颈位置,以及(2)确认模型编码正确,信号配时估计和形心连通性合理。这项工作的关键结果,如随时间变化的起点-终点(OD)流量,被用作TransDNADTA模型的输入。
3.1驾驶员行为调整
3.1.1车辆类别分布
车辆类别分布定义了要仿真的车辆类型(例如,汽车、SUV/皮卡、卡车等)的组合。2013年道路车辆类别研究的数据用于计算AM和PM高峰期车辆类别分布。
3.1.2高速公路出入口处罚
TransModeler具有路径选择参数,可为进出高速公路的车辆指定惩罚。这些参数旨在阻止可能在出口匝道离开高速公路并立即返回入口匝道的路径。然而,这些惩罚也可以阻止合理的路径选择,例如进入高速公路的路径在下一个出口匝道离开之前只能在高速公路上行驶很短的距离。在我们的校准工作中,我们发现主干道与高速公路相比利用不足。为了平衡对利用高速公路和当地路网的道路的需求,高速公路罚款增加到出口60秒,入口120秒。
3.1.3形心连线出行时间误差
与所有区域模型一样,微观仿真模型不模拟TAZ内的交通,因此可能无法准确描述起点形心处的出行起点,也无法准确描述终点形心处的出行终点。在某些TAZ中,存在大量形心连线。起点和终点处的形心连线必须根据权重随机分配,该方法存在各种问题(例如,在某些情况下可能会导致不可行或不合理的路径),或选择作为路径选择计算的一部分。
与路段上的出行时间和延误一样,出行时间可以分配给形心连线,并且这些出行时间可以类似地随机扰动。随机误差越大,该TAZ周围加载(或卸载)点的交通分布越广。随机误差越低,路径选择将有利于TAZ中的少量形心连线,从而使一些形心连线未使用的可能性越大。
为了鼓励在一个TAZ内的加载点之间更广泛地分布交通,一般情况下,形心连线的出行时间为5分钟。特定形心连线有时被分配的出行时间大于或小于该出行时间,以鼓励或阻止使用。 特定形心连线相对于服务于相同形心的其他连线。此外,形心连线出行时间误差(定义为形心连线行驶时间的百分比)设置为50%。
