

CPU优化技术-NEON自动向量化
描述
本文选自极术专栏《嵌入式AI》的文章,授权转自知乎作者高性能计算学院的《移动端算法优化》。前面我们学习了如何快速上手开始NEON编程,ArmNEON优化技术,Arm NEON 汇编与Intrinsics编程,CPU优化技术之NEON介绍 和CPU 优化技术-NEON 指令介绍,本篇将会详细介绍NEON 自动向量化。
一、概述
SIMD 作为一种重要的并行化技术,在提升性能的同时也会增加开发的难度。目前大多数编译器都具有自动向量化的功能,将 C/C++ 代码自动替换为 SIMD 指令。
从编译技术上来说,自动向量化一般包含两部分:循环向量化(Loop vectorization)和超字并行向量化(SLP,Superword-Level Parallelism vectorization,又称Basic block vectorization)。
演示代码:
void add(int *a, int *b, int n, int * restrict sum)
{
// it is assumed that the input n is an integer multiple of 4
for (int i = 0; i < (n & ~3); ++i)
{
sum[i] = a[i] + b[i];
}
}
- 循环向量化:将循环进行展开,增加循环中的执行代码来减少循环次数。如以下代码将循环次数精简到之前的1/4。
for (int i = 0; i < (n & ~3); i += 4)
{
sum[i] = a[i ] + b[i];
sum[i + 1] = a[i + 1] + b[i + 1];
sum[i + 2] = a[i + 2] + b[i + 2];
sum[i + 3] = a[i + 3] + b[i + 3];
}
-
SLP 向量化:编译器将多个标量运算绑定到一起,使其成为向量运算。下图将四次标量运算替换为一次向量运算。
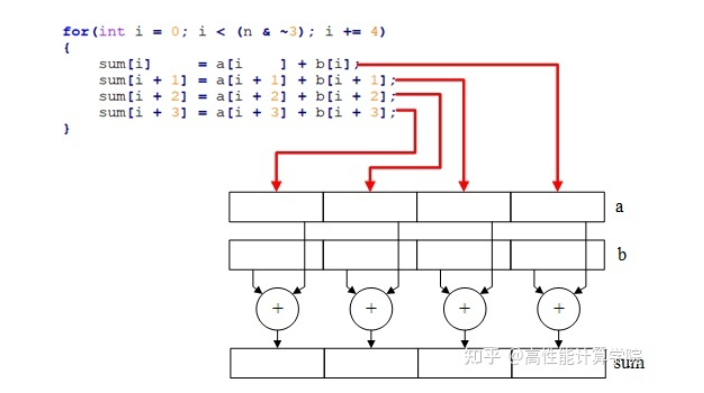
SLP 自动向量化
接下来介绍如何通过编译器实现自动向量化。
二、编译器配置
目前支持自动向量化的编译器有 Arm Compiler 6、Arm C/C++ Compiler、LLVM-clang 以及 GCC,这几种编译器间的相互关系如下表所示。

自动向量化默认不会被启用,编程人员需要向编译器提供允许自动向量化的“许可证”来对自动向量化功能进行使能。
A. Arm Compiler 中使能自动向量化
下文中 Arm Compiler 6 与 Arm C/C++ Compiler 使用 armclang 统称,armclang 使能自动向量化配置信息如下表所示:
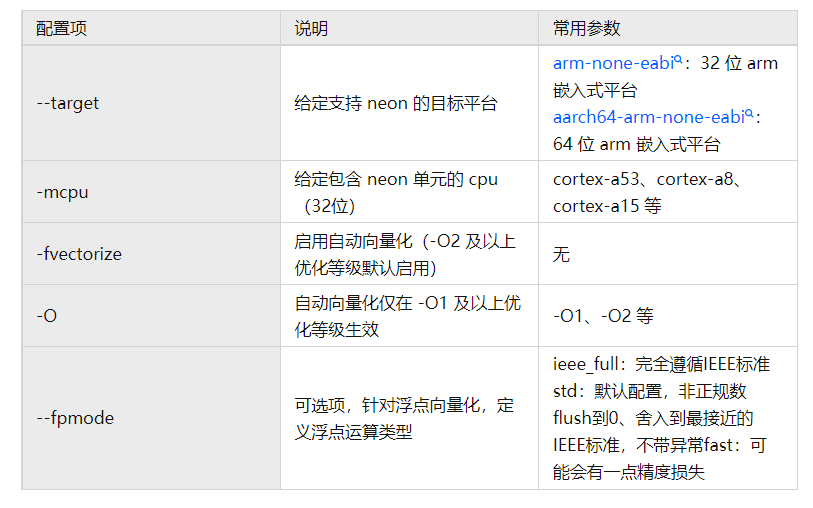
armclang 实现自动向量化示例:
# AArch32
armclang --target=arm-none-eabi -mcpu=cortex-a53 -O1 -fvectorize main.c
# AArch64
armclang --target=aarch64-arm-none-eabi -O2 main.c
B. LLVM-clang中使能自动向量化
Android NDK 从 r13 开始以 clang 为默认编译器,本节通过 cmake 调用Android NDK r19c 工具链展示 clang 的自动向量化方法。
- 使用 Android NDK 工具链使能自动向量化配置参数如下表:

- 在 CMake 中配置自动向量化方式如下:
