

CPU优化技术系列之 NEON 开发设计实现方案
处理器/DSP
描述
一、概述
在前面的"CPU 优化技术"系列文章中我们对NEON做了系统的介绍和说明,包括SIMD和NEON概念,NEON自动向量化以及NEON intrinsic指令集等。但是只掌握这些还不足以编写一个性能完善的NEON程序,在实际的NEON优化工作中我们会遇到如何将标量处理转换为向量处理,如何更高效的处理图像的边界区域等问题。接下来我们会针这些问题进行介绍和说明,让大家可以在实际工作中使用NEON来优化程序的性能。
本文我们会介绍代码如何进行向量化,如何处理向量化的剩余部分,如何处理图像的边界区域,最后会给出一个完整的NEON程序实例。
二、概述向量化编程
2.1. 向量化
向量化就是使用SIMD指令同时对多个数据进行处理,达到提升程序性能的目的。
我们以数据加法为例,标量和向量处理的对比图如下。对于无符号16位类型的加法运算,普通的标量加法需要进行8次的计算量,使用向量加法指令一次就可以完成。
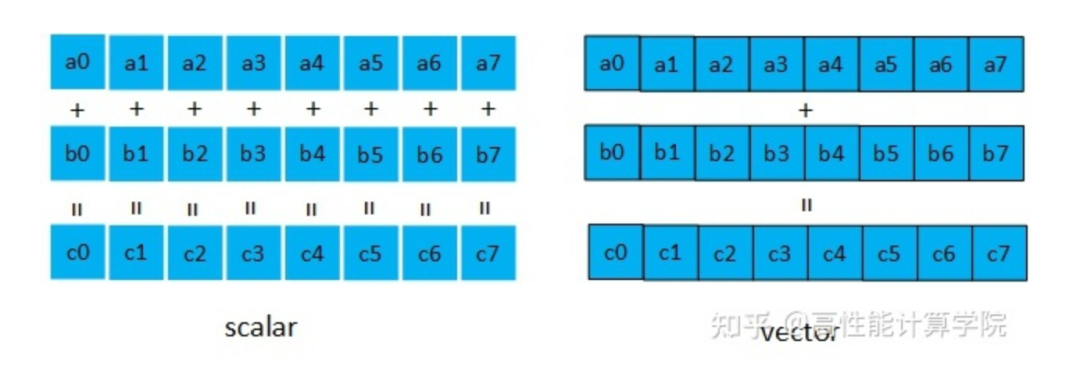
相比于标量编程,向量化编程对于初学者来说有一定的难度:
编程方式的变化:一次处理的不再是单个数据而是多个数据,同时还要专门处理向量化的剩余数据。
向量数据类型的选择:要根据实际的情况选择最合适的向量寄存器。
选择合适的指令:需要非常熟悉NEON指令集,使用最适合的指令获得最好的性能。
2.2 实例讲解
这是一个UV通道下采样代码,输入是u8类型的数据,通过邻近的4个像素求平均,输出u8类型的数据,达到1/4下采样的目的。我们假定每行数据长度是16的整数倍。算法的示意图和参考代码如下所示。

C代码实现:
void DownscaleUv(uint8_t *src, uint8_t *dst, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{
for (int32_t j = 0; j < dst_height; j++)
{
uint8_t *src_ptr0 = src + src_stride * j * 2;
uint8_t *src_ptr1 = src_ptr0 + src_stride;
uint8_t *dst_ptr = dst + dst_stride * j;
for (int32_t i = 0; i < dst_width; i += 2)
{
// U通道
dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] +
src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;
// V通道
dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +
src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;
}
}
}
2.2.1 内层循环向量化
内层循环是代码执行次数最多的部分,因此是向量化的重点。我们的输入和输出都是u8类型,NEON寄存器128bit,所以我们每次处理16个数据。
// 每次有16个数据输出
for (i = 0; i < dst_width; i += 16)
{
//数据处理部分......
}
2.2.2 数据类型的选择
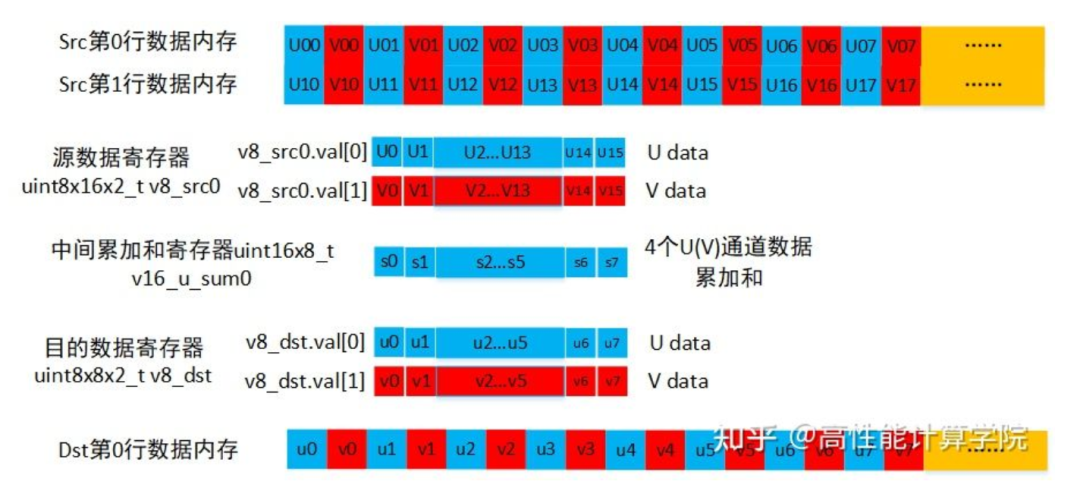
2.2.3 指令的选择
输入数据加载:UV通道的数据是交织的,使用vld2指令可以实现解交织。
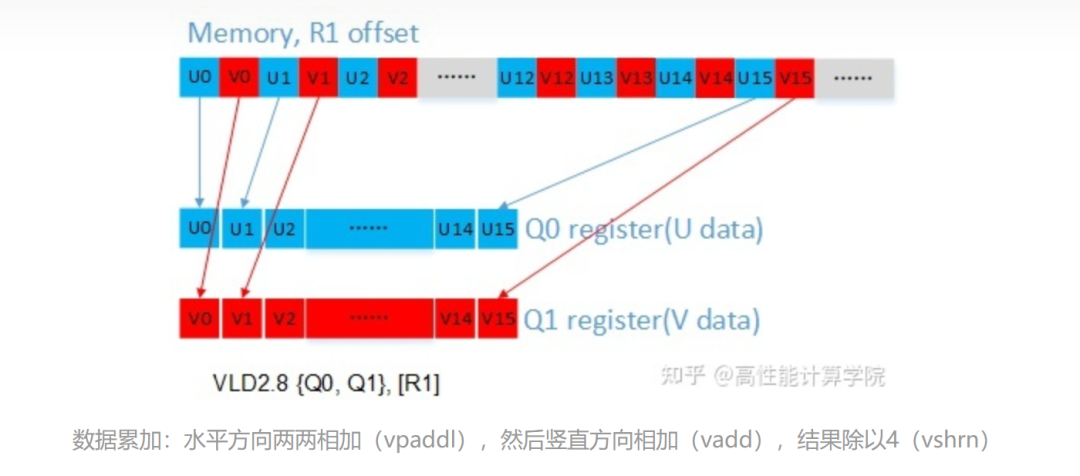
