

视觉新范式!COCs:将图像视为点集
描述
导读
在本文中,作者回顾了视觉表征的一类经典方法:聚类 (Clustering) 。作者将这种范式称之为上下文聚类 (Context Cluster)。这是一种新的用于视觉表征的特征提取范式。并在多种视觉任务中取得了和 ConvNets,ViTs 相当的性能。
本文目录
1 把图片视为点集,简单聚类算法实现强悍视觉架构 (超高分论文)
(目前匿名,待更新)
1.1 CoCs 论文解读
1.1.1 背景和动机
1.1.2 把图像视为一组点集
1.1.3 CoCs 模型的总体架构和图片的预处理环节
1.1.4 上下文聚类块原理
1.1.5 实验结果
1 把图片视为点集,简单聚类算法实现强悍视觉架构
论文名称:Image as Set of Points
论文地址:
https://openreview.net/pdf%3Fid%3DawnvqZja69
1.1.1 背景和动机
提取特征的方式很大程度上取决于如何解释图像。
在方法上,ConvNets 将图像概念化为一组排列成矩形形式的像素,并以滑动窗口的方式使用卷积提取局部特征。卷积网络非常高效的原因是得益于一些重要的归纳偏置 (inductive bias),如局部性 (locality) 和平移等变性 (translation equivariance)。视觉 Transformer 将图像视为一块块组成的序列,并使用全局注意力操作自适应地融合来自每个 Patch 的信息。这样,模型中固有的归纳偏置被抛弃,并获得了令人满意的结果。
最近,有些工作试图把卷积和注意力机制结合在一起,比如:CMT[1],CoAtNet[2]等,这些方法在网格中扫描图像 (通过卷积,获得局部性的先验),同时探索 Patch 之间的相互关系 (通过注意力,获得全局建模的能力)。虽然它们继承了两者的优点,但其见解和知识仍然局限于 ConvNets 和 ViT。
本文作者研究特征提取器 (Feature Extractor),但是视角不仅仅局限在 ConvNets 和 ViT 上。虽然卷积和注意力机制已经被证明了可以用来构建高性能视觉架构,但它们并不是唯一的选择。其他的选择比如基于 MLP 的模型 ResMLP[3],和基于 GNN 的模型 ViG[4]。因此,作者期待在本文中探索一种新的特征提取范式,它可以提供一些新颖的见解,而不是增量式的性能改进。
在本文中,作者回顾了视觉表征的一类经典方法:聚类 (Clustering) 。总体而言,作者将图像视为一组点集,并将所有点分组为 Clusters。在每个类中,我们将这些点聚集成一个 center,然后自适应地将中心点分配给所有的点。作者将这种范式称之为上下文聚类 (Context Cluster) 。
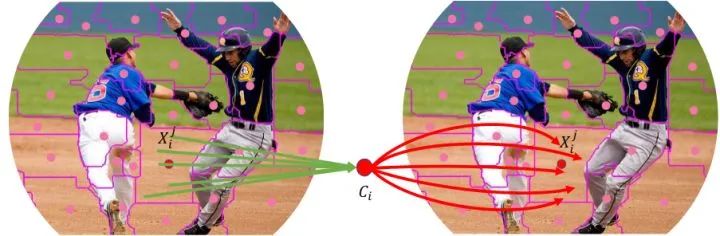
图1:上下文聚类 (context cluster)
如上图1所示,具体而言,作者将每个像素视为一个具有颜色和位置信息的5维数据点。作者将图像转换为一组点云,并利用点云分析的方法用于图像视觉表征。这连接了图像和点云的视觉表征,显示出了强大的泛化性能,也有利于未来的多模态研究。对于一组点,作者引入了一种简化的聚类方法[5],将点分组为一个个类。
