

一个基于学习的LiDAR点云3D线特征分割和描述模型
描述
这个工作来自于浙江大学和DAMO academy。在点云配准领域,尽管已经有很多方法被提出来,但是无论是传统方法,还是近年来蓬勃发展的基于深度学习的三维点云配置方法,其实在真正应用到真实的LiDAR扫描点云帧时都会出现一些问题。造成这种困窘的一个主要的原因在于LiDAR扫描到的点云分布极不均匀。
具体而言,相较于RGBD相机,LiDAR的有效扫描深度要大很多。随着深度的增大,其激光发射出去的扇面将会变得稀疏。因此,即使是扫描同一目标或场景的点云帧之间,其尺度并不一致。导致想要研究的关键点周围的邻域点分布也存在较大不同,难以通过这些3D点的特征描述关联起点云帧。
这个问题一直以来都十分棘手。这个工作独辟蹊径,提出对于这种点云数据,不再通过3D点来构建关联以实现点云配准,而是研究点云数据中的高层次的几何原语。这种做法直观来说是有道理的,因为这些高层次的几何原语通常会有较大的支撑点集,换句话说,其对于点云扫描和采样具有较大的鲁棒性,通常不会因为某个点没有被记录而影响相应几何原语的提取。
同时,几何原语通常具有更具体的特征和几何结构,例如一条直线、一个平面等,其更容易构建不同帧间的关联,避免误匹配。但是,这种研究思路通常难度较大,原因在于缺乏足够的有标签的数据集。在这种情况下,这个工作显得极其重要,它不仅仅提供了一个数据集自动标注模型,同样也是少数真正开始探索几何原语用于点云配准任务的先河性的工作。
摘要:交通杆和建筑物边缘是城市道路上经常可以观察到的物体,为各种计算机视觉任务传达了可靠的提示。为了重复提取它们作为特征并在离散的LiDAR帧之间进行关联以进行配准,我们提出了第一个基于学习的LiDAR点云3D线特征分割和描述模型。
为了在没有耗时和繁琐的数据标记过程的情况下训练我们的模型,我们首先为目标线的基本外观生成合成原语,并构建一个迭代线自动标注过程以逐渐调整真实LiDAR扫描的线标签。我们的分割模型可以在任意尺度扰动下提取线,并且我们使用共享的EdgeConv编码器层来联合训练两个分割和描述符提取头。
基于该模型,我们可以在没有初始变换提示的情况下构建一个用于点云配准的高可用性全局配准模块。实验表明,我们的基于线的配准方法与最先进的基于点的方法相比具有很强的竞争力。
主要贡献:
1.据我们所知,我们提出了第一个基于学习的激光雷达扫描线分割和描述网络,为全局配准提出了一个适用的特征类别。
2.我们提出了一种用于点云线标注方法,该方法可以将从合成数据中学习的模型迁移到真实的LiDAR扫描点云以进行自动标注。