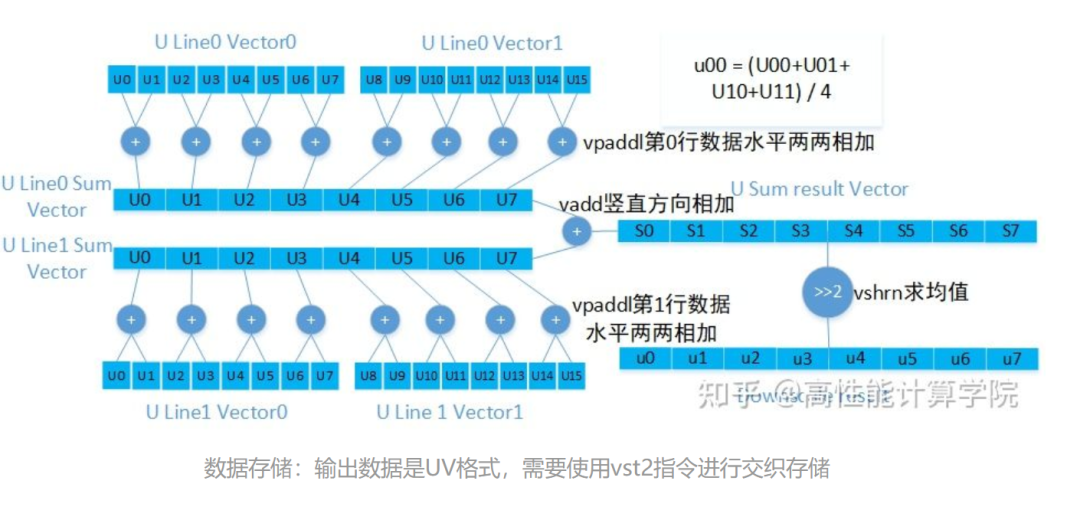
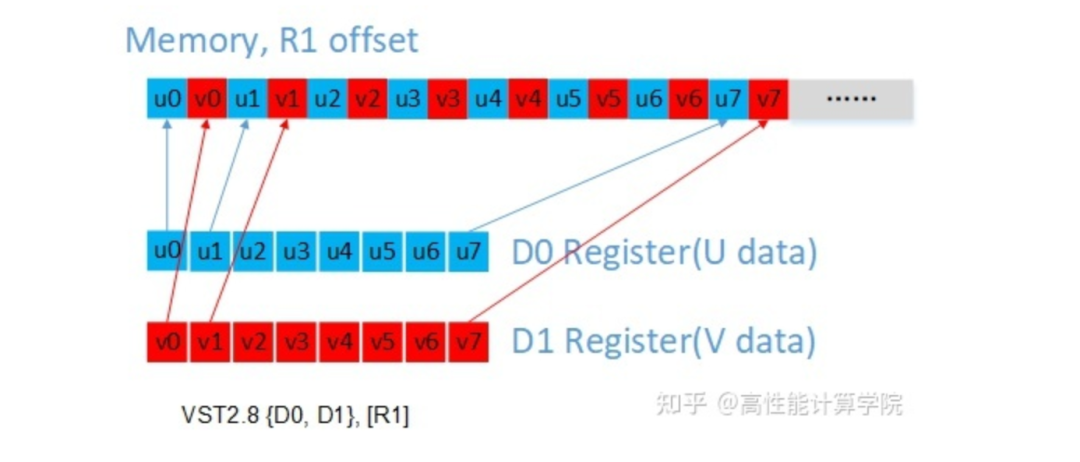
2.2.4 代码实现
//使用intrinsic需要包含的头文件 #includevoid DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride) { //load偶数行的源数据,2组每组16个u8类型数据 uint8x16x2_t v8_src0; //load奇数行的源数据,需要两个Q寄存器 uint8x16x2_t v8_src1; //目的数据变量,需要一个Q寄存器 uint8x8x2_t v8_dst; //目前只处理16整数倍部分的结果 int32_t dst_width_align = dst_width & (-16); //向量化剩余的部分需要单独处理 int32_t remain = dst_width & 15; int32_t i = 0; //外层高度循环,逐行处理 for (int32_t j = 0; j < dst_height; j++) { //偶数行源数据指针 uint8_t *src_ptr0 = src + src_stride * j * 2; //奇数行源数据指针 uint8_t *src_ptr1 = src_ptr0 + src_stride; //目的数据指针 uint8_t *dst_ptr = dst + dst_stride * j; //内层循环,一次16个u8结果输出 for (i = 0; i < dst_width_align; i += 16) { //提取数据,进行UV分离 v8_src0 = vld2q_u8(src_ptr0); src_ptr0 += 32; v8_src1 = vld2q_u8(src_ptr1); src_ptr1 += 32; //水平两个数据相加 uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]); uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]); uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]); uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]); //上下两个数据相加,之后求均值 v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2); v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2); //UV通道结果交织存储 vst2_u8(dst_ptr, v8_dst); dst_ptr += 16; } //process leftovers...... } }
2.3 向量化剩余部分(leftovers)处理
接着上面的实例,内层循环每次计算16个结果,当输出图像宽度不是16整数倍的时候,我们需要考虑结尾如何高效的编写。“NEON Programmer's Guide”中给出了几种推荐写法,下面逐一介绍一下。
2.3.1 Extend arrays with padding
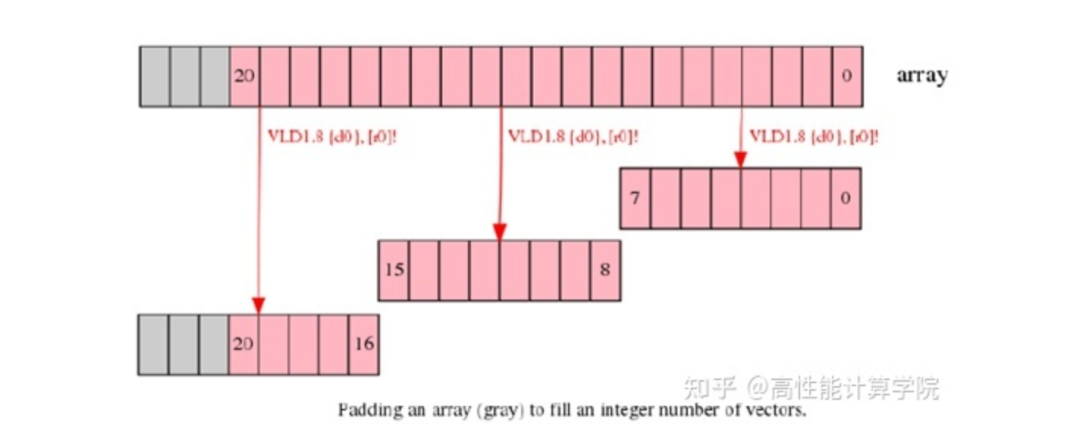
这个方法比较好理解,每行数据长度不是向量长度整数倍我们可以提前将数据补齐到需要的长度,这样处理时候就方便了。这个方法的使用是要分情况的。