作者将基于上下文聚类 (context cluster) 得到的 Deep Model 称之为 Context Clusters (CoCs) 。模型的设计也继承了 ViT 的层次表示和 MetaFormer 的框架。通过将图像视为点的集合,CoC 对不同数据域 (如点云、RGBD 图像等) 具有很强的泛化能力,和比较令人满意的可解释性。尽管 CoC 不以性能为目标,但作者发现在几个基准测试中,它仍然达到了与 ConvNets 或 ViTs 相同甚至更好的性能。
1.1.2 把图像视为一组点集
作为一个通用主干网络的工作,我们首先要明确的一点是:无论作者在鼓吹什么概念,这个网络的每一个 Block 都要做一件事情:就是特征提取 (Feature Extraction)。本文使用的聚类 (Clustering) 操作也不会例外。
在特征提取之前我们先从图像开始。给定一张原始的输入图片 , 作者先对图片的每个像素 增加一个 坐标, 使之成为一个 5 维的向量。其中, 每个位置的坐标可以写成 , 然后将增强后的图像转换为像素点的集合 , 其中 为点的个数, 每个点同时包含特征 (颜色) 和位置 (坐标) 的信息。
这样的表征为图像提供了一个全新的视角,即:把图像视为一组点集,其可以被认为是一种通用数据表示,因为大多数领域的数据可以作为特征和位置信息的组合给出。
1.1.3 CoCs 模型的总体架构和图片的预处理环节
前文提到,无论作者在鼓吹什么概念,这个网络的每一个 Block 都要做一件事情:就是特征提取 (Feature Extraction)。本文作者同样遵循 ConvNets 的方法,利用 Context Clusters Block,提取深层特征。
模型总体架构如下图2所示,每个 Stage 都由点数缩减模块 (Points Reducer Block) 和上下文聚类块 (Context Clusters Block) 组成。
总体而言:
- CoCs 模型的总体架构类似于 Swin,PVT 的金字塔结构。
- Swin 中的图片的预处理环节在 CoCs 里面用的也是卷积。
- Swin 中的 Self-attention 模块在 CoCs 里面用的是上下文聚类模块 (Context Clusters Block) 。
- Swin 中的下采样操作在 CoCs 里面用的是点数缩减模块 (Points Reducer Block) 。
- Swin 中的位置编码是 Add 在图片上的,CoCs 里面用的是 Concat 操作,把3维的 image 搞成了5维的 "augmented image"。
在图片的预处理环节, 给定一组像素点的集合 , 作者首先减少点的数量以提高计算效率, 然后应用一系列 Context Clusters Block 来提取特征。为了减少点的数量, 在空间中均匀地选择一些锚点, 并将最近的 个点 ( 等) 通过线性投影进行拼接和融合。
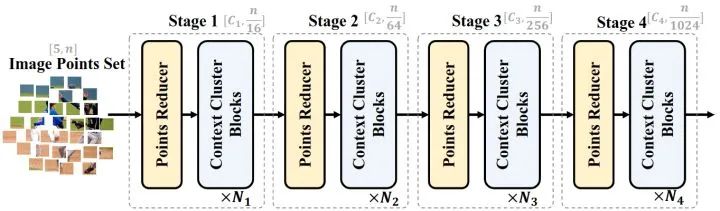 图2:CoCs 模型的总体架构
图2:CoCs 模型的总体架构如何选择锚点呢?如下图3所示,作者展示了16个点和4个锚点,每个锚点都考虑了它最近的4个邻居。所有邻居都沿着通道维度进行 concatenation,并且使用 FC 层来降低维度数并融合信息。在减少点的数量后,会得到4个新的点。这步可以使用 2×2 的卷积实现。