3.我们探索了点云特征的尺度不变性,并通过消除Sim(3)变换中的尺度因子,为改善点云上基于学习的任务在尺度扰动下的泛化提供了可行的思路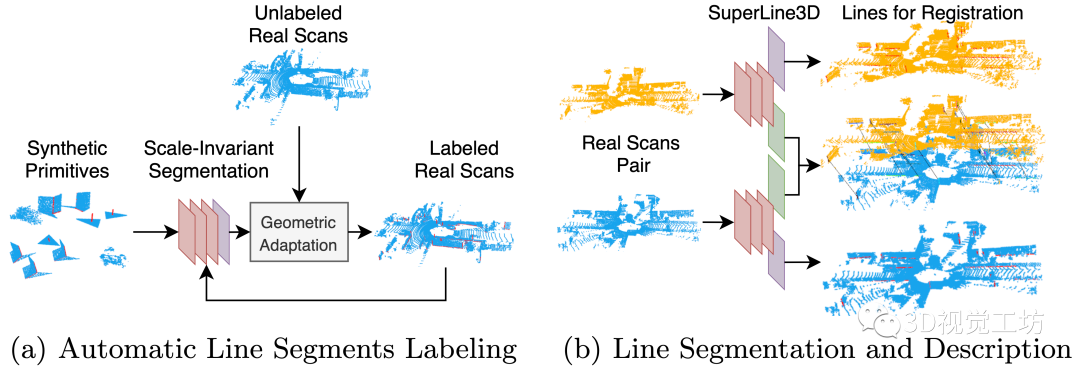
Fig1:整体网络框架。a):我们在合成数据上训练尺度不变的分割,并在多次几何自适应迭代后得到精确的线标签。b):我们同时在标注的LiDAR扫描点云上训练分割和描述符提取网络,其中红色、紫色和绿色层分别代表编码器、分割网络头和描述符提取网络头。
方法介绍: 考虑到缺乏可用的LiDAR扫描点云的有标签线数据集,我们遵循SuperPoint的自监督思想来训练我们的线分割模型,首先构建一个简单的合成数据来初始化一个基础模型,然后使用几何自适应的自动标记真实LiDAR扫描点云进行迭代来调整模型。之后我们收集不同LiDAR扫描点云帧之间的线对应关系,并以端到端的方法联合训练线分割和描述符提取网络。
一、线分割模型
1)合成数据生成.
两种类型的可靠线段可以检测:
1)平面之间的交线,以及2)交通杆。因此,我们选择使用图2(a)所示的以下两个网格原语分别模拟它们的局部外观。这两个网格模型首先被均匀采样成4000个点,如图 2(b) 所示,每个点添加5%的相对3自由度位置扰动。然后,为了模拟附近可能的背景点,我们随机裁剪了40 个基本原语,每个原语包含1000个来自真实扫描点云的点,并将它们放在一起组成最终的合成数据。我们总共生成了5000个合成点云,每个点云有5000个点。
2)尺度不变线分割.
我们将线检测视为点云分割问题,主要挑战是原语尺度缩放问题:在真实的LiDAR点云帧中,点的密度随着扫描距离的增加而降低,而当目标特征远离传感器时,体素网格下采样不能完全归一化密度。此外,我们的合成数据生成也没有考虑线的尺度(如图 2(e)放在一起时所示)。如果不处理这个问题,当训练和测试数据在不同的尺度上时,模型将不会产生合理的预测。 我们的网络通过消除Sim(3)变换的尺度因子s和使用相对距离来解决这个问题,如: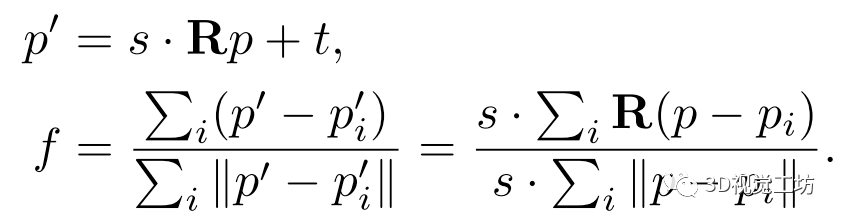
在上式中,我们搜索点p的k=20个最近点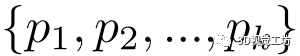 ,并计算尺度不变的局部特征f(p与其近邻点之间的曼哈顿距离与欧几里得距离之比)。这种特征定义的损失在于f不能反映原点在欧几里德空间中的位置,因此此变换存在信息损失。 3)模型结构. 我们选择DGCNN作为我们的主干,因为它直接对点及其最近的近邻点进行编码而无需复杂的操作。下式展示了其被称为EdgeConv的局部特征编码函数,其中
