

解构内核 perf 框架的实现讲解
嵌入式技术
描述
1. 综述
本系列文章旨在解构内核 perf 框架的实现。perf 是一个庞大的系统,所涉及的逻辑板块非常多,因此想要把 perf 框架讲清楚是不容易的。为了让读者能建立起清晰的脉络,本系列文章会根据一定的内在逻辑,逐步展开对各板块的解构。 perf 框架其本身因为考虑了很多 general 的需求,比如子任务继承父任务的 event、perf 框架后端可对接多种 PMU、既支持 per-cpu 亦支持 per-task 的 event 监控、既支持 counting(计数)模式亦支持 sampling(采样)模式,等等,这些会给解构 perf 框架带来不必要的麻烦。为强干弱枝我们的解构逻辑脉络,本系列文章以无继承、per-task、后端只对接硬件 PMU、counting 模式的 perf 工作流程作为分析切入点。 本文乃系列文章的第一篇。简要铺垫 perf 的前端,并对前端所确立的 perf 体系基本模型做阐述。 本文语义下,“perf 框架”指的是实现在内核中的 perf 框架系统,“perf 前端”指的是用户态的系统调用接口。 本文所涉及 PMU 相关的知识,请自行参阅本号《Intel SDM 之 Performance Monitoring》,或 Intel SDM。
2. perf 前端
2.1 是什么
本文所谓的“perf 前端”,并非指“perf”这个用户态程序,而是 perf_event_open 这个系统调用的用户侧接口。实际上 perf 程序其底层就是基于 perf_event_open。 libc 并未对此系统调用做用户态封装,需要用户自行封装。有关 perf_event_open 的细节请读者自行 "man perf_event_open",本文默认读者熟悉 perf_event_open 的使用(如果该条件不成立,那么您可能并非本系列文章的潜在受众),不会对该接口的众多细节做展示,而只挑选与内核 perf 框架模型有对应关系的点进行展开。
2.2 为什么
perf 框架,前端承接用户态的各种事件(event)的属性配置,后端将 event 嫁接到内核的调度、文件系统等框架中,底层对接各种 PMU 硬件,所以其必然要建立一个复杂、严谨的模型(抽象)系统。而 perf 前端是整个模型系统对接用户的最外层,所以搞清楚 perf 前端,是理解 perf 框架其模型系统的一个必要过程。
3. 事件(event)
3.1 是什么
所谓事件,就是用户所关心的,在 OS 运行过程中所发生的一个 ... ... 好吧,事件。 比方说,你可能关心某个任务在运行中的 ipc(instruction per cycle)指标,那么你需要监控(采样、计数)任务运行中的两个事件:instructions、cycles。 比如你可以以固定间隔,定期获取该周期内此任务的 instruction 及 cycle 数,然后计算二者的比值即可。 如何获取这些事件数呢?其后端需要借助 PMU。
3.2 事件类型
事件有很多类型:
PERF_TYPE_HARDWARE
PERF_TYPE_SOFTWARE
PERF_TYPE_TRACEPOINT
PERF_TYPE_HW_CACHE
PERF_TYPE_RAW
PERF_TYPE_BREAKPOINT
我们关注 PERF_TYPE_HARDWARE、PERF_TYPE_SOFTWARE、PERF_TYPE_HW_CACHE、PERF_TYPE_RAW 这四种类型。 实际上,事件类型的本质,就是其后端 PMU 的类型。
3.2.1 hardware
与硬件相关的事件。典型事件有:
PERF_COUNT_HW_CPU_CYCLES
PERF_COUNT_HW_INSTRUCTIONS
PERF_COUNT_HW_CACHE_REFERENCES
PERF_COUNT_HW_CACHE_MISSES
特征是其后端必须使用硬件 PMU 来监控。比如 PERF_COUNT_HW_INSTRUCTIONS,你要想知道运行期间所产生的 instruction 数,就必须借助硬件才能实现。
3.2.2 software
与软件相关的事件。典型事件有:
PERF_COUNT_SW_PAGE_FAULTS
PERF_COUNT_SW_CONTEXT_SWITCHES
PERF_COUNT_SW_CPU_MIGRATIONS
特征是其后端使用的是一个软件实现的 PMU 来监控。比如 PERF_COUNT_SW_CONTEXT_SWITCHES,你要想知道运行期间的上下文切换次数,就必须借助内核中基于调度系统实现的软件 PMU 才能实现。