PyTorch 代码如下 (PointRecuder 和 Transformer 类金字塔结构使用的下采样操作是一致的):
class PointRecuder(nn.Module):
"""
Point Reducer is implemented by a layer of conv since it is mathmatically equal.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
 图3:模型一开始选择锚点的方法,很像 ViT 的卷积分 Patch 操作
图3:模型一开始选择锚点的方法,很像 ViT 的卷积分 Patch 操作1.1.4 上下文聚类模块原理
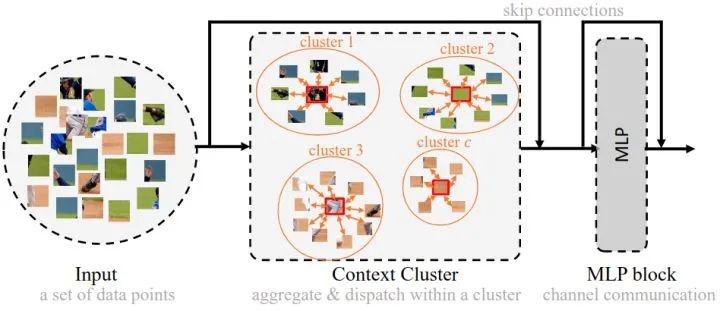 图4:一个上下文聚类 Block
图4:一个上下文聚类 Block本小节介绍 CoCs 的核心:上下文聚类模块 (图4虚线部分) 的原理。总体而言,上下文聚类模块分为两部分:特征聚合 (Feature Aggregating) 和**特征再分配 (Feature Dispatching)**。作者首先将特征点聚类成为 Cluster,然后,每个聚类中的特征点将被聚合,然后再分派回去。
给定一组特征点 , 作者根据相似度将所有点分组为几个组, 每个点被单独分配到一个 Cluster 中。聚类的方法使用 SLIC , 设置 个聚类中心, 每个聚类中心都通过计算其 个最近邻的平均值得到。然后计算成对余弦相似矩阵 和得到的中心点集。完成之后, 作者将每个点分配到最相似的 Cluster 中, 产生 个聚类。值得注意的是, 每个 Cluster 中可能有不同数量的点。极限情况下一些 Cluster 中可能没有点。
特征聚合
现在把目光放在一个 Cluster 内部。假设一个簇包含 个点 ( 的一个子集), 这 个点与聚类中心的相似度为 。作者将这 个点映射到一个 value space 中, 得到: , 其中, 是 value dimension。类似地, value space 中也有一个聚类中心 , 聚合的特征 可以写成:
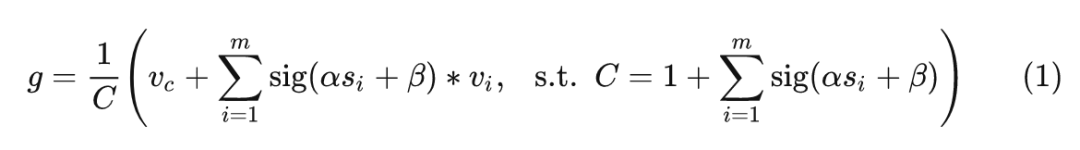
这里 和 是可学习的标量, 用于缩放和移动, 是 Sigmoid 函数, 用于重新缩放相似度到 。 表示 中的第 个点。从经验上看, 这种策略比直接应用原始相似度的结果要好得多, 因为不涉及负值。为了数值的稳定性, 作者在式1中加入了聚类中心 , 和归一化因子 。
特征再分配
然后,聚合的特征 根据相似性自适应地分配到聚类中的每个点。通过这样做,点之间可以相互通信,并共享来自 Cluster 中所有点的特征,方法如下:
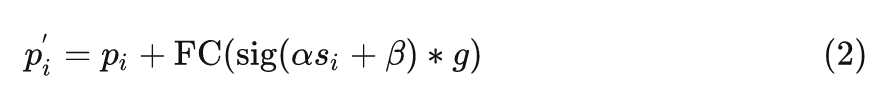
这里,作者遵循和1式相似的做法来处理相似性,并应用一个全连接 (FC) 层来匹配特征维度 (从值空间维度 到原始维度 )。
多头机制
考虑到 ViT 中使用的多头注意力机制,作者在上下文聚类模块中使用了类似的做法,也使用了 hh 个 head,且多头操作的输出由 FC 层融合,发现多头机制也使得模型效果更好。
聚类中心不动?