这意味着,例如,模型中的任何给定驾驶员可以感知形心连线上的行驶时间,5分钟的行驶时间在2.5到7.5分钟之间。高误差意味着允许足够的变化,以克服在紧邻形心连线的加载点下游的交通信号处可能经历的延误。这样,形心连线的选择不会完全受形心附近路段上延误的影响。
3.1.4 I-15快车道的用户A
I-15快车道是沿I-15高速公路的平行车道,从撒哈拉大道延伸至Silverado牧场大道。驾驶员只能在特定位置进出快车道。使用快车道的选择被建模为寻求最小化出行时间的随机最短路径模型。当存在平行路线且出行时间相似时,例如使用快车道或不使用快车道所代表的时间,模型很难以现实的方式在两条路径之间分配车辆。
为了解决这个问题,我们将所有车辆中的75%指定为用户A车辆,并为用户A的车辆保留I-15快车道。用户A车辆有资格使用快车道,但也可以选择使用通用车道。这确保了快车道的需求不会超过车道的容量,但也保留了路径选择模型为车辆选择路径的能力。
3.2基于仿真的动态交通分配
与传统静态分配相比,DTA的主要优势在于详细处理了不同时间和不同地点拥堵的形成和缓解方式。拥堵发生的时间和地点在很大程度上取决于出行出发时段和分布方式。 路径选择行为是DTA模型的核心,因此也是模型校准的核心。在考虑根据DTA的模型流量与现场观察到的流量之间的拟合之前,重要的是考虑如何确定DTA中的模型体。
DTA模型交通量最终取决于驾驶员做出的路径选择决定,这是发车时间和网络中预期出行条件的函数。预期的出行条件来自于模型中所有出行者的路径选择以及由此产生的拥堵模式。为了模拟合理的路径选择,驾驶员必须了解他们在出行中预计经历的拥堵出行时间。
这些出行时间不是先验已知的,因此是根据感兴趣时段(例如AM、PM)的微观交通仿真来估计的。 因此,整个周期的微观仿真是迭代执行的,连续平均(MSA)方法应用于输出出行时间和迭代之间的转向延误。每次运行的路径选择是上一次仿真和平均出行时间的函数。