3.2.3 hw_cache
与 cache 相关的事件。该类事件与上述两类不同。上述两类,每一种事件,通过一个 id(事件编码)来描述;而描述一个 cache 相关的事件,需要三个维度的信息:
cache id:具体是监控哪一级 cache(PERF_COUNT_HW_CACHE_L1D、PERF_COUNT_HW_CACHE_L1I、PERF_COUNT_HW_CACHE_LL 等)。
cache op id:监控的是对 cache 的什么操作(PERF_COUNT_HW_CACHE_OP_READ、PERF_COUNT_HW_CACHE_OP_WRITE、PERF_COUNT_HW_CACHE_OP_PREFETCH)。
cache op result id:操作的结果(PERF_COUNT_HW_CACHE_RESULT_ACCESS、PERF_COUNT_HW_CACHE_RESULT_MISS)。
具体来说,用户期望监控 LLC 读操作 miss 事件,则组合 PERF_COUNT_HW_CACHE_LL、PERF_COUNT_HW_CACHE_OP_READ、PERF_COUNT_HW_CACHE_RESULT_MISS 这三个参数,并传给 perf_event_open 接口。 这类事件,其后端使用的仍然是硬件 PMU(没错,与 hardware 类型一样)。
3.2.4 raw
实际上,hardware 事件的编码,如 PERF_COUNT_HW_CPU_CYCLES,是对事件编码的简化、抽象。 perf 系统对常用的硬件事件提供了形似 PERF_COUNT_HW_CPU_CYCLES 的简化编码。一个事件在 PMU 体系中,原教旨的编码应该是 umask + event select:

图 1:PERF_COUNT_HW_CPU_CYCLES 事件的 umask + event select 编码方式
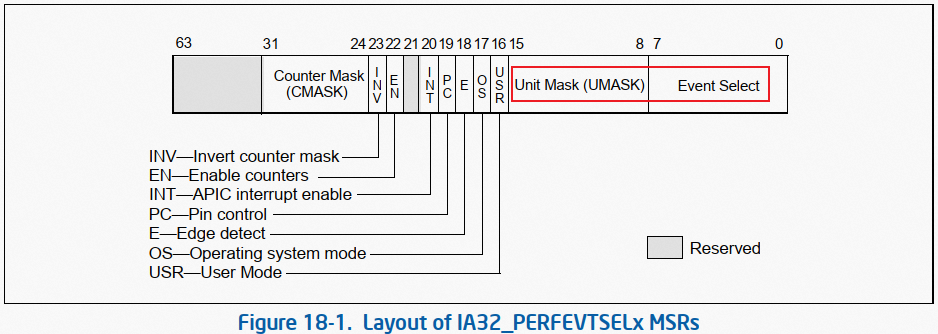
图 2:IA32_PERFEVTSELx 寄存器格式 更多细节参阅本号《Intel SDM 之 Performance Monitoring》或 Intel SDM。 因为 PMU 可监控的事件非常之多,perf 框架不可能对所有事件都提供抽象编码,所以如果要对抽象编码范围覆盖之外的其他事件做监控,需要采用 umask + event select 的方式,告诉 perf(PMU)所要监控的事件。 这种采用 umask +event select 方式编码的事件即是 raw 类型事件。 raw 事件的本质,就是 hardware、hw_cache 事件中无法被抽象编码所覆盖的那些漏网之鱼事件,也是 SDM 中对事件的原教旨编码方式,所以后端也是硬件 PMU。 在后面文章的分析中我们其实可以看到,hardware、hw_cache 类型事件,其本质就是 raw 事件。
3.2.5 事件类型与 PMU 的关系
这里要注意,PMU 不一定非得是一个硬件,也有软件实现的 PMU。
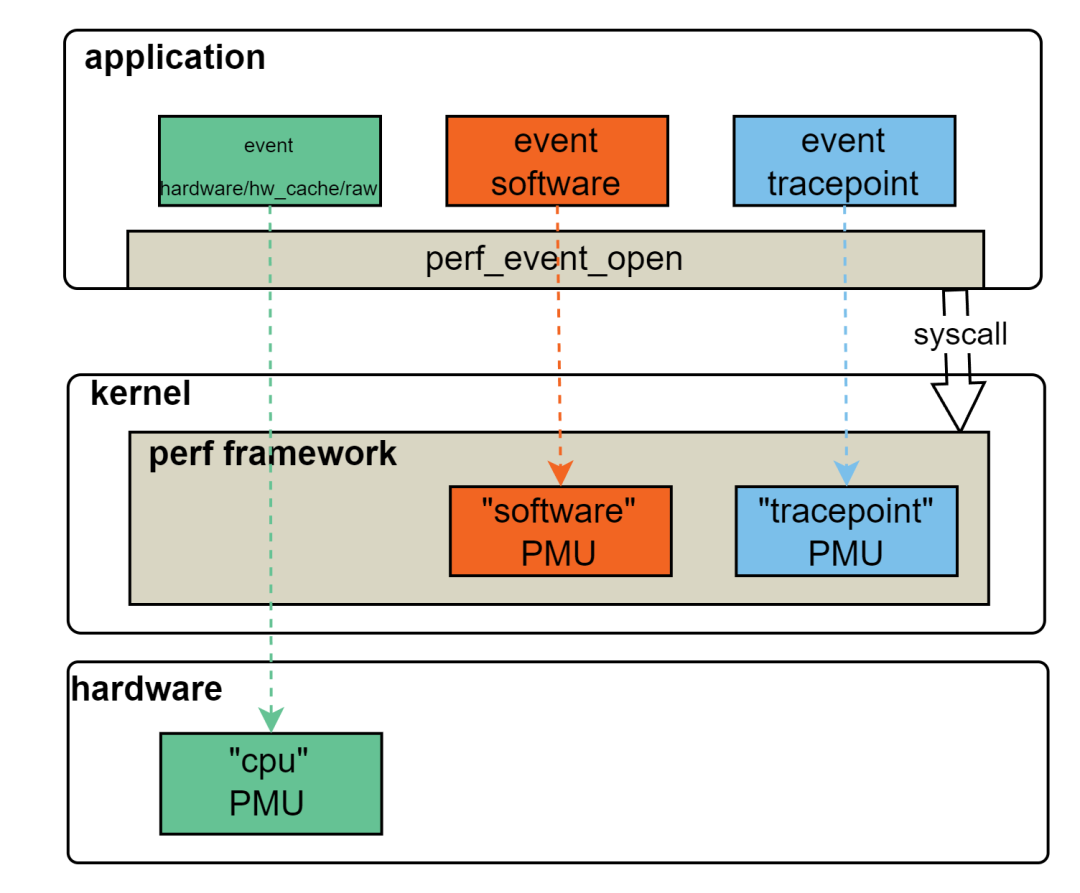
图 3:事件类型与 PMU 的关系
3.3 事件监控模式
事件的监控有两种模式,一曰 counting,一曰 sampling。
counting 模式很简单,就是简单的获取事件的计数,比如过去 5S 内 cpu 0 或 task 123 运行期间产生的 instruction 数等。
sampling 模式比较复杂,其利用 PMU 定时去对 CPU 当前运行的 ip 等信息进行采样,并通过一个环形 buffer 将采样数据给到用户态。
如综述所言,本系列文章重点关注 counting 模式。
4. 前端编程基本范式
这里介绍前端的编程范式,不是为了介绍其本身而介绍,主要是为了介绍 perf 框架模型系统的前端呈现。 具体参数配置、接口形式等,请自行 man。
4.1 基本 counting 模式编程
注意 perf_event_attr 中对事件类型、事件编码的指定。
/* 用户自己对 syscall 的封装
*/
long perf_event_open(struct perf_event_attr *hw_event, pid_t pid,
int cpu, int group_fd, unsigned long flags) {
int ret;