传统的聚类算法和 SuperPixel 技术都是迭代更新中心直到收敛,但是这将导致过高的计算成本,使得推理时间将呈指数增长。在上下文聚类中,作者固定聚类中心不动,在准确性和速度之间取得妥协。
PyTorch 代码如下 (变量维度我已经在代码中标明):
class Cluster(nn.Module):
def __init__(self, dim, out_dim, proposal_w=2,proposal_h=2, fold_w=2, fold_h=2, heads=4, head_dim=24, return_center=False):
"""
:param dim: channel nubmer
:param out_dim: channel nubmer
:param proposal_w: the sqrt(proposals) value, we can also set a different value
:param proposal_h: the sqrt(proposals) value, we can also set a different value
:param fold_w: the sqrt(number of regions) value, we can also set a different value
:param fold_h: the sqrt(number of regions) value, we can also set a different value
:param heads: heads number in context cluster
:param head_dim: dimension of each head in context cluster
:param return_center: if just return centers instead of dispatching back (deprecated).
"""
super().__init__()
self.heads = heads
self.head_dim=head_dim
self.fc1 = nn.Conv2d(dim, heads*head_dim, kernel_size=1)
self.fc2 = nn.Conv2d(heads*head_dim, out_dim, kernel_size=1)
self.fc_v = nn.Conv2d(dim, heads*head_dim, kernel_size=1)
self.sim_alpha = nn.Parameter(torch.ones(1))
self.sim_beta = nn.Parameter(torch.zeros(1))
self.centers_proposal = nn.AdaptiveAvgPool2d((proposal_w,proposal_h))
self.fold_w=fold_w
self.fold_h = fold_h
self.return_center = return_center
def forward(self, x): #[b,c,w,h]
value = self.fc_v(x)
x = self.fc1(x)
x = rearrange(x, "b (e c) w h -> (b e) c w h", e=self.heads) #[b*heads,head_dim,w,h]
value = rearrange(value, "b (e c) w h -> (b e) c w h", e=self.heads) #[b*heads,head_dim,w,h]
if self.fold_w>1 and self.fold_h>1:
# split the big feature maps to small loca regions to reduce computations of matrix multiplications.
b0,c0,w0,h0 = x.shape
assert w0%self.fold_w==0 and h0%self.fold_h==0,
f"Ensure the feature map size ({w0}*{h0}) can be divided by fold {self.fold_w}*{self.fold_h}"
x = rearrange(x, "b c (f1 w) (f2 h) -> (b f1 f2) c w h", f1=self.fold_w, f2=self.fold_h) #[bs*blocks,c,ks[0],ks[1]] #[b*heads*64,head_dim,w/8,h/8]
value = rearrange(value, "b c (f1 w) (f2 h) -> (b f1 f2) c w h", f1=self.fold_w, f2=self.fold_h) #[b*heads*64,head_dim,w/8,h/8]
b,c,w,h = x.shape #[b*heads*64,head_dim,w/8,h/8]
centers = self.centers_proposal(x) # [b,c,C_W,C_H], we set M = C_W*C_H and N = w*h #[b*heads*64,head_dim,2,2]
value_centers = rearrange(self.centers_proposal(value) , 'b c w h -> b (w h) c') # [b,C_W,C_H,c] #[b*heads*64,4,head_dim]
b,c,ww,hh = centers.shape #[b*heads*64,head_dim,2,2]
sim = torch.sigmoid(self.sim_beta + self.sim_alpha * pairwise_cos_sim(centers.reshape(b,c,-1).permute(0,2,1), x.reshape(b,c,-1).permute(0,2,1))) #[B,M,N] #[b*heads*64,4,w/8*h/8]
# sololy assign each point to one center
sim_max, sim_max_idx = sim.max(dim=1,keepdim=True)
mask = torch.zeros_like(sim) # binary #[B,M,N]
mask.scatter_(1, sim_max_idx, 1.)