如果需要自己申请内存,复制来扩展边界,这并不是一种高效的方法。
如果外部数据先要经过其他的处理(例如rgb2yuv),我们可以考虑将前一级的输出保存成需要的长度,这样后面的uv下采样就可以得到扩展的内存了。
2.3.2 Overlap data elements
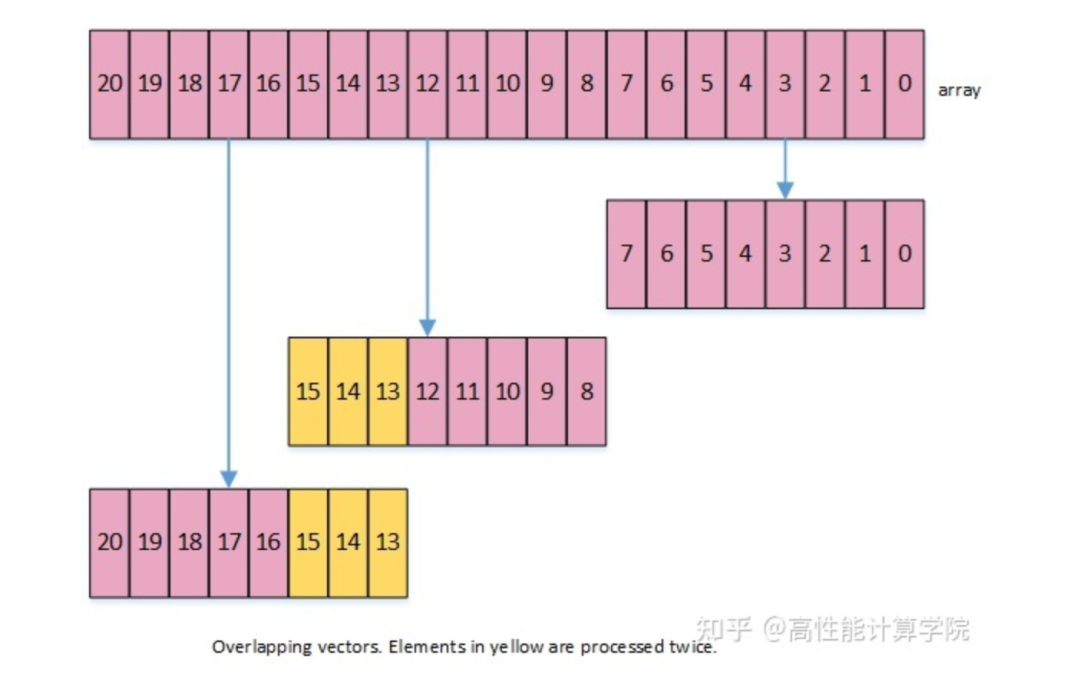
这种做法是在处理尾部数据的时候,从后往前提取一个向量的数据进行计算,这样会出现一部分数据重复计算。接着2.2.4节的示例,这种方法的实现代码如下:
#includevoid DownscaleUvNeon(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride) { uint8x16x2_t v8_src0; uint8x16x2_t v8_src1; uint8x8x2_t v8_dst; int32_t dst_width_align = dst_width & (-16); int32_t remain = dst_width & 15; int32_t i = 0; for (int32_t j = 0; j < dst_height; j++) { uint8_t *src_ptr0 = src + src_stride * j * 2; uint8_t *src_ptr1 = src_ptr0 + src_stride; uint8_t *dst_ptr = dst + dst_stride * j; for (i = 0; i < dst_width_align; i += 16) { v8_src0 = vld2q_u8(src_ptr0); src_ptr0 += 32; v8_src1 = vld2q_u8(src_ptr1); src_ptr1 += 32; uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]); uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]); uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]); uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]); v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2); v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2); vst2_u8(dst_ptr, v8_dst); dst_ptr += 16; } //process leftover if (remain > 0) { //从后往前回退一次向量计算需要的数据长度,有部分数据是之前处理过的 src_ptr0 = src + src_stride * (j * 2) + src_width - 32; src_ptr1 = src_ptr0 + src_stride; dst_ptr = dst + dst_stride * j + dst_width - 16; v8_src0 = vld2q_u8(src_ptr0); v8_src1 = vld2q_u8(src_ptr1); uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]); uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]); uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]); uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]); v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2); v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2); vst2_u8(dst_ptr, v8_dst); } } }
