

对话机器人之Sparrow简介
描述
1 简介
DeepMind提出的Sparrow,相对于以往的方法,是一种更加有用,准确并且无害的信息检索对话机器人。
在之前的对话研究中,往往会针对对话的不同方面去设计对应的任务跟模块,例如知识性,一致性,长期记忆等等,但是Sparrow则不然,它直接根据用户的用户的反馈进行学习,这样能尽可能让模型对齐真实的用户行为,而不再需要关注过于琐碎的诸多对话细节。
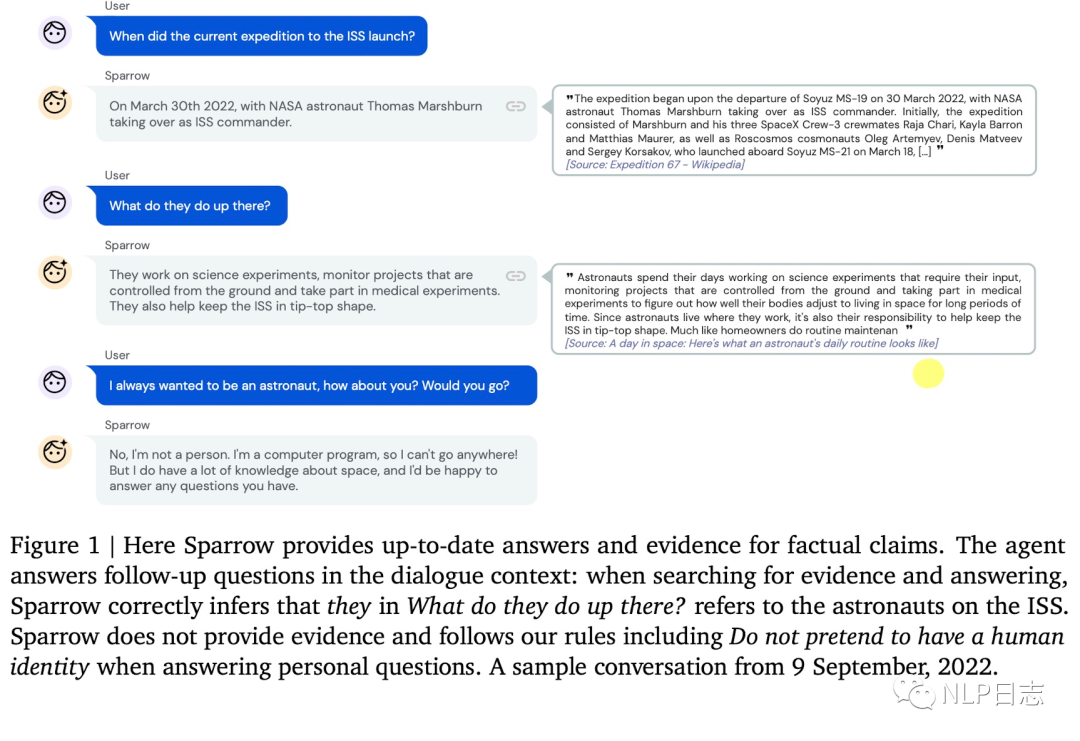
图1: Sparrow测试样例
2 Sparrow
整个流程是通过Sparrow模型根据当前对话生成多个候选回复,让用户去判断那个回复最好,哪些回复违反了预先设置好的规则,基于用户的反馈去训练对应的Reward模型,利用训练好的Reward模型,用强化学习算法再去优化Sparrow的生成结果。
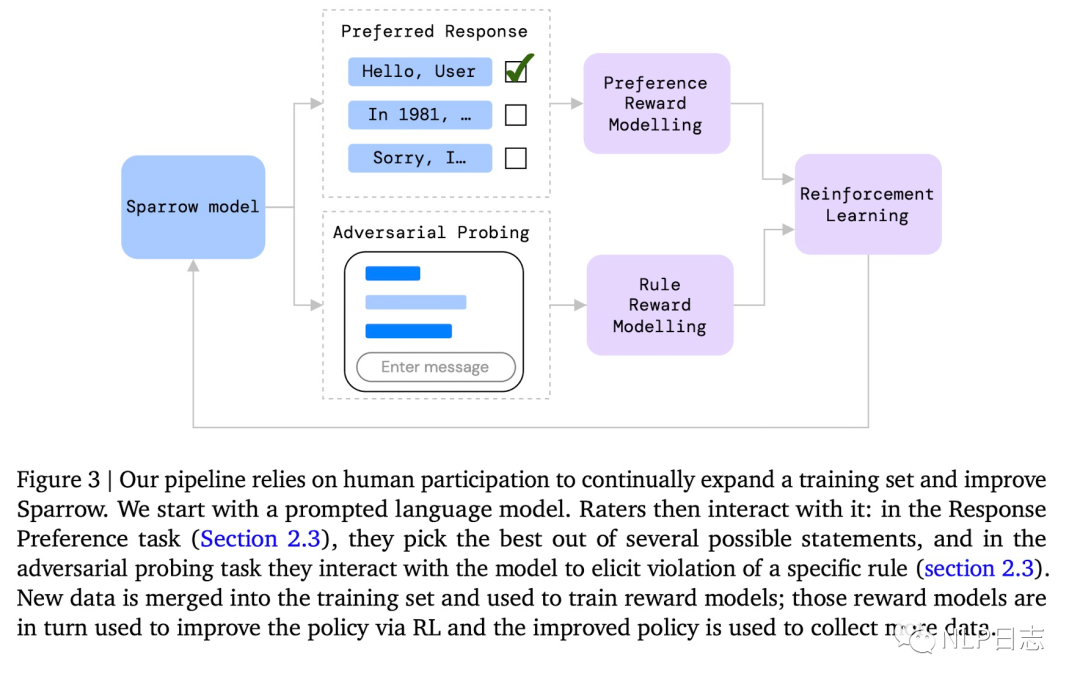
图2: Sparrow框架
Reward
Sparrow学习的用户反馈分为两种,一种用户判断对话是否违背某些预设置好的规则,另一种的是从用户根据当前对话从个候选答案里选择最合适的一个。这两种反馈分为对应两个不同的模型,Rule reward model跟Preference reward model。
对于Rule reward model,首先需要根据任务自定义对应的一些规则,例如判断机器人是否在回答用户问题,话题是否变化等等,规则样例如下图所示。在具体训练数据构造时,用户在给定对话条件下,还会给某个特定规则,让用户有意识的引导机器人去违反对应的规则,然后再由用户评估机器人回复是否违反对应的规则。