sim= sim*mask
value2 = rearrange(value, 'b c w h -> b (w h) c') # [B,N,D] #[b*heads*64,w/8*h/8,head_dim]
# out shape [B,M,D]
# [b*heads*64,1,w/8*h/8,head_dim] * [b*heads*64,4,w/8*h/8,1] = [b*heads*64,4,w/8*h/8,head_dim]
# [b*heads*64,4,head_dim]
out = ( ( value2.unsqueeze(dim=1)*sim.unsqueeze(dim=-1) ).sum(dim=2) + value_centers)/ (mask.sum(dim=-1,keepdim=True)+ 1.0) # [B,M,D]
if self.return_center:
out = rearrange(out, "b (w h) c -> b c w h", w=ww)
# return to each point in a cluster
else:
# # [b*heads*64,4,1,head_dim] * [b*heads*64,4,w/8*h/8,1] = [b*heads*64,w/8*h/8,head_dim]
out = (out.unsqueeze(dim=2)*sim.unsqueeze(dim=-1)).sum(dim=1) # [B,N,D]
# [b*heads*64,head_dim,w/8*h/8]
out = rearrange(out, "b (w h) c -> b c w h", w=w)
if self.fold_w>1 and self.fold_h>1: # recover the splited regions back to big feature maps
out = rearrange(out, "(b f1 f2) c w h -> b c (f1 w) (f2 h)", f1=self.fold_w, f2=self.fold_h) # [b*heads,head_dim,w,h]
out = rearrange(out, "(b e) c w h -> b (e c) w h", e=self.heads) # [b,head_dim*heads,w,h]
out = self.fc2(out) # [b,out_dim,w,h]
return out
1.1.5 实验结果
ImageNet-1K 图像分类
如下图6所示是在 ImageNet-1K 上的消融实验结果。当 Position info. 即位置信息删掉时,模型无法训练了。在没有 Context Cluster 操作的情况下,性能下降了 3.3%。此外,多头设计可使结果提高 0.9%。0.9,weight decay 为0.5,使用了 Exponential Moving Average (EMA)。如下图56所示,CoCs 能够获得与广泛使用的基线相当甚至更好的性能。
