

实时通信中的AI降噪技术分析
电子说
描述
Part 01● 概述 ●
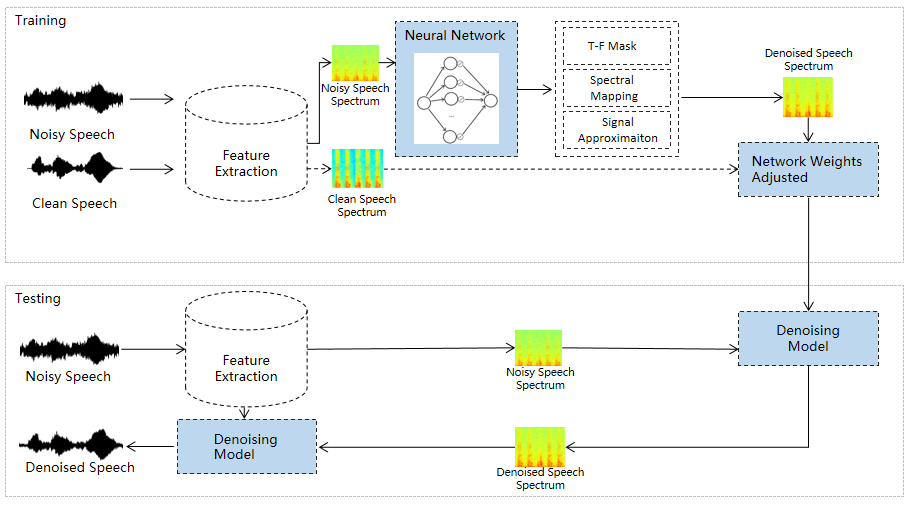
在实时音视频通信场景,麦克风采集用户语音的同时会采集大量环境噪声,传统降噪算法仅对平稳噪声(如电扇风声、白噪声、电路底噪等)有一定效果,对非平稳的瞬态噪声(如餐厅嘈杂噪声、地铁环境噪声、家庭厨房噪声等)降噪效果较差,严重影响用户的通话体验。针对泛家庭、办公等复杂场景中的上百种非平稳噪声问题,融合通信系统部生态赋能团队自主研发基于GRU模型的AI音频降噪技术,并通过算法和工程优化,将降噪模型尺寸从2.4MB压缩至82KB,运行内存降低约65%;计算复杂度从约186Mflops优化至42Mflops,运行效率提升77%;在现有的测试数据集中(实验环境下),可有效分离人声和噪声,将通话语音质量Mos分(平均意见值)提升至4.25。
Part 02● 噪声分类和降噪算法选择 ●
实时音视频的应用场景中,设备处于复杂的声学环境,麦克风采集语音信号的同时还会采集大量噪声,对实时音视频质量来说是一个非常大的挑战。噪声的种类是多种多样的。根据噪声的数学统计特性可以将噪声分为两类:
平稳噪声:噪声的统计特性在比较长的时间里不会随时间而变化,比如白噪声、电风扇、空调、车内噪声等;
非平稳噪声:噪声的统计特性随时间在变化,如餐厅嘈杂噪声、地铁站、办公室、家庭厨房等。
在实时音视频应用中,通话易受到各类噪声干扰从而影响体验,因此实时音频降噪已经成为实时音视频中的一个重要功能。对于平稳的噪声 ,比如空调出风口呼呼声或者录制设备的底噪,它不会随着时间变化而产生较大变化,可以将其估计预测出来,通过简单的减法的方式把它去掉,常见的有谱减法、维纳滤波以及小波变换。对于非平稳噪声,例如马路上车子呼啸而过的声音、餐厅内餐盘的撞击声、家庭厨房内的锅具的敲击声,都是随机突发出现,是不可能通过估计预测的方式去解决的。传统算法对于非平稳噪声难以估计和消除,这也是我们采用深度学习算法的原因。
Part 03● 深度学习降噪算法设计 ●