# method 1
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O1 -fvectorize")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O1 -fvectorize")
# method 2
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O2")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O2")
C. GCC 中使能自动向量化
在 gcc 中使能自动向量化配置参数如下:
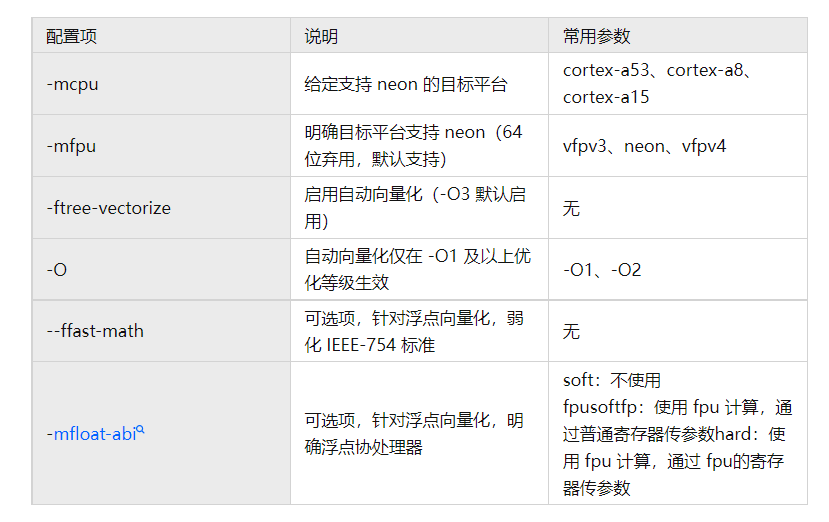
-
在不明确配置 -mcpu 的情况下,编译器将使用默认配置(取决于编译工具链时的选项设置)进行编译。
-
通常情况下 -mfpu 和 -mcpu 的配置存在关联性,对应关系如下。(如当选取-mcpu为cortex-a8时,-mfpu一般设置为vfpv3或neon)
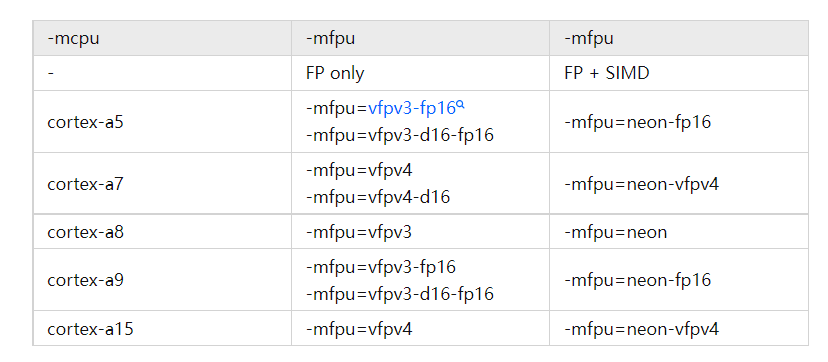
gcc 中实现自动向量化的编译配置如下:
# AArch32
arm-none-linux-gnueabihf-gcc -mcpu=cortex-a53 -mfpu=neon -ftree-vectorize -O2 main.c
# AArch64
aarch64-none-linux-gnu-gcc -mcpu=cortex-a53 -ftree-vectorize -O2 main.c
此外,gcc 中可以通过 -fopt-info-vec 命令查看自动向量化的详细信息,比如哪些代码实现了向量化,哪些代码没有实现向量化及没有进行向量化的原因。
D. 自动向量化实例
我们以上节的求和示例代码,来对编译器自动向量化的功能进行演示。编译器以 32 位 arm-gcc 为例:
# automatic vectorization is not enabled
arm-none-linux-gnueabihf-gcc -O2 main.c -o avtest
# automatic vectorization is enabled
arm-none-linux-gnueabihf-gcc -mfpu=neon -ftree-vectorize -O2 main.c -o avtest
- 使用 objdump 查看反汇编代码,反汇编命令如下:
arm-none-linux-gnueabihf-objdump -d avtest > assemble.txt
-
反汇编结果对比如下图:
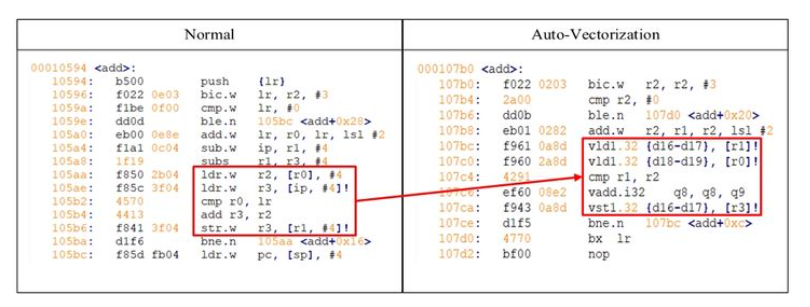
反汇编代码
启用自动向量化之后,编译器通过矢量化加载 (ldr -> vld1)、求和 (add -> vadd)以及保存 (str -> vst1)等指令,将每次循环中处理的数据变为 4 个,循环次数精简为之前的 1/4。
三、自动向量化友好型代码
基于一定的编程优化准则,可以更好的协助编译器完成自动向量化的工作,获得理想的性能状态。
A. 避免使用难以向量化的语句
-
数据依赖
当循环中存在数据依赖时,编译器无法进行向量化。
下述代码中计算 a[i] 时依赖上一次循环的输出,无法被向量化。
// the output of a[i] depends on its last result
for (int i = 1; i < n; ++i)
{
a[i] = a[i - 1] + 1;
}
-
多级指针
编译器无法对间接寻址,多级索引、多级解引用等行为进行向量化,尽量避免使用多级指针。