以上这种方法我们平时用的比较多,不仅可以处理剩余元素,而且可以保持向量处理的高效性。
2.3.3 Process leftovers as single elements
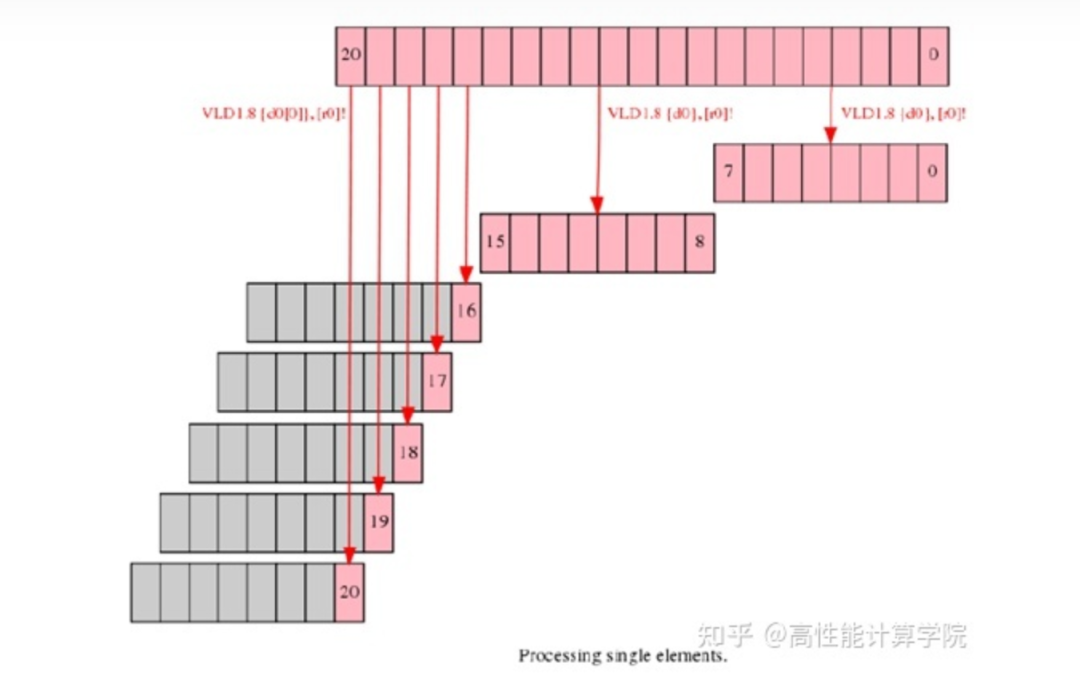
这种做法利用NEON向量可以只加载/存储一个元素的功能,虽然使用向量指令,但是每个结果独立计算和存储。这是一种很不推荐的方法。每次的向量计算只使用一个元素,浪费了计算资源(NEON指令相比于标量指令的执行周期要长,各指令执行时间可以参考文献[2])。
2.3.4 标量处理剩余部分
剩余部分直接采用标量来处理,这种是最简单的方法,也是最常用的方法,每行的剩余元素可以简单的用标量处理,因为绝大部分都是向量计算,剩余元素所占比例非常小,因此使用标量不会对性能产生太明显的影响。
void DownscaleUvNeonScalar(uint8_t *src, uint8_t *dst, int32_t src_width, int32_t src_stride, int32_t dst_width, int32_t dst_height, int32_t dst_stride)
{
uint8x16x2_t v8_src0;
uint8x16x2_t v8_src1;
uint8x8x2_t v8_dst;
int32_t dst_width_align = dst_width & (-16);
int32_t remain = dst_width & 15;
int32_t i = 0;
for (int32_t j = 0; j < dst_height; j++)
{
uint8_t *src_ptr0 = src + src_stride * j * 2;
uint8_t *src_ptr1 = src_ptr0 + src_stride;
uint8_t *dst_ptr = dst + dst_stride * j;
for (i = 0; i < dst_width_align; i += 16) // 16 items output at one time
{
v8_src0 = vld2q_u8(src_ptr0);
src_ptr0 += 32;
v8_src1 = vld2q_u8(src_ptr1);
src_ptr1 += 32;
uint16x8_t v16_u_sum0 = vpaddlq_u8(v8_src0.val[0]);
uint16x8_t v16_v_sum0 = vpaddlq_u8(v8_src0.val[1]);
uint16x8_t v16_u_sum1 = vpaddlq_u8(v8_src1.val[0]);
uint16x8_t v16_v_sum1 = vpaddlq_u8(v8_src1.val[1]);
v8_dst.val[0] = vshrn_n_u16(vaddq_u16(v16_u_sum0, v16_u_sum1), 2);
v8_dst.val[1] = vshrn_n_u16(vaddq_u16(v16_v_sum0, v16_v_sum1), 2);