为了提高音频SDK对于各种噪声场景的降噪能力,弥补传统降噪算法的不足,我们研发了基于RNN的AI降噪模块,结合传统降噪技术和深度学习技术。重点针对家庭和办公室使用场景的降噪处理,在噪声数据集中加入大量的室内噪声类型,诸如办公室内的键盘敲击、办公桌与办公用品拖拉的摩擦声、座椅拖动、家庭中的厨房嘈杂声、地板撞击声等等。
与此同时,为了在移动端的实时语音处理落地,该AI音频降噪算法将计算开销和库的尺寸控制在一个非常低的量级。在计算开销上,以48KHz为例,每帧语音的RNN网络处理处理仅需约17.5Mflops,FFT和IFFT每帧语音需要约7.5Mflops,特征提取需要约12Mflops,总计约42Mflops,计算复杂度约和48KHz的Opus编解码相当,在某品牌中端手机型号,统计RNN降噪模块CPU占用约为4%。在音频库的尺寸上,开启RNN降噪编译后,音频引擎库的体积仅仅增加约108kB。
Part 04● 网络模型及处理流程 ●
该模块采用RNN 模型,原因是 RNN 相比其他学习模型(例如 CNN)携带时间信息,可以对时序信号进行建模,而不仅仅是单独的音频输入和输出帧。同时,模型采用门控循环单元(GRU,如图1所示),实验表明,GRU在语音降噪任务上的性能略好于LSTM,并且由于GRU的权值参数更少,可以节省计算资源。与简单的循环单元相比,GRU有两个额外的门。重置门控制状态是否用于计算新状态,而更新门控制状态将根据新输入改变的程度。这个更新门使GRU可以长时间记忆时序信息,这也是GRU比简单的循环单元表现更好的原因。
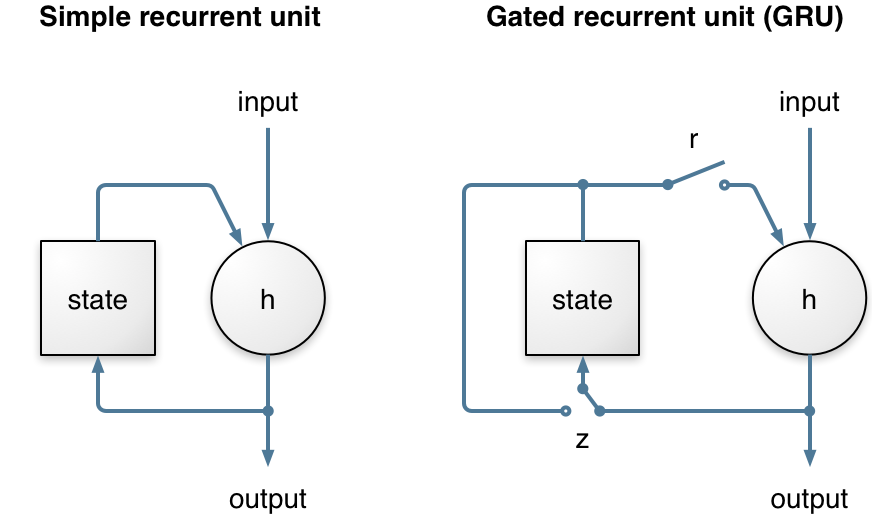
图 1 左侧为简单循环单元,右侧为GRU
模型的结构如图2所示。训练后的模型会被嵌入到音视频通信 SDK 中,通过读取硬件设备的音频流,对音频流进行分帧处理并送入 AI 降噪预处理模块中,预处理模块会将对应的特征(Feature)计算出来,并输出到训练好的模型中,通过模型计算出对应的增益(Gain)值,使用增益值对信号进行调整,最终达到降噪的目的(如图3所示)。
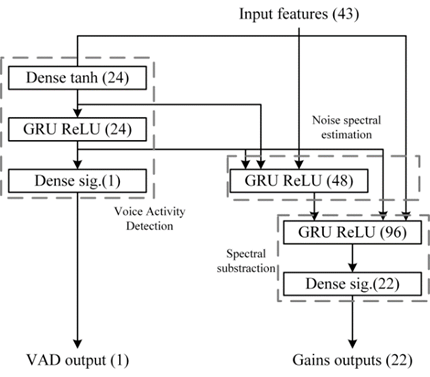
图 2. 基于GRU的RNN网络模型
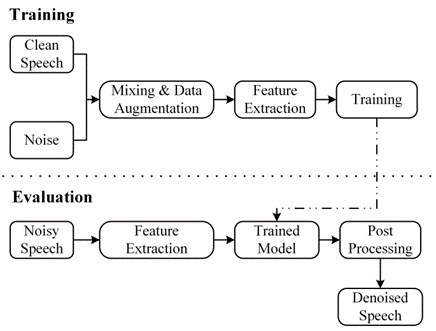