下述代码通过 idx 进行了多级索引,无法被向量化。
// idx is unpredictable, so this code cannot be vectorized
for (int i = 0; i < n; ++i)
{
sum[idx[i]] = a[idx[i]] + b[idx[i]];
}
-
条件及跳转语句
当循环中存在条件语句或跳转语句时,代码很难被向量化。因此应尽量避免在循环中的使用if、break等语句。当循环中需要调用函数时,尽量使用内联函数进行替换。
下述代码通过调用内联函数 add_single2 避免发生函数跳转。
__attribute__((noinline)) int add_single1(int a, int b);
__inline__ __attribute__((always_inline)) int add_single2(int a, int b);
void add(const int *a, const int *b, int n, int * restrict sum)
{
for (int i = 0; i < (n & ~3); ++i)
{
// replace normal functions with inline functions
// sum[i] = add_single1(a[i], b[i]);
sum[i] = add_single2(a[i], b[i]);
}
}
-
长数据类型
neon 对 64 位长数据类型的支持有限,且较小的数据位宽有更高的并行度,应尽量选用较小的数据类型。当程序中存在浮点数据时,指明其数据类型。
下述代码指明1.0是浮点数据,否则编译器会优先将其理解为double。
// assume that array sum and a are floating-point arrays
for (int i = 0; i < (n & ~3); ++i)
{
// replace 1.0 with 1.f
// sum[i] = a[i] + 1.0;
sum[i] = a[i] + 1.f;
}
B. 增加自动向量化信息
-
地址交叠
指针操纵同一片数据区的情况被称为地址交叠。地址交叠会阻止自动向量化操作。
当程序不会发生地址交叠时,用 restrict 限定符(C99 引入)在代码中声明指针所指区域是独立的。
下述代码通过 restrict 限定 sum 与 a、b 间没有地址交叠的情况。
// add restrict before the output parameter sum
void add(const int *a, const int *b, int n, int * restrict sum)
-
数组尺寸
明确数组尺寸,使其达到向量化处理长度的整数倍。但应注意处理不足向量化部分的剩余数据。
下述代码通过掩码操作表明处理循环次数是 4 的整数倍。
// make number of cycles is an integer multiple of 4,
for (int i = 0; i < (n & ~3); ++i)
// don't forget to process the remaining data
-
循环展开
在一些编译器中可以通过在 for 循环之前增加预处理语句告知编译器循环展开级数。
下述代码告知 armclang 编译器希望将循环展开 4 次。
// #pragma unroll (4) // armcc
#pragma clang loop interleave_count(4) //armclang
for (int i = 0; i < n; ++i)
{
// ...
