

DS31256 PCI总线利用率
描述
本应用笔记解释了如何计算DS31256 HDLC控制器的总线带宽。显示了实验室测试示例。总线利用率计算器电子表格已解释,可应要求提供。
概述
DS31256 HDLC控制器访问PCI总线,在发送和接收HDLC数据包时获取和存储这些数据包。本应用笔记解释了如何计算DS31256正常工作所需的可用总线带宽。本应用笔记中使用的术语将在一开始就定义。
根据本应用笔记中提供的信息,用户可以修改计算器电子表格中的数字(可根据要求提供),以适应其特定应用。
| 变量 | 定义 | 有效范围 |
| B | 主机更新接收空闲队列和传输挂起队列或读取接收完成队列和传输完成队列之前处理的平均数据包数 | 1, 2, 3, . . . . |
| C | 每个数据包所需的平均总线周期数 | 1, 2, 3, . . . . |
| D | 传输数据所需的总线周期数 | 1, 2, 3, . . . . |
| P | 数据包大小(以字节为单位) | 64 |
| R | 由于 RAM 访问延迟而增加的平均总线周期数 | 0, 1, 2, . . . . |
| X | 向数据缓冲区发送或获取数据包数据所需的平均总线访问次数 | 1, 2, 3, . . . . |
巴士访问的类型
DS31256或主机执行四种类型的总线访问,以支持DS31256中的直接存储器访问(DMA)。在下面的描述中,变量 D 定义为数据周期数,变量 R 定义为由于 RAM 访问延迟而需要的总线周期数。
访问类型 1:DMA 从主机 RAM 突发读取
从主机 RAM 读取 DMA 突发时所需的总线周期总数为 [3+R+D]。该公式由图1和表2推导出来。
| 周期 | 不。所需周期 |
| 地址周期 | 1 |
| 周转周期 | 1 |
| 内存访问延迟周期 | R |
| 数据周期 | D |
| 周转周期 | 1 |
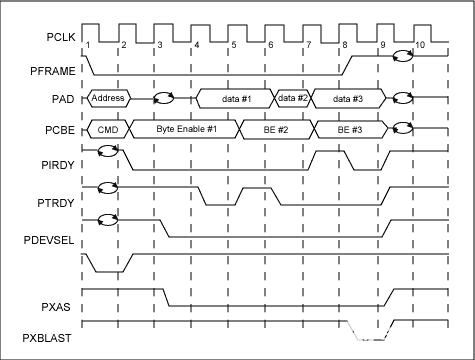
图1.DS31256 PCI总线读取
访问类型 2:DMA 对主机 RAM 的突发写入
DMA 突发写入主机 RAM 时所需的总线周期总数为 [2+R+D]。该公式由图2和表3推导而来。
| 周期 | 不。所需周期 |
| 地址周期 | 1 |
| 内存访问延迟周期 | R |
| 数据周期 | D |
| 周转周期 | 1 |
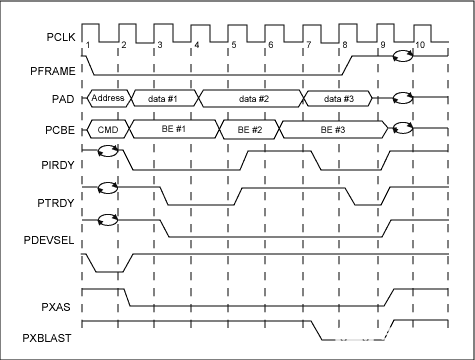
图2.DS31256 PCI总线写入周期
访问类型3:由主机写入DS31256
主机写入DS31256时所需的总线周期总数为7。
访问类型4:主机读取DS31256
主机从DS31256读取数据时所需的总线周期总数为7。
注意:对于访问类型3和4,7周期访问是DS31256固有的,不能更改。
每个数据包所需的总线周期数
要计算总线利用率,必须知道所需的总线周期数。为了获得这个数字,做了几个假设,并在表4中列出。图 3 显示了主机和 DMA 对于接收或传输的每个数据包将遵循的标准序列。从图3中,可以创建一个公式来计算每个数据包所需的平均总线周期数,即变量C。
传输侧
发送端周期 = 读挂起队列 + 写水平描述符链 + 读描述符 + 从主机内存读取数据包 + 写完成队列 + 读/写寄存器。
Ct = [(3 + R + 12)/12] + [2 + R + 1] + [3 + R + 4] + [(P/4) + (3 + R)X] + [(2 + R + 6)/6] + [4(7/B)]
接收端
接收端周期 = 读取空闲队列 + 将数据包写入主机内存 + 写入描述符 + 写入完成队列 + 读/写寄存器。