图3. 上方为模型训练流程,下方为实时降噪流程
Part 05● AI降噪处理效果和落地 ●
图4为带有键盘敲击噪声的降噪前后语音语谱图的对比,上半部分为降噪前的带噪语音信号,其中红色矩形框内为键盘敲击噪声。下半部分为降噪后的语音信号,通过观测可以发现,绝大部分键盘敲击声均可以被抑制,同时语音损伤控制在较低的程度。
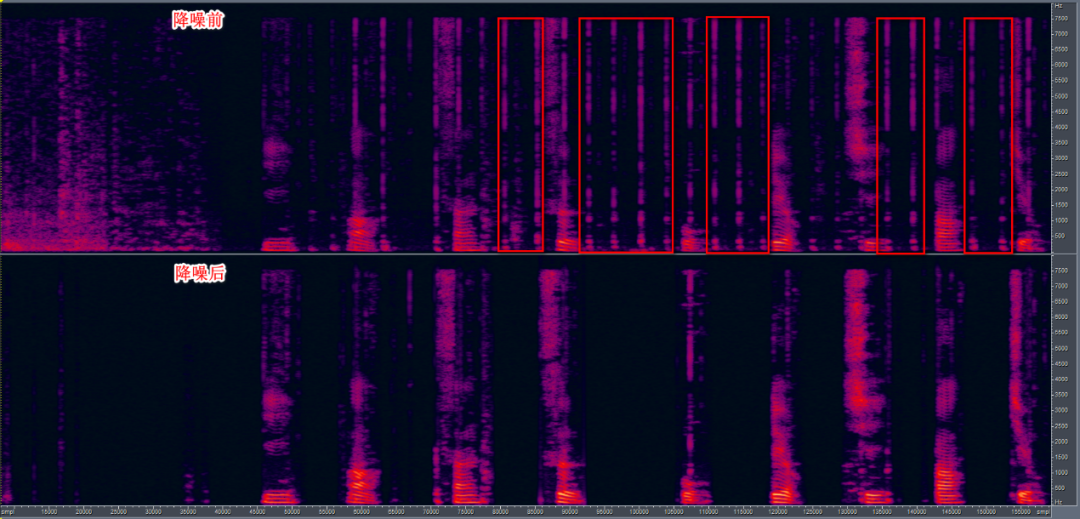
图4. 带噪语音(通话过程伴随着键盘敲击声)降噪前后对比
目前的AI降噪模型,已经在手机端和家亲上线,改善手机端和家亲APP通话降噪效果,对泛家庭、办公室等100多种噪声场景具备优秀的抑制能力,同时保持语音不失真。下一阶段,将将持续优化AI降噪模型的计算复杂度,以在IoT低功耗设备上能够推广使用。
审核编辑:陈陈
-
延迟15ms vs 软件50ms:硬件AI降噪不可替代的理由2026-06-03 471
-
AI赋能6G与卫星通信:开启智能天网新时代2025-10-11 3924
-
RTC技术在实时通信中的应用 RTC与VoIP的区别2024-12-11 2869
-
NanoEdge AI的技术原理、应用场景及优势2024-03-12 1684
-
光纤通信技术在电力通信中的应用2023-04-19 2373
-
无线通信中的MIMO技术2021-06-15 1556
-
基于DSP的语音降噪系统设计方案解析2017-10-31 2351
-
高速DSP技术及其在通信中的应用2017-10-20 1007
-
labview通信中如果有通信协议,如何处理通信中传输的协议数据?2016-04-11 2778
-
网络通信中差错控制技术的应用与研究2016-03-28 911
-
全国高技术重点图书·通信技术领域_现代通信中的排队论2012-08-18 6139
-
McWiLL系统在应急通信中的应用分析2011-11-10 984
-
MIMO技术在对流层散射通信中的性能分析2011-11-03 751
-
PROFINET及其同步实时通信分析2010-02-21 770
全部0条评论

快来发表一下你的评论吧 !