vst2_u8(dst_ptr, v8_dst);
dst_ptr += 16;
}
//process leftover
src_ptr0 = src + src_stride * j * 2;
src_ptr1 = src_ptr0 + src_stride;
dst_ptr = dst + dst_stride * j;
for (int32_t i = dst_width_align; i < dst_width; i += 2)
{
dst_ptr[i] = (src_ptr0[i * 2] + src_ptr0[i * 2 + 2] +
src_ptr1[i * 2] + src_ptr1[i * 2 + 2]) / 4;
dst_ptr[i + 1] = (src_ptr0[i * 2 + 1] + src_ptr0[i * 2 + 3] +
src_ptr1[i * 2 + 1] + src_ptr1[i * 2 + 3]) / 4;
}
}
}
三、边界处理方法
在许多图像处理算法中,经常会遇到需要处理边界的情况。例如灰度图的3x3高斯滤波,为了计算边界附近点的输出,需要在原图的上下左右各填充1个像素的padding。
一种通用的处理方法是申请一块添加了边界大小的内存空间,将边界填充为需要的数据,并且将原有数据复制到新申请的内存空间中,完成扩边操作(openCV采用的就是这种做法)。这样新的数据块中就有了边界数据,后面的数据处理就很方便了。
但是通用方法不一定是最优的方法,内存申请和填充会增加大量的额外时间,对提升算法性能很不利。我们可以充分利用NEON指令在几乎不增加时间空间开销的前提下完成一些特殊的边界处理。
3.1 常量填充
常量填充就是在有效数据块的上下左右添加常量边界值,完成数据的扩充。例如3x3高斯滤波计算需要在上下左右添加1个常量边界值进行计算。
上下边界的填充比较简单,我们只需要使用vdup指令填充一个向量v8_pre_row_data。
左右边界填充也需要用到dup来的向量v8_const_pad,使用vext来组建新的向量,示意图及参考代码如下。
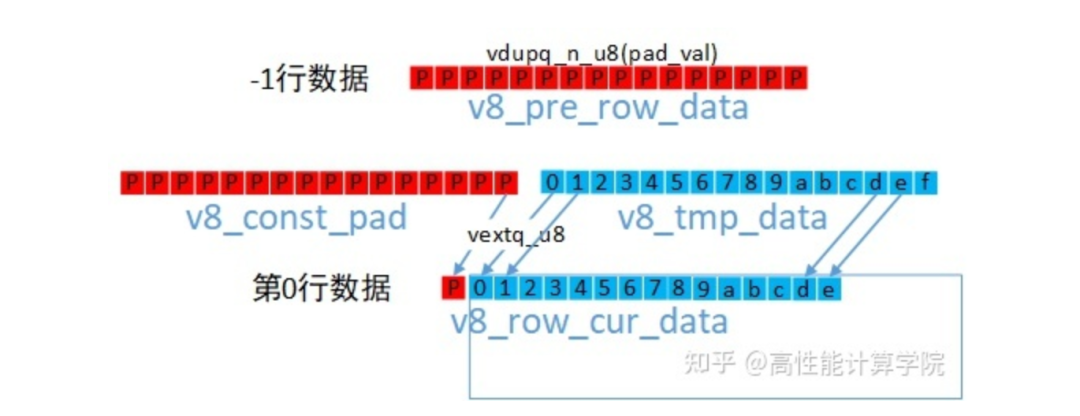
//dup指令生成pading向量 uint8x16_t v8_const_pad = vdupq_n_u8(pad_val); //-1行数据 v8_pre_row_data = v8_const_pad; //读取第0行数据 uint8x16_t v8_tmp_data = vld1q_u8(pt_row0); //第0行带有左padding的数据 uint8x16_t v8_row_cur_data = vextq_u8(v8_const_pad, v8_tmp_data, 15); //读取第1行数据 v8_tmp_data = vld1q_u8(pt_row1); //第1行带有左padding的数据 uint8x16_t v8_next_row_data = vextq_u8(v8_const_pad, v8_tmp_data, 15);
3.2 复制填充
复制填充就是复制最边缘的像素作为边界。我们同样以3x3高斯滤波计算为例。
上下边界的方法一样,我们可以使用vld加载第0行或者最后一行的数据即可。
左右边界的方法一样,对于左边界,我们可以使用VLD1_DUP指令提取边界数据,然后使用vext来组建新的向量,参考代码如下。
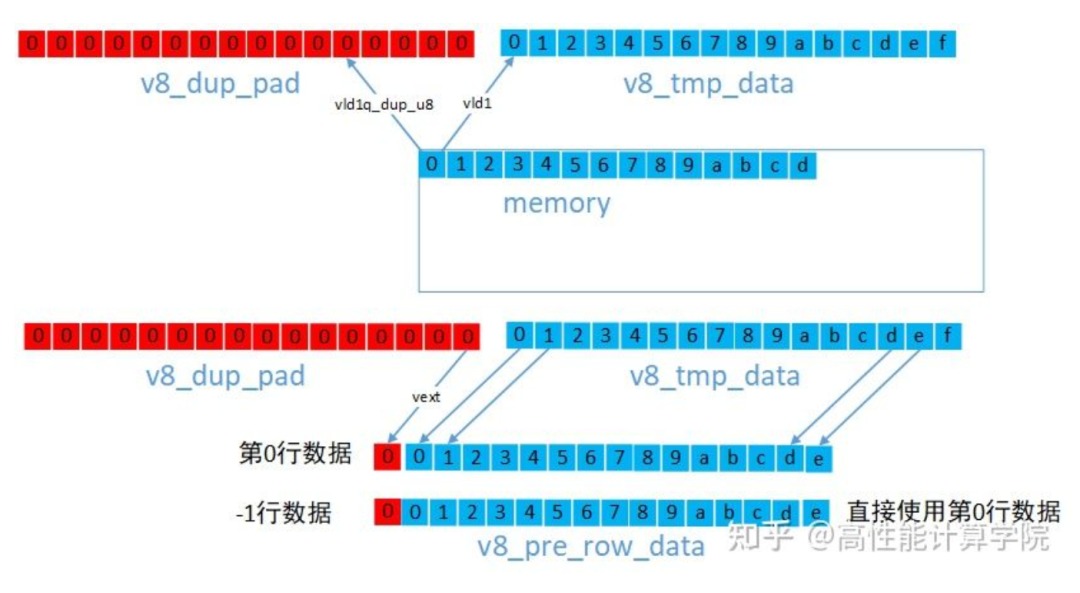