,并计算尺度不变的局部特征f(p与其近邻点之间的曼哈顿距离与欧几里得距离之比)。这种特征定义的损失在于f不能反映原点在欧几里德空间中的位置,因此此变换存在信息损失。 3)模型结构. 我们选择DGCNN作为我们的主干,因为它直接对点及其最近的近邻点进行编码而无需复杂的操作。下式展示了其被称为EdgeConv的局部特征编码函数,其中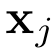 是第j个特征,
是第j个特征,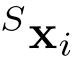 是特征空间 S中 的邻居, h是学习的模型。
是特征空间 S中 的邻居, h是学习的模型。 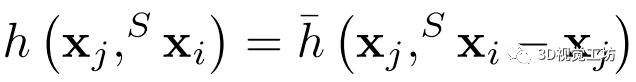 在第一个EdgeConv层中,x表示欧氏空间中的点坐标。在我们的实现中,我们收集每个点的k=20个最近邻点并计算尺度不变特征f。然后我们把第一个EdgeConv层变成:
在第一个EdgeConv层中,x表示欧氏空间中的点坐标。在我们的实现中,我们收集每个点的k=20个最近邻点并计算尺度不变特征f。然后我们把第一个EdgeConv层变成: 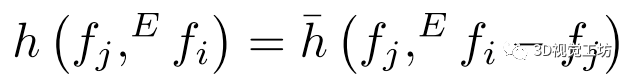 它用尺度不变的特征f代替了欧氏空间中的坐标,但
它用尺度不变的特征f代替了欧氏空间中的坐标,但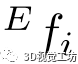 仍然是欧氏空间中第i个邻居点
仍然是欧氏空间中第i个邻居点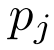 的特征,而不是
的特征,而不是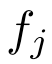 在特征空间中的邻居。由于在生成尺度不变特征时,原始欧氏空间中的部分信息已经丢失,保留原始欧氏空间中的邻域关系可以减少进一步的信息丢失。
在特征空间中的邻居。由于在生成尺度不变特征时,原始欧氏空间中的部分信息已经丢失,保留原始欧氏空间中的邻域关系可以减少进一步的信息丢失。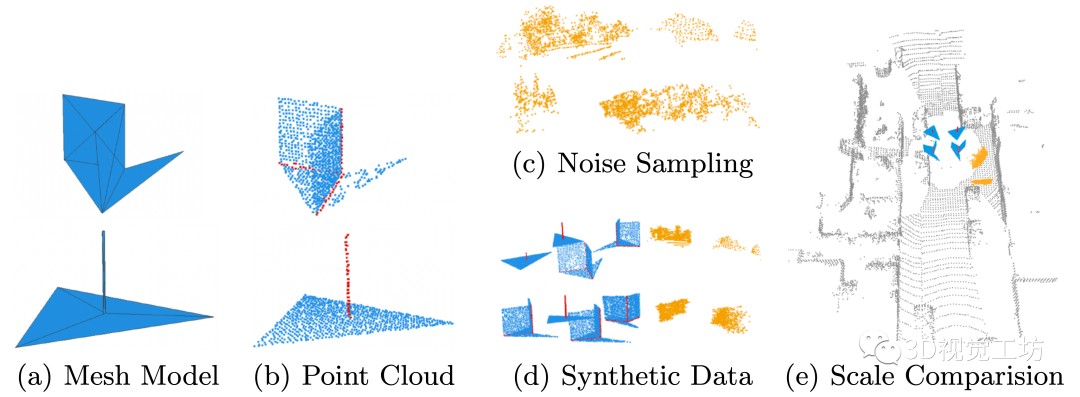
Fig2:合成数据生成步骤。我们通过对原始网格模型进行采样并将真实扫描散点作为噪声来增强生成合成数据。
4)自动线标注.