该迭代DTA框架的主要目标是平衡路径选择,以使驾驶员在模型充分收敛时无法切换到替代路径并改善其出行时间,这是用户平衡(UE)的一种形式。 出行时间被平均化,以便在迭代中平滑它们,以防止从一个迭代到下一个迭代在好的和坏的路径之间来回切换效率低下。
DTA一直运行,直到它收敛到目标间隙,定义为上一次迭代的出行时间和延误与当前迭代的出行和延误之间的均方根误差(RMSE)百分比,或者直到达到最大迭代次数。 然而,在基于仿真的DTA应用中,通常依赖最大迭代次数而不是目标间隙作为停止运行标准。
因为仿真模型是随机蒙特卡罗模拟(即,每个仿真都是用不同的随机种子启动的,并且会产生不同的结果),并且因为车辆出行是整数(即,它们不能像静态交通分配方法那样被分成很小的部分),可能无法实现高质量静态交通分配所期望的数量级的目标间隙。
考虑到在基于仿真的环境中,目标间隙的相关只是趋势,而不是绝对值,唯一相关的问题是运行DTA,直到目标间隙无法进一步缩小。在基于仿真的DTA应用中,通常认为在大约50次迭代中收敛是足够的。 执行DTA后,可以轻松浏览、查看和检查模型中使用的路径是否合理。在OD对之间目视观察到的路径以及通过选定关键路段的路径都满足先验预期。通过DTA迭代,从路径选择集合中筛选出不合理的路径。 DTA中不仅消除了糟糕的路径选择,而且路径选择也因出发时间而异。
路径选择是随机的、动态的路径选择,使得每个驾驶员对出行时间的感知不同于其他驾驶员,并且驾驶员在给定路段上期望的平均出行时间取决于沿着路径到达路段的时间。在模型中,从一个时间间隔的中点到下一时间间隔的出行时间以分段线性方式表示。因此,路段上的预期出行时间在时间上连续变化,而不是像直方图中那样不连续变化。
3.3动态OD矩阵估计(DODME)
运行DTA并估计行驶时间和转向延误后,可以进行模拟,以确定研究区域内路段的模拟交通量和速度与每15分钟间隔内的观测流量和速度的匹配程度。