}
-
结构体加载
编译器仅会对每一成员都有操作的结构体加载操作进行自动向量化,可以结合实际需求考虑去除用于结构体对齐的填充数据。
下述代码中删除用于填充结构体的变量 padding 以避免无法向量化。
struct st_align
{
char r;
char g;
char b;
// delete the data used to populate the structure
// char padding;
};
-
neon 加载指令要求结构体中的所有项有相同的大小。
下述代码中结构体由于 short 类型与 char 类型不一致而不会被执行自动向量化。
struct st_align
{
short r; // change short to char to get auto-vectoration
char g;
char b;
};
-
循环构造
尽量通过 < 构造循环,而不是 <= 和 != 。
下述代码通过调整i的范围实现 < 替换 <= 。
// use '<' to construct a loop instead of '<='
// for(int i = 1; i <= n; ++i)
for (int i = 1; i < n + 1; ++i)
{
// ...
}
-
数组索引
当对数组进行操作时,使用数组索引替代指针索引。
下述代码通过 sum[i] 进行索引,而不是*(sum + i)。
// replace arrary with pointer
// *(sum + i) = *(a + i) + *(b + i);
sum[i] = a[i] + b[i];
C. 重排数据实现缓存友好
-
循环合并
当数据连续存储在结构体中时,可以进行循环合并操作,即在一个循环内处理临近的数据,提高缓存命中率。
下述代码将 r、g、b 三个通道的处理合并到一个循环中。
// combine the rgb operation
/*
for (...)
{
pixels[i].r = ....;
}
for (...)
{
pixels[i].g = ....;
}
for (...)
{
pixels[i].b = ....;
}
*/
// cache friendly code
for (...)
{
pixels[i].r = ....;
pixels[i].g = ....;
pixels[i].b = ....;
}
四、总结
本章节主要介绍了自动向量化的相关内容,其优缺点对比如下:
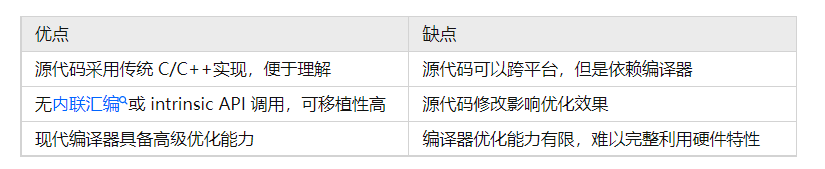
总之,虽然通过自动向量化技术我们可以在一定程度上降低向量化编程难度,增强代码的可移植性,但是不能完全依赖于编译器,而且有时为了获得更高性能的代码,还是需要通过intrinsic甚至neon汇编进行编程。
审核编辑 :李倩
-
CPU优化技术之自动向量化实例2022-10-08 2754
-
小白快速上手Arm NEON编程手册指南2022-07-15 6454
-
使用SVE对HACCmk进行矢量化的案例研究2022-11-08 3815
-
如何使用Arm Compiler 6自动矢量化功能为Neon编译2023-08-02 898
-
RealView编译工具NEON矢量化编译器指南2023-08-12 571
-
NEON音频编解码器优化技术2010-09-02 723
-
发掘函数级单指令多数据向量化的方法2017-11-29 846
-
基于Matrix的Givens旋转的QR分解向量化方法2017-12-05 1240
-
控制流SIMD向量化方法2017-12-26 1077
-
DSP的并行指令分析和冗余优化算法2018-02-24 1347
-
MATLAB的循环向量化编程方法的详细资料研究2019-08-28 1593
-
NEON编程中的一些常见优化技巧2022-12-12 3255
-
CPU优化技术之NEON 的基本原理、指令2022-12-19 6328
-
从CPU优化技术层面讲解Arm NEON2022-12-26 3058
-
RISC-V架构下的编译器自动向量化2025-06-06 1619
全部0条评论

快来发表一下你的评论吧 !