当前没有可用的 LiDAR点云有标签线数据集,并且难以对点云进行手动标记。因此,我们构建了一个自动线标注框架(图 3)。受SuperPoint启发,我们对LiDAR扫描点云执行几何自适应。首先,我们仅在合成数据上训练一个尺度不变的分割模型,并将XOY中20m和偏航 360°的均匀分布的2D变换应用于LiDAR扫描点云。
然后,我们使用经过训练的模型来预测扰动数据上的标签,聚合来自所有扰动帧的结果,并将超过80%预测属于线的点作为候选点。为了将点聚类成线,我们使用区域增长算法。点之间的连通性通过0.5m搜索半径的KD-Tree定义。我们使用标注点作为种子,生长到附近的标注点,并拟合线。
一旦提取了此类线,我们将继续在获得的有标签LiDAR扫描点云上调整分割模型。我们重复几何自适应3次以在KITTI里程计序列上生成12989个自动标注的 LiDAR帧。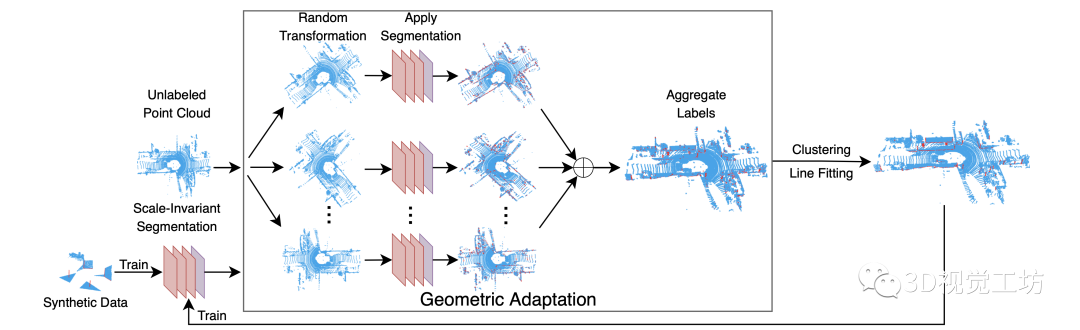
Fig3:自动标注框架。我们使用几何自适应和线拟合来减少网络预测噪声,并通过迭代训练提高真实LiDAR扫描点云的模型精度。
二、联系训练线分割和描述符提取网络
1)线描述符的定义.
不同于只需要线段两个端点的几何定义,每条线的描述符应通过其所有所属点传达局部外观,因为观察到的端点可能由于可能的遮挡而在帧之间变化。因此,我们将描述符定义为其所有所属点的平均值。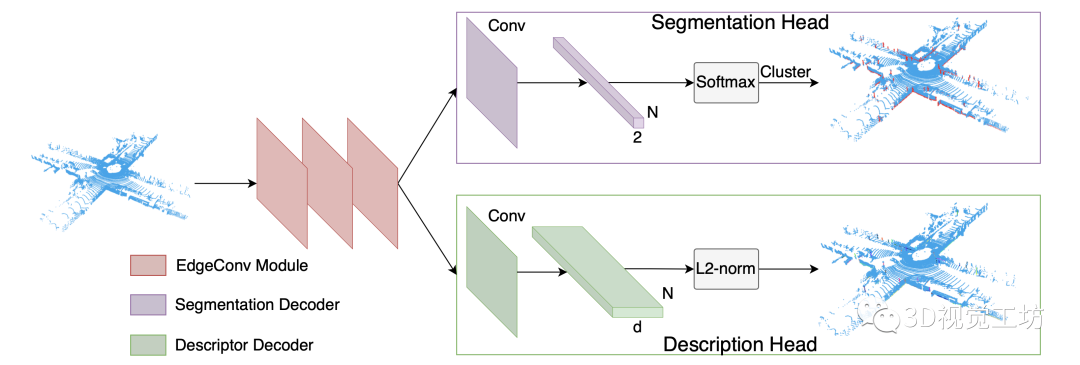
Fig4: 网络架构。该网络使用EdgeConv模块来提取特征。分割网络头和描述符提取头分别用于预测每个点的标签和描述符。
2)网络结构.