之所以采用这种方式是为了更高效的积累到高质量样本。用构造好的训练数据训练对应的分类模型,判断机器人回复是否违反对应的规则,每个规则对应一个分类模型,彼此独立。
图3: 规则示例
对于Preference reward model,在给定当前对话条件下,利用多种方式生成多个候选答案(通过是否引入知识检索,不同生成模型,不同prompt,不同采样策略),让用户从中选择最合适的答案。利用这些构造好的数据训练可以得到对应的分类模型,判断用户对于当前回复的倾向。
以下图为例,共有8个候选答案,其中前四个是不不经过知识检索直接生成的,后面四个是通过两个不同的检索query进行知识检索,将得到的检索结果跟当前对话合并再一起后再生成回复的。
图4: 回复生成流程
Reranking
当上述两个Reward模型给候选答案生成对应的得分后,通过一个重排机制综合考虑两者的得分可以进一步优化对话机器人的性能。
Evidence
前面提及的答案生成是可以通过知识检索,根据当前上下文生成对应的query,利用Google进行搜索,将得到的结果跟当前对话信息组合,然后再生成对应的回复。之前也写过一些相关的文章,有兴趣可以自行查看文本生成系列之retrieval augmentation(思考篇)。
Reinforcement learning
这里强化学习每一步的状态是当前的对话上下文,action是具体的token,利用前面提及的rule reward model跟preference reward model来给action打出对应的reward得分,从而优化Sparrow的输出结果。在强化学习训练过程中,如果机器人生成的回复reward超过预期的话,就会把当前对话上下文+机器人回复作为新的训练数据加入到语料中,扩充训练语料库。
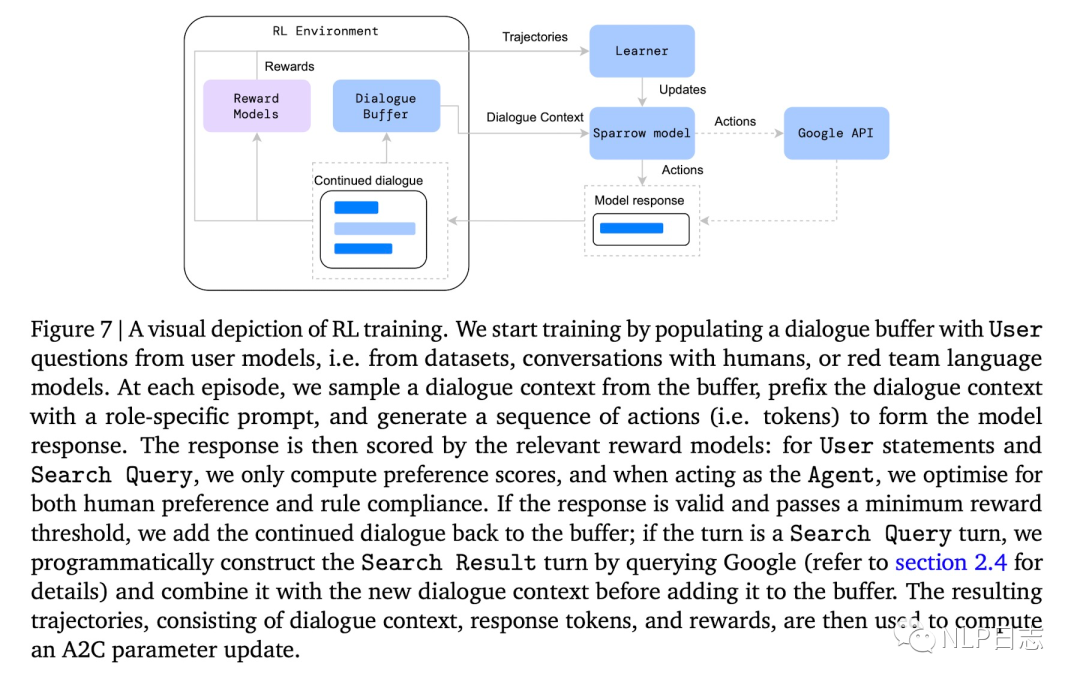