ret = syscall(__NR_perf_event_open, hw_event, pid, cpu,
group_fd, flags);
return ret;
}
int main(void) {
struct perf_event_attr pe;
long long count;
int fd;
/* 这里初始化了一个 attr
* 此 attr 是向 perf_event_open 刻画事件属性的关键参数
*/
memset(&pe, 0, sizeof(struct perf_event_attr));
/* type:当前要监控的是一个 hardware 类型事件
* 如前文所述,hardware 类型事件,其本质就是 perf 框架提供了抽象事件编码的硬件事件
*/
pe.type = PERF_TYPE_HARDWARE;
pe.size = sizeof(struct perf_event_attr);
/* config:指定事件的编码(instruction 事件)
*/
pe.config = PERF_COUNT_HW_INSTRUCTIONS;
/* disable:该事件默认初始是 disabled 模式
*/
pe.disabled = 1;
/* 不监控 kernel(OS)模式下的事件
*/
pe.exclude_kernel = 1;
/* perf_event_open pid 入参是 0
* 表明监控当前 task 的 instruction 事件
* 一个事件在用户态的呈现,就是一个 fd
*/
fd = perf_event_open(&pe, 0, -1, -1, 0);
/* RESET:复位计数值为 0
* ENABLE:enable 此事件(attr 参数中初始此事件是 disabled 的)
* 故而需要显式 enable
*/
ioctl(fd, PERF_EVENT_IOC_RESET, 0);
ioctl(fd, PERF_EVENT_IOC_ENABLE, 0);
/* 此 printf 的前后对事件进行了 enable、disable
* 所以,本程序的 instruction,本质上就是此 printf 语句运行期间的 instruction。
*/
printf("Measuring instruction count for this printf
");
ioctl(fd, PERF_EVENT_IOC_DISABLE, 0);
/* 读出事件的计数值
*/
read(fd, &count, sizeof(long long));
printf("Used %lld instructions
", count);
close(fd);
}
4.2 事件组读取
4.1 节中,对 instruction 单一事件进行监控,并读取 instruction 的计数。 perf 事件读取还支持一种 PERF_FORMAT_GROUP 读取方式,效果是将若干个事件放进一个组内,每个组有一个 group leader。对 group leader 进行读取,可以一次读出组内所有事件的计数。 下面演示将一个 hardware 类型事件和一个 raw 类型事件作为一个组,一次读取整组事件计数的基本范式:
struct read_format {
u64 nr; /* The number of events */
u64 values[2];
};
int main(void) {
struct perf_event_attr pe;
struct read_format count;
int group_leader_fd, group_member_fd;
/* 创建一个 hardware 类型的事件,不赘述
*/
memset(&pe, 0, sizeof(struct perf_event_attr));
pe.type = PERF_TYPE_HARDWARE;
pe.size = sizeof(struct perf_event_attr);
pe.config = PERF_COUNT_HW_INSTRUCTIONS;
pe.disabled = 1;
pe.exclude_kernel = 1;
/* 这里指定采用 PERF_FORMAT_GROUP 读取方式
* 注意,只在 group leader 时需要指定该参数
*/
pe.read_format = PERF_FORMAT_GROUP;
/* 创建 group leader
*/