DTA之后是动态OD矩阵估计(DODME)的应用,该过程模拟全峰值周期,计算15分钟间隔内整个观测流量和速度位置的相对均方根误差(RMSE),在15分钟内通过的流量观测和速度位置,对每一次观测流量与速度匹配程度进行评分,并在得分最差的出行中执行以下方式之一: (1)出行移除 (2)出行克隆 (3)出发时间提前15分钟 (4)出发时间调整15分钟后 可以对移除、克隆或转移的出行类型设置条件,以限制DODME并将人工智能应用于自动化程序。
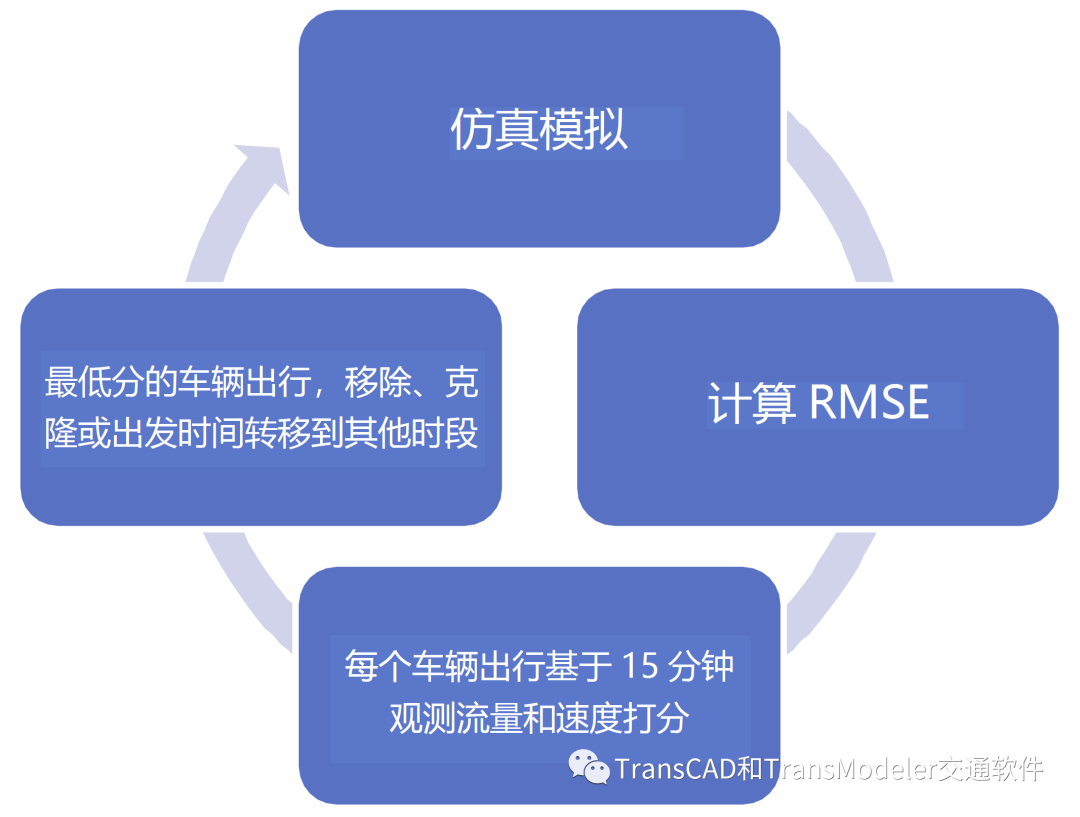
DODME迭代过程 在DODME的每个应用程序中,都会进行多次迭代,并以可能提高观测流量匹配性的方式调整需求。当判断需求发生重大变化时,再次运行DTA,以更新预期的出行时间和转向延误,并实现需求变化与路径选择所依据的拥堵模式之间的一致性。 因此,重复应用DTA和DODME,直到总体相对RMSE没有进一步改善。
3.4校准结果
将模型中15分钟间隔内的路段交通量和速度与可用交通数据(如第2.5节交通流量观测数据和第2.6节速度数据所述)进行比较,以评估模型的拟合程度。 百分比均方根误差(%RMSE)通常用于统计分析,以将模拟交通量与实际交通量进行比较。%RMSE反映了单个路段上的模型流量和观测流量计数之间的差异(与总和的差异),还提供了与观测流量相关的误差大小的信息。
在比较模型流量和观测流量时,%RMSE值通常在10%和100%之间。低%RMSE值通常反映与交通量非常相似的模型交通量,而高%RMSE则反映相反的情况。完整的%RMSE结果汇总如下表所示。
| %RMSE | 观测流量 | |
| AM | ||
| 全部 | 31.1% | 11,536 |
| 高速公路 | 23.8% | 3,408 |
| 干道 | 34.4% | 6,416 |
| PM | ||
| 全部 | 29.9% | 23,544 |
| 高速公路 | 25.8% | 6,880 |
| 干道 | 29.4% | 13,216 |