通过约 25M 个参数,CoCs 的性能超过了增强的 ResNet50 和 PVT-small 1.1%,并达到 80.9% 的 Top-1 精度。此外,CoCs 明显优于基于 MLP 的方法。这一现象表明,上下文集群模块有助于建模视觉表征。
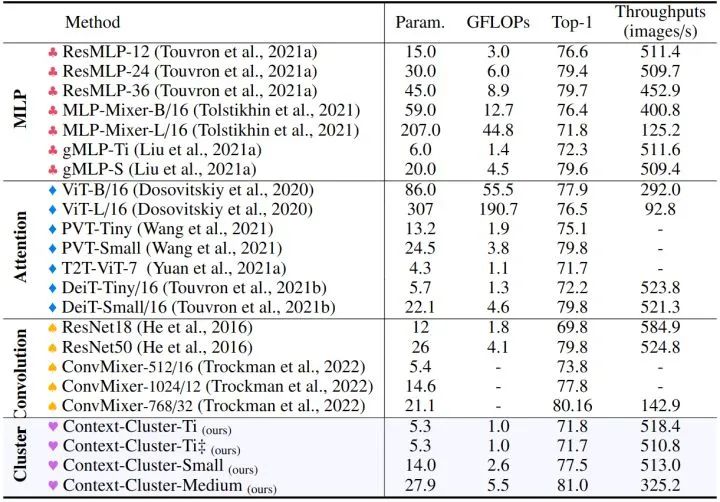 图5:ImageNet-1K 图像分类实验结果
图5:ImageNet-1K 图像分类实验结果如下图5所示是在 ImageNet-1K 上的消融实验结果。当 Position info. 即位置信息删掉时,模型无法训练了。在没有 Context Cluster 操作的情况下,性能下降了 3.3%。此外,多头设计可使结果提高 0.9%。
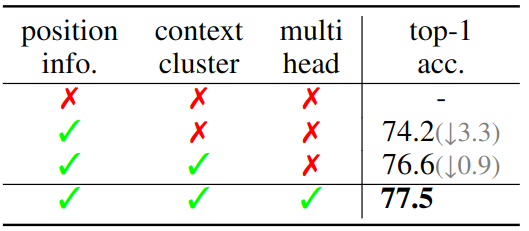 图6:消融实验结果
图6:消融实验结果聚类可视化结果
作者在图7中绘制了 ViT 的注意力图,ConvNet 的 class activation map (i.e., CAM),和 CoCs 的 clustering map。可以看到,本文的方法在最后的 Stage 清晰地将 "鹅" 聚为一个 object context,并将背景 "草" 分组在一起。上下文聚类甚至可以在非常早期的 Stage 聚类相似的上下文。
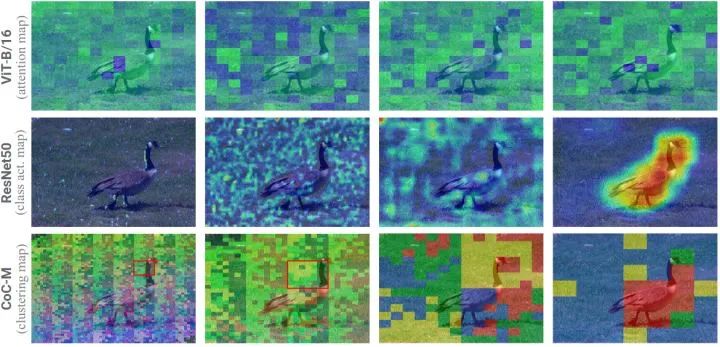 图7:聚类可视化结果,从左到右分别是4个 Stage ([3rd, 6th, 9th, 12th]) 的聚类可视化结果
图7:聚类可视化结果,从左到右分别是4个 Stage ([3rd, 6th, 9th, 12th]) 的聚类可视化结果ScanObjectNN 3D 点云分类实验结果
作者选择 PointMLP 作为模型的基线,因为它的性能和易用性。作者将上下文聚类模块放在 PointMLP 中的每个 Residual Point Block 之前。得到的模型称为 PointMLP-CoC。如下图7所示,作者展示了所有类别的平均准确度 (mAcc) 和所有样本的总体准确度 (OA)。实验结果表明,该方法可以显著提高 PointMLP 的性能,平均准确率提高0.5% (84.4% vs. 83.9%),总体准确率提高 0.8% (86.2% vs. 85.4%)。
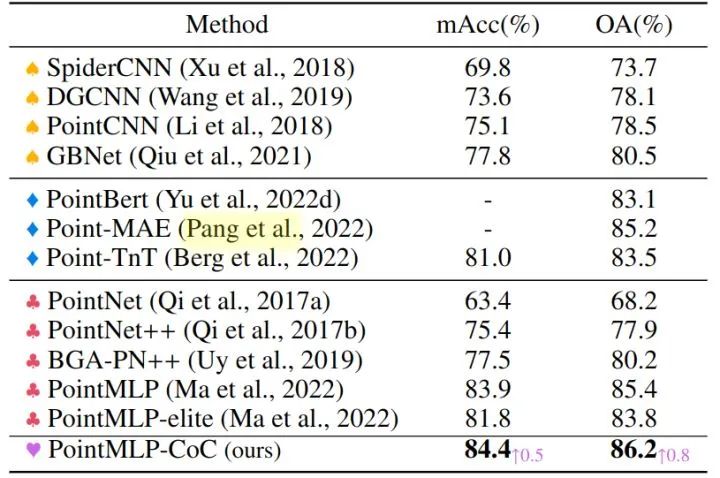 图8:点云分类实验结果
图8:点云分类实验结果MS-COCO 目标检测和实例分割实验结果
接下来,作者研究 Context Cluster 操作对下游任务的泛化性,包括 MS-COCO 目标检测和实例分割。检测头和实例分割头使用 Mask RCNN。所有模型使用 1× scheduler (12 epochs) 进行训练,并使用 ImageNet 预训练权重进行初始化。为了进行比较,作者将 ResNet 作为 ConvNets 的代表,PVT 作为 ViTs 的代表。
对于分辨率为 (1280,800) 大小的图像,检测和分割任务将有 1000 个点。很明显,将1000个点分成4个 Cluster 会产生较差的结果。为此,作者研究了一个局部区域中使用4,25,49个中心,并将得到的模型分别称为 Small/4、Small/25 和 Small/49。如图9的结果表明,Context Cluster 操作对下游任务具有很好的泛化能力。CoC-Small/25 在检测和实例分割任务上都优于 ConvNet 和 ViT 基线。