//提取0行padding数据 uint8x16_t v8_dup_pad = vld1q_dup_u8(pt_row0); //提取第0行数据 uint8x16_t v8_tmp_data = vld1q_u8(pt_row0); //第0行带有左padding的数据 uint8x16_t v8_row_cur_data = vextq_u8(v8_dup_pad, v8_tmp_data, 15); //-1行直接使用第0行 uint8x16_t v8_pre_row_data = v8_row_cur_data; //取1行padding数据 v8_dup_pad = vld1q_dup_u8(pt_row1); v8_tmp_data = vld1q_u8(pt_row1); //第1行带有左padding的数据 uint8x16_t v8_next_row_data = vextq_u8(v8_dup_pad, v8_tmp_data, 15);
3.3 反射填充
常见的有反射(dcba"abcdefgh"hgfed)和101反射(edcb"abcdefgh"gfed),处理的方式几乎一样,我们以稍复杂的101反射介绍,同样选择3x3高斯滤波计算举例。
上下边界的方法一样,我们需要根据反射类型,将padding行的数据向量赋值为相应行的数据向量即可。左右边界的方法一样,对于左边界,我们可以使用VLD1指令提取边界数据,然后使用vrev来翻转向量内部元素最后使用vext来组建新的向量。
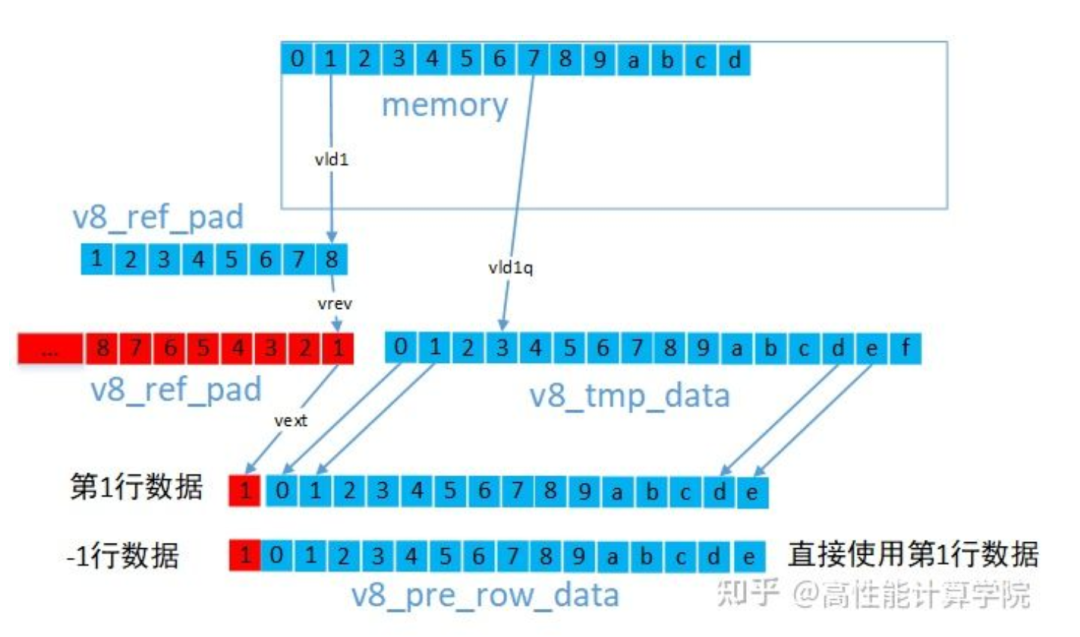
参考代码:
uint8x8_t v8_ref_pad = vld1_u8(pt_row0 + 1); uint8x8_t v8_ref_pad1; uint8x8_t v8_tmp_data = vld1q_u8(pt_row0); //翻转数据,用于生成101反射padding v8_ref_pad1 = vrev64_u8(v8_ref_pad); //第0行带有左padding的数据 uint8x8_t v8_cur_row_data = vextq_u8(vcombine_u8(v8_ref_pad, v8_ref_pad1), v8_tmp_data, 15); v8_ref_pad = vld1_u8(pt_row1 + 1); v8_tmp_data = vld1q_u8(pt_row1); v8_ref_pad1 = vrev64_u8(v8_ref_pad); //第1行带有左padding的数据 uint8x8_t v8_next_row_data = vextq_u8(vcombine_u8(v8_ref_pad, v8_ref_pad1), v8_tmp_data, 15); //-1行数据 uint8x8_t v8_pre_row_data = v8_next_row_data;
四、优化实例
4.1 说明
我们使用核参数为{{1,2,1},{2,4,2},{1,2,1}}对灰度图(size:4095x2161)做高斯滤波,边界填充类型为BORDER_REFLECT101。
4.2 过程分析
整体流程:
Gaussian3x3Sigma0NeonU8C1是主函数
Gaussian3x3RowCalcu是行处理函数,完成一行的处理
第一次处理上边边界,然后是中间处理,最后是下边界处理
int32_t Gaussian3x3Sigma0NeonU8C1(const uint8_t *src, uint8_t *dst, int32_t height, int32_t width, int32_t istride, int32_t ostride)
{
if ((NULL == src) || (NULL == dst))
{
printf("input param invalid!