为了进一步支持DTA模型与观测流量数据的拟合度,将DTA模型的交通量与所有道路的观测流量进行了比较。在这些散点图中,每个点的x值表示15分钟的观测流量,y值表示15小时的模型流量。如果模型流量始终等于观测流量,则所有点将直接位于对角虚线上。位于对角线下方的点是模型流量低于观测流量。
位于对角线上方的点是模型流量高于观测流量。散点图显示,模型分配的流量和观测流量之间有相当好的一致性,模型流量总体略低于观测流量。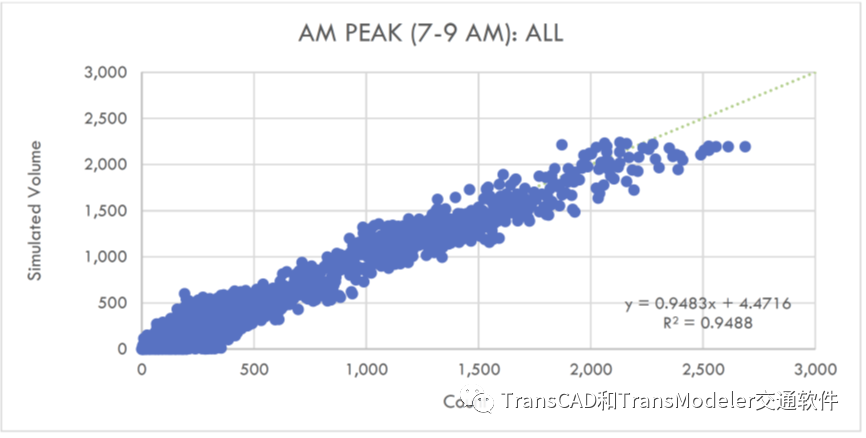
早高峰所有路段DTA模型和观测流量散点图
晚高峰干道DTA模型和观测流量散点图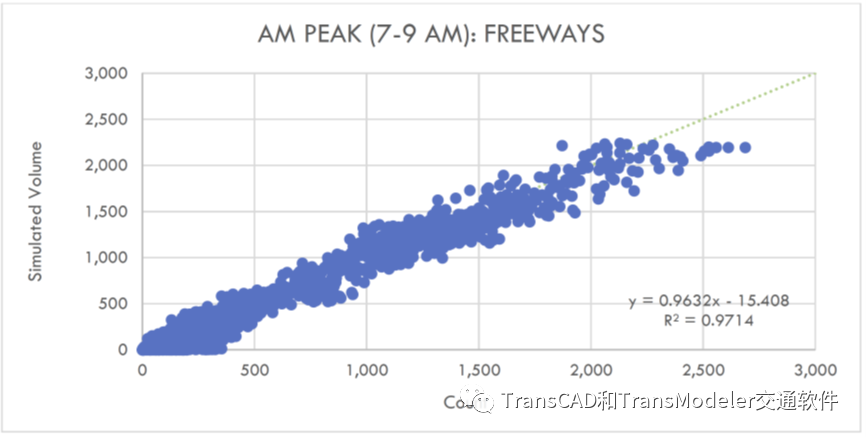
早高峰高速公路DTA模型和观测流量散点图
3.5 TransDNA模型校准
TransDNA是一种基于中观仿真的DTA模型,它与TransModeler DTA等微观模型共享时变需求输入需求。此外,中观DTA模型的校准涉及供给侧输入和速度密度参数的估计/调整。中观仿真模型的供给校准涉及按路段等级指定速度密度函数和通行能力。
拉斯维加斯的OD需求是从TransModeler开发的校准微观仿真模型中获得的。路径选择系数、速度密度函数和通行能力采用了TransDNA中提供的默认值。这些参数是根据我们的文献综述以及基于现场传感器数据的校准。 下图显示了AM峰值(700)模型与观测交通量数据的拟合示例。
每个图表将观测观测观测到的流量(在水平轴上)与模型的相应输出(在垂直轴上)在该峰值内的15分钟时间间隔进行比较。红色虚线表示完美拟合目标,而蓝色虚线表示实际数据的线性回归。虽然这些代表了一个合理准确的模型,但应注意的是,进一步校准(尤其是OD需求侧)将对模型有益。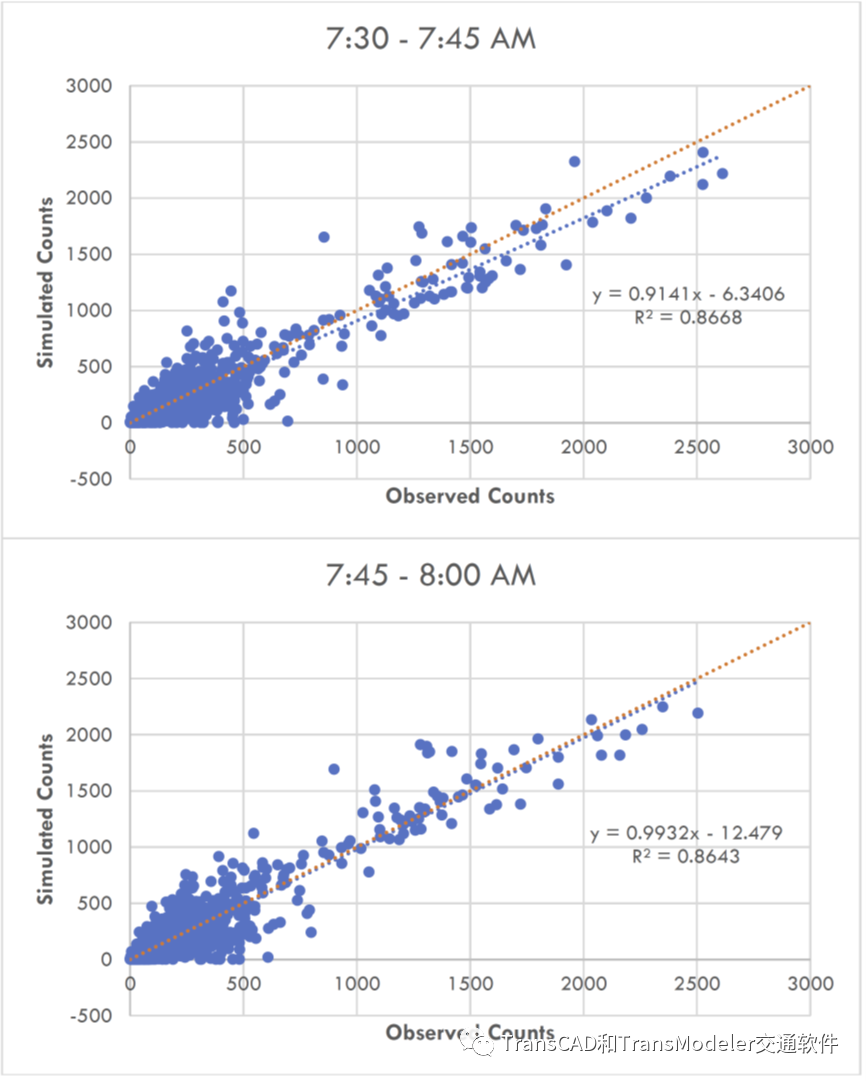
早高峰DTA模型和观测流量散点图
4、模型验证
校准过程完成后,通过将仿真出行时间与Google出行时间进行比较,验证TransModeler DTA模型。验证的目的是建立模型中的仿真出行时间与谷歌为分布在整个地区的OD对的大样本估计的出行时间之间的拟合度。 如第2.7节所述,查询了2019年4月10日(星期三)典型春季的谷歌出行时间数据。