我们的网络结构(图4)由堆叠的三个EdgeConv层组成,用于特征编码,两个解码器分别用于线分割和描述。每个EdgeConv层输出一个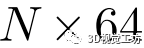 张量,在max-pooling层之后用于3层的分割和描述。我们使用ReLU进行激活。分割网络头将特征向量卷积后变成一个
张量,在max-pooling层之后用于3层的分割和描述。我们使用ReLU进行激活。分割网络头将特征向量卷积后变成一个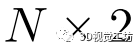 大小的张量(N为输入点数),然后通过softmax层得到每个点的布尔坐标,预测是否属于一条线。描述符提取网络头输出一个大小为
大小的张量(N为输入点数),然后通过softmax层得到每个点的布尔坐标,预测是否属于一条线。描述符提取网络头输出一个大小为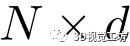 的张量,然后进行L2归一化得到一个d维的描述符。 3)损失函数.我们的分割损失
的张量,然后进行L2归一化得到一个d维的描述符。 3)损失函数.我们的分割损失 是一个标准的交叉熵损失,对于描述符损失,我们首先使用线段标签得到每条线段的均值描述符u,然后使用
是一个标准的交叉熵损失,对于描述符损失,我们首先使用线段标签得到每条线段的均值描述符u,然后使用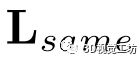 将点描述符拉向u。
将点描述符拉向u。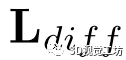 的提出是为了让不同行的描述符相互排斥。此外,对于点云对,我们计算匹配损失
的提出是为了让不同行的描述符相互排斥。此外,对于点云对,我们计算匹配损失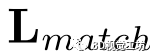 和非匹配线之间的损失
和非匹配线之间的损失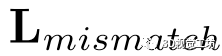 。每一个损失项都可以写成如下形式:
。每一个损失项都可以写成如下形式: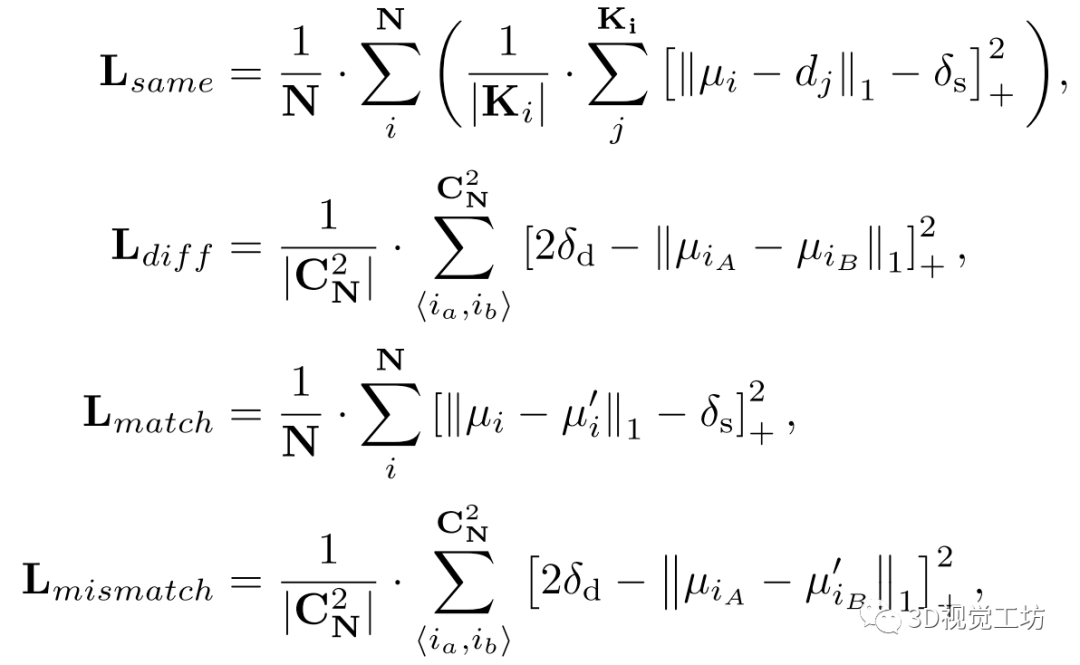
其中N是检测到的线数, 代表两条线的所有对。i和j是两个迭代器,分别用于直线和直线上的点。
代表两条线的所有对。i和j是两个迭代器,分别用于直线和直线上的点。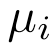 是一条线的平均描述符,
是一条线的平均描述符,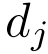 是其相关点j的描述符。
是其相关点j的描述符。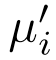 和
和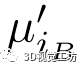 是另一个关联点云的平均描述符,
是另一个关联点云的平均描述符,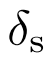 和