Cr = [(3 + R + 24)/12] + [(P/4) + (2 + R)X] + [2 + R + 3] + [(2 + R + 6)/6] + [4(7/B)]
总公式
Ct + Cr = 21.16 + 3.5R + 0.5P + (5 + 2R)X + 56/B
| 1 | 所有数据包均为 64 字节(被视为最坏情况)。 |
| 2 | HDLC 数据包的帧校验序列 (FCS) 不会传输到 PCI 总线或从 PCI 总线传输。 |
| 3 | 在接收端,仅使用大型缓冲区(禁用小型缓冲区)。 |
| 4 | 接收 DMA 将突发读取空闲队列并突发写入已完成队列。 |
| 5 | 传输 DMA 将突发读取挂起队列,并突发写入已完成队列。 |
| 6 | 所有数据包都适合单个缓冲区(即只有一个描述符)。这是合理的,因为数据包是 64 字节。 |
| 7 | 所有物理层链路都充满了数据包;不发送或接收空闲代码。 |
| 8 | 不考虑中断例程和开销(如对本地总线的访问)。 |
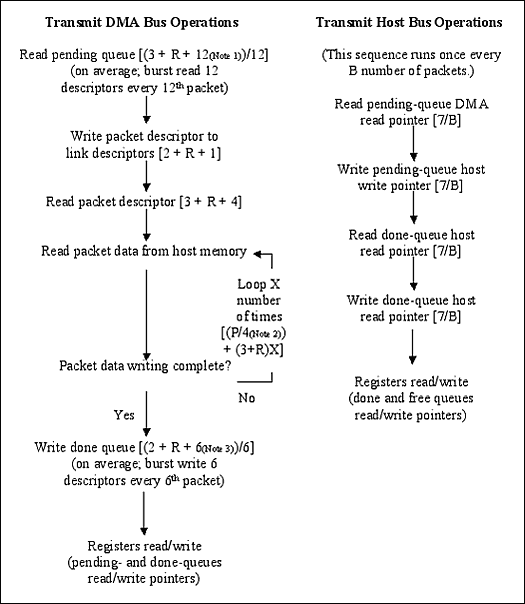
图3.每个数据包的总线周期流程图。
笔记:
12 个描述符 x 1 个双字 = 12 个传输挂起队列描述符双字
数据包数据(以字节为单位)= 4 字节/数据周期
6 个描述符 x 1 个双字 = 6 个传输完成队列描述符双字
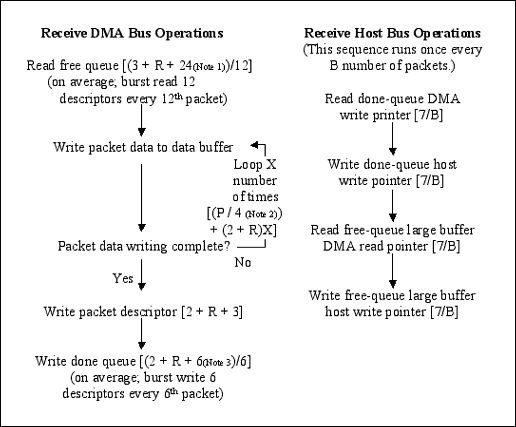
图3.(续)
笔记:
12 个描述符 x 2 个双字 = 24 个接收自由队列描述符双字
数据包数据(以字节为单位)= 4 字节/数据周期
6 个描述符 x 1 个双字 = 6 个接收完成队列描述符双字
PCI 总线利用率
总线利用率定义为DS31256每秒所需的总线周期数除以每秒可用的总线周期总数。可以针对特定的 HDLC 配置和流量负载计算总线利用率。计算假设PCI总线时钟速率为33MHz(33,000,000Hz),并且使用一个DS31256。以下是 PCI 总线利用率的详细计算。
公式 1:
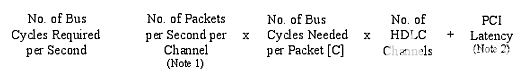
公式2:
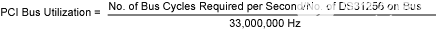
笔记:

例子
PCI总线利用率实验室测试是为了表征DS31256的PCI总线利用率。假设所有传入和传出数据包的长度均为 56 字节 (P = 56)。结果总结在表5中。可根据要求提供计算总线利用率的电子表格(如表 6 所示)。(请联系模拟技术支持团队)
| B | P | R | |||||||
| 模式 | 不。端口数量 | 平均编号已完成队列 已处理的条目 | 像素大小(字节) | 平均内存访问延迟周期 | 不。的高密度LCC通道 | 合计编号频道数量 | 通道数据速率(千字节) | PCI 时钟速率 (兆赫) | PCI 总线利用率(%) |
| 高速 | 3 | 14.17 | 56 | 8.35 | 1 | 3 | 52 | 52 | 47.55 |
| 非通道化 | 3 | 35.53 | 56 | 8.50 | 1 | 3 | 29 | 29 | 49.06 |
| 低速 | 16 | 100.46 | 56 | 10.60 | 1 | 16 | 12 | 12 | 55.27 |
| 非通道化 | 16 | 24.30 | 56 | 10.24 | 1 | 16 | 10 | 10 | 52.54 |
| T1 | 16 | 8.081 | 56 | 7.1375 | 12 | 192 | 128 * | 1.544 | 18.26 |