理想情况下,将获得2015年(模型的校准年)的出行时间数据,以进行验证。然而,历史出行时间数据不可获取,谷歌的Directions API只能查询未来日期,尽管其结果基于历史数据。 通过生成整个网络的动态Skim矩阵来获得仿真出行时间,该矩阵按每个OD对的出发间隔汇总仿真出行时间。
在上午高峰时段,获得了四个15分钟出发时段的Google出行时间:7:00 AM、7:30AM、8:00 AM和8:30 AM。Google出行时间与仿真出行时间进行了比较。 在下午高峰时段,谷歌获得了8个15分钟出发时间:下午2:00、下午2:30、下午3:00、下午3:30、下午4:00、下午4:30、下午5:00、下午5:30。谷歌出行时间与仿真出行时间进行了比较。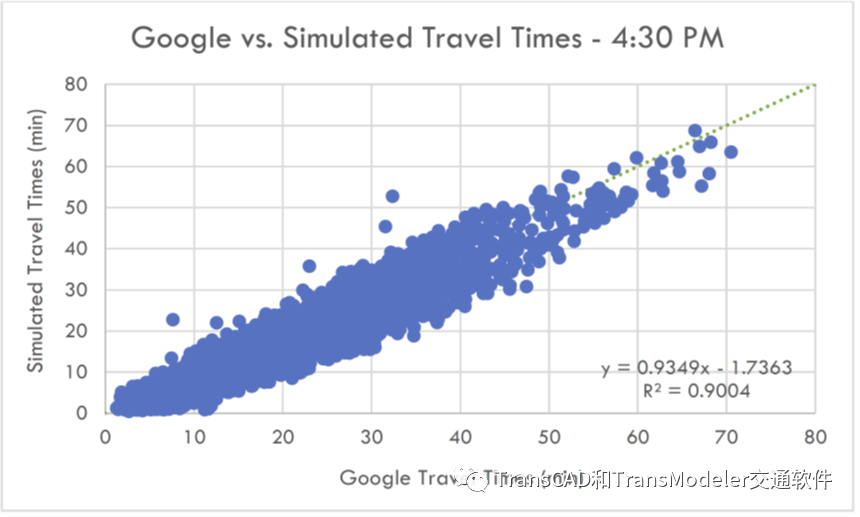
晚高峰谷歌出行时间和仿真出行时间散点图 上面只给出一个样例图表。完整的每个图表都显示了最适合数据的回归线方程以及确定系数R2,这是数据与回归线拟合程度的统计度量。与第3.4节中的图表类似,如果仿真出行时间始终等于谷歌出行时间,则所有点都将直接位于对角虚线上,该线的斜率将为1.0,R2值将为1.0。
R2值是数据与给定斜率的回归线拟合程度的统计度量。对角线下方的点是仿真出行时间比谷歌预测的出行时间短的出行。对角线上方的点是仿真出行时间大于谷歌出行时间的出行。图表表明,在几乎所有时段,仿真时间都非常接近对角线,R2值非常高,斜率接近1.0。
5、模型应用说明
5.1选择正确的DTA进行分析
当您希望使用DTA分析项目或方案时,选择正确的DTA非常重要:TransModeler中基于微观仿真的DTA或TransDNA中基于中观仿真的DTA。选择将在很大程度上取决于两个广泛的问题,理想情况下按以下优先顺序提出: 有效执行分析需要什么样的敏感性?什么时间和资源可用于执行分析?