 图9:目标检测实验结果
图9:目标检测实验结果ADE20K 语义分割实验结果
接下来,作者研究 Context Cluster 操作对 ADE20K 语义分割任务的泛化性,语义分割头使用 semantic FPN。所有模型使用 80k iterations 进行训练,并使用 ImageNet 预训练权重进行初始化。为了进行比较,作者将 ResNet 作为 ConvNets 的代表,PVT 作为 ViTs 的代表。
ADE20K 的实验结果如下图10所示。使用类似数量的参数,Context Cluster 操作明显优于 PVT 和 ResNet。Context Cluster 操作类似于 SuperPixel,这是一种过度分割的技术。当应用于特征提取时,作者期望 Context Cluster 操作能够对中间特征中的上下文进行过度分割,并在语义分割任务中表现出改进。与目标检测和实例分割任务不同,center 数量对结果影响不大。
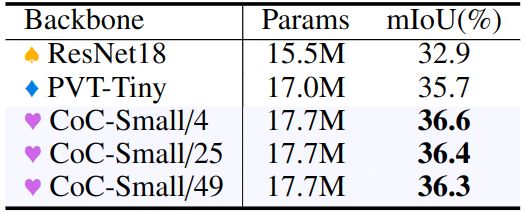 图10:语义分割实验结果
图10:语义分割实验结果总结
提取特征的方式很大程度上取决于如何解释图像。在本文中,作者回顾了视觉表征的一类经典方法:聚类 (Clustering) 。总体而言,作者将图像视为一组点集,并将所有点分组为 Clusters。在每个类中,我们将这些点聚集成一个 center,然后自适应地将中心点分配给所有的点。作者将这种范式称之为上下文聚类 (Context Cluster)。这是一种新的用于视觉表征的特征提取范式。受点云分析和 SuperPixel 算法的启发,Context Cluster与 ConvNets 和 ViTs 有本质区别,不涉及卷积和注意力。并在多种视觉任务中取得了和 ConvNets,ViTs 相当的性能。
-
如何提取、匹配图像特征点2024-04-19 1881
-
机器视觉图像采集卡:关键的图像处理设备2024-02-22 1509
-
通过将异步获取的图像与LiDAR点云对准的方案2023-12-12 2046
-
中值滤波去除图像上存在孤立的噪声点2022-03-25 3704
-
机器视觉中的图像增广技术综述2021-06-03 965
-
用于计算机视觉训练的图像数据集介绍2021-02-26 2657
-
机器学习和计算机视觉的前20个图像数据集2021-01-28 1240
-
用于计算机视觉训练的图像数据集2020-12-31 3271
-
微信精选:图像处理软件在机器视觉系统中怎么工作?2019-09-19 2610
-
计算机视觉/深度学习领域常用数据集汇总2018-08-29 5372
-
基于HSI空间的粗糙集与分层的彩色图像分割算法2018-01-08 1692
-
机器视觉图像处理之角点检测技术2016-01-22 4414
-
选择机器视觉图像处理软件需要从哪些方面入手2014-06-27 5662
-
机器视觉与计算机视觉的关系简述2014-05-13 3260
全部0条评论

快来发表一下你的评论吧 !