");
return -1;
}
//BORDER_REFLECT101 top padding
const uint8_t *p_src0 = src + istride;
const uint8_t *p_src1 = src;
const uint8_t *p_src2 = src + istride;
uint8_t *p_dst = dst;
//计算第0行输出
Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width);
//中间行的处理
for (int32_t row = 1; row < height - 1; row++)
{
p_src0 = src + (row - 1) * istride;
p_src1 = src + (row - 0) * istride;
p_src2 = src + (row + 1) * istride;
p_dst = dst + row * ostride;
Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width);
}
//计算最后一行输出
p_src0 = src + (height - 2) * istride;
p_src1 = src + (height - 1) * istride;
p_src2 = src + (height - 2) * istride;
p_dst = dst + (height - 1) * ostride;
Gaussian3x3RowCalcu(p_src0, p_src1, p_src2, p_dst, width);
return 0;
}
Gaussian3x3RowCalcu实现
内联函数,完成一行的处理,基于高斯行列分离计算,先计算行累加,然后计算列累加。
左边界处理:
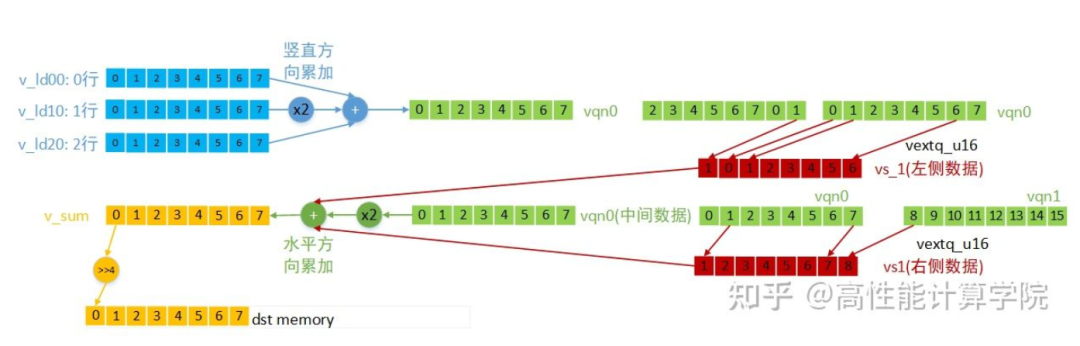
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width)
{
if ((NULL == src0) || (NULL == src1) || (NULL == src2) || (NULL == dst))
{
printf("input param invalid!
");
return -1;
}
int32_t col = 0;
uint16x8_t vqn0, vqn1, vs_1, vs, vs1;
uint8x8_t v_lnp;
int32_t width_t = (width - 9) & (-8);
uint8x8_t v_ld00 = vld1_u8(src0);
uint8x8_t v_ld01 = vld1_u8(src0 + 8);
uint8x8_t v_ld10 = vld1_u8(src1);
uint8x8_t v_ld11 = vld1_u8(src1 + 8);
uint8x8_t v_ld20 = vld1_u8(src2);
uint8x8_t v_ld21 = vld1_u8(src2 + 8);
//竖直方向3行的累加和
vqn0 = vaddl_u8(v_ld00, v_ld20);
vqn0 = vaddq_u16(vqn0, vshll_n_u8(v_ld10, 1));
vqn1 = vaddl_u8(v_ld01, v_ld21);
vqn1 = vaddq_u16(vqn1, vshll_n_u8(v_ld11, 1));
//生成padding数据
vs_1 = vextq_u16(vextq_u16(vqn0, vqn0, 2), vqn0, 7);
vs1 = vextq_u16(vqn0, vqn1, 1);
//水平方向累加和
vs = vaddq_u16(vaddq_u16(vqn0, vqn0), vaddq_u16(vs_1, vs1));
v_lnp = vqrshrn_n_u16(vs, 4);
vst1_u8(dst, v_lnp);
vs_1 = vextq_u16(vqn0, vqn1, 7);
// for循环......