首先,如果项目涉及交通控制(即交通信号或匝道信号控制i)、智能交通系统(ITS)或先进的交通需求管理策略(ATMS),那么基于微观仿真的DTA将提供更好的运行条件处理,从而提供更好的分析工具。同样,如果该项目需要对高速公路进行重大改进,从而改变合流或交织运行,那么微观仿真也将提供更准确的效益量化,因为中观模型采用了更集计的方法来分析对高速公路设施交通流至关重要的合流和交织相互作用。
其次,如果分析只要求快速得到接近项目的效益,例如测试可行性或将很多备选方案排除为少量备选方案,以便随后进行更详细的研究,那么TransDNA中的中观DTA是推荐的选择,因为相对于TransModeler中的微观DTA,其设置和运行时间较少。
5.2 TransModeler中小子区域的微观仿真
值得注意的是,如果特定分析涉及相对本地化的项目——例如,互通式立交或交叉口几何设计,甚至是走廊沿线的加宽项目——那么基于微观仿真的分析可能具有成本效益,并将提供更好(即更准确)的分析。然而,运行区域DTA可能不合适。
相反,建议从区域模型中提取一个较小的研究区域并用于分析。可以在“路段”图层中选择路段并将其导出到新的仿真数据库。执行此操作时,TransModeler将提示您在此时导出子区域的信号配时。要提取对同一选择集路段的需求估计,请选择“仿真”>“选项”并选中“报告子区域O-D和动态Skim数据”,然后从“选择”下拉列表中选择选择集。
然后,运行仿真以生成子区域OD矩阵。如果需要对分析有高度的信心(即,分析将支持投资决策或工程设计,而不是简单地回答规划问题),子区域模型应进行校准和验证,以细化为子区域导出的数据,以改善子区域模型与观察值的匹配,就像任何微观仿真研究一样。
5.3未来年情景OD矩阵创建
对于未来几年的交通需求估计,尚无既定的实践,但研究文献中已经提出了几种方法并在实践中使用。这些方法通常被称为pivot-point方法,校准的基准年矩阵用于从预测年出行需求模型产生的未经调整的出行表Vf,pivot到预测年经调整的出行表Vf,adj。
最简单的pivot-point模型基于基准年模拟需求Vb,sim与未调整基准年需求Vb之比,对未调整预测需求Vf进行修正: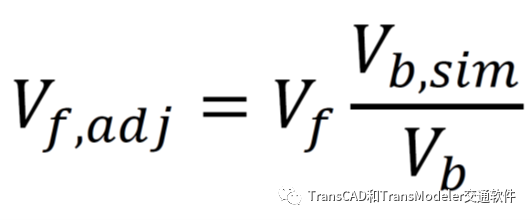
TransCAD和TransModeler中的标准矩阵操作可以使用矩阵菜单中的命令执行,以计算调整后的预测出行表。在TransModeler和TransDNA DTA模型中,Vb,sim表示输入到这些模型的校准出行表,Vb表示TransCAD中RTC出行需求模型产生的基准年(即2015年)出矩阵,Vf表示出行需求模型也产生的预测年出行矩阵。
此外,由于出行需求模型产生的预测交通量Vf将是静态的单时段需求,因此可以假设DTA模型中的动态(即15分钟)出行矩阵中反映的时间分布相同。 由于没有制定区域DTA模型动态预测出行表的标准实践,建议RTC考虑进一步的研究,以确定哪种pivot方法最有效,和/或探索应用DTA的项目中的各种pivot方法,以获得替代方法的直接项目经验。
审核编辑:刘清
-
Transography美国数据产品为交通建模和分析提供准确性2023-09-05 1804
-
DTA和应对不确定性的EMA简析2023-04-17 2737
-
基于TransModeler软件的精细化交通设计2022-08-20 3481
-
TransCAD网页版系统要求2022-08-03 2585
-
TransModeler SE和TransModeler的对比2022-07-25 1704
-
如何应用使用TransCAD和TransModeler迅速开展一个区域路网的仿真2022-07-21 4874
-
TransCAD图像注册的应用方法2022-05-30 4228
-
多模式多用户交通分配模型的详细功能2022-04-11 4459
-
TransCAD/TransModeler交通影响分析2022-04-06 4655
-
TransCAD模型一键运行工具介绍2022-04-02 5385
-
基于量子进化算法求解动态交通分配模型陈华程2017-03-16 856
-
交通分析仿真软件的研究2011-07-26 777
-
CORBA技术在动态交通分配系统中的应用2006-03-24 1362
全部0条评论

快来发表一下你的评论吧 !