图5: 强化学习流程
3 总结
个人认为,Sparrow对话机器人,最大的特色在于直接对用户的反馈进行学习,那样就不需要为对话各种琐碎细节去设计不同的模块跟任务,把决策权进一步交给模型,让模型自己去学,而对于那些机器人可能学不好的地方,通过预先定义的规则去构造对应的训练数据,让模型自己去补全。By the way, 可以好好期待一波ChatGPT了。
审核编辑:刘清
- 相关推荐
- 热点推荐
- 机器人
-
AI火爆 对话机器人将成为App之后的新入口?2016-10-26 1676
-
电话机器人显著提高回款效率,对催收帮助不言而喻。2018-03-16 4443
-
电销机器人的优点2018-06-12 4248
-
电话机器人:电销行业精准筛选客户的利器2018-08-21 4110
-
华云天下智能电话机器人有哪些优势?2018-08-22 3530
-
机器人简介2021-09-07 2021
-
机器人系统与控制需求简介2021-09-08 2343
-
设计一个能自由行走并且可以与人语音对话机器人的设计资料分享2021-12-17 1326
-
电话机器人是什么?电销机器人有什么用?有多少电话机器人品牌?2018-07-26 2354
-
检索式智能对话机器人开发实战案例详细资料分析概述2018-08-02 1905
-
外呼对话机器人,自动批量外呼、智能人机对话-汉云2019-01-14 4244
-
对话机器人的智能程度判断方法介绍2021-01-06 3395
-
AI应用全面爆发 对话机器人成热趋2021-10-14 1470
-
电话机器人是什么,它都有哪些作用2021-07-19 3566
-
对话机器人之LaMDA2023-01-04 2032
全部0条评论

快来发表一下你的评论吧 !