}
中间部分处理
第二部分for循环是计算中间部分数据的结果,先做竖直方向的累加,再做水平方向的累加,每次计算8个输出结果。各向量的数据含义及计算方法(for循环第一次计算)见下图。
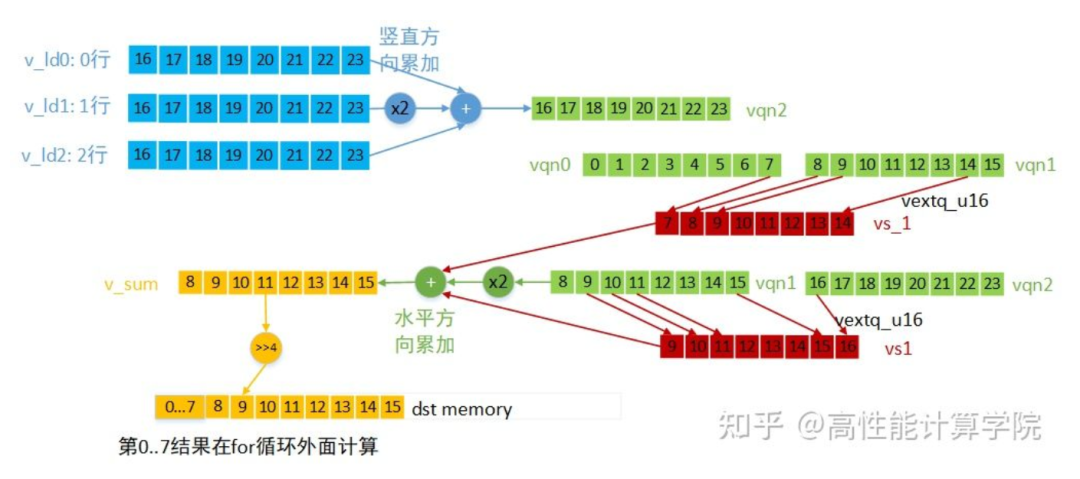
最后一次的向量计算单独处理,为了防止提取下一组数据时越界。
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width)
{
// 计算前8个输出......
for (col = 8; col < width_t; col += 8)
{
// 3行的输入数据
uint8x8_t v_ld0 = vld1_u8(src0 + col + 8);
uint8x8_t v_ld1 = vld1_u8(src1 + col + 8);
uint8x8_t v_ld2 = vld1_u8(src2 + col + 8);
//竖直方向的累加和
uint16x8_t vqn2 = vaddl_u8(v_ld0, v_ld2);
vqn2 = vaddq_u16(vqn2, vshll_n_u8(v_ld1, 1));
//水平方向累加和
vs1 = vextq_u16(vqn1, vqn2, 1);
uint16x8_t vtmp = vshlq_n_u16(vqn1, 1);
uint16x8_t v_sum = vaddq_u16(vtmp, vaddq_u16(vs1, vs_1));
uint8x8_t v_rst = vqrshrn_n_u16(v_sum, 4);
vst1_u8(dst + col, v_rst);
vs_1 = vextq_u16(vqn1, vqn2, 7);
vqn1 = vqn2;
}
//最后一组向量计算,为了防止越界读取数据,右侧数据只读取一个
{
uint8x8_t v_ld0 = vld1_lane_u8(src0 + col + 8, v_ld0, 0);
uint8x8_t v_ld1 = vld1_lane_u8(src1 + col + 8, v_ld1, 0);
uint8x8_t v_ld2 = vld1_lane_u8(src2 + col + 8, v_ld2, 0);
uint16x8_t vqn2 = vaddl_u8(v_ld0, v_ld2);
vqn2 = vaddq_u16(vqn2, vshll_n_u8(v_ld1, 1));
vs1 = vextq_u16(vqn1, vqn2, 1);
uint16x8_t vtmp = vshlq_n_u16(vqn1, 1);
uint16x8_t v_sum = vaddq_u16(vtmp, vaddq_u16(vs1, vs_1));
uint8x8_t v_rst = vqrshrn_n_u16(v_sum, 4);
vst1_u8(dst + col, v_rst);
col += 8;
}
//process leftovers...
}
最后剩余的非对齐部分我们使用标量进行计算。
static inline int32_t Gaussian3x3RowCalcu(const uint8_t *src0, const uint8_t *src1, const uint8_t *src2, uint8_t *dst, int32_t width)
{
// 向量计算部分......
for (; col < width; col++)
{
int32_t idx_l = (col == width - 1) ? width - 2 : col - 1;
int32_t idx_r = (col == width - 1) ? width - 2 : col + 1;
int32_t acc = 0;
acc += (src0[idx_l] + src0[idx_r]);
acc += (src0[col] << 1);
acc += (src1[idx_l] + src1[idx_r]) << 1;
acc += (src1[col] << 2);
acc += (src2[idx_l] + src2[idx_r]);
acc += (src2[col] << 1);
uint16_t res = ((acc + (1 << 3)) >> 4) & 0xFFFF;
dst[col] = CAST_U8(res);
}
return 0;
}
4.3 运行结果
下图是我们在高通骁龙888平台上的运行结果,可以看到使用NEON优化之后运行时间从15.53ms下降到了3.22ms,性能有了4倍多的提升。感兴趣的读者可以自己运行下结果。

4.4 工程代码 https://github.com/mobile-algorithm-optimization/guide/tree/main/NeonGaussian
编辑:黄飞
-
Arm Neon技术指南2023-08-08 629
-
学习架构-用Neon优化C代码intrinsic2023-08-02 651
-
从CPU优化技术层面讲解Arm NEON2022-12-26 3031
-
CPU优化技术之NEON 的基本原理、指令2022-12-19 6305
-
NEON编程中的一些常见优化技巧2022-12-12 3209
-
Arm NEON编程技术上手指南2022-12-06 2963
-
ARMv7系列芯片算法的NEON优化耗时异常的原因是什么2022-08-16 2022
-
小白快速上手Arm NEON编程手册指南2022-07-15 6446
-
介绍一些ARM NEON编程中常见的优化技巧2022-03-30 3561
-
NEON技术如何实现移动端视频高效解码AV1?2019-06-05 6425
-
ARM NEON技术在车位识别算法中的应用2014-07-23 4593
-
NEON音频编解码器优化技术2010-09-02 717
全部0条评论

快来发表一下你的评论吧 !