和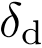 分别为正负边缘。
分别为正负边缘。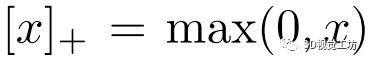 , 且表示L1距离。最后,我们使用
, 且表示L1距离。最后,我们使用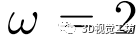 来平衡最终的损失:
来平衡最终的损失: 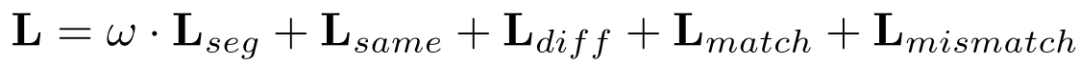
3)基于线的配准.
我们的网络为每个点输出标签和描述符。我们首先提取线,然后我们执行描述符匹配以获得行对应。匹配描述符的阈值设置为0.1。用于将源云 注册到目标点云的变换通过最小化所有线匹配代价
注册到目标点云的变换通过最小化所有线匹配代价 中的点到线距离进行优化:
中的点到线距离进行优化: 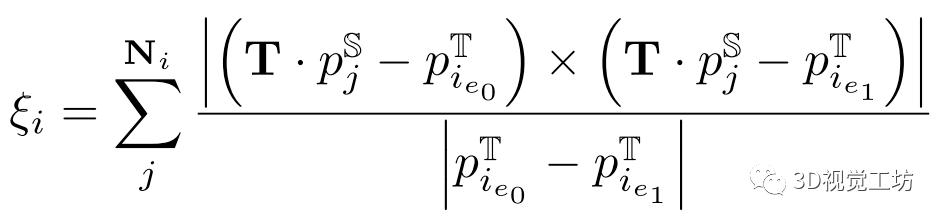 其中
其中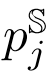 是源点云中的线上的点,
是源点云中的线上的点,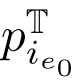 和
和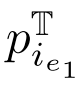 是线i的匹配线
是线i的匹配线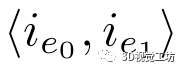 的端点。
的端点。
审核编辑:刘清
-
LiDAR如何构建3D点云?如何利用LiDAR提供深度信息2021-04-06 5343
-
基于3D点云的多任务模型在板端实现高效部署2023-12-28 3365
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2742
-
浩辰3D软件中如何创建槽特征?3D模型设计教程!2020-09-28 1749
-
3D软件中如何应用文本特征?3D文本特征应用技巧2021-04-22 6659
-
点云问题的介绍及3D点云技术在VR中的应用2017-09-27 1553
-
散乱点云数据特征信息提取算法2018-01-30 1192
-
3D模型的加权特征点调和表达2018-02-10 802
-
如何在LiDAR点云上进行3D对象检测2022-04-26 3651
-
何为3D点云语义分割2022-07-21 10615
-
如何直接建立2D图像中的像素和3D点云中的点之间的对应关系2022-10-18 11443
-
基于深度学习的3D分割综述(RGB-D/点云/体素/多目)2022-11-04 3505
-
NeuralLift-360:将野外的2D照片提升为3D物体2023-04-16 3196
-
基于深度学习的点云分割的方法介绍2023-07-20 772
-
基于深度学习的3D点云实例分割方法2023-11-13 3939
全部0条评论

快来发表一下你的评论吧 !