group_leader_fd = perf_event_open(&pe, 0, -1, -1, 0);
/* 创建一个 raw 类型的事件
* 假设要监控的事件编码:umask = 0x00, event_select = 0x3c
* 实际上此事件就是 UnHalted Core Cycles(也就是 hardware 类型的 PERF_COUNT_HW_CPU_CYCLES)
*/
memset(&pe, 0, sizeof(struct perf_event_attr));
pe.type = PERF_TYPE_RAW;
pe.size = sizeof(struct perf_event_attr);
/* 注意 raw 类型事件,config 的编码方式
*/
pe.config = (0x00 << 4) | 0x3c;
pe.disabled = 1;
pe.exclude_kernel = 1;
/* 创建 group member,perf_event_open 的 group_fd 参数指定为 group_leader_fd
*/
group_member_fd = perf_event_open(&pe, 0, -1, group_leader_fd, 0);
/* 组模式下,只需要操作 group leader 即可
*/
ioctl(group_leader_fd, PERF_EVENT_IOC_RESET, 0);
ioctl(group_leader_fd, PERF_EVENT_IOC_ENABLE, 0);
printf("Measuring instruction count for this printf
");
ioctl(group_leader_fd, PERF_EVENT_IOC_DISABLE, 0);
/* 读出事件组的计数值,注意这里入参 count 是一个 struct read_format
*/
read(group_leader_fd, &count, sizeof(count));
/* 只有 count.nr 与当前组成员数(包括 leader、member)匹配,才是合法的数据
*/
if (count.nr == 2)
printf("Used %llu instructions, %llu cycles
", count.values[0], count.values[1]);
close(group_leader_fd);
close(group_member_fd);
}
4.3 模型总结
perf_event_open 支持 per-task 级别的事件监控,pid 入参传入目标 task 的 pid 即可。如综述所言,per-cpu 级别的事件监控本系列文章不做重点讨论。
perf_event_open 支持对事件进行分组,group leader 的 attr 需要带上 PERF_FORMAT_GROUP 参数,group member 的创建需要指定 group leader。
5. 总结
本文简要介绍 perf 前端的编程范式,意在为后续 perf 框架中模型系统的抽象建立直观感受。
编辑:黄飞
-
Linux perf 简要介绍2023-11-09 1976
-
如何使用perf性能分析工具2023-11-08 3047
-
《SoC底层软件低功耗系统设计与实现》基于Linux专门讲解软件低功耗框架和设计的书籍2023-09-08 1828
-
Linux perf性能、实际应用与案例2023-07-03 1451
-
内核perf框架解构系列:PMU硬件架构相关的概念及编程2023-03-28 3095
-
Coolbpf 在perf 事件中的增强2022-10-25 2097
-
perf 在内核中的实现原理2022-10-17 3801
-
linux内核中llist.h文件中的链表宏讲解2022-05-23 2886
-
全志Tina中使用perf分析CPU使用率2022-05-20 6145
-
如何去实现一种ThreadX内核框架的设计呢2021-11-29 2109
-
Linux内核开发框架学习资料汇总2021-06-17 1176
-
如何使用Linux内核实现USB驱动程序框架2020-11-06 1656
-
利用tracepoint梳理调度器框架及主要流程2020-10-30 3027
-
你知道perf学习-linux自带性能分析工具怎么用?2019-05-16 3321
全部0条评论

快来发表一下你的评论吧 !