| E1 | 16 | 8.154 | 56 | 7.8645 | 16 | 256 | 128 | 2.048 | 28.07 |
| 2E1 | 16 | 10.894 | 56 | 8.003 | 16 | 256 | 256 | 4.096 | 55.82 |
| 4E1 | 16 | 381.207 | 56 | 8.3123 | 8 | 128 | 1024 | 8.192 | 50.97 |
|
*笔记: 每个 T1 帧有 193 位 = [(24 个时隙 x 8 位)+ 1 个同步位]。 每个时隙的数据速率为 64,000 位/秒。 (64,000 位/秒)/8 位 = 8,000 帧/秒 T1 帧将每 125 微秒到达一次 =1/(8,000 帧)/秒。 数据速率为 1,536,000 位/秒 = 24 通道 x(8 位/通道/帧)x(8,000 帧/秒)。 总线速为 1,544,000 位/秒 = [(24 通道 x (8 位/通道)) + (1 个同步(位/帧))] x(8,000 帧/秒)。 |
|||||||||
| 输入变量 | ||
| B | 14.17 | 主机更新接收空闲队列和传输挂起队列或读取接收/传输完成队列之前处理的平均数据包数。 |
| P | 56 | 数据包的大小(以字节为单位)。 |
| R | 8.35 | 由于 RAM 访问延迟而增加的平均总线周期数。 |
| 每个DS31256的HDLC通道数 | 3 | 在非通道化模式下运行时,每个活动端口使用 1 个。 |
| 通道数据速率(千字节) | 52,000.00 | 请注意,T1 速度 == 1536kbps。 |
| 渠道利用率 | 39.5% | 在实际应用程序中,数据包之间可能有时间。 |
| PCI 时钟速率 (兆赫) | 33 | |
| PCI 延迟/事务 | 10 | 这是基于执行与处理数据包关联的每个事务所需的平均周期数。我们的设计师在模拟中使用了 10,这是相当保守的。 |
| 总线上的DS31256数量 | 1 | |
| 中间变量 | ||
| C | 104.04 | 每个数据包所需的平均总线周期数。 |
| X | 1.00 | 向/从数据缓冲区发送/获取数据包数据所需的平均总线访问次数。 |
| 数据包/秒/通道 | 45,871.43 | |
| 总 PCI 延迟 | 1,376,142.86 | |
| 不。所需总线周期数/秒 | 15,693,122 | |
| 半双工 | 全双工 | |
| 总线利用率 | 47.6% | 95.11% |
| 总线容量(千兆字节) | 264 | |
| 总线吞吐量 (Mbps) | 125.54 | 251.09 |
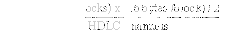
注意:
其中 1024 个块是 FIFO 大小,FIFO 高水位线和低水位线设置为 50%。
结论
本应用笔记解释了如何计算DS31256在给定应用中所需的总线带宽。提供了一些实验室测试示例。可根据要求提供用于执行计算的电子表格。
审核编辑:郭婷
-
DS31256的分数级T1 (FT1)环回检测2023-06-16 2043
-
DS31256 接口 - 电信2023-01-14 129
-
如何利用DS31256 HDLC控制器实现间隔时钟应用2023-01-13 1929
-
DS31256 HDLC控制器的配置步骤—桥接模式2009-04-21 1987
-
DS31256的初始化步骤2009-04-20 1351
-
DS31256的PCI总线利用率2009-04-18 1733
全部0条评论

快来发表一下你的评论吧 !
